咱们接着这个系列的上一篇文章继续:
政安晨:【深度学习处理实践】(八)—— 表示单词组的两种方法:集合和序列![]() https://blog.csdn.net/snowdenkeke/article/details/136762323
https://blog.csdn.net/snowdenkeke/article/details/136762323
Transformer是一种架构,用于在自然语言处理(NLP)和其他任务中进行序列到序列(seq2seq)学习。它于2017年由Vaswani等人提出,成为深度学习领域的重要里程碑。
Transformer的核心思想是完全摒弃传统的循环神经网络(RNN)结构,并引入了自注意力机制来处理输入序列。它由编码器和解码器两部分组成,可用于多种任务,如机器翻译、文本生成和语言模型等。
编码器部分由多个相同的层组成,每层都包含一个多头自注意力机制和一个前馈神经网络。
自注意力机制允许模型在处理输入序列时关注不同位置的信息,而不像RNN那样依次处理。每个自注意力机制的输出被连接并输入到前馈神经网络中,以产生编码器的最终输出。
解码器部分与编码器类似,也由多个相同的层组成。除了自注意力机制和前馈神经网络外,每个解码器层还包含一个额外的自注意力机制,用于对编码器的输出进行注意。这样做的目的是在生成输出的同时,利用编码器的信息来提高模型的性能。
Transformer的训练使用了一种称为自回归的策略,即模型在生成目标序列时逐个预测。此外,Transformer还使用了残差连接和层归一化等技术,以加快训练过程和提高模型性能。
相较于传统的RNN模型,Transformer能够更好地处理长序列,且无需按顺序处理输入。其自注意力机制能够捕捉到序列中不同位置的依赖关系,从而提高了模型的表达能力。
因此,Transformer在NLP和其他序列任务中取得了很大的成功,并成为目前最主流的深度学习架构之一。
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
Transformer架构
咱们再啰嗦一下这个里程碑式的架构:
从2017年开始,一种新的模型架构开始在大多数自然语言处理任务中超越RNN,它就是Transformer。
Transformer由Ashish Vaswani等人的奠基性论文“Attention Is All You Need”引入。这篇论文的要点就在标题之中。事实证明,一种叫作神经注意力(neural attention)的简单机制可以用来构建强大的序列模型,其中并不包含任何循环层或卷积层。
这一发现在自然语言处理领域引发了一场革命,并且还影响到其他领域。神经注意力已经迅速成为深度学习最有影响力的思想之一。
咱们这篇文章将深入介绍它的工作原理,以及它为什么对序列数据如此有效。然后,我们将利用自注意力来构建一个Transformer编码器。它是Transformer架构的一个基本组件,我们会将其应用于一个IMDB影评分类任务。
理解自注意力
