以下内容有任何不理解可以翻看我之前的博客哦:吴恩达deeplearning.ai专栏
文章目录
- 为什么要使用树集合
- 使用多个决策树(Tree Ensemble)
- 有放回抽样
- 随机森林
- XGBoost(eXtream Gradient Boosting)
- XGBoost的库实现
- 何时使用决策树
- 决策树和树集合
- 神经网络
使用单个决策树的缺点之一是该决策树可能对数据中的微小变化高度敏感,改变这种问题的一个解决方式是不仅仅使用一个决策树,而是使用多个,我们称为树集合。
为什么要使用树集合
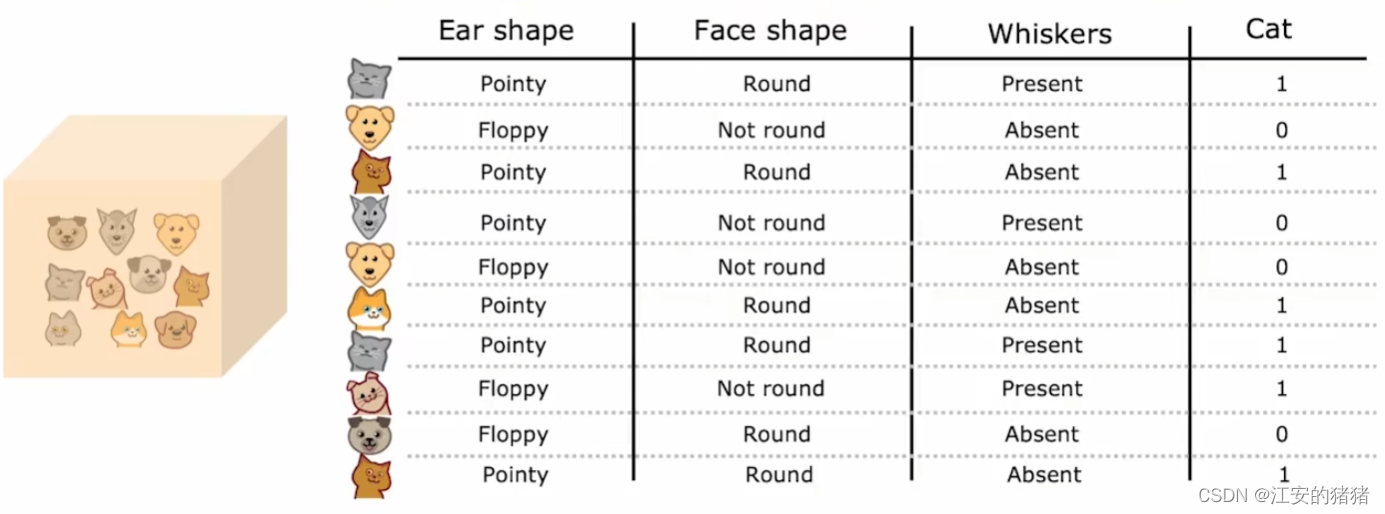
我们先来理解下什么叫做对于数据的变化高度敏感:

假设我们仅仅将数据集中的一只猫替换成一只与它特征相反的猫,结果发现,树的根节点的最优选择直接变成了是否有胡须,那么甚至导致了整个决策树变得完全不同了,这样就意味着算法的健壮性不够,所以,针对这种情况,我们的解决方案是构建多棵决策树。
使用多个决策树(Tree Ensemble)

