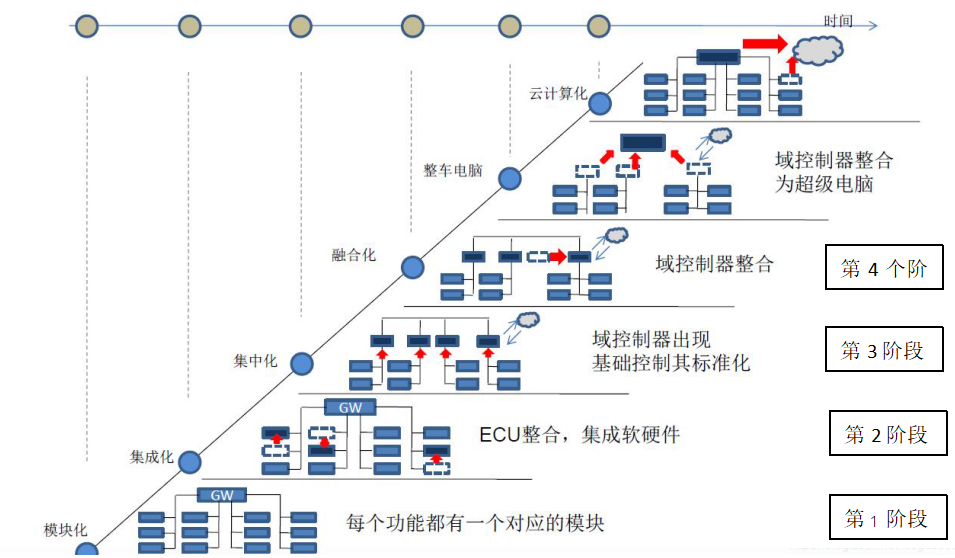
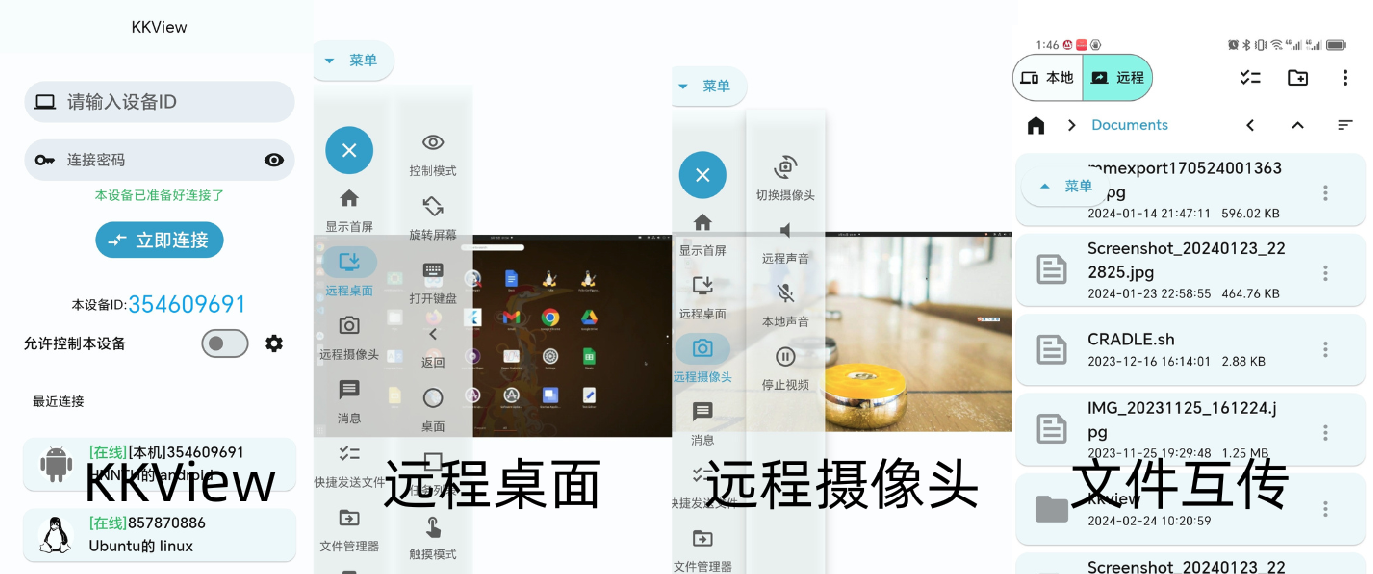
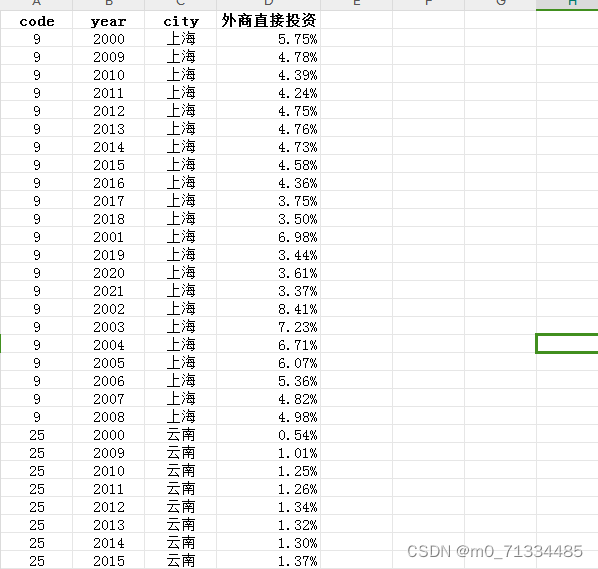
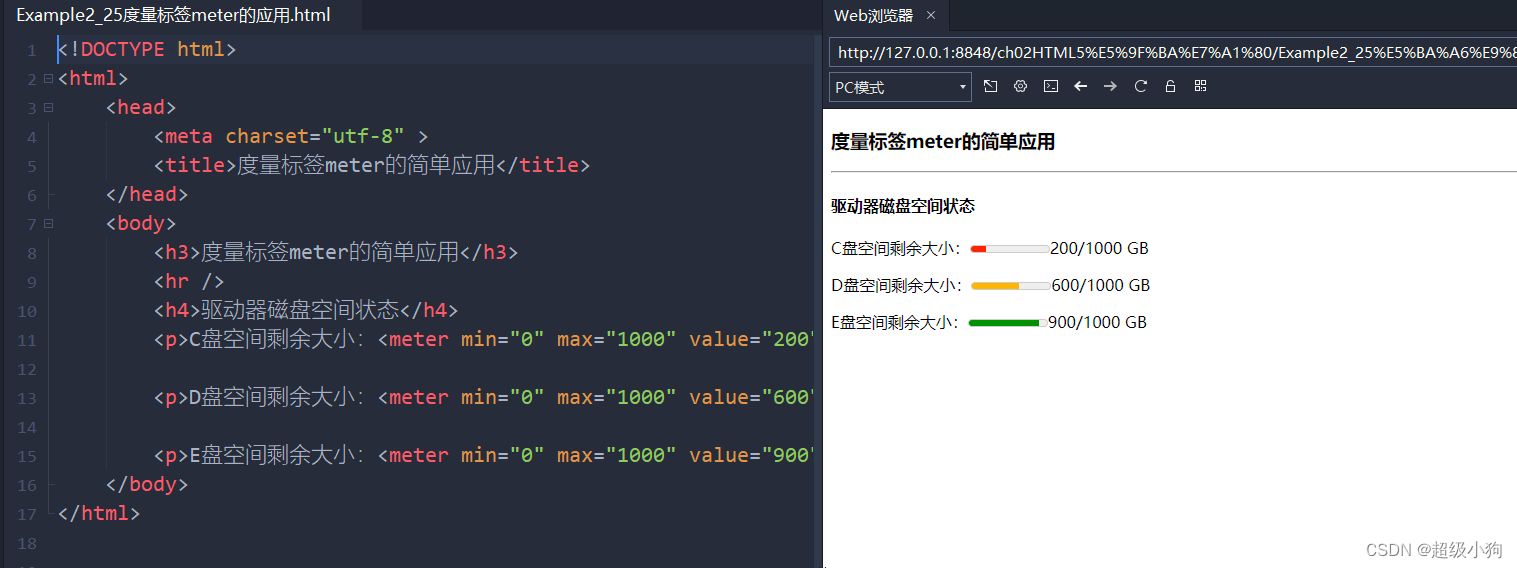
前言
在 pandas 中,向量化计算是指利用 pandas 对象的内置方法和函数,将操作应用到整个数据结构的每个元素,从而在单个操作中完成大量的计算。
但在一些需求中,我们无法使用向量化计算,就需要迭代操作,本例就是这样的一种情况。
需求:
- 第一行的值为所在行的 a + b
- 第二行及以后的值为 上一行的 c + a
思路:
- 本例不是一个向量化的计算,因为第一行的计算逻辑与其他行的计算逻辑不同。针对,这样的情况,我们可以用迭代的方法进行灵活的操作。
- 先根据第一行的计算逻辑增加 c 列,然后迭代并排除第一行,对其他行按计算逻辑进行修改。
二、使用步骤
读入数据
代码如下(示例):
import pandas as pddf = pd.DataFrame({'a': [5, 6, 7], 'b': [3, 5, 8]})
df

# 按第一行的计算逻辑增加 c 列:
df['c'] = df.a+df.b
df

# 迭代计算修改其他行:
# 遍历df的每一行,返回一个命名元组,命名元组的字段包括Index和DataFrame中的各列
for i in df.itertuples():if i.Index != 0:df.loc[i.Index, 'c'] = i.a + df.loc[i.Index-1, 'c'] # 当前行的'a'列值与上一行的'c'列值相加,并将结果赋值给当前行的'c'列
# 以上代码,df.itertuples() 产生一个可迭代 map 对象,每行是一个 namedtuple 类型数据。即:for i in df.itertuples():print(i)

# 接着判断如果索引不是第一行(值为 0)就用 loc 获取定位并进行修改,最后得到的数据为:df

总结
以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。