📖 前言:MapReduce是一种分布式并行编程模型,是Hadoop核心子项目之一。实验前需确保搭建好Hadoop 3.3.5环境、安装好Eclipse IDE
🔎 【Hadoop大数据技术】——Hadoop概述与搭建环境(学习笔记)
目录
- 🕒 1. 在Eclipse中搭建MapReduce环境
- 🕒 2. 倒排索引
- 🕘 2.1 案例分析
- 🕤 2.1.1 Map阶段
- 🕤 2.1.2 Combine阶段
- 🕤 2.1.3 Reduce阶段
- 🕘 2.2 案例实现
- 🕤 2.2.1 Map阶段实现
- 🕤 2.2.2 Combine阶段实现
- 🕤 2.2.3 Reduce阶段实现
- 🕤 2.2.4 Runner程序主类实现
- 🕒 3. 数据去重
- 🕘 3.1 案例分析
- 🕤 3.1.1 Map阶段
- 🕤 3.1.2 Reduce阶段
- 🕘 3.2 案例实现
- 🕤 3.2.1 Map阶段实现
- 🕤 3.2.2 Reduce阶段实现
- 🕤 3.2.3 Runner程序主类实现
- 🕒 4. TopN
- 🕘 4.1 案例分析
- 🕘 4.2 案例实现
- 🕤 4.2.1 Map阶段实现
- 🕤 4.2.2 Reduce阶段实现
- 🕤 4.2.3 Runner程序主类实现
🕒 1. 在Eclipse中搭建MapReduce环境
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin
下载后,将插件复制到 Eclipse 安装目录的 plugins 文件夹中
🔎 点击获取软件 提取码: 09oy
sudo mv hadoop-eclipse-plugin-2.7.3.jar /opt/eclipse/plugins/
之后重启eclipse完成插件导入。
在继续配置前请确保已经开启了 Hadoop
hadoop@Hins-vm:/usr/local/hadoop$ ./sbin/start-dfs.sh
插件需要进一步的配置。
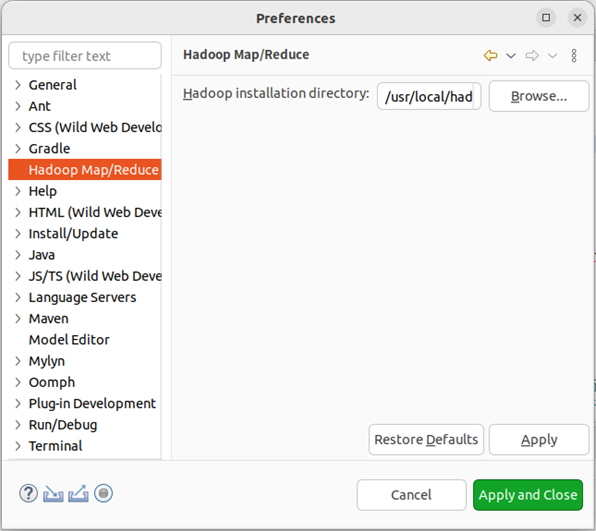
第一步:选择 Window 菜单下的 Preference。
此时会弹出一个窗口,窗口的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录(如//usr/local/hadoop)。
