该示例为参考算法,仅作为在 征程 6 上模型部署的设计参考,非量产算法。
1.简介
激光雷达天然地具有深度信息,摄像头可以提供丰富的语义信息,它们是车载视觉感知系统中两个最关键的传感器。但是,如果激光雷达或者摄像头发生故障,则整个感知框架不能做出任何预测,这在根本上限制了实际自动驾驶场景的部署能力。目前主流的感知架构选择在特征层面进行多传感器融合,即中融合,其中比较有代表性的路线就是 BEV 范式。BEVFusion 就是典型的中融合方法,其存在两个独立流,将来自相机和 LiDAR 的原始输入编码为同一个 BEV 空间。由于是通用的融合框架,相机流和 LiDAR 流的方法都可以自由选择,在 nuScenes 数据集表现出了很强的泛化能力。本文将介绍 BEVFusion 在地平线 J6E/M 平台上的优化部署。
2.性能精度指标
模型参数:
| 模型 | 数据集 | Input shape | LiDAR Stream | Camera Stream | BEV Head | Occ Head |
|---|---|---|---|---|---|---|
| BEVFusion | Nuscenes | 图像输入:6x3x512x960点云输入:1x5x20x40000 | CenterPoint | BEVFormer | BEVFormerDetDecoder | BevformerOccDetDecoder |
性能精度表现:
| 浮点****精度 NDS | 量化精度 NDS | J6E | |
|---|---|---|---|
| Latency/ms | FPS | ||
| 0.6428 | 0.6352 | 135.64 | 30.95 |
3.公版模型介绍
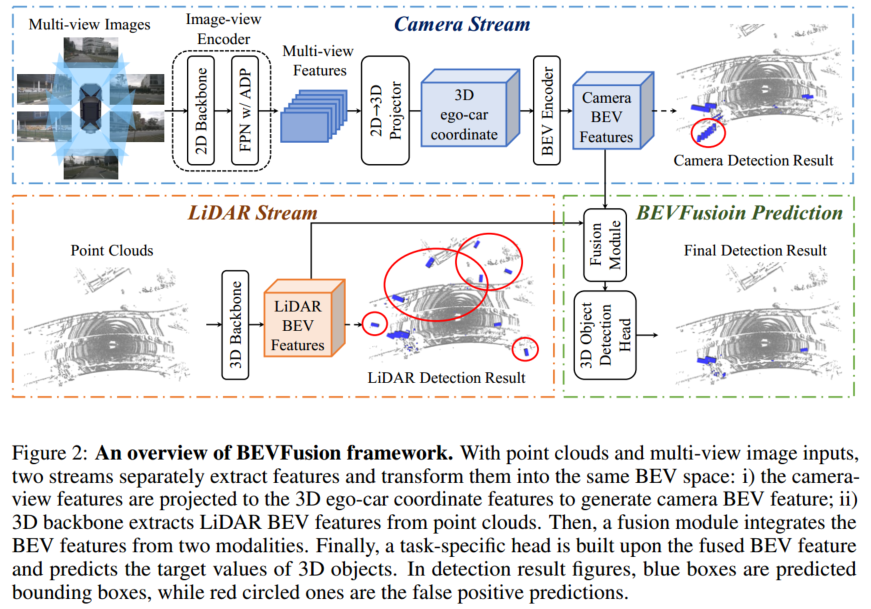
BEVFusion 主要由相机流、激光雷达流、动态融合模块和检测头组成,下面将逐一进行介绍。
3.1 相机流
相机流将多视角图像转到 BEV 空间,由图像编码器、视觉投影模块、BEV 编码器组成。
3.1.1 图像****编码器
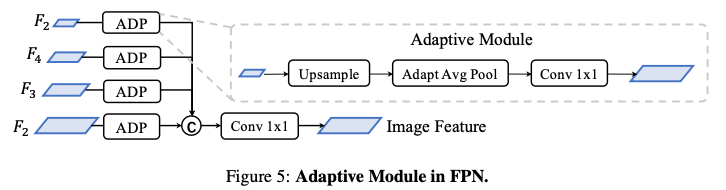
图像编码器旨在将输入图像编码为语义信息丰富的深度特征,它由用于基本特征提取的 2D backbone Dual-Swin-Tiny 和用于多尺度特征提取的 FPN 组成,并采用了一个简单的功能自适应模块 ADP 来完善上采样功能,如下图所示:
3.1.2 视觉投影模块
视觉投影模块采用 LSS 将图像特征转换为 3D 自车坐标,将图像视图作为输入,并通过分类方式密集地预测深度。
然后,根据相机外参和预测的图像深度,获取伪体素。
3.1.3 BEV 编码模块
BEV 编码模块采用空间到通道(S2C)操作将 4D 伪体素特征编码到 3D BEV 空间,从而保留语义信息并降低成本。然后又使用四个 3 × 3 卷积层缩小通道维度,并提取高级语义信息。
3.2 LiDAR 流
LiDAR 流将激光雷达点转换为 BEV 空间,BEVFusion 采用 3 种流行的方法,PointPillars、CenterPoint 和 TransFusion 作为激光雷达流,从而展示模型框架的优秀泛化能力。
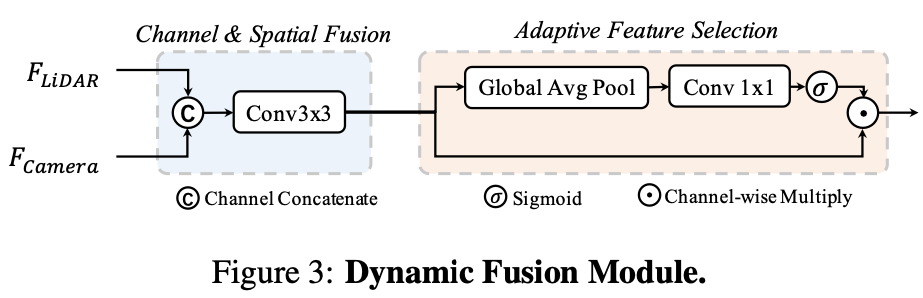
3.3 动态融合模块
动态融合模块的作用是将 concat 后的相机、 LiDAR 的 BEV 特进行有效融合。受 Squeeze-and-Excitation 机制的启发, BEVFusion 应用一个简单的通道注意力模块来选择重要的融合特征,网络结构图如下所示:
