作者:Yingjun Wu
TL;DR.
curl https://risingwave.com/sh | sh
在2021年初,我创立了RisingWave,目标是推广流计算技术的普及。在过去的三年中,我不断的向市场布道RisingWave,希望RisingWave能够在流计算这一市场中占有一席之地。经过坚持不懈的努力,如今,RisingWave已被数百家企业采用,这些企业遍布多个领域,包括一些世界顶尖的金融交易、制造业、安全、航空航天等行业的公司。
为大型企业提供优质服务总是能够令人感到兴奋。然而,与此同时,我始终在思考一个问题:为什么总是大公司?为什么不是中小型企业或者个人?将流计算技术以开发者为中心来设计是否切实可行?换句话说,个人开发者或中小型企业是否能够真正利用流计算技术的强大功能?
数据系统市场的平民化趋势
“让流计算技术平民化”。产生这一想法,并不是单纯因为我喜欢开脑洞。如果我们看一下如今的数据系统市场的话,我们便会发现,云上的数据库服务已经呈现了很明显的向开发者市场下沉的趋势。正如其他任何先进技术的发展历程一样,各类数据库通常都是首先被顶尖科技公司等利用,然后随着时间的推移,逐渐被广大人民群众,尤其是个人开发者与中小型公司,所使用。
这一技术平民化的过程,需要有两大前提同时被满足:
-
从用户角度出发,开发者及中小型公司有足够的需求;
-
从产品角度出发,市场上有足够好用便宜的产品。
对于OLTP数据库这一领域来说,技术平民化已经实现了:小到搭建个人网站,大到构建大型服务,只要用户有需求存储数据,都会可能选择使用OLTP数据库。PostgreSQL、MySQL这类成熟的数据库早已被无数公司部署在生产环境中,而云上SaaS产品如Supabase、Neon等将PostgreSQL带到云上,并提供了一系列工具,让开发者可以使用小几十美金一个月的价格来搭建应用。
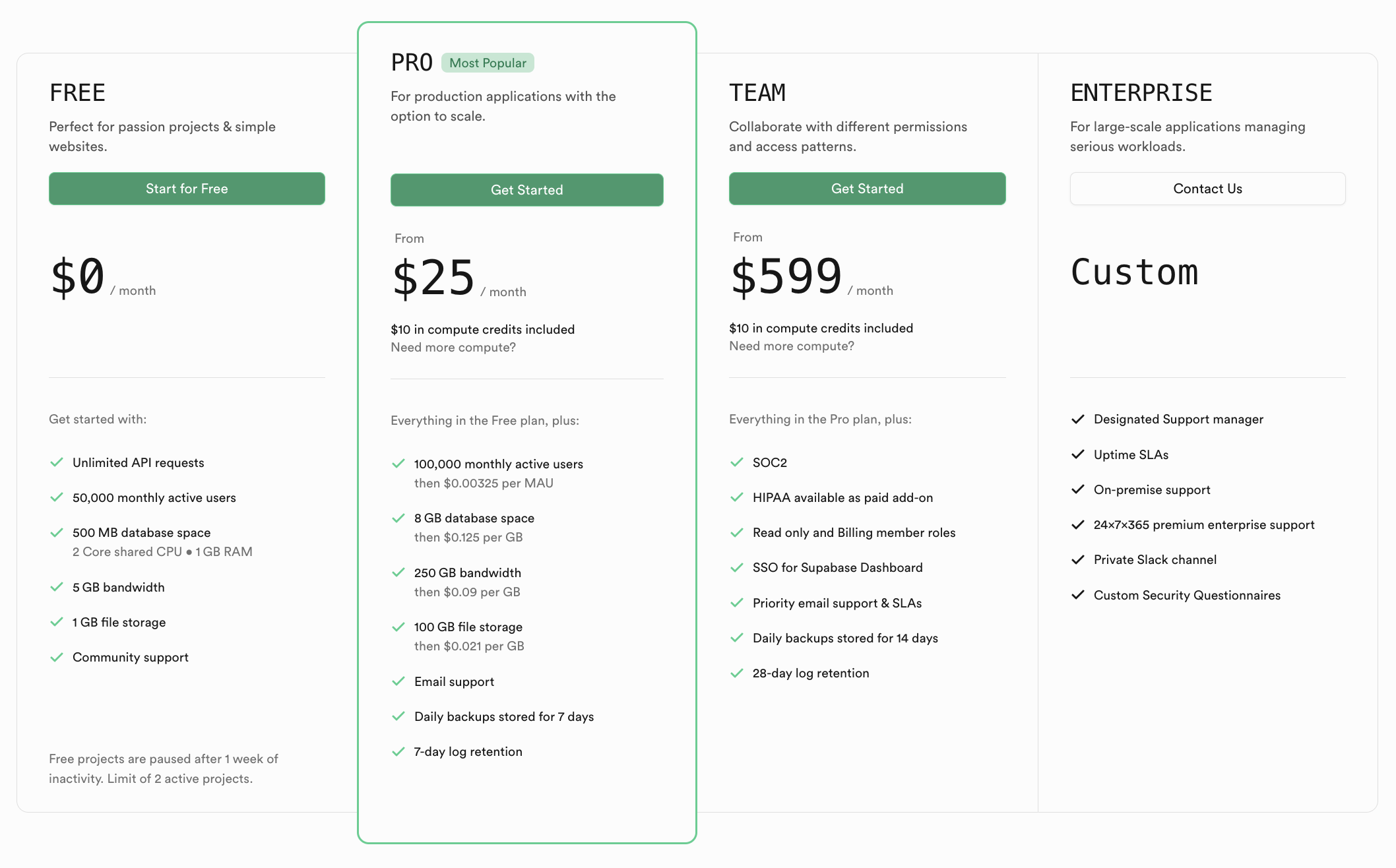 Supabase 的定价:个人开发者可以选择使用免费版本或者25美金一个月的服务。
Supabase 的定价:个人开发者可以选择使用免费版本或者25美金一个月的服务。
 Neon 的定价:个人开发者可以选择使用免费版本或者19或69美金一个月的服务。
