本文作者: slience_me
文章目录
- Transformers in Time Series A Survey综述总结
- 1 Introduction
- 2 Transformer的组成
- Preliminaries of the Transformer
- 2.1 Vanilla Transformer
- 2.2 输入编码和位置编码 Input Encoding and Positional Encoding
- 绝对位置编码 Absolute Positional Encoding
- 相对位置编码 Relative Positional Encoding
- 2.3 多头注意力 Multi-head Attention
- 2.4 前馈和残差网络(简单放在这)
- 3 时间序列中的Transformers的分类 Taxonomy of Transformers in Time Series
- 4 时间序列的网络修改 Network Modifications for Time Series
- 4.1 位置编码 Positional Encoding
- 4.2 注意力模块 Attention Module
- 4.3 基于架构的注意力创新 Architecture-based Attention Innovation
- 5 时间序列Transformer的应用 Applications of Time Series Transformers
- 5.1 Transformers in Forecasting
- 时间序列的预测 Time Series Forecasting
- 模块级变体
- 架构级变体
- 时空预测 Spatio-Temporal Forecasting
- 事件预测 Event Forecasting
- 5.2 异常检测中的Transformer
- 5.3 分类中的Transformer
- 6 实验评估与讨论 Experimental Evaluation and Discussion
- 鲁棒性分析
- 模型大小分析
- 季节性趋势分解分析
- 7 未来研究机会 Future Research Opportunities
- 7.1 时间序列Transformer的归纳偏差
- 7.2 用于时间序列的Transformer和GNN
- 7.3 用于时间序列的预训练Transformer
- 7.4 Transformer与体系结构级别的变体
- 7.5 用于时间序列的NAS Transformers
- 8 结论 Conclusion
- 7.5 用于时间序列的NAS Transformers
- 8 结论 Conclusion
Transformers in Time Series A Survey综述总结
Transformers在自然语言处理和计算机视觉的诸多任务中取得了更优的性能,这也引起了时间序列社区的广大的兴趣。在Transformers的众多优点中,捕获远程依赖关系和交互的能力对于时间序列建模特别具有吸引力,从而在各种时间序列应用中取得了令人兴奋的进展。在本文中,作者团队系统地审查Transformer计划的时间序列建模,突出他们的优点以及局限性。
该文章从两个角度去审视时间序列Transformers的发展
- 网络结构 : 总结了Transformers,以适应时间序列分析的挑战,已作出的调整和修改。
- 应用:根据预测、异常检测和分类等常见任务对时间序列Transformers进行分类
在实证上,进行了稳健性分析,模型大小分析和季节趋势分解分析,以研究Transformers在时间序列中的表现。
最后,讨论和建议未来的研究方向,提供有用的研究指导。