4.地平线部署优化
地平线参考算法使用流程请参考附录《TCJ6007-J6 参考算法使用指南》;对应高效模型设计建议请参考附录《J6 算法平台模型设计建议
4.1 优化点总结
整体情况:
BEVFusion 参考算法采用 BEVFormer 和 centerpoint 分别生成视觉和 LiDAR BEV 特征,然后使用 SE 模型融合 BEV 特征,最后将 BEV 特征解码。
暂时无法在飞书文档外展示此内容
改动点:
相机流使用了地平线深度优化后的 bevformer 参考算法,并将其转换到 LiDAR 坐标系,其相对于公版的优化如下:
使用地平线深度优化后的高效 backbone HENet 提取图像特征;
将 attention 层的 mean 替换为 conv 计算,使性能上获得提升;
公版模型中,在 Encoder 的空间融合模块,会根据 bev_mask 计算有效的 query 和 reference_points,输出 queries_rebatch 和 reference_points_rebatch,作用为减少交互的数据量,提升模型运行性能。对于稀疏的 query 做 crossattn 后再将 query 放回到 bev_feature 中。;
修复了公版模型中时序融合的 bug,并获得了精度上的提升,同时通过对关键层做 int16 的量化精度配置以保障 1%以内的量化精度损失。
LiDAR 流采用了地平线深度优化后的 centerpoint 参考算法,其相对于公版的优化如下:
前处理部分的输入为 5 维点云并做归一化处理,对量化训练更加友好;
PillarFeatutreNet 中的 PFNLayer 使用 Conv2d + BatchNorm2d + ReLU,替换原有的 Linear + BatchNorm1d + ReLU,使该结构可在 BPU 上高效支持,实现了性能提升;
PillarFeatutreNet 中的 PFNLayer 使用 MaxPool2d,替换公版的 torch.max,便于性能的提升;
Scatter 过程使用 horizon_plugin_pytorch 优化实现的 point_pillars_scatter,便于模型推理优化,逻辑与 torch 公版相同;
对于耗时严重的 OP,采用 H、W 维度转换的方式,将较大维数放到 W 维度,比如 1x5x40000x20 转换为 1x5x20x40000;
相对于公版,增加了 OCC 任务头,实现了 LiDAR+Camera+OCC 动静态二网合一;
4.2 性能优化
4.2.1 相机流
公版 BEVFusion 使用流行的 Lift-Splat-Shoot(LSS)并适度调整以提高性能。参考算法直接采用了地平线深度优化后的 BEVFormer 参考算法作为相机流网络,bev 网格的尺寸配置为 128 x128。
改动点 1:
backbone 由公版的 Dual-Swin-Tiny 替换为地平线的高效 backbone HENet,不仅在精度上可与 ResNet50 相媲美,而且在性能上有显著优势。
HENet 是针对 征程 6 平台专门设计的高效 backbone,其采用了纯 CNN 架构,总体可分为四个 stage,每个 stage 会进行 2 倍下采样。以下为总体的结构配置:
depth = [4, 3, 8, 6]
block_cls = ["GroupDWCB", "GroupDWCB", "AltDWCB", "DWCB"]
width = [64, 128, 192, 384]