Neon 的定价:个人开发者可以选择使用免费版本或者19或69美金一个月的服务。
对于OLAP数据库来说,技术平民化也正快速发展。当用户需要进行一定的数据统计与分析时,PostgreSQL等操作型数据库就难以胜任了。择如Snowflake、Redshift这样的数据仓库系统对开发者来说成本高且复杂。而如今,如ClickHouse这样的OLAP数据库,即便在单机环境下也能进行高效的数据分析。初创公司Tinybird基于ClickHouse搭建了无服务的计算平台,让大家可以以很低的价格进行数据分析。
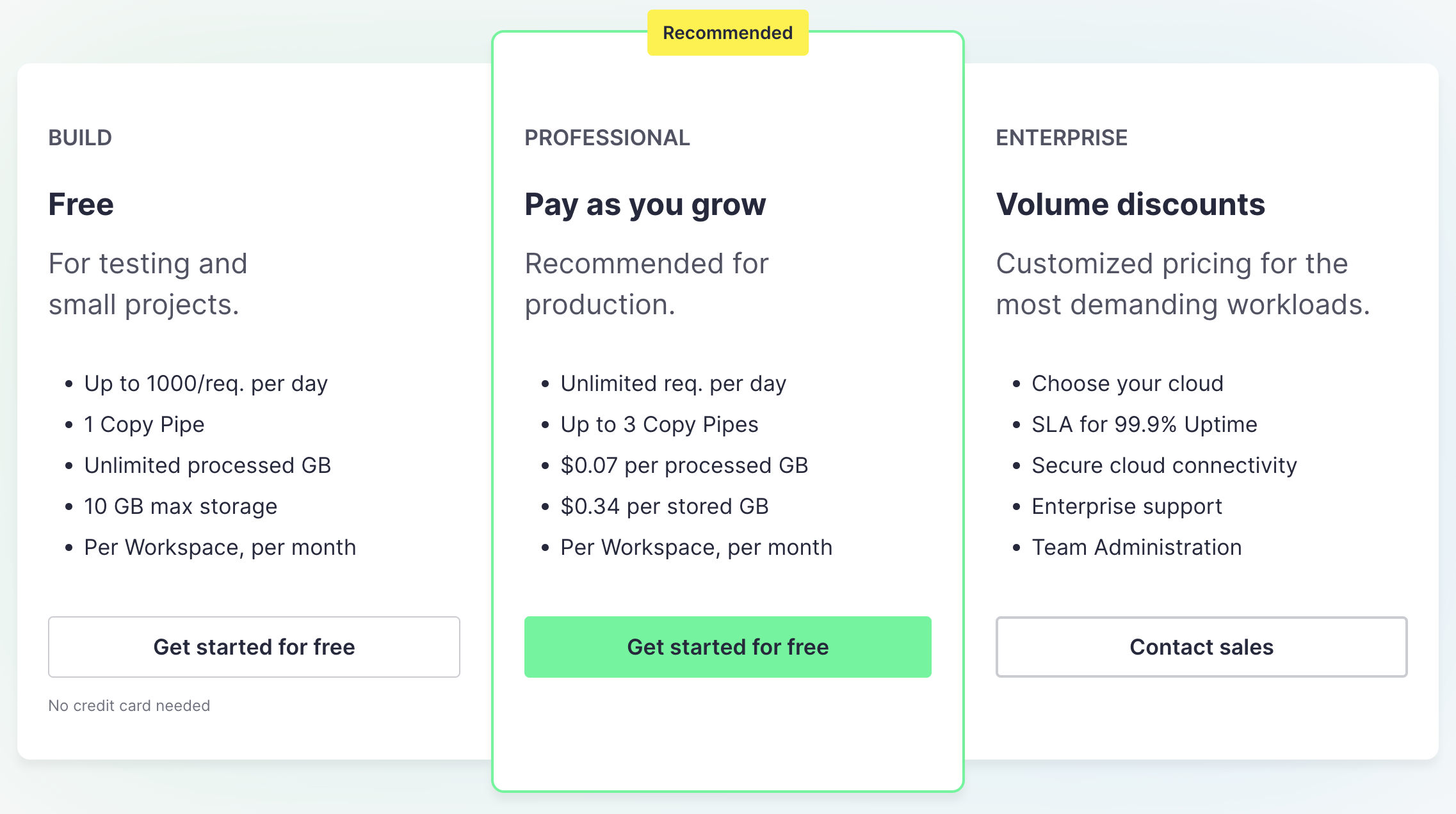 Tinybird的定价:个人开发者可以选择使用免费版本或者根据用量付费。
Tinybird的定价:个人开发者可以选择使用免费版本或者根据用量付费。
在OLTP与OLAP数据库这两个赛道中,我们都看到了同样的情况。流计算已经经历了二十多年的发展。然而,在这发展历程中,我们似乎并没有看到任何一个流计算产品真正下沉到开发者市场中,在个人开发者与中小型公司内部普及。我们如果看一下几个常见的流计算产品,无论是Spark Streaming还是Flink,目前更多应用在了有具有一定规模工程团队的科技公司中。对于个人或者小团队来说,部署使用这类大数据组件很显然门槛较高。可以想象一下,当一个小团队还在为构建产品雏形而加班加点的时候,几乎不可能有时间去考虑自己如何使用一套流计算框架。他们想要的仅仅是一个开箱即用的工具产品罢了。
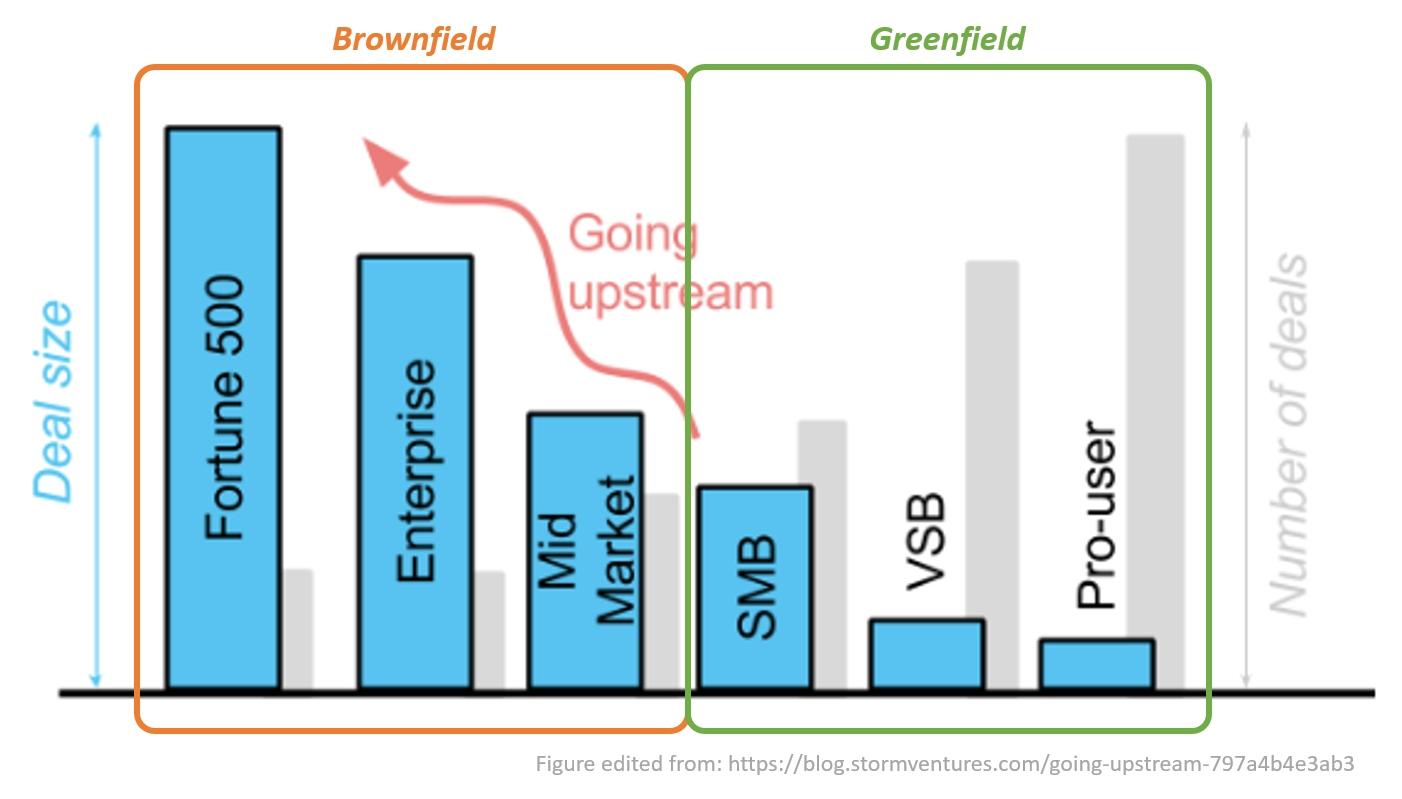 在流计算领域里,面向中小型企业与开发者的系统还是一片蓝海。
在流计算领域里,面向中小型企业与开发者的系统还是一片蓝海。
思考到这里,我们不难发现,在流计算领域,面向企业的流计算系统已经日渐饱和,形成了竞争激烈的红海。相反,针对开发者的流计算系统似乎仍是一片未被充分开发的蓝海。我们不禁会想,在2024年这个时间点上,让流计算平民化的时机是否已经成熟?
流计算的平民化:从用户角度分析