文章链接
文章代码
1 Introduction
在过去的几年里,许多Transformer已经被提出来大大提高各种任务的最先进性能。有相当多的文献综述来自不同的方面,例如在NLP应用中[Han et al.,2021],CV应用[Han等人,2022]和efficient Transformers[Tay等人,2022年],但尚未有针对时间序列中Transformer应用的全面综述。
在本文中,作者团队的目的是填补时间序列中Transformer应用的全面综述的差距与空白,总结了时间序列Transformers的主要发展。本文首先给予简要的介绍,然后从网络修改和应用领域的角度提出了一个新的分类法的时间序列的Transformers的Vanilla Transformer。
- 网络修改:讨论了低级别(即模块)和高级别(即架构)的Transformers,以优化时间序列建模的性能的改进。
- 应用程序:分析和总结Transformers的流行的时间序列任务,包括预测,异常检测和分类。对于每个时间序列Transformer,分析其见解,优势和局限性。
对于每个时间序列Transformer,分析其见解,优势和局限性。并进行了广泛的实证研究,包括鲁棒性分析,模型大小分析和季节趋势分解分析。
讨论了时间序列Transformers未来可能的方向,包括时间序列Transformers的归纳偏差,时间序列的Transformers和GNN,时间序列的预训练Transformers, 具有架构级别变体的Transformers,以及时间序列的NAS Transformers。
2 Transformer的组成
Preliminaries of the Transformer
2.1 Vanilla Transformer
Vanilla Transformer [Vaswani等人,2017]遵循具有编码器-解码器结构的最具竞争力的神经序列模型。编码器和解码器都由多个相同的块组成。每个编码器块由多头自注意模块和位置前馈网络组成,而每个解码器块在多头自注意模块和位置前馈网络之间插入交叉注意模型。
2.2 输入编码和位置编码 Input Encoding and Positional Encoding
与LSTM或RNN不同,Vanilla Transformer没有递归。相反,它利用在输入嵌入中添加的位置编码来对序列信息进行建模。在下面总结一些位置编码。
绝对位置编码 Absolute Positional Encoding
在vanilla Transformer中,对于每个位置索引t,编码向量由下式给出:
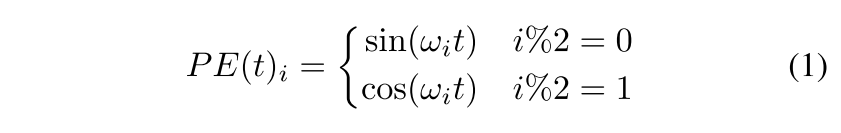
其中ωi是每个维度的手工频率。另一种方法是为每个位置学习一组位置嵌入,这更灵活[Meson等人,2019; Gehring等人,2017年]。
相对位置编码 Relative Positional Encoding
根据对输入元素之间的成对位置关系更有益的直觉,提出了相对位置编码方法。例如,其中一种方法是向注意机制的关键添加可学习的相对位置嵌入。
除了绝对和相对位置编码之外,还有一些使用混合位置编码的方法将它们结合在一起 。通常,位置编码被添加到标记嵌入中并馈送到Transformer。
参考解读: CSDN | 个人博客
2.3 多头注意力 Multi-head Attention
通过查询-关键字-值(QKV)模型,Transformer使用的缩放点积注意力由下式给出:
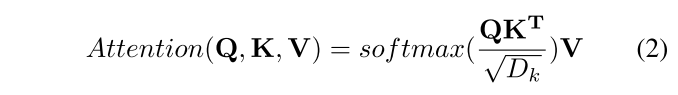

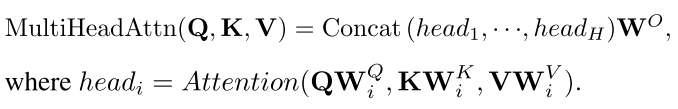