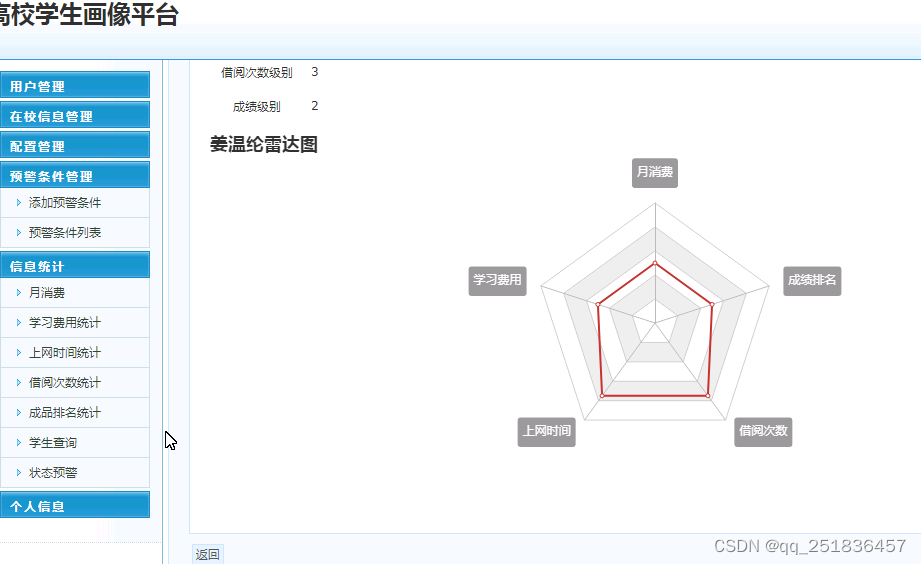
如果你的模型也这样做,那会怎么样?这个想法很简单但很强大:所有的模型输入信息并非对手头任务同样重要,所以模型应该对某些特征“多加注意”,对其他特征“少加注意”。
卷积神经网络中的最大汇聚:查看一块空间区域内的特征,并选择只保留一个特征。这是一种“全有或全无”的注意力形式,即保留最重要的特征,舍弃其他特征。
TF-IDF规范化:根据每个词元可能携带的信息量,确定词元的重要性分数。重要的词元会受到重视,而不相关的词元则会被忽视。这是一种连续的注意力形式。
有各种不同形式的注意力,但它们首先都要对一组特征计算重要性分数。
特征相关性越大,分数越高;
特征相关性越小,分数越低,如下图所示。如何计算和处理这个分数,则因方法而异。
(深度学习中的“注意力”的一般概念:为输入特征给定“注意力分数”,可利用这个分数给出输入的下一个表示)
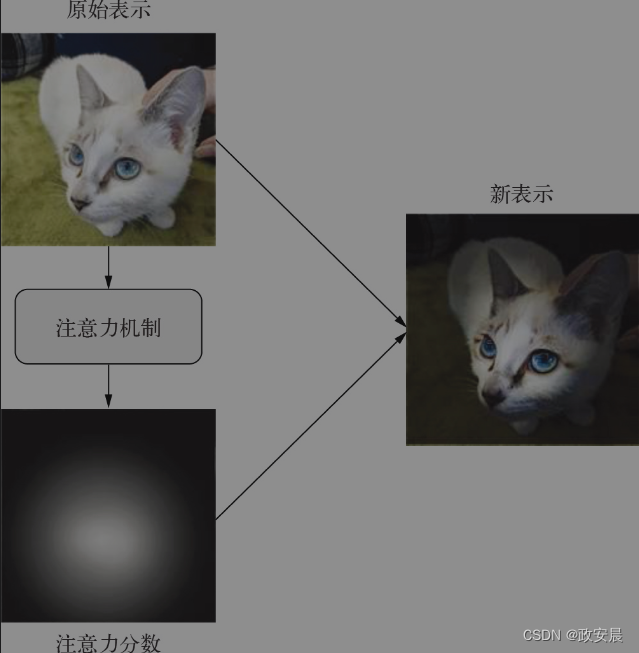
至关重要的是,这种注意力机制不仅可用于突出或抹去某些特征,还可以让特征能够上下文感知(context-aware)。
你刚刚学过词嵌入,即捕捉不同单词之间语义关系“形状”的向量空间。在嵌入空间中,每个词都有一个固定位置,与空间中其他词都有一组固定关系。
但语言并不是这样的:一个词的含义通常取决于上下文。
你说的“mark the date”(标记日期)与“go on a date”(去约会),二者中的“date”并不是同一个意思,与你在市场上买的date(椰枣)也不是同一个意思。当你说“I'll see you soon”(一会儿见)、“I'll see this project to its end”(我会一直跟着这个项目直到结束)或“I see what you mean”(我懂你的意思),这三个“see”的含义也有着微妙的差别。当然,“he”(他)、“it”(它)等代词的含义完全要看具体的句子,甚至在一个句子中含义也可能发生多次变化。
显然,一个好的嵌入空间会根据周围词的不同而为一个词提供不同的向量表示。这就是自注意力(self-attention)的作用。自注意力的目的是利用序列中相关词元的表示来调节某个词元的表示,从而生成上下文感知的词元表示。来看一个例句:“The train left the station on time”(火车准时离开了车站)。再来看句中的一个单词:“station”(站)。我们说的是哪种“station”?是“radio station”(广播站),还是“International Space Station”(国际空间站)?我们利用自注意力算法来搞清楚,如下图所示:
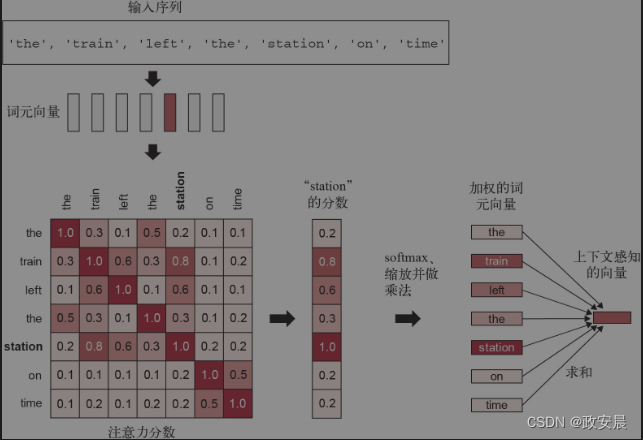
(自注意力:计算“station”与序列中其余每个单词之间的注意力分数,然后用这个分数对词向量进行加权求和,得到新的“station”向量)
第1步是计算“station”向量与句中其余每个单词之间的相关性分数。
