一.小结
本小节主要是学习关联规则,但是学习这个之前,我们要学习Apriori算法求的频繁集。
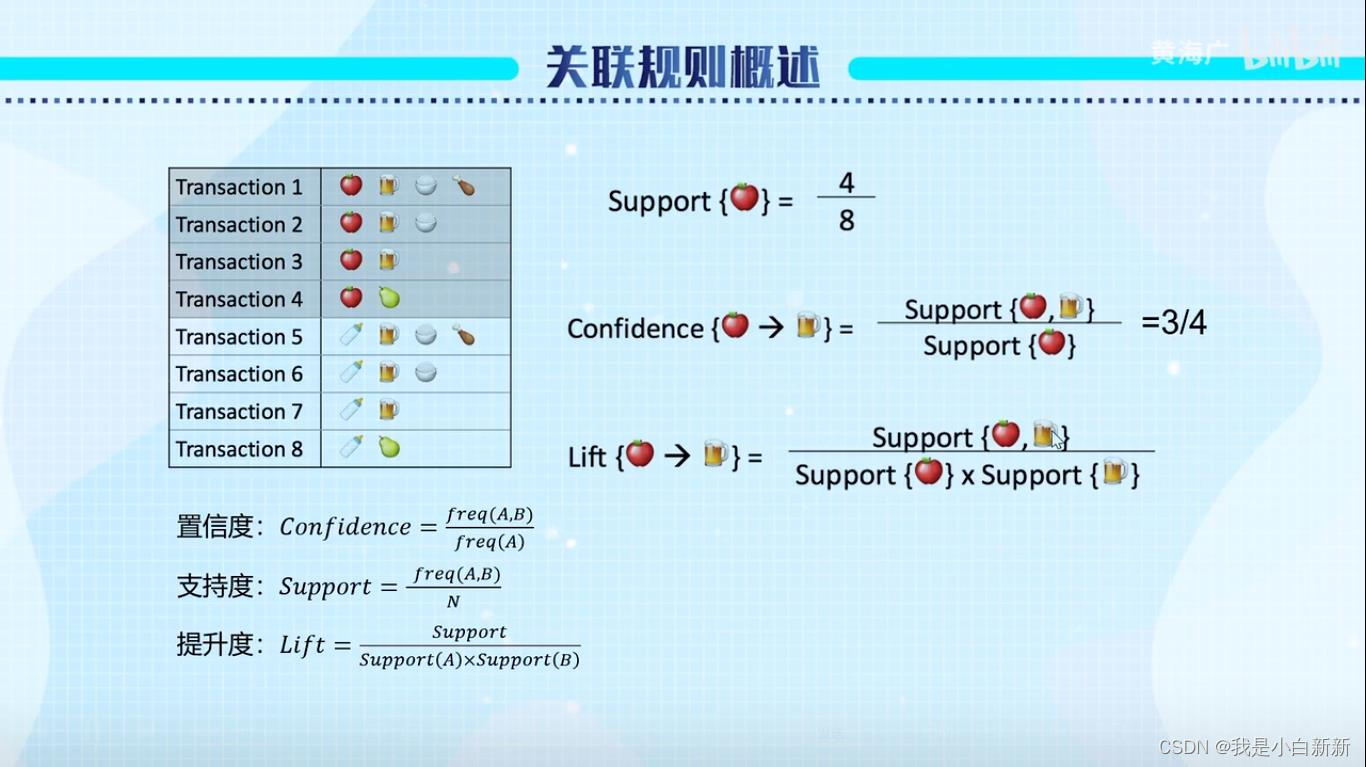
二.实操演示
(1)处理数据集
- 导入数据
#导入数据
import pandas as pd
path = 'C:\\Users\\chxy\\Desktop\\data\\store_data.csv'
records = pd.read_csv(path,header=None,encoding='utf-8',na_filter=False)
#na_filter=False,表示空值导入后会显示为空,而不是NaN
print(records)