attention_block_num = [0,0,0,0]
mlp_ratios, mlp_ratio_attn = [2, 2, 2, 3], 2
act_layer = ["nn.GELU", "nn.GELU", "nn.GELU", "nn.GELU""]
use_layer_scale = [True,True,True,True]
final_expand_channel, feature_mix_channel = 0,1024
down_cls = ["S2DDown", "S2DDown", "S2DDown", "None"71
模型相关细节可以参考【地平线高效 backbone: HENet】。
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/backbones/henet.py
改动点 2:
bevformer 中的Temporal Self-Attention通过引入时序信息与当前时刻的 BEV Query 进行融合,提高 BEV Query 的建模能力,Temporal Self-Attention中最关键的结构为MultiScaleDeformableAttention。
经评估,该模块中的 mean 对性能影响较大,参考算法中将其替换为固定 weight 的 conv 计算,从而获取性能上的提升,相关代码:
class HorizonTemporalSelfAttention(MultiScaleDeformableAttentionBase):"""The basic structure of HorizonTemporalSelfAttention.Args:embed_dims: The embedding dimension of Attention.num_heads: Parallel attention heads.num_levels: The num of featuremap.num_points: The num points for each head sample.grid_align_num: The align num for grid, align the grid shape of \gridsample operator to \[bs * numhead, -1, grid_align_num * numpoints, 2].num_bev_queue: The num queue for temporal fusion.reduce_align_num: The align num for reduce mean, align the shape to \[bs, num_bev_queue * reduce_align_num, -1, num_query].dropout: Probability of an element to be zeroed.feats_size: The Size of featmaps."""def
__init__
(self,embed_dims: int = 256,num_heads: int = 8,num_levels: int = 4,num_points: int = 4,grid_align_num: int = 8,num_bev_queue: int = 2,reduce_align_num: int = 1,dropout: float = 0.1,feats_size: Sequence[Sequence[int]] = ((128, 128),),) -> None:super().