这就是“注意力分数”。我们简单地使用两个词向量的点积来衡量二者的关系强度。它是一种计算效率很高的距离函数,而且早在Transformer出现之前,它就已经是将两个词嵌入相互关联的标准方法。在实践中,这些分数还会经过缩放函数和softmax运算,但目前先忽略这些实现细节。
第2步利用相关性分数进行加权,对句中所有词向量进行求和。
与“station”密切相关的单词对求和贡献更大(包括“station”这个词本身),而不相关的单词则几乎没有贡献。由此得到的向量是“station”的新表示,这种表示包含了上下文。具体地说,这种表示包含了“train”(火车)向量的一部分,表示它实际上是指“train station”(火车站)。
对句中每个单词重复这一过程,就会得到编码这个句子的新向量序列。
类似NumPy的伪代码如下:
def self_attention(input_sequence):output = np.zeros(shape=input_sequence.shape)# 对输入序列中的每个词元进行迭代for i, pivot_vector in enumerate(input_sequence):scores = np.zeros(shape=(len(input_sequence),))for j, vector in enumerate(input_sequence):# 计算该词元与其余每个词元之间的点积(注意力分数)scores[j] = np.dot(pivot_vector, vector.T)# (本行及以下1行)利用规范化因子进行缩放,并应用softmaxscores /= np.sqrt(input_sequence.shape[1]) scores = softmax(scores)new_pivot_representation = np.zeros(shape=pivot_vector.shape)for j, vector in enumerate(input_sequence):# 利用注意力分数进行加权,对所有词元进行求和new_pivot_representation += vector * scores[j] # 这个总和即为输出output[i] = new_pivot_representation return output当然,你在实践中需要使用向量化实现。
Keras有一个内置层来实现这种方法:MultiHeadAttention层。该层的用法如下:
num_heads = 4
embed_dim = 256
mha_layer = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
outputs = mha_layer(inputs, inputs, inputs)读到这里,你可能会有一些疑问。
为什么要向该层传递3次inputs?这似乎有些多余。我们所说的“多头”(multiple heads)是什么?听起来有点吓人——如果砍掉这些头,它们还会重新长出来吗?以上问题的答案都很简单,我们来看一下。