参考解读: CSDN | 个人博客
2.4 前馈和残差网络(简单放在这)
前馈网络是一个完全连接的模块,
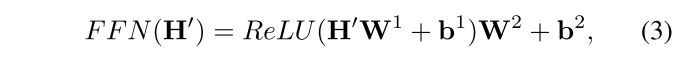
在更深的模块中,在每个模块周围插入一个残余连接模块,然后是一个层规范化模块。
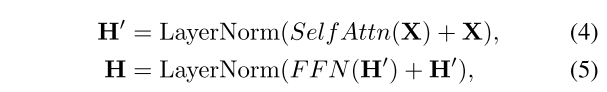
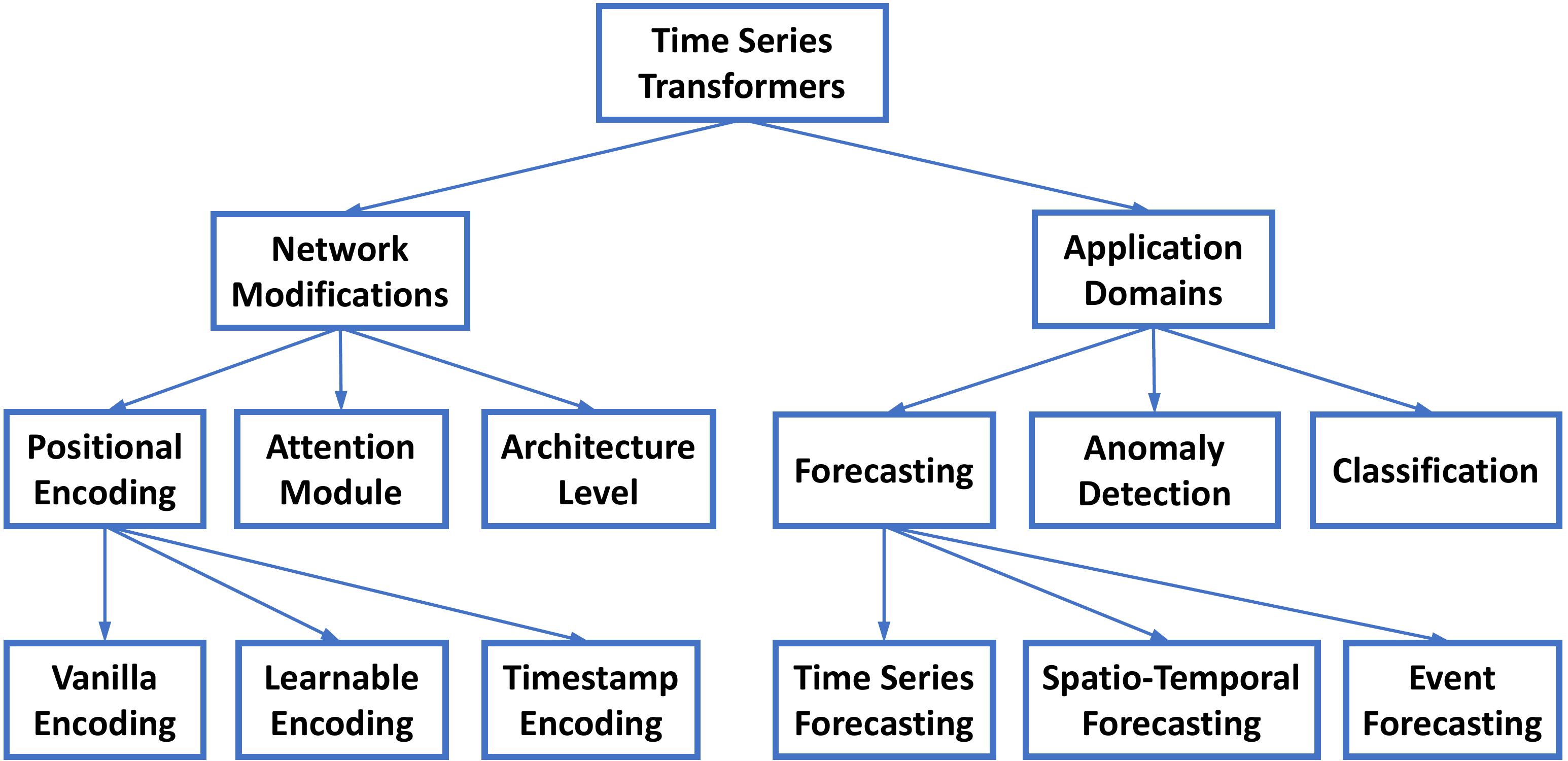
3 时间序列中的Transformers的分类 Taxonomy of Transformers in Time Series
为了总结现有的时间序列Transformers,作者团队从网络修改和应用领域的角度提出了一个分类,如下图所示。
在此基础上,对已有的时间序列Transformers进行了系统的回顾。
- 从网络修改的角度,总结了Transformer的模块级和架构级的变化,以适应时间序列建模的特殊挑战。
- 从应用的角度出发,根据时间序列Transformers的应用任务进行分类,包括预测、异常检测和分类。
4 时间序列的网络修改 Network Modifications for Time Series
4.1 位置编码 Positional Encoding
由于时间序列的顺序很重要,因此将输入时间序列的位置编码到Transformer中非常重要。一个常见的设计是首先将位置信息编码为向量,然后将它们与输入时间序列一起作为额外的输入注入到模型中。在使用Transformer建模时间序列时,如何获取这些向量可以分为三个主要类别。
总结:
- 原始位置编码(Vanilla Positional Encoding):简单地添加到输入时间序列嵌入中,但无法充分利用时间序列数据的特征。一些研究[Li等人,2019]简单介绍了在[Vaswani等,2017]中使用的原始位置编码(第2.2节),该编码随后被添加到输入时间序列的嵌入中,并馈送到Transformer。
- 可学习位置编码(Learnable Positional Encoding):通过学习适当的位置嵌入,比固定的原始位置编码更灵活,可以更好地适应特定任务。[Zerveas等人,2021]在Transformer中引入了一个嵌入层,该层与其他模型参数一起学习每个位置索引的嵌入向量。[Lim等人,2021] 使用LSTM网络来编码位置嵌入,可以更好地利用时间序列中的顺序信息。
- 时间戳编码(Timestamp Encoding):利用时间戳信息,将其编码为附加的位置编码,提高了对时间序列数据的利用效率。时间戳信息包括日历时间戳(例如,秒、分钟、小时、周、月和年)和特殊时间戳(例如假期和事件)。这些时间戳具有信息量但在原始的Transformer中很少被利用。为了缓解这个问题,Informer [Zhou等,2021] 提议使用可学习的嵌入层将时间戳编码为附加的位置编码。类似的时间戳编码方案还在Autoformer [Wu等,2021] 和FEDformer [Zhou等,2022] 中使用过。
4.2 注意力模块 Attention Module
Transformer的核心是自注意力模块。它可以被视为一个完全连接的层,其权重根据输入模式之间的成对相似性动态生成。因此,它与完全连接层具有相同的最大路径长度,但参数数量较少,适合建模长期依赖关系。(Transformer的计算优化主要就集中在self attention的计算熵)
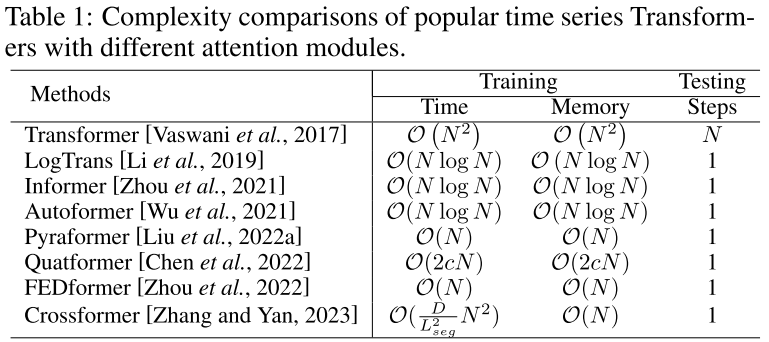
原始Transformer中的自注意力模块的时间和内存复杂度为O(N2)(N为输入时间序列的长度),当处理长序列时,这成为计算瓶颈。
