孤客python学习思路
- python学习从入门到精通
- 前言
- 预备知识
- Python简介
- 程序设计思想
- 导入python资源包
- 用户体验模块
- 获得A和B的能力值与场次模块
- 模拟n局比赛模块
- 判断比赛结束条件
- 模拟n次单局比赛=模拟n局比赛
- 打印结果模块
- 安装Python
- 运行方式
- 常用开发工具
- 编码规范
- 模块管理
python学习从入门到精通
前言
利用框架的力量,看懂游戏规则,才是入行的前提
大多数人不懂,不会,不做,才是你的机会,你得行动,不能畏首畏尾
选择才是拉差距的关键,风向,比你流的汗水重要一万倍,逆风划船要累死人的
为什么选择学习Python语言,不选择Java语言?
借棋弈做比喻,智商高的不要选择五子琪,要选择围棋,它能长久地吸引你。
不都是在棋盘上一颗黑了颗白子地下吗?因为围棋更复杂,能够掌握如此复杂的技艺、产生稳定输出的棋手、让我们更佩服,选择学习大数据开发也如此,能让你的职业生泪走得更远,少走弯路。
这个栏目为初学者全面整理入门Python必学知识,内容是按照体系划分的,集合190多篇高质量文章带你认识Python,掌握入门的规则。
只要跟着顺序去学,把里面的体系知识掌握了,你才能真正的入门大数据,前提得自律加坚持,赶快行动吧。
预备知识
Python简介

1 Python简介
Python 是一种简单易学并且结合了解释性、编译性、互动性和面向对象的脚本语言。Python提供了高级数据结构,它的语法和动态类型以及解释性使它成为广大开发者的首选编程语言。
- Python 是解释型语言: 开发过程中没有了编译这个环节。类似于PHP和Perl语言。
- Python 是交互式语言: 可以在一个 Python 提示符 >>> 后直接执行代码。
- Python 是面向对象语言: Python支持面向对象的风格或代码封装在对象的编程技术。
2 Python发展史
2.1 Python的发展
Python的创始人为Guido van Rossum。1989年,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,做为ABC 语言的一种继承。
Python 是由其他语言发展而来的,其中主要包括 ABC、Modula-3、C、C++、SmallTalk、Unix shell 等。
自从2004年以后,python的使用率呈线性增长。

Python 2于2000年10月16日发布,稳定版本是Python 2.7。Python 3于2008年12月3日发布,不完全兼容Python 2。2011年1月,它被TIOBE编程语言排行榜评为2010年度语言。

2.2 Python的版本更新
目前python发布的版本过程主要包括如下:
| 发布年份 | 版本 |
|---|---|
| … | … |
| 发布年份 | 版本 |
| ------ | – |
| March 24, 2022 | 3.10.4 |
| 2023 | 3.11 |
| – | – |
| 2024 | 3.12 |
| … | … |
| – | – |
| … | … |
目前python 的最新版本已经达到3.10.4,因此可见版本更新之快。

2.1 Python2.0与Python3.0的区别
- 输出方面
Python2.0 使用print关键字进行输出,比如:print “Hello”;
Python3.0 使用print()函数,比如:print(“Hello”)。
- 输入方面
Python2.0 使用raw_input()函数,比如:name=raw_input(“请输入你的名字:”);
Python3.0 使用input()函数,比如:name=input(“请输入你的名字:”)。
- 字符串的编码格式
Python2.0 默认采用ASCII编码对输入的字符串进行编码;
Python3.0 默认采用Unicode编码对字符串进行编码。
- 格式化字符串的方式
Python2.0 用%占位符进行标准化格式输出字符串,比如:“Hello,%s" % (“World”);
Python3.0 用format()函数,比如:”Hello,{}“.format(“World”)。
- 源文件的编码格式
Python2.0 默认采用ASCII,因此使用中文时要在源文件开头加上一行注释:# – coding: utf-8 --;
Python3.0 默认采用utf-8。
- 数据类型
python2.0 有整型int、长整型long
python3.0 只有整型int
- 代码规范
python 2.0 源码不规范,重复代码很多
python 3.0 源码精简,美观、优雅
3 Python编译和运行过程
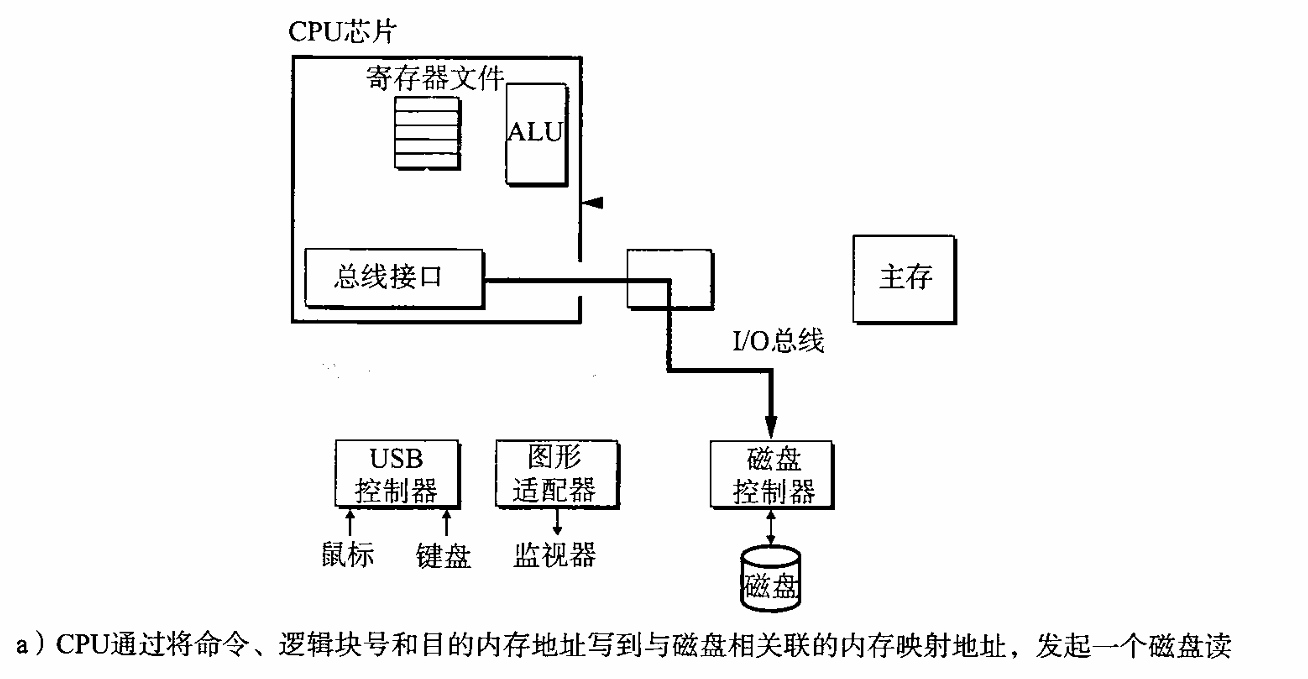
虽然Python源代码文件(.py)可以直接使用Python命令运行,但实际上Python并不是直接解释Python源代码,它是具有一个编译和运行的过程,具体过程如下图:

首先将Python源代码(.py文件)编译生成Python字节码(Python Byte
Code,字节码文件的扩展名一般是.pyc),然后再由Python虚拟机(Python Virtual
Machine,简称PVM)来执行Python字节码,最后在终端输出运行结果。
通过以上编译和运行过程可分析:Python是一种解释型语言,指的是解释Python字节码,而不是Python源代码。这种机制的基本思想与Java和.NET是一致的。
3.1 Python解释器
Python解释器(Interpreter)是把Python语言翻译成计算机 CPU 能听懂的机器指令。
首先可以在命令提示行输入python --version来查看python的版本:
$ python --version
Python 3.7.4
然后在命令提示符中输入"Python"命令来启动Python解释器:
$ python
执行以上命令后,出现如下信息:
$ python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
Python解释器易于扩展,可以通过调用C语言或C++来扩展新功能和数据类型。
3.2 Python解释器种类
Cpython:用C语言开发的,在命令行下运行Python就是启动Cpython解释器,官方下载的python2.7均为Cpython。Cpython用>>>作为提示符。
Ipython:基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。IPython用In [序号]:作为提示符。
PyPy:主要针对执行速度。采用JIT技术,对Python代码进行动态编译。绝大部分Python代码都可以在PyPy下运行。
Jpython:运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython:运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
Boost.Python:使得Python和C++的类库可互相调用(.pyc)。
3.3 Python虚拟机
python并不将py文件编译为机器码来运行,而是由python虚拟机一条条地将py语句解释运行,python虚拟机的执行方式就是模仿普通x86可执行文件运行方式。
虚拟机输入为字节码.pyc文件,由字节码文件加载器将二进制的.pyc文件加载到内存,由执行引擎解释执行,输出为字节码文件的执行结果。
3.4 Python字节码(.pyc)
Python中的字节码(bytecode) 是一种数据类型, Python代码的编译结果就是bytecode对象。bytecode对象可以由虚拟机加载后直接运行,而pyc文件就是bytecode在硬盘上的保存形式。
假如有个test.py文件需要执行,那么它会先生成.pyc文件,一般可能的情况如下:
- 执行 python test.py 会对test.py进行编译成字节码并解释执行,但不会生成test.pyc。
- 如果test.py中加载了其他模块,如import
urllib2,那么python会对urllib2.py进行编译成字节码,生成urllib2.pyc,然后对字节码解释执行。 - 如果想生成test.pyc,可以使用python内置模块py_compile来编译,也可以执行命令 python -m
py_compile test.py 这样,就生成了test.pyc。 - 加载模块时,如果同时存在.py和.pyc,python会使用.pyc运行,如果.pyc的编译时间早于.py的时间,则重新编译
.py文件,并更新.pyc文件。
4 Python的应用
Python的应用主要有以下领域:
- Linux/UNIX运维:提供API(Application ProgrammingInterface应用程序编程接口),能方便进行系统维护和管理。
- GUI程序开发(PyQt、Kivy等)
- Web程序开发(Django、Flask等框架):支持最新的XML技术。
- 移动App开发(PyQt、Kivy等):Python的PyOpenGL模块封装了“OpenGL应用程序编程接口”,能进行二维和三维图像处理。PyGame模块可用于编写游戏软件。
- 网络爬虫(为搜索引擎、深度学习等领域提供数据源)
- 网络编程(基于Socket等协议):提供丰富的模块支持sockets编程,能方便快速地开发分布式应用程序。很多大规模软件开发计划例如Zope,Mnet
及BitTorrent. Google都在广泛地使用它。 - 图形处理:有PIL、Tkinter等图形库支持,能方便进行图形处理。
- 文本处理:python提供的re模块能支持正则表达式,还提供SGML,XML分析模块,许多程序员利用python进行XML程序的开发。
- 数据库编程:可通过遵循Python DB-API(数据库应用程序编程接口)规范的模块与Microsoft SQL
Server,Oracle,Sybase,DB2,Mysql、SQLite等数据库通信。python自带有一个Gadfly模块,提供了一个完整的SQL环境。 - 数据科学:NumPy扩展提供大量与许多标准数学库的接口。机器学习(scikit-learn、TensorFlow框架)、数据统计分析和可视化(Matplotlib、seaborn框架)。
python应用举例: Google -谷歌在很多项目中用python作为网络应用的后端,如Google Groups、Gmail、Google Maps等 NASA - 美国宇航局,从1994年起把python作为主要开发语言 豆瓣网 - 图书、唱片、电影等文化产品的资料数据库网站 Torchlight --Python编写的大型3D游戏,原Blizzard公司人员制作发行,开源 Blender - 以C与Python开发的开源3D绘图软件 在科学研究中也得到广泛的应用
5 Python的特点
- 简单易读易学:Python是非常简单的语言,并且具有清晰的风格和强制缩进,Python具有简单的语法,极其容易入门。
- 免费其开源:Python是自由/开放源码的软件。可以自行对其源代码进行修改使用。
- 可移植性:Python可以被移植在许多平台上,常用的平台包括Linux、Windows、VxWorks、PlayStation、Windows
CE、PocketPC等。 - 解释性: Python解释器把源代码转换成字节码,然后再把它翻译成计算机使用的机器语言并运行,即Python代码在运行之前不需要编译。
- 面向对象:Python支持面向对象的编程。程序通过组合(composition)与继承(inheritance)的方式定义类(class)。
- 可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,那么可以将部分程序用C或C++进行编写,然后在Python程序中调用。
- 可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
- 交互式命令行:python可以单步直译运行,可以在一个 Python 提示符 >>> 后直接执行代码。
- 丰富的标准库:Python标准库包括字符串处理(字典、数组切片、正则表达式re)、文档生成、多线程、串行化、数据库、HTML/XML解析(BeautifulSoup,Expat)、单元测试(PyUnit)、代码版本控制(PySVN)、WAV文件、网络控制(urllib2)、密码系统、GUI(图形用户界面,PyQt)、图形模块(Tkinter、PyTCL、WxPython)等。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
- 规范性:采用强制缩进的方式使得代码具有较好可读性,减少了视觉上的错乱。
- 胶水语言:python经常用作将不同语言编写的程序“粘”在一起的胶水语言。Boost.Python使得Python和C++的类库可互相调用(.pyc);Jpython是用Java实现的Python,可以同时使用两者的类库;Ironpython是Python在.NET平台上的版本。
6 Python优点
- 易于学习,非常适合初学者,也特别适合专家使用
- 可伸缩程度高,适于大型项目或小型的一次性程序(称为脚本)
- 可移植,跨平台
- 可嵌入(使 ArcGIS 可脚本化)
- 稳定成熟
- 用户社区规模大
程序设计思想