一般的自注意力:查询−键−值模型
到目前为止,我们只考虑了输入序列只有一个的情况。
但是,Transformer架构最初是为机器翻译而开发的,它需要处理两个输入序列:当前正在翻译的源序列(比如“How's the weather today?”)与需要将其转换成的目标序列(比如“¿Quétiempo hace hoy?”)。Transformer是一种序列到序列(sequence-to-sequence)模型,它的设计目的就是将一个序列转换为另一个序列。
咱们稍后会深入介绍序列到序列模型:
自注意力机制的作用如下所示:
outputs = sum(inputs * pairwise_scores(inputs, inputs))
这个表达式的含义是:“对于inputs(A)中的每个词元,计算该词元与inputs(B)中每个词元的相关程度,然后利用这些分数对inputs(C)中的词元进行加权求和。”重要的是,A、B、C不一定是同一个输入序列。
一般情况下,你可以使用3个序列,我们分别称其为查询(query)、键(key)和值(value)。这样一来,上述运算的含义就变为:“对于查询中的每个元素,计算该元素与每个键的相关程度,然后利用这些分数对值进行加权求和。”
outputs = sum(values * pairwise_scores(query, keys))这些术语来自搜索引擎和推荐系统,如下图所示。
(从数据库中检索图片:将“查询”与一组“键”进行对比,并将匹配分数用于对“值”(图片)进行排序)
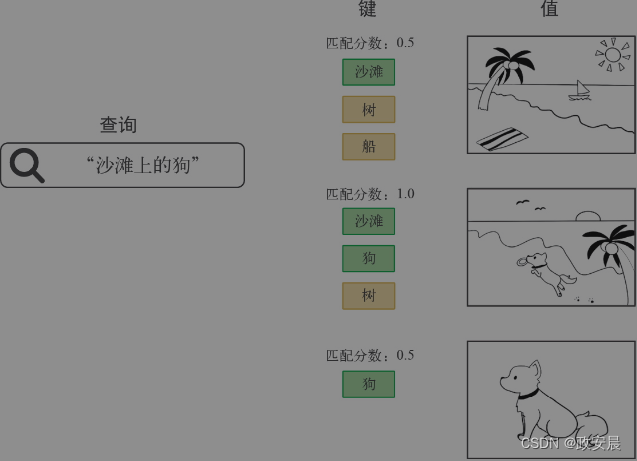
想象一下,你输入“沙滩上的狗”,想从数据库中检索一张图片。在数据库内部,每张照片都由一组关键词所描述——“猫”“狗”“聚会”等。我们将这些关键词称为“键”。搜索引擎会将你的查询和数据库中的键进行对比。“狗”匹配了1个结果,“猫”匹配了0个结果。然后,它会按照匹配度(相关性)对这些键进行排序,并按相关性顺序返回前n张匹配图片。
从概念上来说,这就是Transformer注意力所做的事情。你有一个参考序列,用于描述你要查找的内容:查询。你有一个知识体系,并试图从中提取信息:值。每个值都有一个键,用于描述这个值,并可以很容易与查询进行对比。你只需将查询与键进行匹配,然后返回值的加权和。
在实践中,键和值通常是同一个序列。
比如在机器翻译中,查询是目标序列,键和值则都是源序列:对于目标序列中的每个元素(如“tiempo”),你都希望回到源序列(“How's the weather today?”),并找到与其相关的元素(“tiempo”和“weather”应该有很强的匹配程度)。
当然,如果你只做序列分类,那么查询、键和值这三者是相同的:将一个序列与自身进行对比,用整个序列的上下文来丰富每个词元的表示。
这就解释了为什么要向MultiHeadAttention层传递3次inputs。但为什么叫它“多头注意力”呢?
