文章目录
- 什么是Spark
- 对比Hadoop
- Spark应用场景
- Spark数据处理流程
- 什么是RDD
- Spark架构相关进程
- 入门案例:统计单词数量
- Spark开启historyServer
什么是Spark
- Spark是一个用于大规模数据处理的统一计算引擎
- Spark一个重要的特性就是基于内存计算,从而它的速度可以达到MapReduce的几十倍甚至百倍
对比Hadoop
- Spark是一个综合性质的计算引擎,Hadoop既包含Mapreduce(计算)还包含HDFS(存储)和YARN(资源管理),两个框架定位不同,从综合能力来说Hadoop更胜一筹
- 计算模型:Spark任务可以包含多个计算操作,轻松实现复杂迭代计算,Hadoop中的mapreduce任务只包含Map和Reduce阶段,不够灵活
- 处理速度:Spark任务的数据是存放在内存里面的,而Hadoop中的MapReduce任务是基于磁盘的
在实际工作中Hadoop会作为一个提供分布式存储和分布式资源管理的一个角色存在,Spark会依赖于Hadoop去做计算。
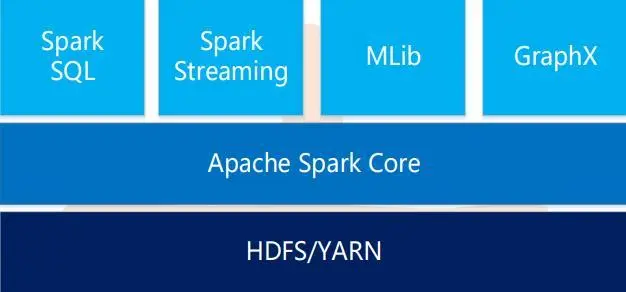
Spark应用场景
- 低延时的海量数据计算需求
- 低延时的SQL交互查询需求
- 准实时计算需求
Spark数据处理流程

什么是RDD
- 通常通过Hadoop上的文件,即HDFS文件进行创建,也可以通过程序中的集合来创建
- 是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集
- 弹性:RDD数据在默认的情况下存放内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入磁盘
- RDD在抽象上来说是一种元素数据的集合,它是被分区的,每个分区分布在集群中的不同节点上,从而RDD中的数据可以被并行操作
- 容错性:最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来。比如某个节点的数据由于故障导致分区的数据丢了,RDD会自动通过数据来源重新计算数据
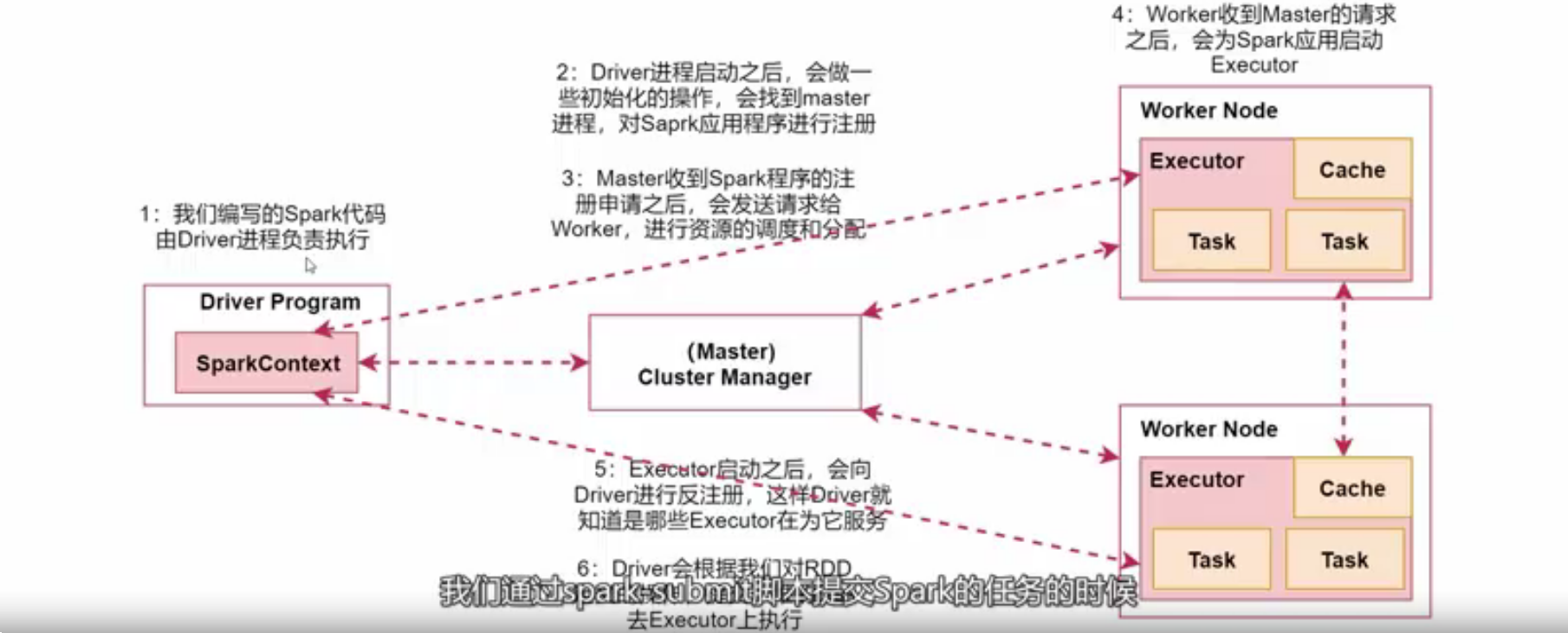
Spark架构相关进程
- Driver:我们编写的Spark程序由Driver进程负责执行
- Master:集群的主节点中启动的进程
- Worker:集群的从节点中启动的进程
- Executor:由Worker负责启动的进程,执行数据处理和数据计算
- Task:由Executor负责启动的线程,是真正干活的
入门案例:统计单词数量
# scala 代码
object WordCountScala {def main(args: Array[String]): Unit = {val conf = new SparkConf();conf.setAppName("wordCount").setMaster("local")val context = new SparkContext(conf);val linesRDD = context.textFile("D:\\hadoop\\logs\\hello.txt");var wordsRDD = linesRDD.flatMap(line => line.split(" "))val pairRDD = wordsRDD.map(word => (word, 1))val wordCountRDD = pairRDD.reduceByKey(_ + _)wordCountRDD.foreach(wordCount => println(wordCount._1 + "---" + wordCount._2))context.stop()}