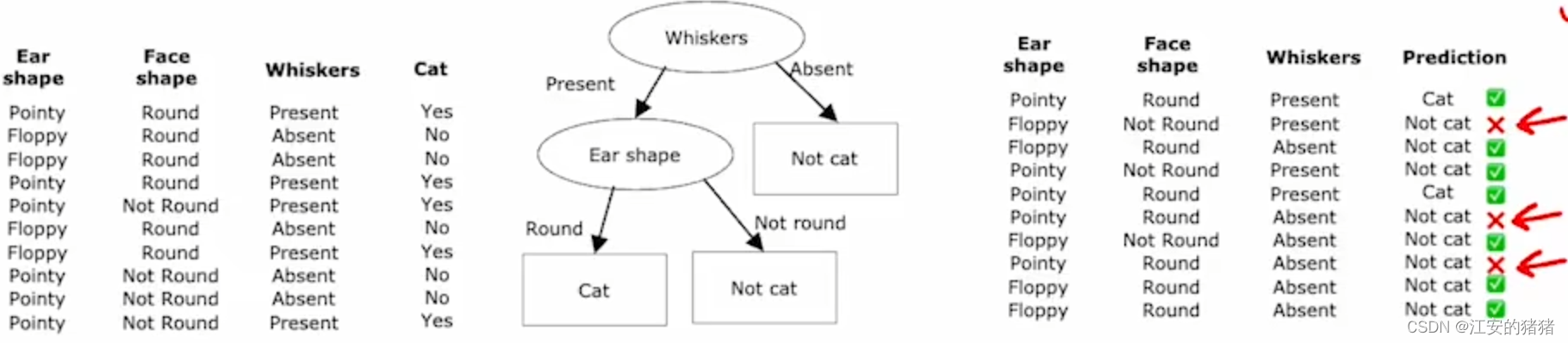
假设你已经有三棵决策树了,假设这三棵树都是合理的(具体如何构建我们在后面再提),那么你有一只猫,在三种不同的树中的预测分别如上图,三棵树在一起开了个会,最终少数服从多数,投票决定它是一只猫。
所以我们该如何才能构建出这棵树呢? 我们将介绍一种方法。
有放回抽样
我们要做的是替换采样,步骤大概是这样的:我们将所有的训练集的样本放到一个黑箱中,从中随机抽取一定数量的例子,即使重复也没关系不用放回,然后你就构建好了一个新的替换的数据集,这个数据集可能重复,也可能不包含所有数据,但是没关系,这是计划的一部分哈哈。这样你就构建了一个和以前很相似但是有略微不同的数据集合。事实证明,这是构建树集合的关键。
随机森林
在这一章节中,我们着重讨论随机森林算法,这是一种强大的树样本算法,比使用单个决策树效果更好。

在例子中,我们从样本集中随机放回地抽取一定数量的树然后根据这些树来构建出一颗树,然后重复这一步骤,你可以构建几十棵,几百棵树,例如64,128之类,然后在这又随机抽样组成的随机森林对新样本进行预测,从而得到最终结果。
事实证明,将树的数量设置的很多并不会降低效果,但是当树的数量超过一个临界点时,你最终会得到收益递减的效果。这种树集合的创建方法也叫做袋状决策(bagged decision tree)。
实际上有一个对袋装决策的修改,从而能使其变为随机森林。关键思想是,即使你采用这种带有替换的采样过程,很多时候你依然会获得同样的根节点,以及非常相似的根节点附近的节点。因此,为了避免这种情况的发生,我们需要更加随机一点。通常的做法是在每个节点上选择一个特征进行切割,方法是每次选取特征时随机选取k个,再从k个中选取一个最大增益特征作为该节点的分类特征。这种方法有效的原因是它允许决策树出现更多的情况的可能。
XGBoost(eXtream Gradient Boosting)
XGBoost是当前效果非常好的一种基于决策树和样本的决策树。我们看看XGBoost的工作原理。
构建决策树时,我们从数据集中抽取m个来创建新的数据集,但是与之前不同的是,我们要改变抽到每个元素的概率,让它更有可能抽到在之前已经创建的决策树中分类错误的例子。这就像你学弹钢琴,要把弹得不好的那一部分拿出来多练,而不是把整首曲子都再弹一遍。
XGBoost有以下特点
- 开源实现。
- 快速、高效。
- XGBoost还内置了正则化防止过度拟合,因此在相关竞赛之中表现很好。
- 有一个很好的默认选项来判断何时停止拆分。
- 为不同的数据使用不同的方法,对数据集大小要求不高。
XGBoost的库实现
XGBoost的从头实现其实是很复杂的,因此很多人会选择开源库来实现。
你可以使用如下方式导入XGBoost库并且初始化分类器:
from xgboost import XGBClassifiermodel = XGBClassifier()model.fit(X_train, Y_train)
y_pred = model.predict(X_test)
或者你是想回归:
from xgboost import XGBRegressormodel = XGBRegressor()
model.fit(X_train, Y_train)
y_pred = model.predict(X_test)
何时使用决策树
我们什么时候该选择何种方法呢?让我们看看每种方法的适用情况
决策树和树集合
通常适用于表格数据(结构化数据)
不适用于非结构化数据,例如音频,视频,文本等
速度快
小型决策树是可解释的
神经网络
适用于各种不同的数据类型
慢
需要和迁移学习一起使用
更容易构建多层神经网络
为了给读者你造成不必要的麻烦,博主的所有视频都没开仅粉丝可见,如果想要阅读我的其他博客,可以点个小小的关注哦。