多头注意力
“多头注意力”是对自注意力机制的微调,它由“Attention Is All You Need”这篇论文引入。
“多头”是指:自注意力层的输出空间被分解为一组独立的子空间,对这些子空间分别进行学习,也就是说,初始的查询、键和值分别通过3组独立的密集投影,生成3个独立的向量。每个向量都通过神经注意力进行处理,然后将多个输出拼接为一个输出序列。每个这样的子空间叫作一个“头”。
整体示意图如下图所示:
(MultiHeadAttention层)
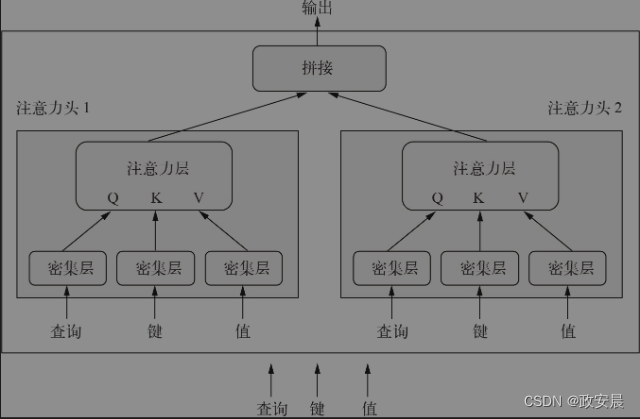
由于存在可学习的密集投影,因此该层能够真正学到一些内容,而不是单纯的无状态变换,后者需要在之前或之后添加额外的层才能发挥作用。
此外,独立的头有助于该层为每个词元学习多组特征,其中每一组内的特征彼此相关,但与其他组的特征几乎无关。
这在原理上与深度可分离卷积类似:
对于深度可分离卷积,卷积的输出空间被分解为多个独立学习的子空间(每个输入通道对应一个子空间)。
“Attention Is All You Need”这篇论文发表时,人们发现将特征空间分解为独立子空间的想法对计算机视觉模型有很大好处,无论是深度可分离卷积,还是另一种密切相关的方法,即分组卷积。多头注意力只是将同样的想法应用于自注意力。
Transformer编码器
如果添加密集投影如此有用,那为什么不在注意力机制的输出上也添加一两个呢?
实际上这是一个好主意,我们来这样做吧。
因为我们的模型已经做了很多工作,所以我们可能想添加残差连接,以确保不会破坏任何有价值的信息——咱们以前说过,对于任意足够深的架构,残差连接都是必需的。
咱们以前还介绍过,规范化层有助于梯度在反向传播中更好地流动。因此,我们也添加规范化层。
这大致就是我所想象的Transformer架构的发明者当时头脑中的思考过程。
将输出分解为多个独立空间、添加残差连接、添加规范化层——所有这些都是标准的架构模式,在任何复杂模型中使用这些模式都是明智的。这些模式共同构成了Transformer编码器(Transformer encoder),它是Transformer架构的两个关键组件之一,如下图所示:
(TransformerEncoder将MultiHeadAttention层与密集投影相连接,并添加规范化和残差连接)

最初的Transformer架构由两部分组成:
一个是Transformer编码器,负责处理源序列;
另一个是Transformer解码器(Transformer decoder),负责利用源序列生成翻译序列。
我们很快会介绍关于解码器的内容。
重要的是,编码器可用于文本分类——它是一个非常通用的模块,接收一个序列,并学习将其转换为更有用的表示。我们来实现一个Transformer编码器,并尝试将其应用于影评情感分类任务,如下代码所示:
(将Transformer编码器实现为Layer子类)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layersclass TransformerEncoder(layers.Layer):def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):super().__init__(**kwargs)# 输入词元向量的尺寸self.embed_dim = embed_dim# 内部密集层的尺寸self.dense_dim = dense_dim# 注意力头的个数self.num_heads = num_headsself.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)self.dense_proj = keras.Sequential([layers.Dense(dense_dim, activation="relu"),layers.Dense(embed_dim),])self.layernorm_1 = layers.LayerNormalization()self.layernorm_2 = layers.LayerNormalization()# 在call()中进行计算def call(self, inputs, mask=None):# (本行及以下1行) Embedding层生成的掩码是二维的,但注意力层的输入应该是三维或四维的,所以我们需要增加它的维数if mask is not None:mask = mask[:, tf.newaxis, :]attention_output = self.attention(inputs, inputs, attention_mask=mask)proj_input = self.layernorm_1(inputs + attention_output)proj_output = self.dense_proj(proj_input)return self.layernorm_2(proj_input + proj_output)# 实现序列化,以便保存模型def get_config(self):config = super().get_config()config.update({"embed_dim": self.embed_dim,"num_heads": self.num_heads,"dense_dim": self.dense_dim,})return config保存自定义层
在编写自定义层时,一定要实现get_config()方法:这样我们可以利用config字典将该层重新实例化,这对保存和加载模型很有用。该方法返回一个Python字典,其中包含用于创建该层的构造函数的参数值。
所有Keras层都可以被序列化(serialize)和反序列化(deserialize),如下所示:
config = layer.get_config()# config不包含权重值,因此该层的所有权重都是从头初始化的