Python编程思想
Python是一种面向对象oop(Object Oriented Programming)的脚本语言。
面向对象是采用基于对象(实体)的概念建立模型,模拟客观世界分析、设计、实现软件的办法。
在面向对象程序设计中,对象包含两个含义,其中一个是数据,另外一个是动作。面向对象的方法把数据和方法组合成一个整体,然后对其进行系统建模。
python编程思想的核心就是理解功能逻辑,如果对解决一个问题的逻辑没有搞清楚,那么你的代码看起来就会非常的紊乱,读起来非常的拗口,所以一旦逻辑清晰,按照模块对功能进行系统编程,那么你的代码设计肯定是漂亮的!!!
1 基本的程序设计模式
任何的程序设计都包含IPO,它们分别代表如下:
- I:Input 输入,程序的输入
- P:Process 处理,程序的主要逻辑过程
- O:Output 输出,程序的输出
因此如果想要通过计算机实现某个功能,那么 基本的程序设计模式包含三个部分,如下:
- 确定IPO:明确需要实现功能的输入和输出,以及主要的实现逻辑过程;
- 编写程序:将计算求解的逻辑过程通过编程语言进行设计展示;
- 调试程序:对编写的程序按照逻辑过程进行调试,确保程序按照正确逻辑正确运行。
2 解决复杂问题的有效方法:自顶向下(设计)
2.1 自顶向下-分而治之
如果要实现功能的逻辑比较复杂的时候,就需要对其进行模块化设计,将复杂问题进行分解,转化为多个简单问题,其中简单问题又可以继续分解为更加简单的问题,直到功能逻辑可以通过模块程序设计实现,这也是程序设计的自顶向下特点。总结如下:
- 将一个总问题表达为若干个小问题组成的形式
- 使用同样方法进一步分解小问题
- 直至,小问题可以用计算机简单明了的解决
2.2 举例1:体育竞技分析
2.2.1 程序总体框架
printlnfo() 步骤1:打印程序的介绍性信息
getlnputs() 步骤2:获得程序运行参数:proA, proB, n
simNGames() 步骤3:利用球员A和B的能力值,模拟n局比赛
printSummary() 步骤4:输出球员A和B获胜比赛的场次及概率
2.2.2 程序设计
导入python资源包
from random import random
用户体验模块
def printIntro():print("这个程序模拟两个选手A和B的某种竞技比赛")print("程序运行需要A和B的能力值(以0到1之间的小数表示)")
获得A和B的能力值与场次模块
def getIntputs():a = eval(input("请输入A的能力值(0-1):"))b = eval(input("请输入B的能力值(0-1):"))n = eval(input("模拟比赛的场次:"))return a, b, n模拟n局比赛模块
def simNGames(n, probA, probB):winsA, winsB = 0, 0for i in range(n):scoreA, scoreB = simOneGame(probA, probB)if scoreA > scoreB:winsA += 1else:winsB += 1return winsA, winsB
判断比赛结束条件
def gameOver(a, b):return a == 15 or b == 15
模拟n次单局比赛=模拟n局比赛
def simOneGame(probA, probB):scoreA, scoreB = 0, 0serving = "A"while not gameOver(scoreA, scoreB):if serving == "A":if random() < probA:scoreA += 1else:serving = "B"else:if random() < probB:scoreB += 1else:serving = "A"return scoreA, scoreB打印结果模块
def printSummary(winsA, winsB):n = winsA + winsBprint("竞技分析开始,共模拟{}场比赛".format(n))print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA, winsA / n))print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB, winsB / n))def main():printIntro() probA, probB, n = getIntputs() # 获得用户A、B能力值与比赛场次NwinsA, winsB = simNGames(n, probA, probB) # 获得A与B的场次printSummary(winsA, winsB) # 返回A与B的结果main()
2.2.3 测试结果

