目录
1.Redis服务器被挖矿案例
2.redis常见用途
3.redis环境配置
4.redis的持久化机制
5.redis动态修改配置
6.webshell提权案例
7.定时任务+bash反弹连接提权案例
8.SSH Key提权案例
9.redis安全加固分析
1.Redis服务器被挖矿案例
我没有体验过,那就看看别人的把
记一次阿里云服务器因Redis被【挖矿病毒crypto和pnscan】攻击的case,附带解决方案_容器里的redis会被攻击吗-CSDN博客
2.redis常见用途
缓存、数据共享分布式、分布式锁、全局 ID、计数器、限流、位统计、购物车、用户消息时间线 timeline、消息队列、抽奖、点赞、签到、打卡、商品标签、商品筛选、用户关注、推荐模型、排行榜.
1.缓存:字符类型缓存
例如:热点数据缓存(例如报表、明星出轨),对象缓存、全页缓存、可以提升热点数据的访问数据。
2.数据共享分布式:字符类型
因为redis是分布式的独立服务,可以在多个应用之间共享
例如:分步式session
<dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId>
</dependency>3.分布式锁:字符串类型
setnx方法,只有不存在时才能添加成功,返回true
public static boolean getLock(String key) {Long flag = jedis.setnx(key, "1");if (flag == 1) {jedis.expire(key, 10);}return flag == 1;
}public static void releaseLock(String key) {jedis.del(key);
}4.全局ID
int型,incrby,利用原子性
incrby userid 1000
分库分表的场景,一次性拿一段
5.计数器
int型 ,incr方法
例如:文章的阅读量,微博点赞量,允许一定的延迟,先写入redis再定时同步到数据库
6.限流
int型,incr方法
以访问者的ip和其他信息作为key,访问一次增加一次次数,超过次数则返回fslse
7.位统计
string型,bitcount(1.6.6的bitmap数据结构介绍)
字符以8为二进制存储
set k1 a
setbit k1 6 1
setbit k1 7 0
get k1
/* 6 7 代表的a的二进制位的修改
a 对应的ASCII码是97,转换为二进制数据是01100001
b 对应的ASCII码是98,转换为二进制数据是01100010因为bit非常节省空间(1 MB=8388608 bit),可以用来做大数据量的统计。
*/例如:在线用户统计,留存用户统计
setbit onlineusers 01
setbit onlineusers 11
setbit onlineusers 20支持按位与、按位或等等操作
BITOPANDdestkeykey[key...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey 。
BITOPORdestkeykey[key...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey 。
BITOPXORdestkeykey[key...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey 。
BITOPNOTdestkeykey ,对给定 key 求逻辑非,并将结果保存到 destkey 。计算出7天都在线的用户
BITOP "AND" "7_days_both_online_users" "day_1_online_users" "day_2_online_users" ... "day_7_online_users"
8.购物车
string或hash,所有String可以做的hash都可以做
-
key:用户id;field:商品id;value:商品数量。
-
+1:hincr。-1:hdecr。删除:hdel。全选:hgetall。商品数:hlen。
9.用户消息时间线timeline
list,双向链表,直接作为timeline就好了。插入有序
10、消息队列
List提供了两个阻塞的弹出操作:blpop/brpop,可以设置超时时间
blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
上面的操作。其实就是java的阻塞队列。学习的东西越多。学习成本越低
队列:先进先除:rpush blpop,左头右尾,右边进入队列,左边出队列
栈:先进后出:rpush brpop
11、抽奖
自带一个随机获得值
spop myset12、点赞、签到、打卡
假如上面的微博ID是t1001,用户ID是u3001
用 like:t1001 来维护 t1001 这条微博的所有点赞用户
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