许多高效的Transformer被提出来减少二次复杂度,可分为两个主要类别:
- 显式地引入稀疏偏置到注意力机制中,如LogTrans [Li等,2019] 和Pyraformer [Liu等,2022a];
- 探索自注意力矩阵的低秩性质以加速计算,例如Informer [Zhou等,2021] 和FEDformer [Zhou等,2022]。
表1显示了应用于时间序列建模的流行Transformer的时间和内存复杂度
4.3 基于架构的注意力创新 Architecture-based Attention Innovation
为了适应Transformer中用于建模时间序列的各个模块,一些研究[Zhou等,2021;Liu等,2022a]试图在架构层面上对Transformer进行改进。
-
最近的研究引入了分层架构到Transformer中,使其具有整合不同多分辨率特征,高效计算的好处,有利于高效处理长时间序列。
-
Informer[Zhou等,2021]在注意力块之间插入了步幅为2的最大池化层,将时间序列降采样为其一半。
-
Pyraformer[Liu等,2022a]设计了基于C-ary树的注意力机制,其中最细粒度的节点对应于原始时间序列,而较粗粒度的节点表示较低分辨率的时间序列。开发了内尺度和间尺度的注意力,以更好地捕捉不同分辨率之间的时间依赖关系。
5 时间序列Transformer的应用 Applications of Time Series Transformers
5.1 Transformers in Forecasting
在最近几年中,已经开展了大量工作来设计新的Transformer变体,用于时间序列预测任务。模块级别和架构级别变体是两个主要类别,前者占到了迄今为止的大多数研究。
时间序列的预测 Time Series Forecasting
模块级变体
在时间序列预测的模块级别变体中,它们的主要架构类似于原始的Transformer,但存在细微变化。研究人员引入各种时间序列归纳偏差来设计新的模块。以下总结的工作包括三种不同类型:设计新的注意力模块、探索归一化时间序列数据的创新方式,以及利用令牌输入的偏差,如下图所示。
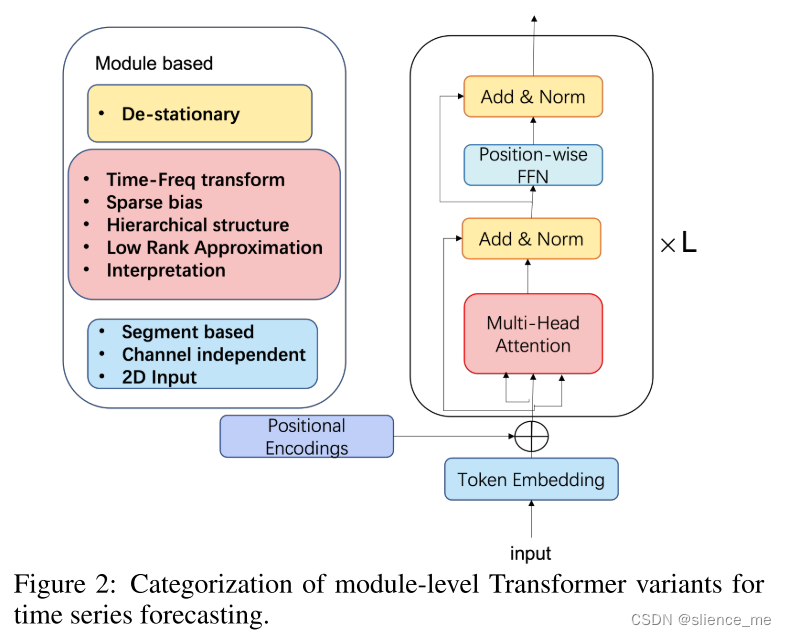
模块级别Transformer的第一种变体类型是设计新的注意力模块,这是比例最大的类别。以下首先描述了六个典型的工作:
-
LogTrans [Li等,2019]: 论文
- 提出了卷积自注意力,利用因果卷积生成自注意力层中的查询和键。
- 引入了稀疏偏置(Logsparse掩码),将计算复杂度从O(N2)降低到O(N logN)。
-
Informer [Zhou等,2021]: 论文
- 未使用显式的稀疏偏置,而是基于查询和键的相似性选择主要查询。
- 设计了一种生成式解码器,直接产生长期预测,避免了长期预测中的累积误差。
-
AST [Wu等,2020a]: 论文
- 使用生成对抗编码器-解码器框架,训练稀疏Transformer模型进行时间序列预测。
- 表明通过直接塑造网络的输出分布来避免通过一步推断导致误差积累,对于改善时间序列预测具有积极作用。
-
Pyraformer [Liu等,2022a]: 论文
- 设计了分层的金字塔式注意力模块,通过沿路径遵循二叉树来捕获不同范围的时间依赖关系。
- 具有线性时间和内存复杂性。
-
FEDformer [Zhou等,2022]: 论文
- 在频域中应用注意力操作,使用傅立叶变换和小波变换。
- 通过随机选择固定大小的频率子集实现了线性复杂度。
-
Quatformer [Chen等,2022]: 论文