__init__
(embed_dims=embed_dims,num_heads=num_heads,num_levels=num_levels,num_points=num_points,grid_align_num=grid_align_num,feats_size=feats_size,)self.dropout = nn.Dropout(dropout)self.num_bev_queue = num_bev_queueself.reduce_align_num = reduce_align_num...#将mean计算替换为conv计算self.query_reduce_mean = nn.Conv2d(self.num_bev_queue * self.reduce_align_num,self.reduce_align_num,1,bias=False,)代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/bevformer/attention.py
改动点 3:
Spatial Cross-Attention利用 Temporal Self-Attention 模块输出的 bev_query, 对主干网络和 Neck 网络提取到的多尺度环视图像特征进行查询,生成 BEV 空间下的BEV Embedding特征。公版的 BEVFormer 中采用 bevmask 来减少 camera 的 query 点数的优化,但是由于涉及到 BPU 不支持的动态 shape,并且涉及到运行效率较低的 gather/scatter 操作(当前 gather 算子已经支持 BPU 加速)。进一步分析发现:
从 bev voxel 的角度来看,中心点到 multi camera 的映射是稀疏的;
从 bev pillar 的角度来看,通常每个 pillar 只会映射到 1-2 个 camera;
基于以上分析以及实验结果,参考算法在设置了virtual_bev_h、virtual_bev_w、max_numcam_overlap这 3 个参数对稀疏率进行配置,这 3 个参数的具体含义是:
virtual_bev_h:虚拟 bev 的高度,用于计算将稀疏点集恢复为密集 bev 的网格,参考算法中配置为 64;
virtual_bev_w:虚拟 bev 的宽度,用于计算将稀疏点集恢复为密集 bev 的网格,参考算法中配置为 80;
max_numcam_overlap:每个 bev pillar 映射到的最多 camera 数量,参考算法中配置为 2;
view_transformer=dict(type="SingleBevFormerViewTransformer",bev_h=bev_h_,bev_w=bev_w_,pc_range=point_cloud_range,num_points_in_pillar=2,embed_dims=
_dim_
,queue_length=1,in_indices=(-1,),single_bev=True,use_lidar2img=use_lidar2img,max_camoverlap_num=max_camoverlap_num, #2virtual_bev_h=64,virtual_bev_w=80,positional_encoding=dict(type="LearnedPositionalEncoding",num_feats=
_pos_dim_
,row_num_embed=bev_h_,col_num_embed=bev_w_,),
代码路径:samples/ai_toolchain/horizon_model_train_sample/scripts/configs/lidar_bevfusion/bevfusion_pointpillar_henet_multisensor_multitask_nuscenes.py
4.2.2 LiDAR 流
公版 BEVFusion 采用了当前流行的 3 种激光点云检测模型 PointPillars , CenterPoint 和 TransFusion 作为 LiDAR 流来展示框架的通用性。BEVFusion 参考算法复用了经过深度优化的 centerpoint 参考算法,其相对于公版主要做了以下性能优化,下面将逐一介绍。
改动点 1:
为了应用 2D 卷积架构,PillarFeatutreNet 将点云(P,N,5)转换为 2D 伪图像,整体步骤如下图所示:
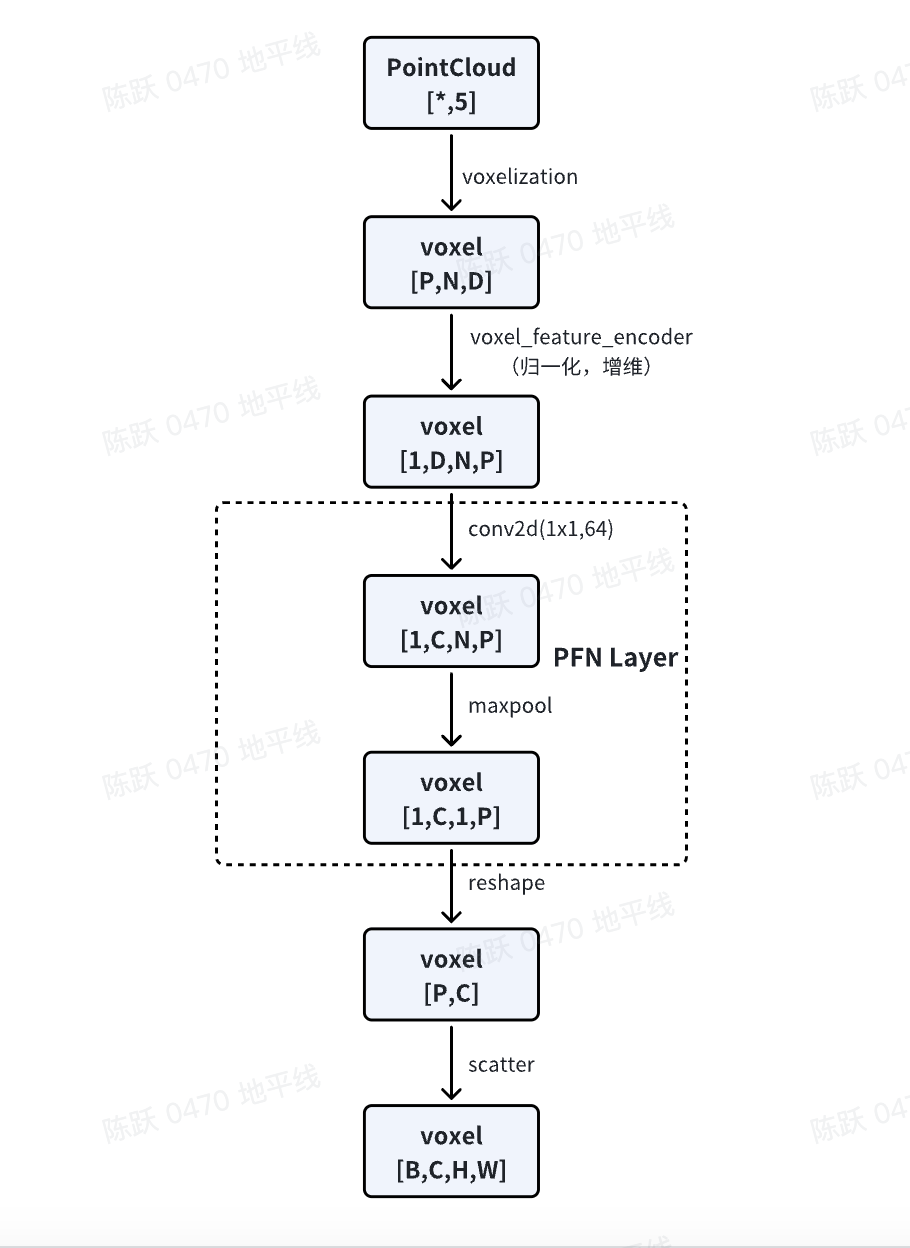
公版模型中 PillarFeatutreNet 中的部分算子在 BPU 运行效率比较低,所以参考算法对其做了替换:
PillarFeatutreNet 中的 PFNLayer 使用 BPU 上运行比较高效的 Conv2d + BathNorm2d + ReLU 算子,替换了公版的 Linear + BatchNorm1d + ReLU 结构,实现了性能的提升;
