目录
1、分析主页作品列表标签结构
2、进入作品页前 判断作品是视频作品还是图文作品
3、进入视频作品页面,获取视频
4、进入图文作品页面,获取图片
5、完整参考代码
6、获取全部作品的一种方法
本文主要使用 selenium.webdriver(Firefox)、BeautifulSoup等相关库,在 centos 系统中,以无登录状态 进行网页爬取练习。仅做学习和交流使用。
安装和配置 driver 参考:
[1]: Linux无图形界面环境使用Python+Selenium最佳实践 - 知乎
[2]: 错误'chromedriver' executable needs to be in PATH如何解 - 知乎
1、分析主页作品列表标签结构

# webdriver 初始化
driver = webdriver.Firefox(options=firefox_options)# 设置页面加载的超时时间为6秒
driver.set_page_load_timeout(6)# 访问目标博主页面
# 如 https://www.douyin.com/user/MS4wLjABAAAAnq8nmb35fUqerHx54jlTx76AEkfq-sMD3cj7QdgsOiM
driver.get(target)# 分别等待 class='e6wsjNLL' 和 class='niBfRBgX' 的元素加载完毕再继续执行
#(等ul.e6wsjNLL加载完就行了)
# WebDriverWait(driver, 6) 设置最长的等待事间为 6 秒
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'e6wsjNLL')))
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'niBfRBgX')))# 在浏览器中执行脚本,滚动页面到最底部,有可能会显示更多的作品
driver.execute_script('document.querySelector(".wcHSRAj6").scrollIntoView()')
sleep(1)# 使用 beautifulsoup 解析页面源代码
html = BeautifulSoup(driver.page_source, 'lxml')# 关闭driver
driver.quit()# 获取作品列表
ul = html.find(class_='e6wsjNLL')# 获取每一个作品
lis = ul.findAll(class_='niBfRBgX')2、进入作品页前 判断作品是视频作品还是图文作品

element_a = li.find('a')
# a 标签下如果能找到 class = 'TQTCdYql' 的元素,
# 则表示该作品是图文,如果没有(则为None),则表示该作品是视频
is_pictures = element_a.find(class_='TQTCdYql')if (not is_pictures) or (not is_pictures.svg):# 视频作品pass
else:# 图文作品pass
3、进入视频作品页面,获取视频
# 拼接作品地址
href = f'https://www.douyin.com{element_a["href"]}'# 使用 webdriver 访问作品页面
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)# 等待 class='D8UdT9V8' 的元素显示后再执行(该元素的内容是作品的发布日期)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))html_v = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()# 获取该作品的发布时间
publish_time = html_v.find(class_='D8UdT9V8').string[5:]video = html_v.find(class_='xg-video-container').video
source = video.find('source')# 为该作品创建文件夹(一个作品一个文件夹)
# 以该作品的 发布时间 加 作品类型来命名文件夹
path = create_dir(f'{publish_time}_video')# 下载作品
download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')4、进入图文作品页面,获取图片