是不是比数据库简单多了。
13、商品标签
老规矩,用 tags:i5001 来维护商品所有的标签。
sadd tags:i5001 画面清晰细腻
sadd tags:i5001 真彩清晰显示屏
sadd tags:i5001 流程至极
14、商品筛选
// 获取差集sdiff set1 set2// 获取交集(intersection )sinter set1 set2// 获取并集sunion set1 set2假如:iPhone11 上市了
sadd brand:apple iPhone11sadd brand:ios iPhone11sad screensize:6.0-6.24 iPhone11sad screentype:lcd iPhone 11赛选商品,苹果的、ios的、屏幕在6.0-6.24之间的,屏幕材质是LCD屏幕
sinter brand:apple brand:ios screensize:6.0-6.24 screentype:lcd15、用户关注、推荐模型
follow 关注 fans 粉丝
相互关注:
sadd 1:follow 2
sadd 2:fans 1
sadd 1:fans 2
sadd 2:follow 1
我关注的人也关注了他(取交集):
sinter 1:follow 2:fans
可能认识的人:
用户1可能认识的人(差集):sdiff 2:follow 1:follow
用户2可能认识的人:sdiff 1:follow 2:follow
16、排行榜
id 为6001 的新闻点击数加1:
zincrby hotNews:20190926 1 n6001获取今天点击最多的15条:
zrevrange hotNews:20190926 0 15 withscores3.redis环境配置
三、redis环境安装-CSDN博客
4.redis的持久化机制
Redis是一个基于内存的数据库,所有的数据都存放在内存中,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的持久化机制。
主要分为两种:
1.RDB快照机制
该机制把数据以快照的形式保存在磁盘上,是某个时间点的一次全量数据备份,以二进制序列化形式写入磁盘存储,保存在磁盘下的文件名位dump.rb,恢复时直接从磁盘上读取数据到内存
1.1如何触发
指令:save、bgsave、自动触发
save:停止除RDB外的所有环境,阻塞时间长
bgsave:建立一个子进程来进行RDB,并写入临时文件,带持久化过程都结束了,会把临时文件copy到磁盘上,阻塞时间较短,也就更为常用
自动触发:在redis.conf配置文件中修改,默认达到以下三种条件,就会自动触发持久化,触发后,底层调用的其实还有bgsave命令:
1分钟内改了1万次,5分钟内改了10次,或15分钟内改了1次。
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
如果不需要持久化机制,则可以注释掉所有的save命令
RDB的优势
1)全量备份,使用灾难恢复。
2)相对于不追求过度完整的场景,其速度更快
3)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
劣势:
1)内容多,占用空间大
2)当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
3)在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。
2.AOF日志机制
是一种持续增量备份,会把redis中的所有操作写入日志文件,且该文件只可追加,不可修改.redis启动的时候会读取该文件进行数据恢复,根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
1)AOF的重写机制,因为日志只增不减,所以添加重写机制,当文件大小达到最大阈值时,就会进行压缩文件,只保留恢复数据的最小指令集,redis提供了bgrewriteaof命令,增添一个新的进程对aof文件进行重写。
2)重写原理:AOF文件持续增长而过大时,会fork出一条新进程来重写aof文件,将内存中的整个数据库内容用命令的方式重写了一个新的aof文件(注意:在重写时并不是读取旧的aof文件),在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作。
3)触发时机:Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
触发机制:
1)每修改同步:appendfsync always 同步持久化,每次发生数据变更会被立即记录到磁盘,性能较差但数据完整性比较好。
2)每秒同步:appendfsync everysec 异步操作,每秒记录,如果一秒内宕机,有数据丢失。
3)不同步:appendfsync no 从不同步
Linux 的 glibc 提供了 fsync()函数可以将指定文件的内容强制从内核缓存刷到磁盘。只要 Redis 进程实时调用 fsync 函数就可以保证 aof 日志不丢失。但是 fsync 是一个磁盘 IO 操作,它速度很慢,如果每条指令都要 fsync 一次,那么 Redis 高性能的地位就不保了。
