目录
- 一、前言
- 二、数据分析和深度学习的区别
- 三、人工智能
- 四、深度学习
- 五、Pandas
- 六、Pandas数据结构
- 6.1 Series - 序列
- 6.2 DataFrame - 数据框
- 七、输入、输出
- 7.1 读取/写入CSV
- 7.2 读取/写入Excel
- 7.3 读取和写入 SQL 查询及数据库表
- 八、调用帮助
- 九、选择(这里可以参考上一篇文章的 Numpy Arrays 相关部分)
- 9.1 取值
- 9.2 选取、布尔索引及设置值
- 9.2.1 按位置
- 9.2.2 按标签
- 9.2.3 按标签/位置
- 9.2.4 布尔索引
- 9.2.5 设置值
- 十、删除数据
- 十一、排序
- 十二、查询序列与数据框的信息
- 12.1 基本信息
- 12.2 汇总
- 十三、应用函数
- 十四、数据对齐
- 14.1 内部数据对齐
- 14.2 使用 Fill 方法运算
- 十五、后记
本文详细介绍了人工智能、数据分析和深度学习之间的关系,并就数据分析所需的Pandas库做了胎教般的入门引导。祝读得开心!
一、前言
本文是原 《数据分析大全》、现改名为 《数据分析》 专栏的第二篇,我在写这篇文章的时候突然意识到——单靠我是不可能把数据分析的方方面面都讲得明明白白,只是是我自己知道什么,然后再输出我所明白的知识罢了。所以《数据分析大全》的“大全”两个字还真是担不起,就改成 《数据分析》 了。
本篇主要介绍数据分析中 Python Pandas 相关知识点,打算通过这一篇帮助大家顺利入门Python Pandas,掌握基本的用法和思想。
上一期《数据分析大全》——Numpy基础可能讲的太过侧重代码而忽略了讲解,如果是还未入门的小白可能看完都不知道讲了啥、为什么要讲这些。
实用性强和门槛低才是好文章的必要因素,像之前的那一篇就太过强调实用了。结果文章是简短了,可除了已经入门或从事相关工作的同行外,没几个能明白讲了啥的。因此,本篇吸取之前的教训,在交稿前又认真地完善了文章的措辞,加上段落间的衔接和引例等语句,方便小白也能看懂。
让我先来填一下上期的坑,聊聊数据分析和深度学习都有什么区别和联系。
二、数据分析和深度学习的区别
数据分析也好,深度学习也罢,都是一种新的技术,而新技术的产生则是为了解决现实中遇到的问题。我们可以姑且把现实问题分为简单问题和复杂问题。简单问题,只需要简单分析,我们使用数据分析就够了。而复杂问题,则需要复杂分析,我们这才使用机器学习。
——那什么是简单问题,什么是复杂问题呢?
简单问题就比如是今年学院奖学金的评选情况、今天公司的业绩这类问题,数据量不是很大,我们就用数据分析。
而我们天天使用的某宝、某东这类购物APP,它会根据你的历史购物习惯(这里面有着海量的数据),来给推荐你可能感兴趣的商品。那是如何做到的呢?对于这种复杂问题,这类APP背后使用的就是机器学习以及相应的推荐算法。
三、人工智能
人工智能的范围很广,广义上的人工智能泛指通过计算机(机器)实现人的头脑思维,使机器像人一样去决策。
机器学习是实现人工智能的一种技术。在机器学习分很多方法(算法),不同的方法解决不同的问题。深度学习是机器学习中的一个分支方法。
总结一下:人工智能、机器学习和深度学习的关系是:人工智能包含机器学习,机器学习包含深度学习(方法),即数据分析>机器学习>深度学习>机器学习。
四、深度学习
深度学习在图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大量的人力做相关的研究和开发。
举个众人皆知的例子,那就是2016年谷歌旗下DeepMind公司开发的阿尔法围棋(AlphaGo)战胜人类顶尖围棋选手。阿尔法围棋的主要工作原理就是“深度学习”。

五、Pandas
咳咳,扯远了,本篇文章要讲的Pandas还没说呢。
在学习任何东西之前,我们都应该明白两个问题——它能干什么?我能用它做什么?