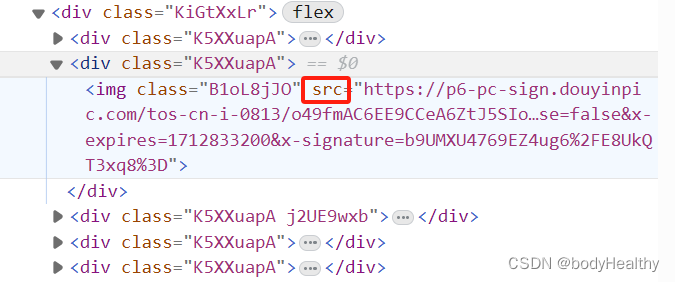
# 拼接作品页地址
href = f'https:{element_a["href"]}'# 使用webdriver访问作品页面
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)# 等待包含作品发表时间的标签加载完成
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))# 获取当前页面的源代码,关闭webdriver,交给beautifulsoup来处理
# (剩下的任务 继续使用webdriver也能完成)
html_p = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()# 获取该作品的发布时间
publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]# 图片列表
img_ul = html_p.find(class_='KiGtXxLr')
imgs = img_ul.findAll('img')# 为该作品创建文件夹,以作品的发布时间+作品类型+图片数量(如果是图片类型作品)
path = create_dir(f'{publish_time}_pictures_{len(imgs)}')# 遍历图片,获取url 然后下载
for img in imgs:download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')5、完整参考代码
# -*- coding: utf-8 -*-import threading,requests,os,zipfile
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from pyvirtualdisplay import Display
from time import sleep
from bs4 import BeautifulSoup
from selenium.common.exceptions import WebDriverExceptiondisplay = Display(visible=0, size=(1980, 1440))
display.start()firefox_options = Options()
firefox_options.headless = True
firefox_options.binary_location = '/home/lighthouse/firefox/firefox'# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 设置一个根路径,作品文件以及日志文件都保留在此
ABS_PATH = f'/home/resources/{get_current_time()}'# 创建目录,dir_name 是作品的发布时间,格式为:2024-02-26 16:59,需要进行处理
def create_dir(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'try:os.makedirs(path)except FileExistsError:print(f'试图创建已存在的文件, 失败({path})')else:print(f'创建目录成功 {path}')finally:return path# 下载 目录名称,当前文件的命名,下载的地址
def download_works(dir_name, work_name, src):response = requests.get(src, stream=True)if response.status_code == 200:with open(f'{dir_name}/{work_name}', mode='wb') as f:for chunk in response.iter_content(1024):f.write(chunk)# 判断作品是否已经下载过