new_layer = layer.__class__.from_config(config)来看下面这个例子:
layer = PositionalEmbedding(sequence_length, input_dim, output_dim)
config = layer.get_config()
new_layer = PositionalEmbedding.from_config(config)在保存包含自定义层的模型时,保存文件中会包含这些config字典。从文件中加载模型时,你应该在加载过程中提供自定义层的类,以便其理解config对象,如下所示:
model = keras.models.load_model(filename, custom_objects={"PositionalEmbedding": PositionalEmbedding})你会注意到,这里使用的规范化层并不是之前在图像模型中使用的BatchNormalization层。
这是因为BatchNormalization层处理序列数据的效果并不好。
相反,我们使用的是LayerNormalization层,它对每个序列分别进行规范化,与批量中的其他序列无关。
它类似NumPy的伪代码如下:
# 输入形状:(batch_size, sequence_length, embedding_dim)
def layer_normalization(batch_of_sequences):# (本行及以下1行)计算均值和方差,仅在最后一个轴(−1轴)上汇聚数据mean = np.mean(batch_of_sequences, keepdims=True, axis=-1) variance = np.var(batch_of_sequences, keepdims=True, axis=-1)return (batch_of_sequences - mean) / variance下面是训练过程中的BatchNormalization的伪代码,你可以将二者对比一下:
# 输入形状:(batch_size, height, width, channels)
def batch_normalization(batch_of_images): # (本行及以下1行)在批量轴(0轴)上汇聚数据,这会在一个批量的样本之间形成相互作用mean = np.mean(batch_of_images, keepdims=True, axis=(0, 1, 2)) variance = np.var(batch_of_images, keepdims=True, axis=(0, 1, 2))return (batch_of_images - mean) / varianceBatchNormalization层从多个样本中收集信息,以获得特征均值和方差的准确统计信息,而LayerNormalization层则分别汇聚每个序列中的数据,更适用于序列数据。
我们已经实现了TransformerEncoder,下面可以用它来构建一个文本分类模型,如下代码所示,它与前面的基于GRU的模型类似。
(将Transformer编码器用于文本分类)
vocab_size = 20000
embed_dim = 256
num_heads = 2
dense_dim = 32inputs = keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)# TransformerEncoder返回的是完整序列,所以我们需要用全局汇聚层将每个序列转换为单个向量,以便进行分类
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",loss="binary_crossentropy",metrics=["accuracy"])
model.summary()我们来训练这个模型,如下代码所示。模型的测试精度为87.5%,比GRU模型略低。
(训练并评估基于Transformer编码器的模型)
callbacks = [keras.callbacks.ModelCheckpoint("transformer_encoder.keras",save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,callbacks=callbacks)
model = keras.models.load_model("transformer_encoder.keras",# 在模型加载过程中提供自定义的TransformerEncoder类custom_objects={"TransformerEncoder": TransformerEncoder})
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")现在你应该已经开始感到有些不对劲了。你能看出是哪里不对劲吗?
咱们这篇文章的主题是“序列模型”。
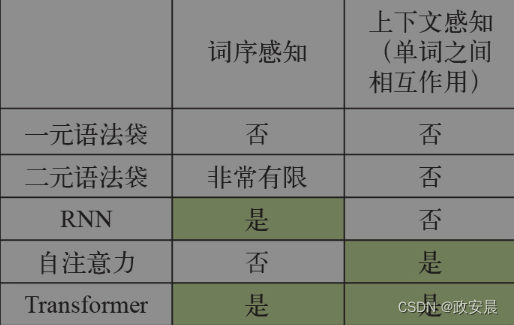
咱们一开始就强调了词序的重要性。但是,Transformer是一种序列处理架构,最初是为机器翻译而开发的。然而……你刚刚见到的Transformer编码器根本就不是一个序列模型。你注意到了吗?它由密集层和注意力层组成,前者独立处理序列中的词元,后者则将词元视为一个集合。你可以改变序列中的词元顺序,并得到完全相同的成对注意力分数和完全相同的上下文感知表示。如果将每篇影评中的单词完全打乱,模型也不会注意到,得到的精度也完全相同。自注意力是一种集合处理机制,它关注的是序列元素对之间的关系,如下图所示,它并不知道这些元素出现在序列的开头、结尾还是中间。
既然是这样,为什么说Transformer是序列模型呢?如果它不查看词序,又怎么能很好地进行机器翻译呢?