2.3 举例2:的斐波那契数列
自顶向下的方式其实就是使用递归来求解子问题,最终解只需要调用递归式,子问题逐步往下层递归的求解。
程序设计:
cache = {}def fib(number):if number in cache:return cache[number]if number == 0 or number == 1:return 1else:cache[number] = fib(number - 1) + fib(number - 2)return cache[number]if __name__ == '__main__':print(fib(35))
运行结果:
14930352>>>
理解自顶向下的设计思维:分而治之
3 逐步组建复杂系统的有效测试方法:自底向上(执行)
3.1 自底向上-模块化集成
自底向上(执行)就是一种逐步组建复杂系统的有效测试方法。首先将需要解决的问题分为各个三元进行测试,接着按照自顶向下相反的路径进行操作,然后对各个单元进行逐步组装,直至系统各部分以组装的思路都经过测试和验证。
理解自底向上的执行思维:模块化集成
自底向上分析思想:
- 任何时候栈中符号串和剩余符号串组成一个句型,当句柄出现在栈顶符号串中时,就用该句柄进行归约,这样一直归约到输入串只剩结束符、栈中符号只剩下开始符号,此时认为输入符号串是文法的句子,否则报错。
自底向上是⼀种求解动态规划问题的方法,它不使用递归式,而是直接使用循环来计算所有可能的结果,往上层逐渐累加子问题的解。在求解子问题的最优解的同时,也相当于是在求解整个问题的最优解。其中最难的部分是找到求解最终问题的递归关系式,或者说状态转移方程。
3.2. 程序设计
#循环的⽅式,自底向上求解
cache = {}
items = range(1,9)
weights = [10,1,5,9,10,7,3,12,5]
values = [10,20,30,15,40,6,9,12,18]
#最⼤承重能⼒
W = 4def knapsack():for w in range(W+1):cache[get_key(0,w)] = 0for i in items:cache[get_key(i,0)] = 0for w in range(W+1):if w >= weights[i]:if cache[get_key(i-1,w-weights[i])] + values[i] > cache[get_key(i-1,w)]:cache[get_key(i,w)] = values[i] + cache[get_key(i-1,w-weights[i])]else:cache[get_key(i,w)] = cache[get_key(i-1,w)]else:cache[get_key(i,w)] = cache[get_key(i-1,w)]return cache[get_key(8,W)]def get_key(i,w):return str(i)+','+str(w)if __name__ == '__main__':# 背包把所有东西都能装进去做假设开始print(knapsack())
29
>>>
安装Python
1 Windows系统下python安装
此次安装主要针对windows开发,因此是在windows 10系统下进行安装。
1.1 python下载安装
Python官网: | Python.org

在这里找到自己需要的版本进行下载即可,但是建议大家不要下载最新版本,懂得都懂。。。下载完成后运行安装即可。
下载稳定版,具体下载版本需要看自己的电脑是多少位的,博主的电脑是64位的,因此安装的版本是64位的3.7.4:
- 可进“设置→系统→关于”查看自己电脑的系统类型,博主的如下:
- 找到对应位数的版本

包含三种安装类型:
-
在线安装,即执行安装后才透过网络下载python: Download Windows x86-64 web-based installer
-
exe程序安装: Download Windows x86-64 executable installer
-
压缩文件解压缩安装: Download Windows x86-64 embeddable zip file
一般都选择exe程序安装
Download:windows x86为32位,windows x86-64为64位
如下是下载好的exe安装程序:
下载exe后,双击.exe文件进入软件安装界面,选中【customize Installation】自定义安装, 并勾上【Add Python to PATH】添加环境变量(Python 3.7添加到路径)选项,意思是把Python的安装路径添加到系统环境变量的Path变量中。


选择Python安装程序和安装位置,然后点击【Install】,软件会默认安装,或者想要更改安装程序的位置,点击【Browse】,在打开的窗口中自行选择软件安装位置,选择完成后点击【Install】。

之后就是等着进度条满,这个时间可能会比较长。

最后Python安装完成,点击【close】退出软件安装。
1.2 Python环境变量配置
手动添加python环境变量过程
- 找到计算机,点击鼠标右键在弹出的选项中点击【属性】,然后点击【高级系统配置】

-
点击【环境变量】

-
在系统变量中,找到Path,双击,在打开的编辑系统变量中,在末尾添加一个英文的分号,将python软件安装路径复制进去就可以了
-
搜索输入"cmd”或者 "win +R”输入cmd 进入命令窗口 ,输入“python --version”并回车。如果出现python版本,则安装成功