PillarFeatutreNet 中的 PFNLayer 使用 MaxPool2d,替换原有的 torch.max,便于性能的提升,对应代码:
class PFNLayer(nn.Module):def
__init__
(self,in_channels: int,out_channels: int,bn_kwargs: dict = None,last_layer: bool = False,use_conv: bool = True,pool_size: Tuple[int, int] = (1, 1),hw_reverse: bool = False,):"""Pillar Feature Net Layer.This layer is used to convert point cloud into pseudo-image.Can stack multiple to form Pillar Feature Net.The original PointPillars paper uses only a single PFNLayer.Args:in_channels (int): number of input channels.out_channels (int): number of output channels.bn_kwrags (dict): batch normalization arguments. Defaults to None.last_layer (bool, optional): if True, there is no concatenation oflayers. Defaults to False."""...if not self.use_conv:...else:#使用Conv2d + BathNorm2d + ReLU,#替换了公版的 Linear + BatchNorm1d + ReLUself.linear = nn.Conv2d(in_channels, self.units, kernel_size=1, bias=False)self.norm = nn.BatchNorm2d(self.units, **bn_kwargs)self.relu = nn.ReLU(inplace=True)#使用 MaxPool2d,替换torch.maxself.max_pool = nn.MaxPool2d(kernel_size=pool_size, stride=pool_size)
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/lidar/pillar_encoder.py
改动点 2:
如上图所示,Scatter 是实现伪图像转换的重要一个步骤,参考算法使用horizon_plugin_pytorch实现的point_pillars_scatter,便于模型推理优化,逻辑与公版相同。对应代码:
from horizon_plugin_pytorch.nn.functional import point_pillars_scatter
class PointPillarScatter(nn.Module):...def forward(...):#input_shape=(coors_range[3:] - coors_range[:3]) / voxel_sizeself.nx = input_shape[0]self.ny = input_shape[1]if self.use_horizon_pillar_scatter: #对应改动4if len(voxel_features.shape) == 4:P, C = voxel_features.size(2), voxel_features.size(3)voxel_features = voxel_features.reshape(P, C)out_shape = (batch_size, self.nchannels, self.ny, self.nx)#(P, C)-->(batch,C,H,W)batch_canvas = point_pillars_scatter(voxel_features, coords, out_shape)else:...return batch_canvas
其中,核心函数point_pillars_scatter是在horizon_plugin_pytorch中实现的。
代码路径: /usr/local/lib/python3.10/dist-packages/hat/models/task_modules/lidar/pillar_encoder.py
4.2.3 动态融合模块
相对于公版的动态融合模块(参考 3.3 节),参考算法在 concat 后新增了 1 个 conv1x1,有助于性能的提升,相关代码如下:
class BevFuseModule(nn.Module):"""BevFuseModule fuses features using convolutions and SE block.Args:input_c: The number of input channels.fuse_c: The number of channels after fusion."""def
__init__
(self, input_c: int, fuse_c: int):super().
__init__
()self.reduce_conv = ConvModule2d(input_c,fuse_c,kernel_size=1,stride=1,padding=0,norm_layer=nn.BatchNorm2d(fuse_c, eps=1e-3, momentum=0.01),act_layer=nn.ReLU(inplace=False),...def forward(self, x: torch.Tensor):#增加了 conv1x1x = self.reduce_conv(x)x = self.conv2(x)pts_feats = self.seblock(x)return pts_feats
代码路径: /usr/local/lib/python3.10/dist-packages/hat/models/task_modules/lidar_fusion/fusion_module.py
4.3 浮点精度优化
4.3.1 旋转增强
在模型训练时,参考算法对 bev 进行旋转增强,相关代码如下:
train_dataset = dict(type="NuscenesBevSequenceDataset",data_path=os.path.join(data_rootdir, "train_lmdb"),...transforms=[dict(type="MultiViewsImgResize", size=input_size),dict(type="MultiViewsImgFlip"),dict(type="MultiViewsImgRotate", rot=(-5.4, 5.4)),dict(type="BevBBoxRotation", rotation_3d_range=(-0.3925, 0.3925)),dict(type="MultiViewsPhotoMetricDistortion"),dict(type="MultiViewsImgTransformWrapper",transforms=[dict(type="PILToTensor"),dict(type="BgrToYuv444", rgb_input=True),dict(type="Normalize", mean=128, std=128),],),],
)
代码路径:
horizon_model_train_sample/scripts/configs/lidar_bevfusion/bevfusion_pointpillar_henet_multisensor_multitask_nuscenes.py
/usr/local/lib/python3.10/dist-packages/hat/data/transforms/multi_views.py
4.3.2 加载预训练模型
为了提升浮点模型的精度,浮点训练时相机流和 LiDAR 流分别加载了预训练模型,然后再共同训练,对应代码如下:
float_trainer = dict(type="distributed_data_parallel_trainer",model=model,data_loader=data_loader,model_convert_pipeline=dict(type="ModelConvertPipeline",converters=[dict(type="LoadCheckpoint",#加载相机流的预训练模型checkpoint_path=os.path.join(camera_ckpt_dir, "float-checkpoint-last.pth.tar"),allow_miss=True,ignore_extra=True,verbose=True,),dict(type="LoadCheckpoint",#加载LiDAR流的预训练模型checkpoint_path=os.path.join(lidar_ckpt_dir, "float-checkpoint-last.pth.tar"),...),
代码路径:
horizon_model_train_sample/scripts/configs/lidar_bevfusion/bevfusion_pointpillar_henet_multisensor_multitask_nuscenes.py
4.4 量化精度优化
4.4.1 全 int8+部分算子配置为 int16