def test_work_exist(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn Falsedef get_all_works(target):try:driver = webdriver.Firefox(options=firefox_options)driver.set_page_load_timeout(6)# 目标博主页面driver.get(target)WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'e6wsjNLL')))WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'niBfRBgX')))driver.execute_script('document.querySelector(".wcHSRAj6").scrollIntoView()')sleep(1)html = BeautifulSoup(driver.page_source, 'lxml')driver.quit()# 作品列表ul = html.find(class_='e6wsjNLL')# 每一个作品lis = ul.findAll(class_='niBfRBgX')for li in lis:element_a = li.find('a')is_pictures = element_a.find(class_='TQTCdYql')if (not is_pictures) or (not is_pictures.svg):href = f'https://www.douyin.com{element_a["href"]}'temp_driver = webdriver.Firefox(options=firefox_options)temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))# 不是必须,剩余内容webdriver也能胜任html_v = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()# 获取该作品的发布时间publish_time = html_v.find(class_='D8UdT9V8').string[5:]# if test_work_exist(f'{publish_time}_video'):# continuevideo = html_v.find(class_='xg-video-container').videosource = video.find('source')# 为该作品创建文件夹path = create_dir(f'{publish_time}_video')# 下载作品download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')else:href = f'https:{element_a["href"]}'temp_driver = webdriver.Firefox(options=firefox_options)temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))# 使用 beautifulsoup 不是必须html_p = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]# 图片列表img_ul = html_p.find(class_='KiGtXxLr')imgs = img_ul.findAll('img')# if test_work_exist(f'{publish_time}_pictures_{len(imgs)}'):# continuepath = create_dir(f'{publish_time}_pictures_{len(imgs)}')for img in imgs:download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')display.stop()print('##### finish #####')except WebDriverException as e: print(f"捕获到 WebDriverException: {e}") except Exception as err:print("捕获到其他错误 get_all_works 末尾")print(err)finally:driver.quit()display.stop()# 将目录进行压缩
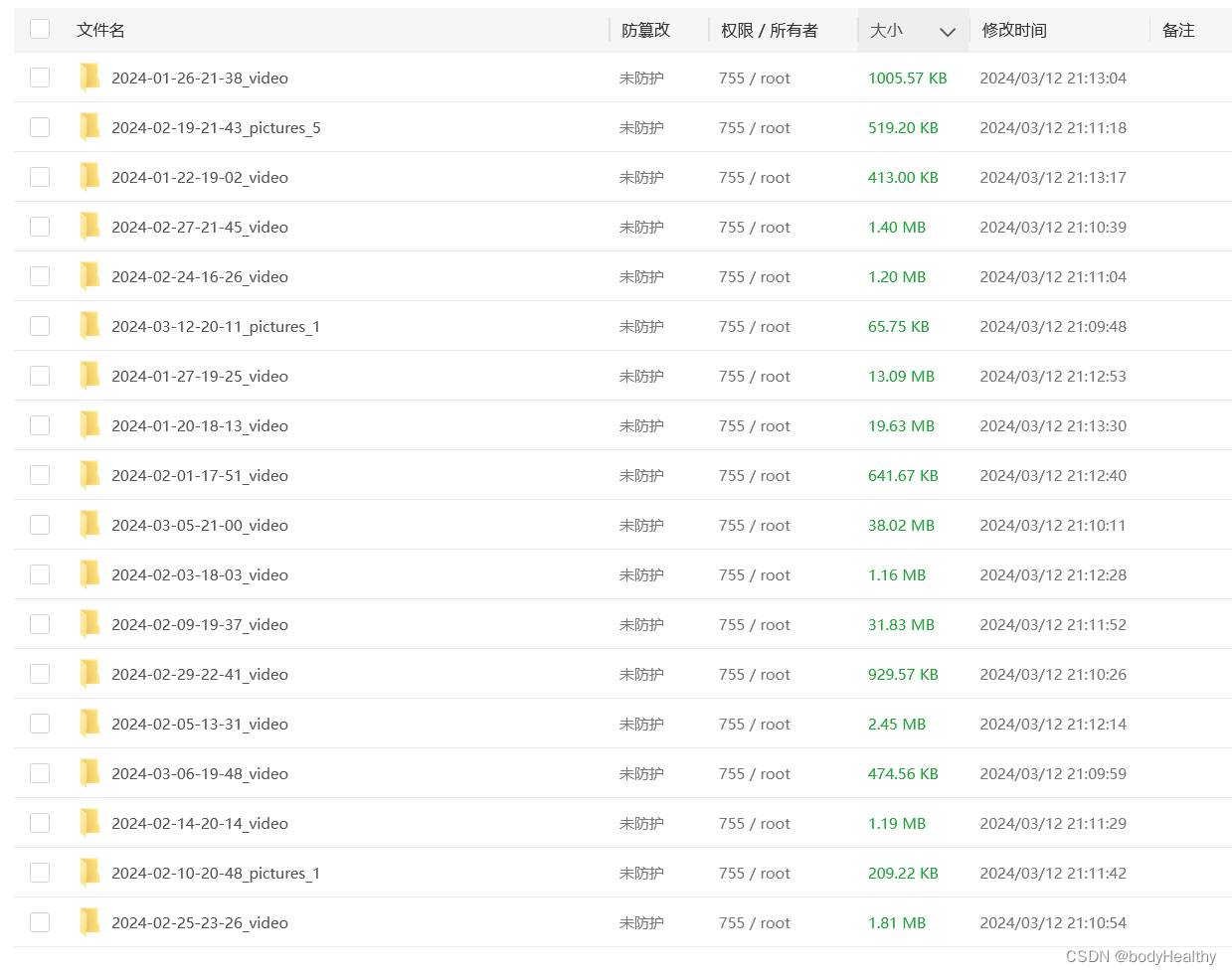