- 对数据集进行编码
#对交易数据进行one-hot编码
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder()#类实例化
one_hot_records = TE.fit(lst_records).transform(lst_records)
print(one_hot_records)
改正后:
import mlxtend
#对交易数据进行one-hot编码
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder()#类实例化
lst_records = records.values.tolist()
one_hot_records = TE.fit(lst_records).transform(lst_records)
print(one_hot_records)

3.
#数据格式转为数据框
df_records = pd.DataFrame(data = one_hot_records,columns = TE.columns_)
print(df_records)
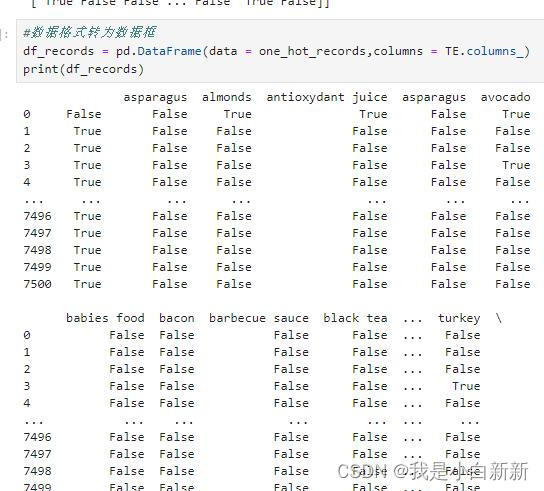
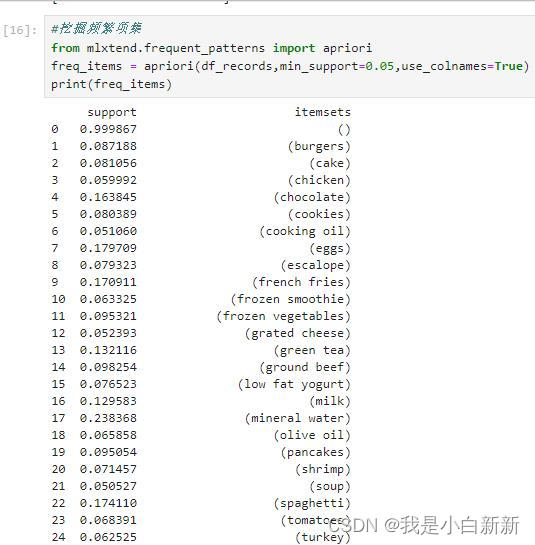
4.
#挖掘频繁项集
from mlxtend.frequent_patterns import apriori
freq_items = apriori(df_records,min_support=0.05,use_colnames=True)
print(freq_items)
(2)关联规则
5挖掘关联规则
#挖掘关联规则
from mlxtend.frequent_patterns import association_rules
association_rules_1 = association_rules(freq_items,metric='confidence',min_threshold=0.2)
print(association_rules_1)
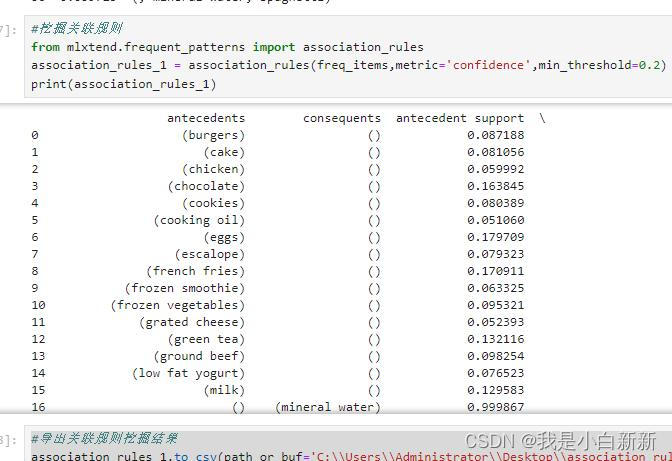
6.导出关联规则挖掘结果
#导出关联规则挖掘结果
association_rules_1.to_csv(path_or_buf='C:\\Users\\Administrator\\Desktop\\association_rules.csv')

三.课后练习P75+P77