- 提出了基于四元数的学习旋转注意力(LRA),引入可学习的周期和相位信息来描述复杂的周期模式。
- 使用全局内存解耦了LRA以实现线性复杂度。
第一类模块级别的变体旨在建立模型的显式解释能力,符合可解释人工智能(XAI)的趋势。其中有以下三项工作:
-
TFT [Lim等,2021]: 论文
- 设计了一个多时间跨度的预测模型,具有静态协变量编码器、门控特征选择和时间自注意解码器。
- 从各种协变量中编码和选择有用信息来执行预测。
- 通过整合全局、时间依赖和事件等信息,保持了可解释性。
-
ProTran [Tang和Matteson,2021] 和 SSDNet [Lin等,2021]:论文
- 将Transformer与状态空间模型(state space model)结合,提供概率预测。
- ProTran设计了一个基于变分推理的生成建模和推理过程。
- SSDNet首先使用Transformer学习时间模式,估计SSM的参数,然后应用SSM进行季节趋势分解,保持了可解释性。
-
SSDNet [Lin等,2021]:论文
- 将Transformer与状态空间模型结合,提供概率预测。
- 首先使用Transformer学习时间模式,估计SSM的参数,然后应用SSM进行季节趋势分解,保持了可解释性。
第二类模块级别的变体是标准化时间序列数据的方式。
目前据作者团队所知,唯一专注于修改标准化机制的工作是 Non-stationary Transformer [Liu等,2022b]。该工作探讨了时间序列预测任务中的过度平稳化问题,提出了相对简单的插件系列平稳化和非平稳化模块,以修改和提升各种注意力块的性能。
第三类模块级别的变体是利用令牌输入的偏差。其中:
-
Autoformer [Wu等,2021] 采用基于分段的表示机制,设计了一个简单的季节趋势分解架构,其中自相关机制充当注意力模块,通过度量输入信号的时延相似性,并聚合前k个相似的子序列,以降低复杂度。论文
-
PatchTST [Nie等,2023] 利用通道独立性,每个通道包含一个单变量时间序列,所有序列共享相同的嵌入,以及子序列级别的补丁设计,将时间序列分段成子序列级别的补丁,作为输入令牌输入到Transformer。这种ViT样式的设计在长时间序列预测任务中提高了数值性能。论文
-
Cross-former [Zhang和Yan,2023] 提出了一种基于Transformer的模型,利用跨维度依赖进行多变量时间序列预测。输入通过新颖的维度分段嵌入转换为二维向量数组,以保留时间和维度信息。然后,使用两阶段注意力层来有效地捕获跨时间和跨维度的依赖关系。论文
架构级变体
一些工作开始设计超出基本Transformer范围的新Transformer架构。其中:
-
Triformer [Cirstea等,2022]:论文
- 设计了一个三角形的、变量特定的补丁注意力。
- 使用三角形树状结构,随着后续输入尺寸呈指数级缩小。
- 通过一组变量特定的参数,使得多层Triformer保持轻量级和线性复杂度。
-
Scaleformer [Shabani等,2023]:论文
- 提出了一个多尺度框架,适用于基于Transformer的时间序列预测模型(如FEDformer [Zhou等,2022],Autoformer [Wu等,2021]等)。
- 通过共享权重,在多个尺度上迭代地细化预测的时间序列,以提高基线模型的性能。
时空预测 Spatio-Temporal Forecasting
在时空预测中,时间序列Transformer考虑了时间和时空依赖关系,以实现准确的预测。具体而言:
-
Traffic Transformer [Cai等,2020]:论文