BEVFusion 参考算法采用的量化策略为全 int8+部分敏感算子通过 set_qconfig 配置为 int16,其中敏感算子的集中分布在 bevformer 部分,如下为 bevformer 中将MultiScaleDeformableAttention中对量化敏感的算子和 Tensor 配置为 int16 的示例代码:
class MultiScaleDeformableAttentionBase(nn.Module):"""The basic class for MultiScaleDeformableAttention.Args:embed_dims: The embedding dimension of Attention.num_heads: Parallel attention heads.num_levels: The num of featuremap.num_points: The num points for each head sample.grid_align_num: The align num for grid, align the grid shape of \gridsample operator to \[bs * numhead, -1, grid_align_num * numpoints, 2].feats_size: The Size of featmaps."""def
__init__
(self,embed_dims: int = 256,num_heads: int = 8,num_levels: int = 4,num_points: int = 4,grid_align_num: int = 8,feats_size: Sequence[Sequence[int]] = ((128, 128),),) -> None:super().
__init__
()...def set_qconfig(self) -> None:"""Set the quantization configuration."""from hat.utils import qconfig_managerint16_module = [self.sampling_offsets,self.quant_shape,self.norm_offset,self.add_offset,self.add1,self.mul1,]for m in int16_module:m.qconfig = qconfig_manager.get_qconfig(activation_qat_qkwargs={"dtype": qint16},activation_calibration_qkwargs={"dtype": qint16,},activation_calibration_observer="mix",)
代码路径:
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/bevformer/attention.py
4.5 其它优化
4.5.1 增加 Occ 任务头
除了公版 BEVFusion 就存在的 3D 检测头外,参考算法增加了 Occ 任务头做占用预测,和 3D 检测头共用特征部分,从而极大地节省了计算资源。Occ 任务头复用了 FlashOcc 中的 head 进行设计,通过通道转高度模块将 BEV 特征沿通道维度执行简单的重塑操作。相关代码如下:
def forward(self, img_feats: Tensor):"""Forward mould.Args:img_feats: (B, C, Dy, Dx)Returns:occ_pred:tensor"""occ_pred = self.final_conv(img_feats)if self.use_upsample is True:occ_pred = F.interpolate(occ_pred, size=(200, 200), mode="bilinear", align_corners=False)# (B, C, Dy, Dx) --> (B, Dx, Dy, C)occ_pred = occ_pred.permute(0, 3, 2, 1)bs, Dx, Dy = occ_pred.shape[:3]if self.use_predicter:#通道转高度操作# (B, Dx, Dy, C) --> (B, Dx, Dy, 2
*C) --> (B, Dx, Dy, Dz*
n_cls)occ_pred = self.predicter(occ_pred)occ_pred = occ_pred.view(bs, Dx, Dy, self.Dz, self.num_classes)return occ_pred
代码路径:
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/flashocc/bev_occ_head.py