在当前的技术环境中,流计算的应用范围越来越广泛,但关键的问题在于:个人开发者和中小型企业是否真正需要流计算技术?从根本上来说,流计算适用的场景必须同时满足两个核心条件:首先,数据以流的形式不断被摄入系统;其次,用户需要对这些即时的数据流进行分析以提取信息。世界上的数据流的来源还是相对比较广泛的,包括但不限于:
-
网站上的用户行为日志(页面访问、点击等等)
-
IoT设备数据
-
社交媒体数据
-
金融交易数据
-
电商订单、支付数据
在这些领域中,如果有开发者希望开发新的产品,并且这些产品需要对数据进行及时的分析,那么就可能需要流计算技术。例如,如果我们希望从股票交易中监控某只股票的波动范围,或者从电子设备回传的数据中分析异常情况,那都是使用流计算技术的非常好的场景。
那么实时数据同步与实时ETL场景,是否也是可以被开发者所利用呢?虽然对开发者具有一定吸引力,但实际上门槛可能还是相对较高。这是因为实时数据同步或ETL通常涉及至少两个系统的协作,在引入流计算系统后,开发者需要同时维护三套系统。对于个人开发者或小型创业团队来说,这样的成本是相当高的,因此这可能并非一个理想的应用场景。
总的来说,我认为从用户角度分析,流计算平民化的前置条件是成立的。
流计算的平民化:从产品角度分析
我们接着从产品角度来分析。无论是个人开发者还是小的开发团队,都是希望将精力专注于快速开发迭代产品,而非研究底层数据系统架构。数据系统的定位就是工具,而工具就是为了给人以更好更快解决问题的手段。
当我们要开发一个面向开发者的数据系统时,我相信需要满足以下特征:
-
能单机部署,不依赖于Docker或Kubernetes等容器,如果能够做到嵌入式那是更好;
-
能提供all-in-one解决方案,不要求所有能力做到最好,但是需要提供各种能力:用户永远希望简化架构,而不希望把很多系统堆叠起来;
-
简单易用,上手门槛极低;
-
与各种其他开发者工具打通。
如果按照这一标准来寻找流计算系统,很显然我们在市面上的可选项极其有限了。幸运的是,RisingWave就是极个别能够满足所有选项的流计算系统。
流计算与批计算
我们讨论了这么多,其实最后又不得不会到一个老生常谈的问题:为什么需要流计算?用批计算不好吗?市面上不少批计算系统(尤其是OLAP数据库)都已经支持实时写入数据,那么为什么不直接使用批系统呢?我认为至少从三个方面来说,流计算系统拥有独一无二的优势:
-
对于一些应用来说,低延迟结果更新的要求强烈。对于金融交易、欺诈检测等场景来说,用户需要的往往是秒级甚至毫秒级的系统响应时间。对于这类应用来说,流计算也许是唯一的解法。OLAP数据库中带有的物化视图功能尽管能够解决部分功能,但面对带有大状态的复杂查询的时候,可能就力不从心了。
-
对于一些应用来说,增量计算带来的好处明显大于存量计算。流计算使用的是增量计算模型,不难想象,这种计算模型大大避免了不必要的重复计算,使得计算效率得到大幅提升。
-
对于一些应用来说,流计算的思考方式更加直观。对于IoT、金融等对于计算顺序有着强烈需求的场景来说,使用流计算更加符合正常思维方式,而批计算的计算反而可能“反直觉”。例如,如果我们想要不断监控过去10分钟内某只股票的平均价格,显然流计算的方式会更加容易被人接受。
当一个用户的使用场景满足这三个方面之一或更多时,我相信用户就可能会更加倾向于使用流计算系统。
RisingWave本地版的设计理念
未来总是充满未知。但与其等待答案,不如自己寻找答案。在RisingWave最新的1.7版本中,我们推出了面向开发者的RisingWave本地版。我们希望这一版本能够让RisingWave能够触及到广大开发者,让开发者能够在自己本地便享受到流计算带来的价值。
RisingWave本地版的设计理念很简单,便是“极简”。
安装部署简单
RisingWave本地版的最大特色之一便是安装部署极其简单。开发者能够通过简单的一行命令就在他们的本机电脑上(Mac或者Ubuntu)安装RisingWave:
curl https://risingwave.com/sh | sh
用户也不需要使用Kubernetes或Docker等容器,真正实现了裸机安装。对于关心程序体积的用户,我们还提供了一些编译选项,可以将程序大小压缩到约140MB。如果对这一大小还感到不满意,也欢迎与我们联系,商量一下更小打包的方案。
All-in-one