- 设计了一个编码器-解码器结构,使用自注意力模块捕获时间-时间依赖关系,以及使用图神经网络模块捕获空间依赖关系。
-
Spatial-temporal Transformer [Xu等,2020]:论文
- 在交通流量预测中,引入了时间Transformer块以捕获时间依赖关系,并设计了一个空间Transformer块,结合图卷积网络,更好地捕获空间-空间依赖关系。
-
Spatio-temporal graph Transformer [Yu等,2020]:论文
- 设计了一个基于注意力的图卷积机制,能够学习复杂的时空注意力模式,以改善行人轨迹预测。
-
Earthformer [Gao等,2022]:论文
- 提出了一个立方体注意力机制,用于高效的时空建模,将数据分解成立方体,并并行应用立方体级别的自注意力。
- 在天气和气候预测中表现出优异的性能。
-
AirFormer [Liang等,2023]:论文
- 设计了一个飞镖形式的空间自注意力模块和一个因果形式的时间自注意力模块,以有效捕获空间相关性和时间依赖关系。
- 此外,它通过潜在变量增强了Transformer,以捕获数据的不确定性并改善空气质量预测。
事件预测 Event Forecasting
在许多实际应用中,事件序列数据具有不规则和异步的时间戳,这与具有相等采样间隔的规则时间序列数据形成对比。事件预测旨在根据过去事件的历史来预测未来事件的时间和标记,通常通过时间点过程(TPP)[Yan等,2019;Shchur等,2021]来建模。最近,一些神经TPP模型将Transformer纳入其中,以提高事件预测的性能。具体而言:
-
Self-attentive Hawkes process (SAHP) [Zhang等,2020] 和 Transformer Hawkes process (THP) [Zuo等,2020]:
- 采用Transformer编码器架构来总结历史事件的影响并计算事件预测的强度函数。
- 通过将时间间隔转换为正弦函数来修改位置编码,以利用事件之间的间隔。
-
Attentive neural datalog through time (ANDTT) [Mei等,2022]:
- 提出了一种更加灵活的方案,通过注意力将所有可能的事件和时间进行嵌入。
- 实验表明,它能够比现有方法更好地捕捉复杂的事件依赖关系。
5.2 异常检测中的Transformer
基于Transformer的架构也有助于时间序列异常检测任务,因为它能够建模时间依赖关系,从而提高检测质量。具体而言:
-
TranAD [Tuli等,2022]:论文
- 提出了一种对抗训练过程,通过增加重建误差来放大异常的小偏差。
- 使用两个Transformer编码器和两个Transformer解码器设计了GAN风格的对抗训练过程,以获得稳定性。
-
MT-RVAE [Wang等,2022] 和 TransAnomaly [Zhang等,2021]:
- 将变分自编码器(VAE)与Transformer相结合,以允许更多的并行化,并将训练成本降低近80%。
- MT-RVAE设计了一个多尺度Transformer来提取和整合不同尺度的时间序列信息,克服了传统Transformer只提取局部信息用于顺序分析的缺点。
-
GTA [Chen等,2021c]:
- 将Transformer与基于图的学习架构结合起来,用于多变量时间序列异常检测。
- GTA包含图卷积结构来建模影响传播过程,通过替换基础多头注意力机制,考虑了“全局”信息。
-
AnomalyTrans [Xu等,2022]:
- 结合Transformer和高斯先验关联,使异常更加可区分。
- 采用最小最大策略来优化异常模型,约束先验关联和序列关联,以获得更可区分的关联差异。