-
可以在命令提示符中输入"Python"命令来启动Python解释器:执行以上命令后,出现如下窗口信息:

安装后python找不到的可能情况及解决办法:
1、先关闭cmd,然后重新打开,再输入“python --version”并回车,如果可以了,那就说明cmd打开后安装的;
2、点击下载的安装包,选择repair,根据提示重新来一次;
3、若没有出现python版本,应该是环境变量没有设置好,打开系统环境变量的Path变量,查看是否有Python的目录。若没有,那就手动配置环境变量。
运行方式
一、交互模式下执行 Python
这种模式下,无需创建脚本文件,直接在 Python解释器的交互模式下编写对应的 Python 语句即可。
1)打开交互模式的方式:
Windows下:在开始菜单找到“命令提示符”,打开,就进入到命令行模式;在命令行模式输入: python 即可进入 Python 的交互模式
Linux 下:直接在终端输入 python,如果是按装了 python3 ,则根据自己建的软连接的名字进入对应版本的 Python 交互环境,例如我建立软连接使用的 python3,这输入 python3。
2)在交互模式下输出: Hello World!
3)退出交互模式,直接输入 exit() 或者quit() 即可。
Windows:

Linux:

二、通过脚本输出
通过文本编辑器,编写脚本文件,命名为 hello.py,在命令行模式下输入 python hello.py 即可
Windows:

Linux:
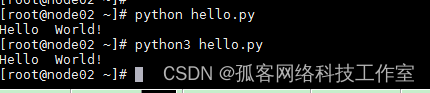
同样,也可以带参数(需要导入包 import sys)
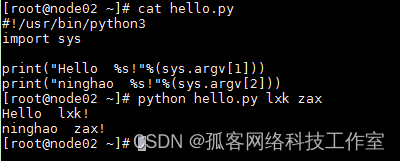
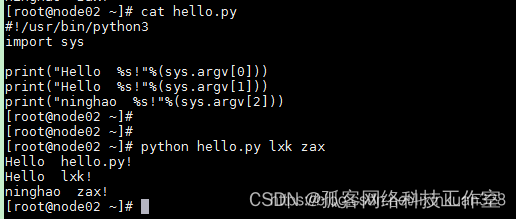
这种方式,要注意脚本文件所在路径,如果当前工作路径和脚本文件不在同一路径下,则要进入 脚本文件所在路径,或者给出脚本文件的完整路径。
1)进入脚本文件所在路径下执行
C:\Windows\System32>G:
G:\test>python hello.py
Hello World!
2)给出脚本文件的完整路径
C:\Windows\System32>python G:\test\hello.py
Hello World!
三、在脚本文件中指定 python 程序所在路径,修改文件为可执行文件,然后直接运行文件
在Linux下:
1)修改文件,添加 #!/usr/bin/python3

2)修改文件权限,添加可执行权限:chmod u+x hello.py
3)运行

此种方式执行的时候,一定要在脚本文件中指定解释器,否则无法直接运行脚本文件
4) python脚本传递参数
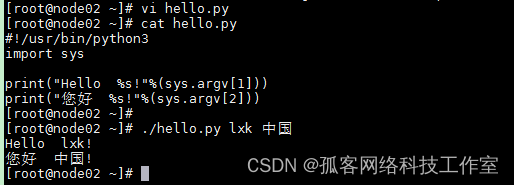
四、交互模式和脚本文件方式的比较
1)在交互模式下,会自动打印出运算结果,而通过脚本文件的方式不会
交互模式:
[node02@localhost code]$ python3
Python 3.6.5 (default, Oct 19 2018, 10:46:59)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-11)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> 100+200
300
>>> exit()
脚本文件:没有任何输出,此时要想输出,必须使用 print 函数进行打印。
[node02@localhost code]$ vi cal.py
[node02@localhost code]$ cat cal.py
100+200
[node02@localhost code]$ python3 cal.py
[node02@localhost code]$
2)在交互模式下,每次输入的语句不会被保存,退出交互环境之后即消失,但是通过脚本文件我们可以保存我们写过的所有语句。所以通常都是通过编写 脚本文件的方式来编写 Python 代码。
注意:在编写脚本文件的时候不要使用 word 和 windows 自带的笔记本,因为他们在保存的时候会保存为 utf-8 BOM 格式,这会导致脚本执行错误。可以使用 sublime,editplus,notepad++
常用开发工具
-
pycharm
-
Visual Studio Code