AOF的优点:
1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
2)AOF只是追加写日志文件,对服务器性能影响较小,速度比RDB要快,消耗的内存较少
3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。
AOF的劣势:
1)对于相同数据集的数据而言,aof文件要远大于rdb文件,恢复速度慢于rdb。
2)对于每秒一次同步的情况,aof运行效率要慢于rdb,不同步效率和rdb相同。
注:如果同时开启两种持久化方式,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
三、Redis4.0的混合持久化:
仅使用RDB快照方式恢复数据,由于快照时间粒度较大时,会丢失大量数据。
仅使用AOF重放方式恢复数据,日志性能相对 rdb 来说要慢。在 Redis 实例很大的情况下,启动需要花费很长的时间。为了解决这个问题,Redis4.0开始支持RDB和AOF的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。RDB 文件的内容和增量的 AOF 日志文件存在一起,这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小
大量数据使用粗粒度(时间上)的rdb快照方式,性能高,恢复时间快。
增量数据使用细粒度(时间上)的AOF日志方式,尽量保证数据的不丢失。在Redis重启时,进行AOF重写的时候就直接把RDB的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB和 AOF 的优点,快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是AOF 格式,可读性较差。
另外,可以使用下面这种方式:Master使用AOF,Slave使用RDB快照,master需要首先确保数据完整性,它作为数据备份的第一选择;slave提供只读服务或仅作为备机,它的主要目的就是快速响应客户端read请求或灾切换。
5.redis动态修改配置
config 命令用于查看当前redis配置、以及不重启redis服务实现动态更改redis配置等
注意:不是所有配置都可以动态修改,且此方式无法持久保存
#设置连接密码
127.0.0.1:6379> CONFIG SET requirepass 123456
OK
#查看连接密码
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) "123456"
获取当前配置
#奇数行为键,偶数行为值
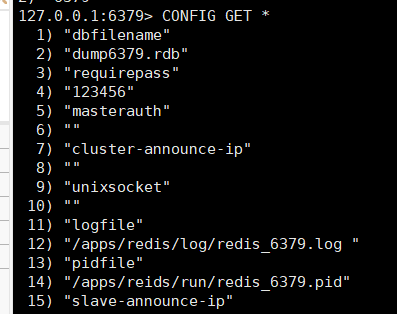
更改最大内存
127.0.0.1:6379> CONFIG SET maxmemory 8589934592
OK
127.0.0.1:6379> CONFIG GET maxmemory
1) "maxmemory"
2) "8589934592
6.webshell提权案例
记一次绕过安全狗和360提权案例-腾讯云开发者社区-腾讯云
7.定时任务+bash反弹连接提权案例
linux系统提权 · 白帽与安全 · 看云
8.SSH Key提权案例
SSH密钥提权_ssh提权-CSDN博客
9.redis安全加固分析
在众多开源缓存技术中,Redis无疑是目前功能最为强大,应用最多的缓存技术之一,但是原生Redis版本在安全方面非常薄弱,很多地方不满足安全要求,如果暴露在公网上,极易受到恶意攻击,导致数据泄露和丢失。
针对DCS的Redis实例,您在使用过程中,可参考如下建议:
- 网络连接配置
- 敏感数据加密后存储在Redis实例,且实例不开启公网访问。
对于敏感数据,尽量加密后存储。如无特殊需要,尽量不使用公网访问。
- 对安全组设置有限的、必须的允许访问规则。
- 客户端应用所在ECS设置防火墙。
- 设置实例访问密码。
- 配置实例白名单。
- 敏感数据加密后存储在Redis实例,且实例不开启公网访问。
- Redis-cli(redis命令行)使用
- 隐藏密码
安全问题:通过在redis-cli指定-a参数,密码会被ps出来,属于敏感信息。
解决方案:修改Redis源码,在main方法进入后,立即隐藏掉密码,避免被ps出来。
- 禁用脚本通过sudo方式执行
安全问题: redis-cli访问参数带密码敏感信息,会被ps出来,也容易被系统记录操作日志。
解决方案:改为通过API方式(Python可以使用redis-py)来安全访问,禁止通过sudo方式切换到dbuser账号使用redis-cli。
- 隐藏密码
10.weblogic基本介绍
https://www.cnblogs.com/wzh313/articles/10510361.html
后续更新中间件靶场漏洞复现!