def zipdir(path, ziph):# ziph 是 zipfile.ZipFile 对象for root, dirs, files in os.walk(path):for file in files:ziph.write(os.path.join(root, file),os.path.relpath(os.path.join(root, file), os.path.join(path, '..')))def dy_download_all(target_url):get_all_works(target_url)directory_to_zip = ABS_PATH # 目录路径output_filename = f'{ABS_PATH}.zip' # 输出ZIP文件的名称with zipfile.ZipFile(output_filename, 'w', zipfile.ZIP_DEFLATED) as zipf:zipdir(directory_to_zip, zipf)return f'{ABS_PATH}.zip' # 返回下载地址if __name__ == '__main__':# 简单测试url = input('请输入博主主页url:')path = dy_download_all(url)print('下载完成')print(f'地址:{path}')测试结果:

6、获取全部作品的一种方法
上述的操作是在无登录状态下进行的,即使在webdriver中操作让页面滚动,也只能获取到有限的作品,大约是 20 项左右。对此提出一个解决方案。
以登录状态(或者有cookies本地存储等状态)访问目标博主页面,滚动到作品最底部,然后在控制台中执行JavaScript脚本,获取全部作品的信息(在这里是作品链接以及作品类型),然后写出到文本文件中。

JavaScript 代码:
let ul = document.querySelector('.e6wsjNLL');// 存放结果
works_list = [];// 遍历,每一次都加入一个对象,包括作品页的地址、作品是否为图片作品
ul.childNodes.forEach((e)=>{let href = e.querySelector('a').href;let is_pictures = e.querySelector('a').querySelector('.TQTCdYql') ? true : false;works_list.push({href, is_pictures})
})// 创建一个Blob对象,包含要写入文件的内容
var content = JSON.stringify(works_list);
var blob = new Blob([content], {type: "text/plain;charset=utf-8"}); // 创建一个链接元素
var link = document.createElement("a"); // 设置链接的href属性为Blob对象的URL
link.href = URL.createObjectURL(blob); // 设置链接的下载属性,指定下载文件的名称
link.download = "example.txt"; // 触发链接的点击事件,开始下载文件
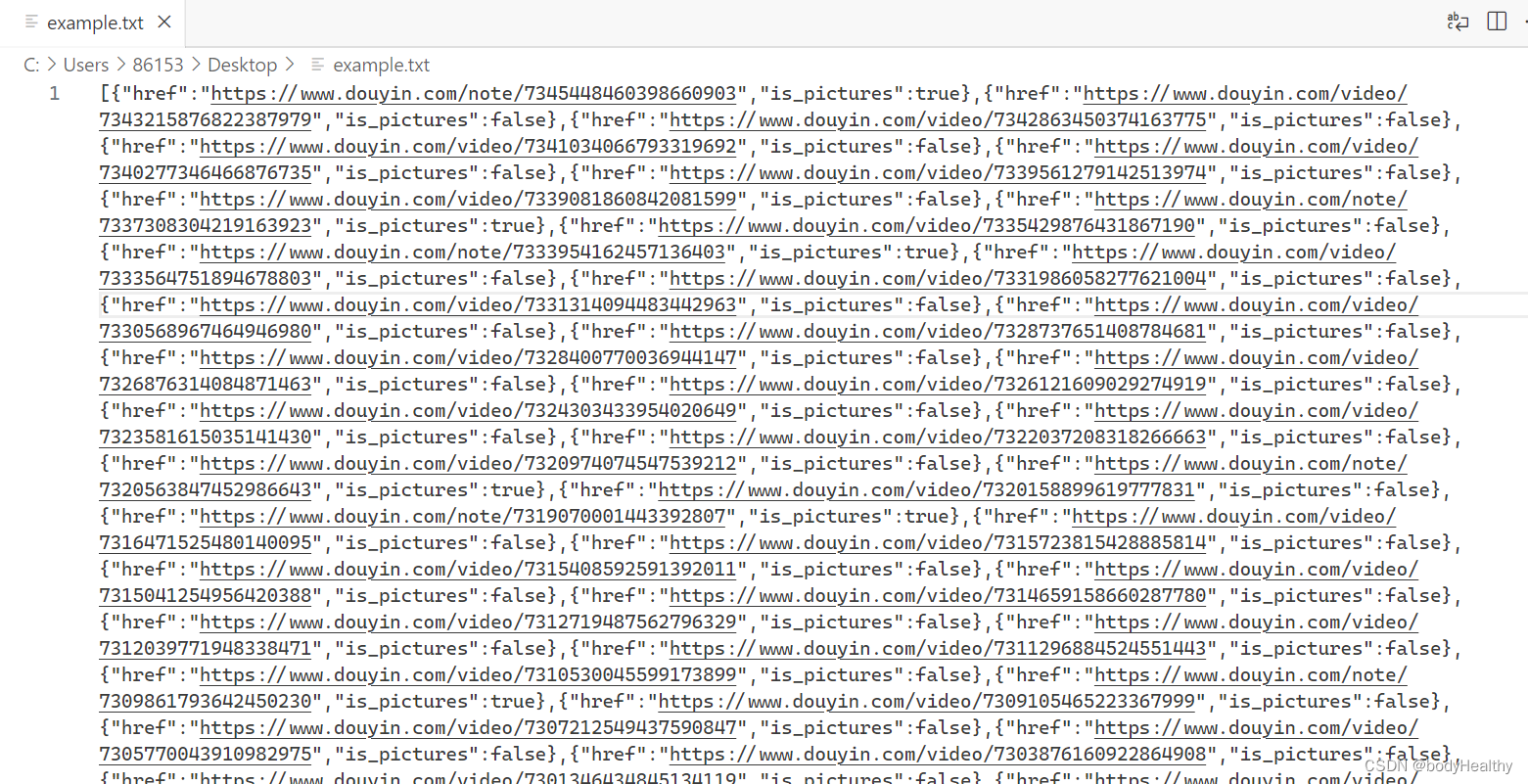
link.click();写出结果:
列表中的每一个元素都是一个对象,href 是作品的地址,is_pictures 以 boolean 值表示该作品是否为图片作品
然后在 python 中读入该文件,使用 json 解析,转成字典列表的形式,遍历列表,对每一个字典(就是每一个作品)进行处理即可。
示例代码:
win 环境下
import json
import threading,requests,os
from bs4 import BeautifulSoup
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from datetime import datetime
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 设置一个根路径,作品文件以及日志文件都保留在此
ABS_PATH = f'F:\\{get_current_time()}'# 创建目录,dir_name 是作品的发布时间,格式为:2024-02-26 16:59,需要进行处理
def create_dir(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'try:os.makedirs(path)except FileExistsError:print(f'试图创建已存在的文件, 失败({path})')else:print(f'创建目录成功 {path}')finally:return path# 下载 目录名称,当前文件的命名,下载的地址