-
IDLE
编码规范

想要写好python代码,必须了解python相关编码规范,有了这个的加持,编写的代码不仅可以实现相应的功能,而且简单易读,逻辑清晰。本节技能树主要分享相应的python编码规范,学习python的小伙伴们请仔细阅读,对你的python代码的编写肯定有质的提高!!!
1 代码编码格式
- 一般来说,声明编码格式在脚本中是必需的。
- 国际惯例,文件编码和 Python 编码格式全部为 utf-8 。例如:在 Python 代码的开头,要统⼀加上如下代码:
# -- coding: utf-8 --
- 如果Python源码文件没有声明编码格式,Python解释器会默认使用ASCII编码。但出现非ASCII编码的字符,Python解释器就会报错,因此非
ASCII 字符的字符串,请需添加u前缀。 - 若出现 Python编码问题,可按照以下操作尝试解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
2 分号
不要在行尾加分号,也不要用分号将两条命令放在同一行。
3 行的最大长度
每行不超过80个字符
以下情况除外:
- 长的导入模块语句
- 注释里的URL斜体样式
不要使用反斜杠连接行。
Python会将 圆括号, 中括号和花括号中的行隐式的连接起来。
圆括号、方括号或花括号以内的表达式允许分成多个物理行,无需使用反斜杠。例如:
month_names = ['Januari', 'Februari', 'Maart', # These are the'April', 'Mei', 'Juni', # Dutch names'Juli', 'Augustus', 'September', # for the months'Oktober', 'November', 'December'] # of the year
隐式的行拼接可以带有注释。后续行的缩进不影响程序结构。后续行也允许为空白行。
如果需要,可以在表达式外围增加一对额外的圆括号。
如果一个文本字符串在一行放不下, 可以使用圆括号来实现隐式行连接
x = ('这是一个非常长非常长非常长非常长 ''非常长非常长非常长非常长非常长非常长的字符串')
4 缩进规则
- Python 采用代码缩进和冒号( : )来区分代码块之间的层次。
- 在 Python
中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。 - Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现。但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4
个空格长度作为一个缩进量(默认情况下,一个 Tab 键就表示 4 个空格)。 - 对于 Python 缩进规则,初学者可以这样理解,Python
要求属于同一作用域中的各行代码,它们的缩进量必须一致,但具体缩进量为多少,并不做硬性规定。
建议使用 Emacs 的 Python-mode 默认值:4 个空格一个缩进层次。不要用tab,也不要tab和空格混用
正确示例代码:
if a==0:print("正确") # 缩进4个空白占位
else: # 与if对齐print("错误") # 缩进4个空白占位或者# 4 个空格缩进,第一行不需要
foo = long_function_name(var_one, var_two, var_three,var_four)
错误示例代码:
if a==0:print("正确")
else: print("错误") print("end") # 错误的是这行代码前面加了一个空格或者# 2 个空格是禁止的
foo = long_function_name(var_one, var_two, var_three,var_four)
5 注释
- Python中使用 # 进行注释,# 号后面要空一格。
- 最需要写注释的是代码中那些技巧性的部分:对于复杂的操作,应该在其操作开始前写上若干行注释.;对于不是一目了然的代码,应在其行尾添加注释。
- 为了提高可读性,注释和代码隔开一定的距离,注释应该至少离开代码2个空格,块注释后面最好多留几行空白再写代码。
- 当代码更改时,优先更新对应的注释。
- 如果一个注释是一个短语或者句子,它的第一个单词应该大写,除非它是以小写字母开头的标识符(永远不要改变标识符的大小写!)。
- 如果注释很短,结尾的句号可以省略。块注释一般由完整句子的一个或多个段落组成,并且每句话结束有个句号。
- 在句尾结束的时候应该使用两个空格。
Python中有三种形式的注释:行注释、块注释、文档注释
行注释:注释应解释自己做了什么,而不是对代码本身的解释
- 有节制地使用行内注释
- 行内注释是与代码语句同行的注释
- 行内注释和代码至少要有两个空格分隔
- 注释由#和一个空格开始。
n = input()
m = input()
t = n / 2 # t是n的一半# 循环,条件为t*m/n 小于n
while (t * m / (n + 1) < n):t = 0.5 * m + n / 2 # 重新计算t值
print(t)
块注释:
- 块注释通常适用于跟随它们的某些(或全部)代码,并缩进到与代码相同的级别 块注释的每一行开头使用一个 #
- 和一个空格(除非块注释内部缩进文本)。
- 块注释内部的段落通常只有一个 # 的空行分隔。
def FuncName(parameter1,parameter2):"""描述函数要做的事情:param parameter1: 参数一描述(类型、用途等):param parameter2: 参数二描述:return: 返回值描述"""
# We use a weighted dictionary search to find out where i is in
# the array. We extrapolate position based on the largest num
# in the array and the array size and then do binary search to
# get the exact number.if i & (i-1) == 0: # true if i is a power of 2
文档注释:
- 要为所有的公共模块,函数,类和方法编写文档说明
- 非公共的方法没有必要,但是应该有一个描述方法具体作用的注释。这个注释应该在def那一行之后
- 多行文档注释使用的结尾三引号应该是自成一行
class SampleClass(object):"""Summary of class here.Longer class information....Longer class information....Attributes:likes_spam: A boolean indicating if we like SPAM or not.eggs: An integer count of the eggs we have laid."""def __init__(self, likes_spam=False):"""Inits SampleClass with blah."""self.likes_spam = likes_spamself.eggs = 0def public_method(self):"""Performs operation blah."""
6 空行
- 顶层函数和类定义,前后用两个空行隔开
- 编码格式声明、模块导入、常量和全局变量声明、顶级定义和执行代码之间空两行 类里面方法定义用一个空行隔开
- 在函数或方法内部,可以在必要的地方空一行以增强节奏感,但应避免连续空行
class Class01:passclass Class02:def function_01(self):passdef function_02(self):pass
使用必要的空行可以增加代码的可读性,通常在顶级定义(如函数或类的定义)之间空两行,而方法定义之间空一行,另外在用于分隔某些功能的位置也可以空一行。
7 制表符还是空格
- 不要混用制表符和空格,因为如果混用了,虽然在编辑环境中显示两条语句为同一缩进层次,但因为制表符和空格的不同会导致 Python
解释为两个不同的层次。 - 在调用 Python 命令行解释器时使用 -t
选项,可对代码中不合法的混合制表符和空格发出警告,使用 -tt时警告将变成错误,这些选项是被高度推荐的。但是强烈推荐仅使用空格而不是制表符。
空格使用规则:
- 在二元运算符两边各空一格,比如赋值(=)、比较(==, <, >, !=, <>, <=, >=, in, not in, is, isnot), 布尔(and, or, not),算术操作符两边的空格可灵活使用,但两侧务必要保持一致
- 不要在逗号、分号、冒号前面加空格,但应该在它们后面加(除非在行尾)
- 函数的参数列表中,逗号之后要有空格
- 函数的参数列表中,默认值等号两边不要添加空格
- 左括号之后,右括号之前不要加添加空格
- 参数列表, 索引或切片的左括号前不应加空格
- 当’='用于指示关键字参数或默认参数值时,不要在其两侧使用空格
正确示例代码:
spam(ham[1], {eggs: 2}, [])if x == 4:print x, y
x, y = y, xdict['key'] = list[index]def complex(real, imag=0.0): return magic(r=real, i=imag)
错误示例代码:
spam( ham[ 1 ] , { eggs: 2 } , [ ] )if x == 4 :print x , y
x , y = y , xdict ['key'] = list [index]def complex(real, imag = 0.0): return magic(r = real, i = imag)
8 命名规范
模块名命名
- 模块尽量使用小写命名,首字母保持小写,尽量不要用下划线(除非多个单词,且数量不多的情况)
# 正确import decoderimport html_parser# 不推荐import Decoder
变量命名
- 不要使用字母I (小写的L), O (大写的O), I
(大写的I)作为单字符的变量名。在有些字体里面,这些字符无法与数字0和1区分。如果想用I, 可使用L代替。 - 变量名尽量小写, 如有多个单词,用下划线隔开。
count = 0
this_is_var = 0
常量或者全局变量命名
- 全部大写,如有多个单词,用下划线隔开
- 全⼤写+下划线式驼峰
MAX_CLIENT = 100
函数命名
- 函数名应该小写,如有多个单词,用下划线隔开。
- 大小写混合仅在为了兼容原来主要以大小写混合风格的情况下使用,保持向后兼容。 私有函数在函数前加一个下划线_。
def run():passdef run_with_env():passclass Person():def _private_func():pass
类命名
- 类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头。
- 在接口被文档化并且主要被用于调用的情况下,可以使用函数的命名风格代替。
- 对于内置的变量命名有一个单独的约定:大部分内置变量是单个单词(或者两个单词连接在一起),首字母大写的命名法只用于异常名或者内部的常量。
class Farm():passclass AnimalFarm(Farm):passclass _PrivateFarm(Farm):pass
类里面函数和方法参数
- 始终要将self作为实例方法的第一个参数。
- 始终要将cls作为类方法的第一个参数。
- 如果函数的参数名和已有关键字冲突,在最后加大意下划线比缩写或者随意拼写更好。因此class_比clss更好。
特别注意:
- 不要中英文混编
- 不要有a、b、c这种没有意义的命名
- 不要怕名字长就随便缩写,比如person_info 缩写成pi
- 不要用大小写区分变量类型,比如a是int类型,A是String类型
- 不要使用容易引起混淆的变量名
- bool变量⼀般加上前缀 is_ 如:is_success
- 变量名不要用系统关键字,如 dir type str等等
以下用下画线作前导或结尾的特殊形式是被公认的:
- _single_leading_underscore(以一个下画线作前导):例如,“from M import *”不会导入以下画线开头的对象。
- single_trailing_underscore_(以一个下画线结尾):用于避免与 Python 关键词的冲突,例如“Tkinter.Toplevel(master, class_=‘ClassName’)”。
- __double_leading_underscore (双下画线):从 Python 1.4 起为类私有名。
- double_leading_and_trailing_underscore:特殊的(magic) 对象或属性,存在于
- 用户控制的(user-controlled)名字空间,例如:init、import 或 file。
9 引号用法规则
- 自然语言使用双引号
- 机器标识使用单引号
- 正则表达式使用双引号
- 文档字符串 (docstring) 使用三个双引号
字符串引号规则:
- 单引号和双引号字符串是相同的。当一个字符串中包含单引号或者双引号字符串的时候,使用和最外层不同的符号来避免使用反斜杠,从而提高可读性。
- 在同一个文件中,保持使用字符串引号的一致性。在字符串内可以使用另外一种引号,以避免在字符串中使用。
正确使用示例:
Tim('Why are you hiding your eyes?')
Bob("I'm scared of lint errors.")
Juy('"Good!" thought a happy Python reviewer.')
- 当且仅当代码中使用单引号’来引用字符串时,才可能会使用三重’''为非文档字符串的多行字符串来标识引用
- 文档字符串必须使用三重双引号"“”
10 模块导入规则
- 导入应该放在文件顶部,位于模块注释和文档字符串之后,模块全局变量和常量之前。
- 导入应该按照从最通用到最不通用的顺序分组:标准库导入、第三方库导入、应用程序指定导入,分组之间空一行。
- 模块名称要短,使用小写,并避免使用特殊符号, 比如点和问号。
- 尽量保持模块名简单,以无需分开单词最佳(不推荐在两个单词之间使用下划线)。 每个导入应该独占一行。
正确使用例子:
import os
import numpy
import sysfrom types import StringType, ListType
错误使用例子:
import os, numpy, sys
- 从一个包含类的模块中导入类时,通常可以写成这样:
from MyClass import MyClass
from foo.bar.YourClass import YourClass
模块导入建议
| 示例 | 评价 |
|---|---|
| from modu import * | 差, 不清楚具体从模块中导入了哪些内容 |
| from modu import sqrt | 稍好 |
| import moduimport modu.sqrt | 最佳 , 调用的时候直接使用modu.sqrt能比较清楚的知 |
| import os import sys | 推荐 |
| import os, sys | 不推荐 |
| from subprocess import Popen, PIPE | 推荐 |
11 Main
主功能应该放在一个main()函数中。
在Python中,pydoc以及单元测试要求模块必须是可导入的。代码应该在执行主程序前总是检查 if name == ‘main’, 这样当模块被导入时主程序就不会被执行。
def main():...if __name__ == '__main__':main()
12 函数设计规范
- 函数设计的主要目标就是最大化代码重用和最小化代码冗余。精心设计的函数不仅可以提高程序的健壮性,还可以增强可读性、减少维护成本。
- 函数设计要尽量短小,嵌套层次不宜过深。 所谓短小, 就是尽量避免过长函数, 因为这样不需要上下拉动滚动条就能获得整体感观,
而不是来回翻动屏幕去寻找某个变量或者某条逻辑判断等。 函数中需要用到 if、 elif、 while 、 for等循环语句的地方,尽量不要嵌套过深,最好能控制在3层以内。不然有时候为了弄清楚哪段代码属于内部嵌套, 哪段属于中间层次的嵌套, 哪段属于更外一层的嵌套所花费的时间比读代码细节所用时间更多。 - 尽可能通过参数接受输入,以及通过return产生输出以保证函数的独立性。 尽量减少使用全局变量进行函数间通信。
- 不要在函数中直接修改可变类型的参数。
- 函数申明应该做到合理、 简单、 易于使用。 除了函数名能够正确反映其大体功能外, 参数的设计也应该简洁明了, 参数个数不宜太多。
参数太多带来的弊端是: 调用者需要花费更多的时间去理解每个参数的意思,测试的时候测试用例编写的难度也会加大。 - 函数参数设计应该考虑向下兼容。
13 版本注记
如果要将 RCS 或 CVS 的杂项包含在你的源文件中,按如下格式操作:
__version__ = "$Revision: 1.4 $"
# $Source: E:/cvsroot/python_doc/pep8.txt,v $
对于 CVS 的服务器工作标记更应该在代码段中明确出它的使用说明,如在文档最开始的版权声明后应加入如下版本标记:
# 文件:$id$
# 版本:$Revision$
这样的标记在提交给配置管理服务器后,会自动适配成为相应的字符串,如:
# 文件:$Id: ussp.py,v 1.22 2004/07/21 04:47:41 hd Exp $ # 版本:$Revision: 1.4 $
这些应该包含在模块的文档字符串之后,所有代码之前,上下用一个空行分割。
模块管理
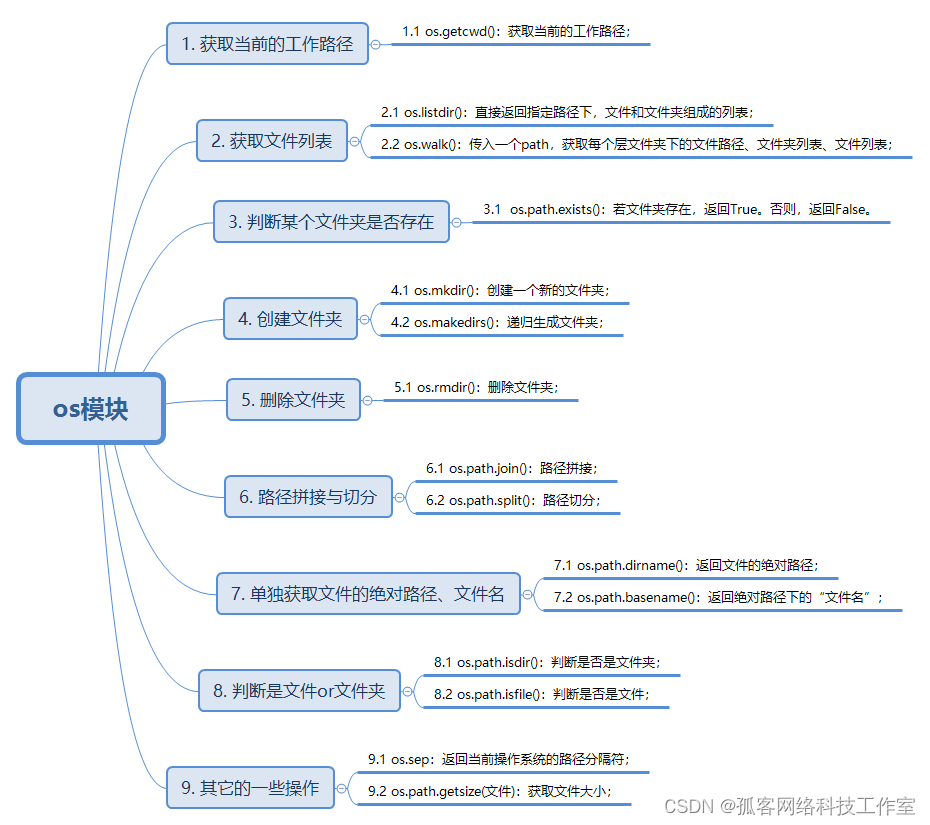
1 OS模块
2 glob模块

-
📢博客主页:孤客网络科技工作室
-
📢欢迎点赞👍收藏⭐️留言 📝如有错误敬请指正!
-
📢本文由孤客原创,部分材料收集与网络,若侵权联系作者,首发于CSDN博客
-
📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更好的生活💻