5.3 分类中的Transformer
Transformer已被证明在各种时间序列分类任务中具有有效性,因为它在捕捉长期依赖方面的显著能力。具体而言:
-
GTN [Liu等,2021]:
- 使用两塔Transformer,其中每个塔分别处理时间步级别的注意力和通道级别的注意力。
- 通过可学习的加权连接(也称为“门控”)来合并两塔的特征。
- 在13个多变量时间序列分类任务中实现了最先进的结果。
-
Rußwurm和Körner [2020]:
- 研究了基于自注意力的Transformer用于原始光学卫星时间序列分类,并与循环神经网络和卷积神经网络进行了比较,取得了最佳结果。
-
TARNet [Chowdhury等,2022]:
- 设计了Transformer来学习任务感知的数据重构,增强了分类性能。
- 利用注意力分数进行重要时间戳的掩蔽和重构,带来了更优越的性能。
另外,还研究了预训练的Transformer在分类任务中的应用:
-
Yuan和Lin [2020]:
- 研究了用于原始光学卫星图像时间序列分类的Transformer,并使用自监督预训练模式,因为标记数据有限。
-
Zerveas等 [2021]:
- 引入了无监督预训练框架,该模型使用按比例屏蔽的数据进行预训练。
- 预训练模型随后在分类等下游任务中进行微调。
-
Yang等 [2021]:
- 提出使用大规模预训练的语音处理模型解决下游时间序列分类问题,在30个流行的时间序列分类数据集上生成了19个具有竞争力的结果。
6 实验评估与讨论 Experimental Evaluation and Discussion
对典型的具有挑战性的基准数据集ETTm2 [Zhou等,2021] 进行了初步的实证研究,以分析Transformer如何处理时间序列数据。由于经典的统计ARIMA/ETS [Hyndman和Khandakar,2008]模型和基本的RNN/CNN模型在这个数据集上的表现不如Transformer,因此重点关注了实验中具有不同配置的流行时间序列Transformer。
鲁棒性分析
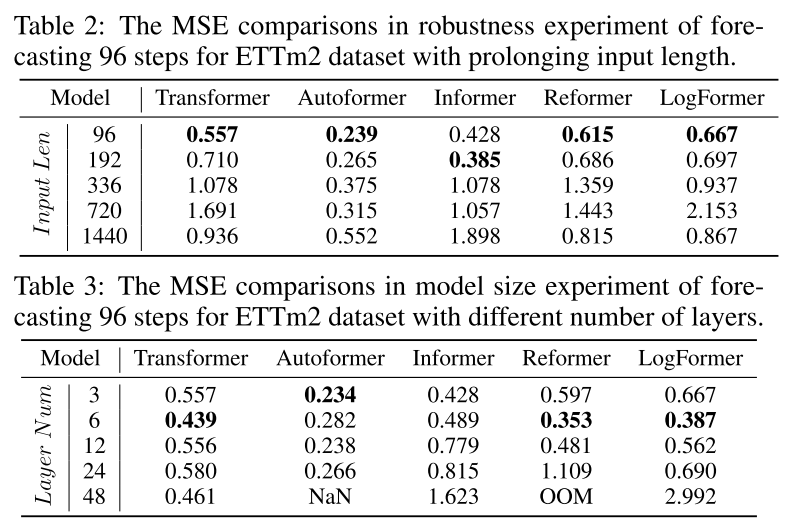
上面描述的许多工作都精心设计了注意力模块,以降低二次计算和内存复杂度,尽管它们实际上使用了一个短的固定大小的输入来在报告的实验中取得最佳结果。这让作者团队对这种高效设计的实际用途产生了疑问。进行了一项鲁棒性实验,延长了输入序列长度,以验证它们处理长期输入序列时的预测能力和鲁棒性。
模型大小分析
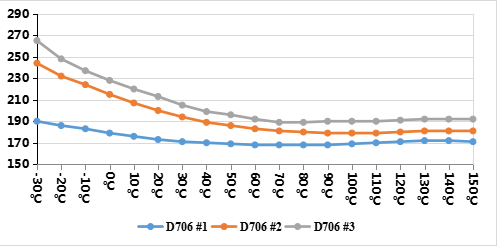
在被引入到时间序列预测领域之前,Transformer已经在NLP和CV社区表现出卓越的性能。Transformer在这些领域的一个关键优势是能够通过增加模型大小来提高预测能力。通常,模型容量由Transformer的层数控制,通常设置在12到128之间。然而,当在表3的实验中比较具有不同层数的不同Transformer模型的预测结果时,通常3到6层的Transformer会取得更好的结果。
季节性趋势分解分析
在最近的研究中,研究人员开始意识到季节性趋势分解是Transformer在时间序列预测中性能的关键部分。作为表4中的一个实验所示,采用了在[Wu等,2021]中提出的简单移动平均季节性趋势分解架构来测试各种注意力模块。可以看出,简单的季节性趋势分解模型可以显著提升模型的性能,提高50%到80%。这是一个独特的模块,通过分解来提升性能似乎是时间序列预测中Transformer应用的一个一致现象,值得进一步探索更先进和精心设计的时间序列分解方案。