Occ label 坐标转换
由于 Occ label 是在 ego 坐标系中标注的,所以需要将其统一到 Lidar 坐标系,相关代码如下:
class NuscenesBevDataset(NuscenesDataset):...def
__getitem__
(self, item):aug_cfg = Noneif isinstance(item, dict):idx = item["idx"]aug_cfg = item["aug"]else:idx = itemsample = self._decode(self.pack_file, self.samples[idx])sample = NuscenesSample(sample)data = self.sampler(sample)if aug_cfg:data["scenes_aug"] = aug_cfgif self.transforms is not None:data = self.transforms(data)if self.with_lidar_occ:#将Occ label由ego坐标系转到lidar坐标系data["gt_occ_info"] = sample._get_lidar_occ(data["lidar2global"])return data
代码路径:
/usr/local/lib/python3.10/dist-packages/hat/data/datasets/nuscenes_dataset.py
Bev 特征裁剪
bev 的空间范围为[51.2,51.2],grid 尺寸为 128x128;而 occ 的空间范围为[40,40],grid 尺寸为 128x128。为了将 bev 空间范围对齐到 Occ,occ_head中根据比例将 128x128 的 bev feature 从中心裁剪出 100x100 的 roi,从而满足 40/51.2=100/128。相关代码如下:
occ_head = dict(type="BevformerOccDetDecoder",use_mask=True,lidar_input=lidar_input,camera_input=camera_input,num_classes=num_classes_occ,#使用RoiResize做bev feature的裁剪roi_resizer=dict(type="RoiResize",in_strides=[1],roi_resize_cfgs=[dict(in_stride=1,roi_box=(14, 14, 114, 114),)],),
代码路径:
horizon_model_train_sample/scripts/configs/lidar_bevfusion/bevfusion_pointpillar_henet_multisensor_multitask_nuscenes.py
5.总结与建议
5.1 训练建议
建议在浮点训练时分别加载 Lidar 流和相机流的预训练模型,然后再训练整个网络;
建议选择合适的 bev grid size,实验中发现 bev grid size 配置为 128x128 时的精度比 50x50 要高;
对于多任务模型,建议在量化训练适当增加 epoch,即量化训练不一定要严格按照浮点训练的 1/10 epoch 来训练;
浮点训练时采用CosineAnnealingLrUpdater策略,量化训练时采用StepDecayLrUpdater策略,对于此模型来说,采用StepDecayLrUpdater策略对量化训练精度更友好;
5.2 部署建议
建议在模型架构设计之初就考虑采用地平线深度优化后的 backbone 或者网络作为 base model;
在注意力机制中存在一些 add、sum 等 ElementWise 操作,对于导致性能瓶颈的可以考虑 conv 替换,对于造成量化风险的可以根据敏感度分析结果合理选择更高的量化精度,以确保注意力机制的部署;
建议在选择 bev size 时考虑性能影响。征程 6 相比于 征程 5 带宽增大,但仍需注意 bev size 过大导致访存时间过长对性能的影响,建议考虑实际部署情况选择合适的 bev size;
若出现性能问题可以通过优化 backbone 或者减少层数或者点数的方式来提升性能,但要注意以上操作可能会导致精度损失,请优先考虑对点数的减少等对精度的影响较小性能收益最高的操作;
附录
论文:BEVFusion
公版模型代码:https://github.com/ADLab-AutoDrive/BEVFusion
参考算法使用指南:J6 参考算法使用指南




![Hetao P3804 Cut 题解 [ 蓝 ] [ AC 自动机 ] [ 差分 ]](https://img2024.cnblogs.com/blog/3389671/202501/3389671-20250112185658523-2023249476.png)