(各类NLP模型的特点)
咱们前面提示过解决方案。Transformer是一种混合方法,它在技术上是不考虑顺序的,但将顺序信息手动注入数据表示中。这就是缺失的那部分,它叫作位置编码(positional encoding)。
我们来看一下:
使用位置编码重新注入顺序信息
位置编码背后的想法非常简单:
为了让模型获取词序信息,我们将每个单词在句子中的位置添加到词嵌入中。这样一来,输入词嵌入将包含两部分:普通的词向量,它表示与上下文无关的单词;位置向量,它表示该单词在当前句子中的位置。我们希望模型能够充分利用这一额外信息。
你能想到的最简单的方法就是将单词位置与它的嵌入向量拼接在一起。你可以向这个向量添加一个“位置”轴。在该轴上,序列中的第一个单词对应的元素为0,第二个单词为1,以此类推。
然而,这种做法可能并不理想,因为位置可能是非常大的整数,这会破坏嵌入向量的取值范围。如你所知,神经网络不喜欢非常大的输入值或离散的输入分布。
在“Attention Is All You Need”这篇原始论文中,作者使用了一个有趣的技巧来编码单词位置:将词嵌入加上一个向量,这个向量的取值范围是[-1, 1],取值根据位置的不同而周期性变化(利用余弦函数来实现)。
这个技巧提供了一种思路,通过一个小数值向量来唯一地描述较大范围内的任意整数。这种做法很聪明,但并不是本例中要用的。
我们的方法更加简单,也更加有效:我们将学习位置嵌入向量,其学习方式与学习嵌入词索引相同。然后,我们将位置嵌入与相应的词嵌入相加,得到位置感知的词嵌入。这种方法叫作位置嵌入(positional embedding)。
我们来实现这种方法,如下代码所示(将位置嵌入实现为Layer子类):
class PositionalEmbedding(layers.Layer):# 位置嵌入的一个缺点是,需要事先知道序列长度def __init__(self, sequence_length, input_dim, output_dim, **kwargs): super().__init__(**kwargs)# 准备一个Embedding层,用于保存词元索引self.token_embeddings = layers.Embedding( input_dim=input_dim, output_dim=output_dim)self.position_embeddings = layers.Embedding(# 另准备一个Embedding层,用于保存词元位置input_dim=sequence_length, output_dim=output_dim) self.sequence_length = sequence_lengthself.input_dim = input_dimself.output_dim = output_dimdef call(self, inputs):length = tf.shape(inputs)[-1]positions = tf.range(start=0, limit=length, delta=1)embedded_tokens = self.token_embeddings(inputs)embedded_positions = self.position_embeddings(positions)# 将两个嵌入向量相加return embedded_tokens + embedded_positions # (本行及以下1行)与Embedding层一样,该层应该能够生成掩码,从而可以忽略输入中填充的0。框架会自动调用compute_mask方法,并将掩码传递给下一层def compute_mask(self, inputs, mask=None): return tf.math.not_equal(inputs, 0)# 实现序列化,以便保存模型def get_config(self): config = super().get_config()config.update({"output_dim": self.output_dim,"sequence_length": self.sequence_length,"input_dim": self.input_dim,})return config你可以像使用普通Embedding层一样使用这个PositionEmbedding层。
我们来看一下它的实际效果。
综合示例:文本分类Transformer
要将词序考虑在内,你只需将Embedding层替换为位置感知的PositionEmbedding层,如下代码所示(将Transformer编码器与位置嵌入相结合):
vocab_size = 20000
sequence_length = 600
embed_dim = 256
num_heads = 2
dense_dim = 32inputs = keras.Input(shape=(None,), dtype="int64")