7 未来研究机会 Future Research Opportunities
在时间序列中,Transformer 的未来研究方向可以从以下几个方面着手:
7.1 时间序列Transformer的归纳偏差
当前的基本Transformer对数据模式和特征没有任何假设。然而,时间序列数据的一个关键特征是其季节性/周期性和趋势模式。一些最近的研究表明,将系列周期性或频率处理纳入时间序列Transformer中可以显著提高性能。此外,一些研究采用了一种看似相反的归纳偏差,但都取得了良好的数值改进。因此,未来的一个方向是根据对时间序列数据的理解和特定任务特性,考虑更有效的方式将归纳偏差引入Transformer中。
7.2 用于时间序列的Transformer和GNN
在应用中,多变量和时空序列变得越来越常见,需要额外的技术来处理高维度数据,特别是捕获维度之间的潜在关系。引入图神经网络(GNN)是一种自然的方式来建模空间依赖性或维度之间的关系。最近的几项研究表明,GNN和Transformer/注意力的组合不仅可以带来显著的性能提升,如交通预测和多模态预测,还能更好地理解时空动态和潜在因果关系。将Transformer和GNN结合起来有效地进行时间序列的时空建模是一个重要的未来方向。
7.3 用于时间序列的预训练Transformer
大规模的预训练Transformer模型已经显著提升了NLP和CV等领域各种任务的性能。然而,针对时间序列的预训练Transformer研究有限,现有研究主要集中在时间序列分类上。因此,如何为时间序列中的不同任务开发适当的预训练Transformer模型,仍然需要在未来进行研究。
7.4 Transformer与体系结构级别的变体
大多数发展中的时间序列Transformer模型都保持了基本Transformer的架构,并主要在注意力模块上进行修改。因此,未来的一个方向是考虑更多的体系结构级别设计,专门针对时间序列数据和任务进行优化。
7.5 用于时间序列的NAS Transformers
超参数,如嵌入维度和头/层的数量,很大程度上会影响Transformer的性能。手动配置这些超参数是耗时的,而且往往导致次优性能。自动ML技术如神经架构搜索(NAS)已成为发现有效深度神经网络架构的流行技术。在近期的研究中,可以发现NLP和CV领域利用NAS自动化Transformer设计的研究。对于行业规模的时间序列数据,这是一个具有实际重要性的方向,自动发现既具有记忆又具有计算效率的Transformer架构,是时间序列Transformer的一个重要未来方向。
8 结论 Conclusion
former模型都保持了基本Transformer的架构,并主要在注意力模块上进行修改。因此,未来的一个方向是考虑更多的体系结构级别设计,专门针对时间序列数据和任务进行优化。
7.5 用于时间序列的NAS Transformers
超参数,如嵌入维度和头/层的数量,很大程度上会影响Transformer的性能。手动配置这些超参数是耗时的,而且往往导致次优性能。自动ML技术如神经架构搜索(NAS)已成为发现有效深度神经网络架构的流行技术。在近期的研究中,可以发现NLP和CV领域利用NAS自动化Transformer设计的研究。对于行业规模的时间序列数据,这是一个具有实际重要性的方向,自动发现既具有记忆又具有计算效率的Transformer架构,是时间序列Transformer的一个重要未来方向。
8 结论 Conclusion
作者团队提供了一份关于时间序列Transformer的调查报告。将审查的方法组织成一个新的分类体系,包括网络设计和应用。并总结了每个类别中的代表性方法,通过实验评估讨论它们的优点和局限性,并突出未来的研究方向。