我相信肯定有人和我在入门数据结构时一样,对这个叫“Pandas”的库有很多问题——Pandas是什么?Pandas一词是怎么来的?Pandas是做什么的?…让我们来一起解决这些困惑。
首先,Pandas是什么?是Panda→熊猫吗?

这听起来很Cool…但很显然我们不可能用熊猫来帮助我们进行数据分析的工作。其实,Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
那么,Pandas 一词是怎么来的呢?
Pandas 名字的由来衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析。总的来说,Pandas 是一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
听起来明白点了,让我们再来看看 Pandas 究竟是干什么用的。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
让我们来总结一下:Pandas 是基于 Numpy 创建的 Python 库,为 Python 提供了易于使用的数据结构和数据分析工具。只需要记住这句话,就可以继续进行我们接下来的学习了!

在Python中,我们可以使用以下语句导入 Pandas 库:
>>> import pandas as pd
六、Pandas数据结构
6.1 Series - 序列
首先我们来看看序列,Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
让我们对上的参数进行简单的说明:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
想想看,要是实现存储任意类型数据的一维数组(如下图),应该怎么实现呢?
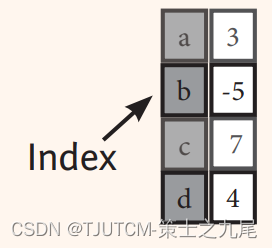
这边附上了实现代码:
>>> s = pd.Series([3, -5, 7, 4], index=['a', 'b', 'c', 'd'])
6.2 DataFrame - 数据框
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(比如数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
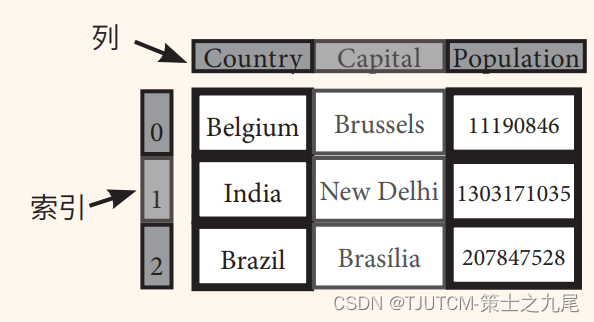
我们要是想实现上方的存储不同类型数据的二维数组,可以这么实现:
>>> data = {'Country': ['Belgium', 'India', 'Brazil'], 'Capital': ['Brussels', 'New Delhi', 'Brasília'],'Population': [11190846, 1303171035, 207847528]}>>> df = pd.DataFrame(data, columns=['Country', 'Capital', 'Population'])
七、输入、输出
7.1 读取/写入CSV
在解决这个问题前先来了解一下,什么是CSV:
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很轻松地处理CSV文件:
>>> pd.read_csv('file.csv', header=None, nrows=5)
>>> df.to_csv('myDataFrame.csv')
7.2 读取/写入Excel
在解决问题时,往往涉及到从Excel读取或写入数据,以下给出了相关的代码实现。也有读取内含多个表的Excel中数据的代码实现:
>>> pd.read_excel('file.xlsx')
>>> pd.to_excel('dir/myDataFrame.xlsx', sheet_name='Sheet1')
# 读取内含多个表的Excel
>>> xlsx = pd.ExcelFile('file.xls')
>>> df = pd.read_excel(xlsx, 'Sheet1')
7.3 读取和写入 SQL 查询及数据库表
关于读取和写入 SQL 查询及数据库表的代码如下:
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:')
>>> pd.read_sql("SELECT * FROM my_table;", engine)
>>> pd.read_sql_table('my_table', engine)
>>> pd.read_sql_query("SELECT * FROM my_table;", engine)
read_sql()是 read_sql_table() 与 read_sql_query() 的便捷打包器
>>> pd.to_sql('myDf', engine)
八、调用帮助
当然,在开发过程中遇到的问题肯定是千奇百怪的。除了在技术论坛上发帖求问、求助师兄师姐,我们也要学会自己查看帮助文档:

调用帮助的代码如下:
>>>help(pd.Series.loc)
九、选择(这里可以参考上一篇文章的 Numpy Arrays 相关部分)
9.1 取值
在取值时,我们可以取序列的值,也可以取数据框的值。以下是取序列值和取数据框子集的代码实现,可以参考一下:
# 取序列的值
>>> s['a']
-5# 取数据框的子集
>>> df[1:]Country Capital Population1 India New Delhi 13031710352 Brazil Brasília 207847528
9.2 选取、布尔索引及设置值
9.2.1 按位置
在我们根据需求选择某些数据时,往往涉及到按行与列的位置选择某值,以下给出了具体的代码:
# 按行与列的位置选择某值
>>> df.iloc[[0],[0]]
'Belgium'
>>> df.iat([0],[0])'Belgium'
9.2.2 按标签
按行与列的名称选择某值的代码实现如下:
# 按行与列的名称选择某值
>>> df.loc[[0], ['Country']]'Belgium'>>> df.at([0], ['Country']) 'Belgium'
9.2.3 按标签/位置
我们也可以选择某行或者选择某列:
# 选择某行
>>> df.ix[2] Country Brazil Capital Brasília Population 207847528# 选择某列
>>> df.ix[:,'Capital']0 Brussels1 New Delhi2 Brasília >>> df.ix[1,'Capital']'New Delhi'
9.2.4 布尔索引
Pandas支持物理顺序进行选取,也支持通过逻辑进行取值。下面给出了几个例子:
>>> s[~(s > 1)] # 序列 S 中没有大于1的值
>>> s[(s < -1) | (s > 2)] # 序列 S 中小于-1或大于2的值
>>> df[df['Population']>1200000000] # 序列 S 中小于-1或大于2的值
9.2.5 设置值
还可以设置索引项的值:
>>> s['a'] = 6 # 将序列 S 中索引为 a 的值设为6
十、删除数据
按索引删除序列的值:
>>> s.drop(['a', 'c']) # 按索引删除序列的值 (axis=0)
>>> df.drop('Country', axis=1) # 按索引删除序列的值 (axis=0)
十一、排序
基本的增删查改都介绍完了,这里再介绍以下排序。下面给出了按索引排序、按某列的值排序、按某列的值排序的另解的代码:
>>> df.sort_index() # 按索引排序
>>> df.sort_values(by='Country') # 按某列的值排序
>>> df.rank() # 按某列的值排序
十二、查询序列与数据框的信息
12.1 基本信息
排序也介绍完了,再来说说查询吧。这里给出了获取行、列索引和获取数据框基本信息的两种方法:
>>> df.shape # (行,列))
>>> df.index # 获取索引
>>> df.columns # 获取索引
>>> df.info() # 获取数据框基本信息
>>> df.count() # 获取数据框基本信息
12.2 汇总
常见的功能实现函数汇总如下:
>>> df.sum() # 合计
>>> df.cumsum() # 合计
>>> df.min()/df.max() # 最小值除以最大值
>>> df.idxmin()/df.idxmax() # 最小值除以最大值
>>> df.describe() # 基础统计数据
>>> df.mean() # 平均值
>>> df.median() # 中位数
十三、应用函数
这里给出了几个常用的函数的调用方法:
>>> f = lambda x: x*2 # 应用匿名函数lambda
>>> df.apply(f) # 应用函数
>>> df.applymap(f) # 应用函数
十四、数据对齐
14.1 内部数据对齐
如有不一致的索引,则使用NA值:
>>> s3 = pd.Series([7, -2, 3], index=['a', 'c', 'd'])
>>> s + s3a 10.0b NaNc 5.0d 7.0
14.2 使用 Fill 方法运算
还可以使用 Fill 方法进行内部对齐运算:
>>> s.add(s3, fill_value=0)a 10.0b -5.0c 5.0d 7.0
>>> s.sub(s3, fill_value=2)
>>> s.div(s3, fill_value=4)
>>> s.mul(s3, fill_value=3)
十五、后记
本期关于人工智能、数据分析和深度学习的关系,人工智能、深度学习的相关内容也介绍完了,本文的重点放在了 Pandas 的快速入门方面,如果能在科研项目、工程开发和日常学习方面帮到大家,就最好不过了!下期会接着介绍Pandas进阶方向的知识(因为这篇写得太多了,就拆成两篇发了)。
非常感谢大家的阅读,也欢迎大家提出宝贵的建议!我们下周见!