# 注意这行代码!
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",loss="binary_crossentropy",metrics=["accuracy"])
model.summary()callbacks = [keras.callbacks.ModelCheckpoint("full_transformer_encoder.keras",save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,callbacks=callbacks)
model = keras.models.load_model("full_transformer_encoder.keras",custom_objects={"TransformerEncoder": TransformerEncoder,"PositionalEmbedding": PositionalEmbedding})
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")模型的测试精度为88.3%。这是一个相当不错的改进,它清楚地表明了词序信息对文本分类的价值。这是迄今为止最好的序列模型,但仍然比词袋方法差一点。
何时使用序列模型而不是词袋模型
有时你会听到这样的说法:词袋方法已经过时了,无论是哪种任务和数据集,基于Transformer的序列模型才是正确的选择。事实绝非如此:在很多情况下,在二元语法袋之上堆叠几个Dense层,仍然是一种完全有效且有价值的方法。
事实上,本章在IMDB数据集上尝试的各种方法中,到目前为止性能最好的就是二元语法袋。
应该如何在序列模型和词袋模型之中做出选择呢?
2017年,我和我的团队系统分析了各种文本分类方法在不同类型的文本数据集上的性能。我们发现了一个显著、令人惊讶的经验法则,可用于决定应该使用词袋模型还是序列模型——它是一个黄金常数。
事实证明,在处理新的文本分类任务时,你应该密切关注训练数据中的样本数与每个样本的平均词数之间的比例,如下图所示。
(选择文本分类模型的简单启发式方法:训练样本数与样本的平均词数之间的比例)
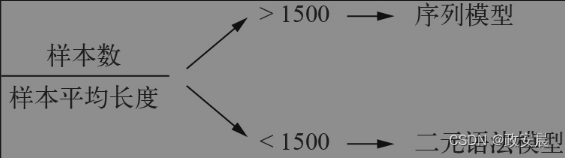
如果这个比例很小(小于1500),那么二元语法模型的性能会更好(它还有一个优点,那就是训练速度和迭代速度更快)。如果这个比例大于1500,那么应该使用序列模型。换句话说,如果拥有大量可用的训练数据,并且每个样本相对较短,那么序列模型的效果更好。
如果想对包含1000个词的文件进行分类,并且你有100 000份文件(比例为100),那么应该使用二元语法模型。如果想对平均长度为40个单词的推文进行分类,并且有50 000条推文(比例为1250),那么也应该使用二元语法模型。但如果数据集规模增加到500 000条推文(比例为12 500),那么就应该使用Transformer编码器。对于IMDB影评分类任务,应该如何选择呢?我们有20 000个训练样本,平均词数为233,所以根据我们的经验法则,应该使用二元语法模型,这也证实了我们在实践中的结果。
这在直觉上是有道理的:
序列模型的输入代表更加丰富、更加复杂的空间,因此需要更多的数据来映射这个空间;
与此相对,普通的词集是一个非常简单的空间,只需几百或几千个样本即可在其中训练logistic回归模型。
此外,样本越短,模型就越不能舍弃样本所包含的任何信息——特别是词序变得更加重要,舍弃词序可能会产生歧义。对于“this movie is the bomb”和“this movie was a bomb”这两个句子,它们的一元语法表示非常接近,词袋模型可能很难分辨,但序列模型可以分辨出哪句是负面的、哪句是正面的。对于更长的样本,词频统计会变得更加可靠,而且仅从词频直方图来看,主题或情绪会变得更加明显。
现在请记住,这个启发式规则是针对文本分类任务的。它不一定适用于其他NLP任务。举例来说,对于机器翻译而言,与RNN相比,Transformer尤其适用于非常长的序列。这个启发式规则只是经验法则,而不是科学规律,所以我们希望它在大多数时候有效,但不一定每次都有效。
咱们先到这里。