爬虫
从网站中获取
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
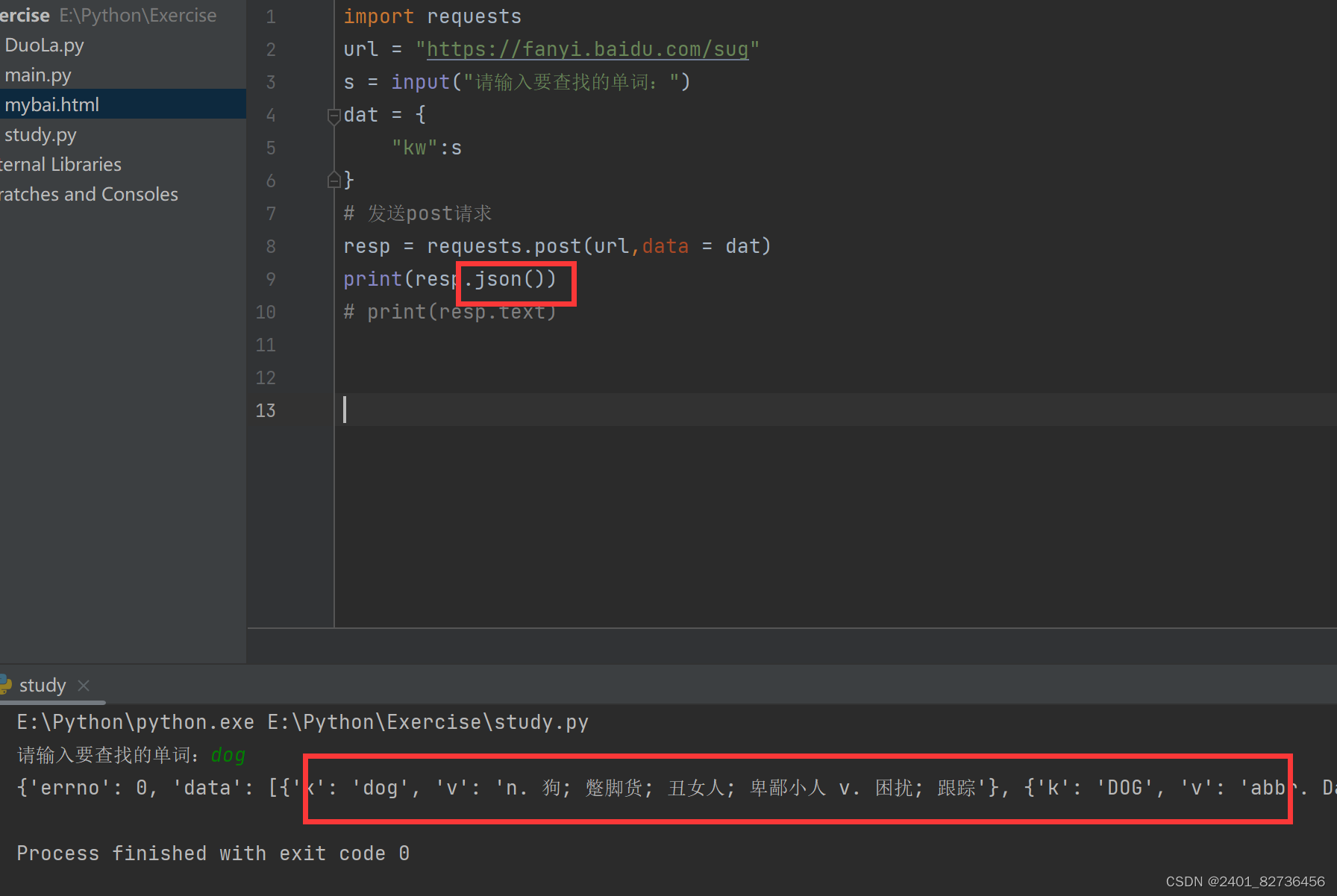
import java.util.regex.Pattern;public class date {public static void main(String[] args) throws IOException {//创建一个URL对象,获取网址URL url=new URL("https://zhuanlan.zhihu.com/p/465034540");//细节,保持网络畅通URLConnection conn=url.openConnection();//创建一个对象去读取网络中的数据BufferedReader br=new BufferedReader(new InputStreamReader(conn.getInputStream()));//获取正则表达式对象Pattern p=Pattern.compile("Java\\d{0,2}");//在读取时每次读一行String line;while((line=br.readLine())!=null){//文本适配器获取正则表达式规定文本Matcher m= p.matcher(line);while (m.find()){System.out.println(m.group());}}br.close();}
}
上述代码运行后即可获得Java?(?为空或数字)
带条件获取
只获取Java1和7,其他版本只要Java,可以这样写正则表达式"Java(?=1|7)"即可
java无视大小写可以这样写"((?i)Java)",
去掉1和7这样写"Java(?!1|7)"
只获取1和7,这样写"Java(?:1|7)"或者"Java(1|7)"
贪婪爬取
贪婪爬取:在爬取数据的时候尽可能多爬取数据
非贪婪爬取:在爬取数据的时候尽可能少爬取数据
例如:String str="abbbbbbbbb";
正则表达式为"ab+"会获取abbbbbbbbb
为"ab+?"则获取ab
正则表达式在字符串方法中使用
public String[] matches(String regex) //判断字符串是否满足正则表达式规则
public String replaceAll(String regex,String newStr) //按照正则表达式的规则进行替换
public String[] split(String regex) //按照正则表达式的规则切割字符串,数组接受
分组
正则表达式分组,每组是有组号的,也就是序号
规则:从一开始连续不间断,以左括号为基准,最左边为第一组,依次类推
(\组号):这一组内容和(\后面组号)的组内容相同
例如:(.+)(.+)(\\1) 即第三组与第一组一致
*:作用于某一组(写在后面),表示后面重复的内容出现0次或多次
例如:(.+)\\1*
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;import static java.util.regex.Pattern.matches;public class date {public static void main(String[] args) throws IOException {String s="(.+)(123)(\\1*)";System.out.println("aaa123aaaaaa". matches(s));//true}
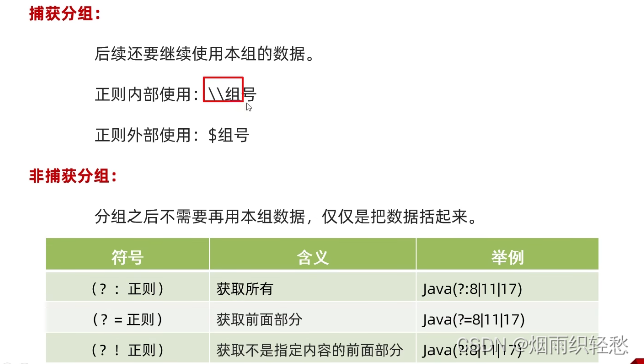
}捕获分组
正则内部使用:\\组号
正则外部使用:$组号
例如:String s="JJaaaaavvvvaaaa";
String str=s.reeplaceAll("(.)\\1+","$1");//str内容使Java