🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
1 NVIDIA Driver and CUDA cuDNN安装配置
2 TensorRT安装配置
2.1 版本对应
2.2 环境配置解压后进入TensorRT根目录:
2.3 安装python包
2.4 测试
3 训练
1 NVIDIA Driver and CUDA cuDNN安装配置
这三者安装安装顺序是GPU Driver->CUDA->cuDNN,可以参考CUDA环境配置在Ubuntu18
注意:版本要对应
2 TensorRT安装配置
2.1 版本对应
笔者CUDA为12.1.1 因此需要找到对应的TensorRT,官网TensorRT官网
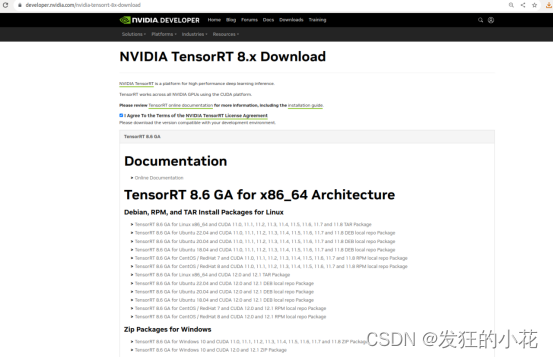
2.2 环境配置
解压后进入TensorRT根目录:
(1)环境变量
vi ~/.bashrc
在文件末尾添加一行代码:
export LD_LIBRARY_PATH=/home/hubery/lib/TensorRT-8.6.1.6/lib:$LD_LIBRARY_PATH
关闭保存
source ~/.bashrc(2)复制文件到系统路径
把TensorRT根目录中的/lib/下面的文件复制到 /usr/lib/下,
把TensorRT根目录中的/include/下面的文件复制到 /usr/include/下
2.3 安装python包
进入TensorRT根目录下的python/目录下
可以看到多个版本的python包。
因为我之前安装的是python3.10版,所以选择安装文件tensorrt_dispatch-8.6.1-cp310-none-linux_x86_64.whl
执行安装命令:
pip install --force-reinstall tensorrt_dispatch-8.6.1-cp310-none-linux_x86_64.whl
2.4 测试
执行无报错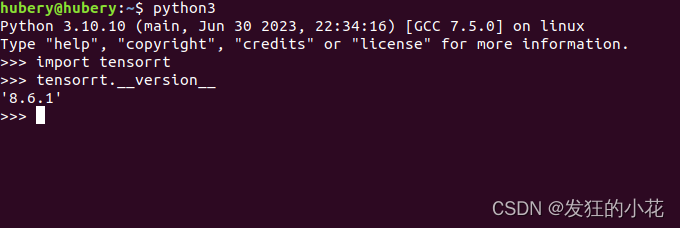
3 TensorFlow 安装配置
3.1 GPU版本
pip3 install tensorflow-gpu==2.10.03.2 CPU版本
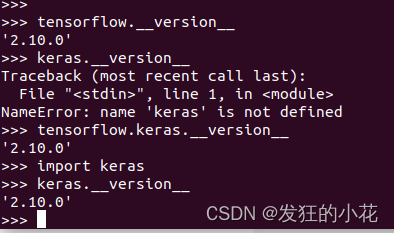
pip3 install tensorflow==2.10.0一般安装TensorFlow时会自动安装keras,如果没有,可以单独安装
pip3 install keras3.3 测试
3 训练
代码来自从零入门 AI 视觉:历时 3 个月,我的代码仓库开源了
# 导入NumPy数学工具箱
import numpy as np
# 导入Pandas数据处理工具箱
import pandas as pd
# 从 Keras中导入 mnist数据集
from keras.datasets import mnist(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data() # 导入keras.utils工具箱的类别转换工具
from tensorflow.keras.utils import to_categorical
# 给标签增加维度,使其满足模型的需要
# 原始标签,比如训练集标签的维度信息是[60000, 28, 28, 1]
X_train = X_train_image.reshape(60000,28,28,1)
X_test = X_test_image.reshape(10000,28,28,1)# 特征转换为one-hot编码
y_train = to_categorical(y_train_lable, 10)
y_test = to_categorical(y_test_lable, 10)# 从 keras 中导入模型
from keras import models
# 从 keras.layers 中导入神经网络需要的计算层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
# 构建一个最基础的连续的模型,所谓连续,就是一层接着一层
model = models.Sequential()
# 第一层为一个卷积,卷积核大小为(3,3), 输出通道32,使用 relu 作为激活函数
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28,28,1)))
# 第二层为一个最大池化层,池化核为(2,2)
# 最大池化的作用,是取出池化核(2,2)范围内最大的像素点代表该区域
# 可减少数据量,降低运算量。
model.add(MaxPooling2D(pool_size=(2, 2)))
# 又经过一个(3,3)的卷积,输出通道变为64,也就是提取了64个特征。
# 同样为 relu 激活函数
model.add(Conv2D(64, (3, 3), activation='relu'))
# 上面通道数增大,运算量增大,此处再加一个最大池化,降低运算
model.add(MaxPooling2D(pool_size=(2, 2)))
# dropout 随机设置一部分神经元的权值为零,在训练时用于防止过拟合
# 这里设置25%的神经元权值为零
model.add(Dropout(0.25))
# 将结果展平成1维的向量
model.add(Flatten())
# 增加一个全连接层,用来进一步特征融合
model.add(Dense(128, activation='relu'))
# 再设置一个dropout层,将50%的神经元权值为零,防止过拟合
# 由于一般的神经元处于关闭状态,这样也可以加速训练
model.add(Dropout(0.5))
# 最后添加一个全连接+softmax激活,输出10个分类,分别对应0-9 这10个数字
model.add(Dense(10, activation='softmax'))# 编译上述构建好的神经网络模型
# 指定优化器为 rmsprop
# 制定损失函数为交叉熵损失
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])# 开始训练
model.fit(X_train, y_train, # 指定训练特征集和训练标签集validation_split = 0.3, # 部分训练集数据拆分成验证集epochs=5, # 训练轮次为5轮batch_size=128) # 以128为批量进行训练# 在测试集上进行模型评估
score = model.evaluate(X_test, y_test)
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率# 预测验证集第一个数据
pred = model.predict(X_test[0].reshape(1, 28, 28, 1))
# 把one-hot码转换为数字
print(pred[0],"转换一下格式得到:",pred.argmax())# 导入绘图工具包
import matplotlib.pyplot as plt
# 输出这个图片
plt.imshow(X_test[0].reshape(28, 28),cmap='Greys')
执行结果:

🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!