与Flink、Spark Streaming等传统流计算系统不同,RisingWave自带存储功能,也就是说,用户不再需要寻找一个所谓“下游数据库”来存储流计算结果。在支持流计算的同时,RisingWave也支持对存储在自身内部的数据进行随机查询。对于用户来讲,RisingWave实质实现了从计算到存储再到服务的所有功能。
上手门槛极低
RisingWave兼容的是PostgreSQL语法。用户可以直接写SQL语句便进行流计算,完全不需要学习Java/Scala等语言的API,更不需要了解如checkpoint、savepoint等系统内部细节。
丰富的系统集成
RisingWave支持了数十种常用系统与管理工具的集成。对于开发者常用的MySQL、PostgreSQL、MongoDB等数据库,RisingWave可以一条语句直接连接,免除中间消息队列等组件。感谢PostgreSQL的生态,RisingWave同样可以与Grafana、Superset、DBeaver、dbt等可视化、管理、建模等工具无缝集成,大幅提升用户体验。
后记
RisingWave本地版寄托着我们对流计算平民化的美好愿景,是我们对于流计算技术发展的一次探索。探索未知自然意味着风险与挑战。我们诚挚地希望读者们能够给予更多的支持,与我们携手共探未来的边界!
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于为用户提供极致简单、高效的流数据处理与管理能力。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,并助力用户极大地简化流计算架构,轻松搭建稳定且高效的流计算应用。RisingWave 始终聆听来自社区的声音,并积极回应用户的反馈。目前,RisingWave 已汇聚了近 150 名开源贡献者和近 3000 名社区成员。全球范围内,已有上百个 RisingWave 集群在生产环境中部署。
了解更多:
官网: risingwave.com
入门教程:快速上手 | RisingWave
GitHub:risingwave.com/github
微信公众号:RisingWave中文开源社区
中文社区用户交流群:risingwave_assistant
英文社区用户交流群:https://risingwave.com/slack