}public class WordCountJava {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setAppName("worldCount").setMaster("local");JavaSparkContext javaSparkContext = new JavaSparkContext();JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("D:\\hadoop\\logs\\hello.txt");// 数据切割,把一行数据拆分为一个个的单词// 第一个是输入数据类型,第二个是输出数据类型JavaRDD<String> wordRDD = stringJavaRDD.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split(" ")).iterator();}});// 迭代word,装换成(word,1)这种形式// 第一个是输入参数,第二个是输出第一个参数类型,第三个是输出第二个参数类型JavaPairRDD<String, Integer> pairRDD = wordRDD.mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<>(word, 1);}});// 根据key进行分组聚合JavaPairRDD<String, Integer> wordCountRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}});// 输出控制台wordCountRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {@Overridepublic void call(Tuple2<String, Integer> tuple2) throws Exception {System.out.println(tuple2._1 + "=:=" + tuple2._2);}});javaSparkContext.stop();}}Spark开启historyServer
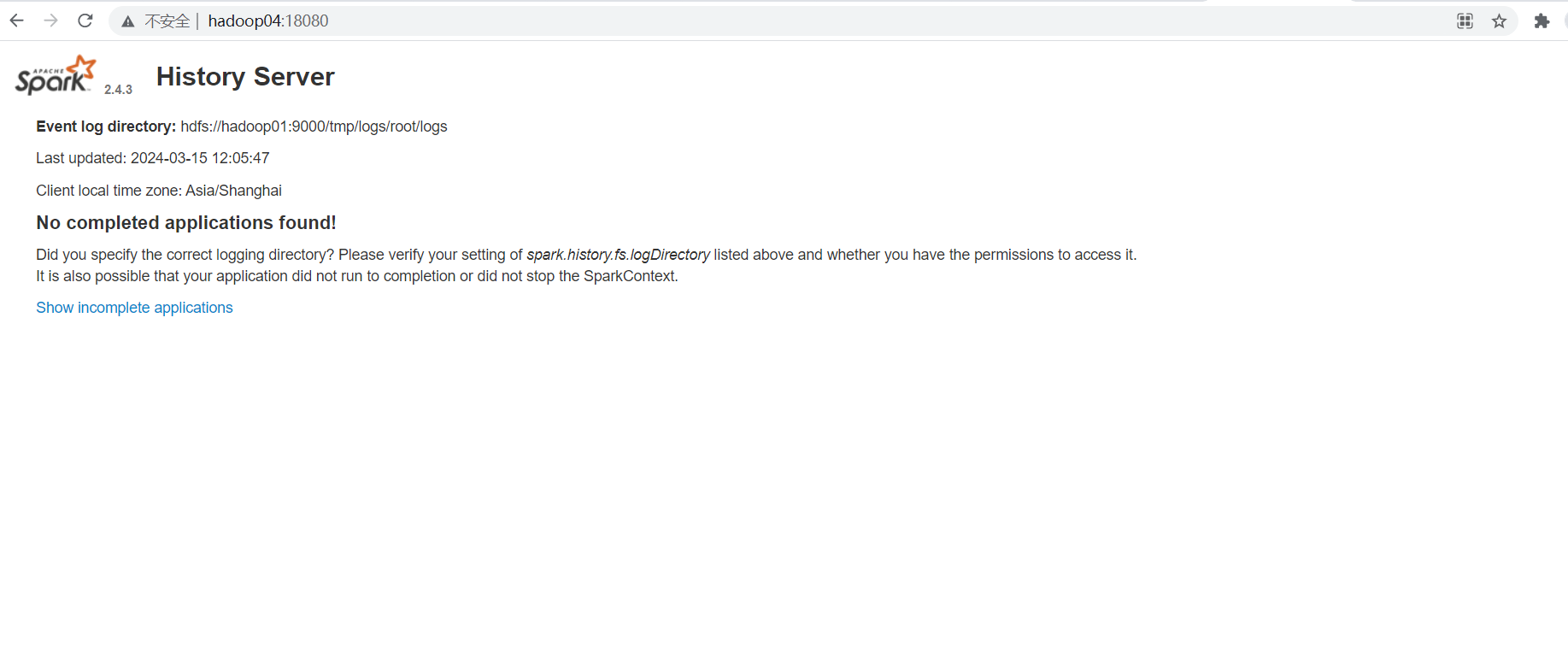
[root@hadoop04 conf]# vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/tmp/logs/root/logs"[root@hadoop04 conf]# vim spark-defaults.conf
spark.eventLof.enable=true
spark.eventLog.compress=true
spark.eventLog.dir=hdfs://hadoop01:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://hadoop01:9000/tmp/logs/root/logs# 启动
[root@hadoop04 conf]# sbin/start-history-server.sh # 访问
http://hadoop04:18080/