def download_works(dir_name, work_name, src):response = requests.get(src, stream=True)if response.status_code == 200:with open(f'{dir_name}/{work_name}', mode='wb') as f:for chunk in response.iter_content(1024):f.write(chunk)# 判断作品是否已经下载过
def test_work_exist(dir_name):dir_name = dir_name.replace(' ', '-').replace(':', '-')path = f'{ABS_PATH}/{dir_name}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn False# 下载一个作品
def thread_task(ul):for item in ul:href = item['href']is_pictures = item['is_pictures']if is_pictures:temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))# 使用 beautifulsoup 不是必须html_p = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]# 图片列表img_ul = html_p.find(class_='KiGtXxLr')imgs = img_ul.findAll('img')# if test_work_exist(f'{publish_time}_pictures_{len(imgs)}'):# continuepath = create_dir(f'{publish_time}_pictures_{len(imgs)}')for img in imgs:download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')else:temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(6)temp_driver.get(href)WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))# 不是必须,剩余内容webdriver也能胜任html_v = BeautifulSoup(temp_driver.page_source, 'lxml')temp_driver.quit()# 获取该作品的发布时间publish_time = html_v.find(class_='D8UdT9V8').string[5:]# if test_work_exist(f'{publish_time}_video'):# continuevideo = html_v.find(class_='xg-video-container').videosource = video.find('source')# 为该作品创建文件夹path = create_dir(f'{publish_time}_video')# 下载作品download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')if __name__ == '__main__':content = ''# 外部读入作品链接文件with open('../abc.txt', mode='r', encoding='utf-8') as f:content = json.load(f)length = len(content)if length <= 3 :thread_task(content)else:# 分三个线程ul = [content[0: int(length / 3) + 1], content[int(length / 3) + 1: int(length / 3) * 2 + 1],content[int(length / 3) * 2 + 1: length]]for child_ul in ul:thread = threading.Thread(target=thread_task, args=(child_ul,))thread.start()