第二步:切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Window -> Perspective -> Open Perspective -> Other,弹出一个窗口,从中选择 Map/Reduce 选项即可进行切换。
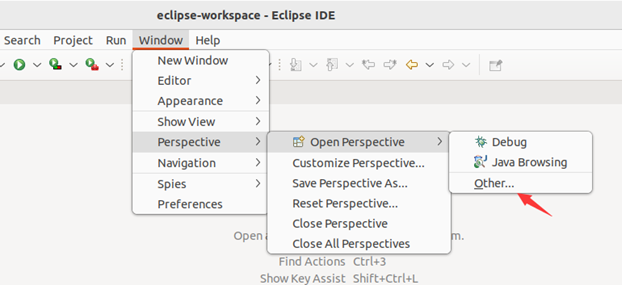
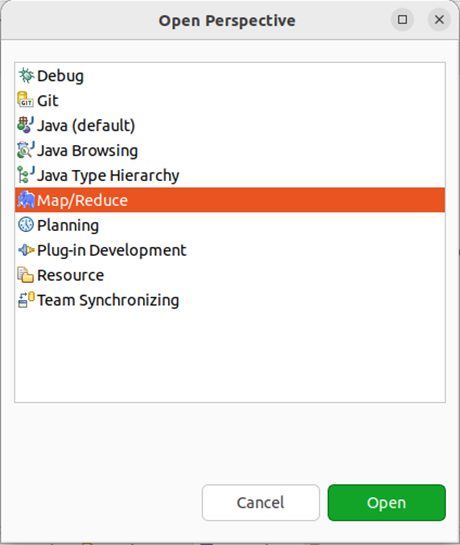
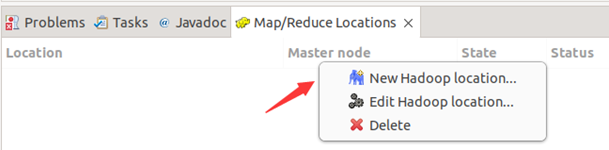
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
在弹出来的 General 选项面板中,General 的设置要与 Hadoop 的配置一致。一般两个 Host 值是一样的,如果是伪分布式,填写 localhost 即可,本文使用Hadoop伪分布式配置,设置 fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 的 Port 要改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
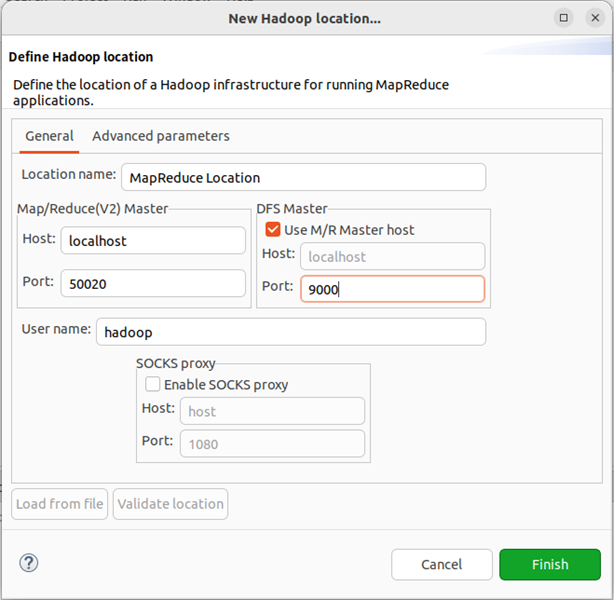
点击 finish,Map/Reduce Location 就创建好了。
在 Eclipse 中操作 HDFS 中的文件:
配置好后,点击左侧 Project Explorer 中的 MapReduce Location 就能直接查看 HDFS 中的文件列表了,双击可以查看内容,右键点击可以上传、下载、删除 HDFS 中的文件,无需再通过繁琐的 hdfs dfs -ls 等命令进行操作了。
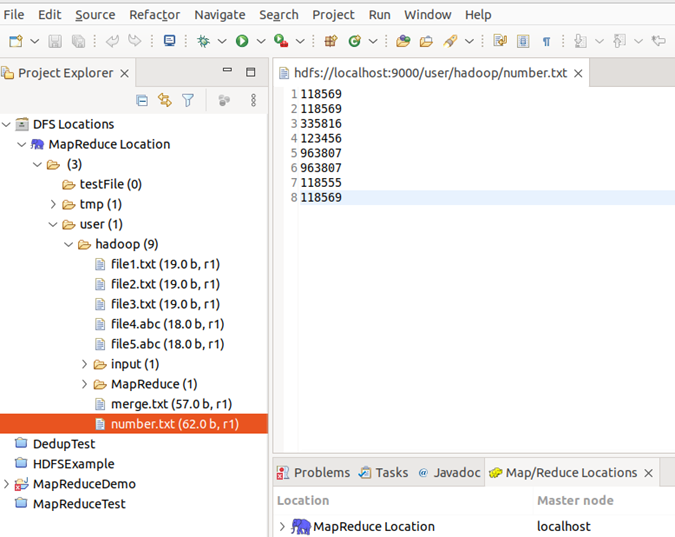
注:HDFS 中的内容变动后,Eclipse 不会同步刷新,需要右键点击 Project Explorer中的 MapReduce Location,选择 Refresh,才能看到变动后的文件。
🕒 2. 倒排索引
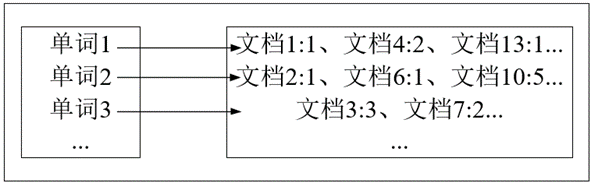
倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词或词组在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据文档来确定内容,因此称为倒排索引(Inverted Index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(Inverted File)。
倒排文件由一个单词或词组和相关联的文档列表组成。
在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度。最常用的是使用词频作为权重,即记录单词或词组在文档中出现的次数,用户在搜索相关文档时,就会把权重高的推荐给客户。
🕘 2.1 案例分析
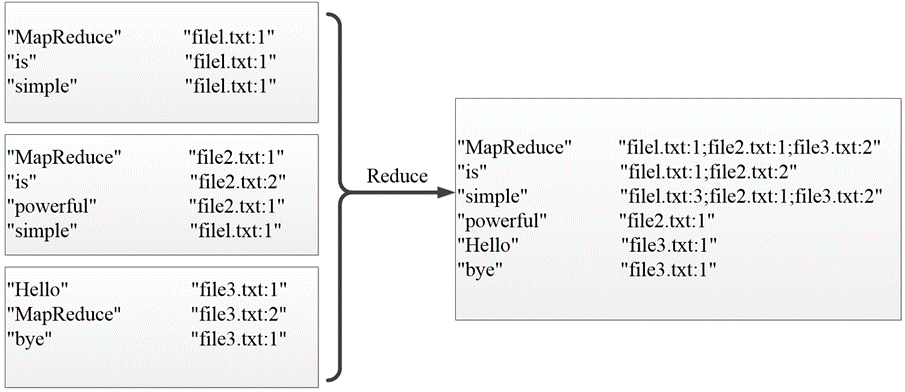
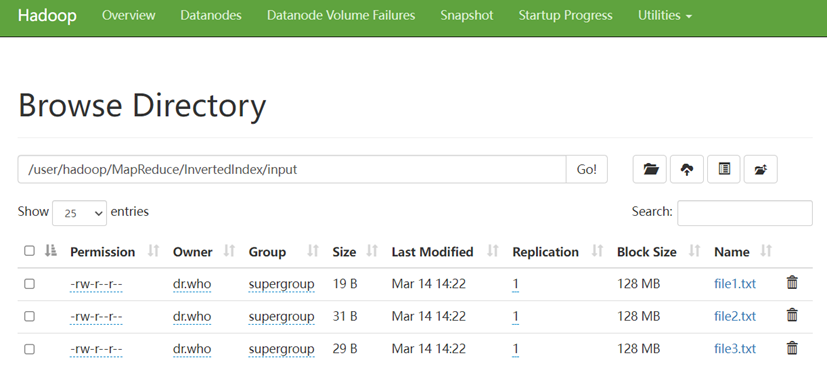
现有三个源文件file1.txt、file2.txt和file3.txt,需要使用倒排索引的方式对这三个源文件内容实现倒排索引,并将最后的倒排索引文件输出。
file1.txt
MapReduce is simple
file2.txt
MapReduce is powerful is simple
file3.txt
Hello MapReduce bye MapReduce
使用实现倒排索引的MapReduce程序统计文件file1.txt、file2.txt和file3.txt中每个单词所在文本的位置以及各文本中出现的次数。

🕤 2.1.1 Map阶段
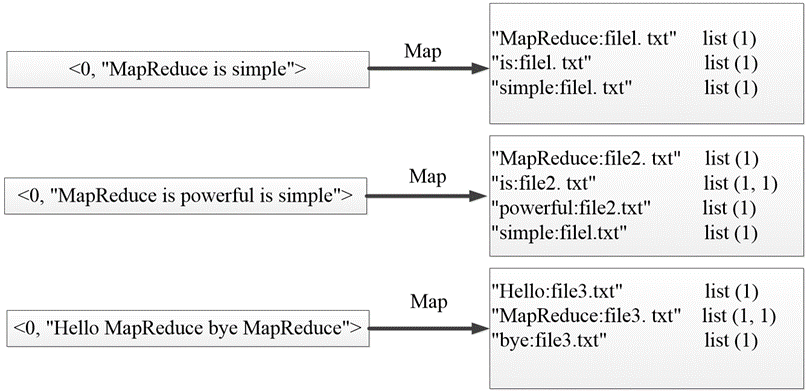
MapTask使用默认的lnputFormat组件对每个文本文件进行处理,得到文本中的每行数据的起始偏移量及其内容,作为Map阶段输入的键值对,进一步得到倒排索引中需要的3个信息:单词、文档名称和词频。
🕤 2.1.2 Combine阶段
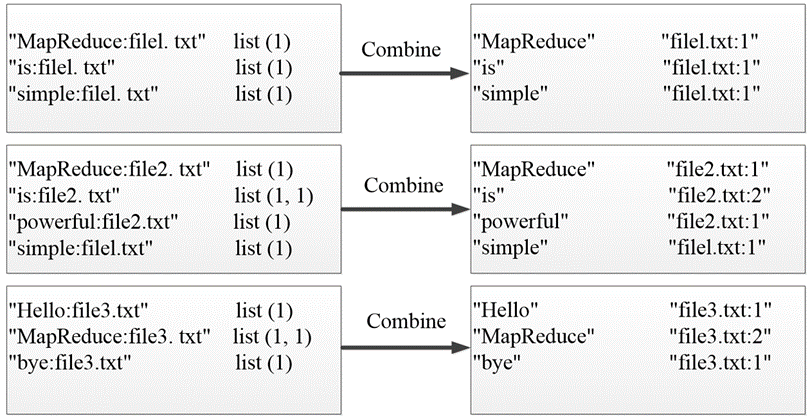
经过Map阶段数据转换后,同一个文档中相同的单词会出现多个的情况,单纯依靠后续ReduceTask同时完成词频统计和生成文档列表会耗费大量时间,因此可以通过Combiner组件先完成每一个文档中的词频统计。
🕤 2.1.3 Reduce阶段
经过上述两个阶段的处理后,Reduce阶段只需将所有文件中相同key值的value值进行统计,并组合成倒排索引文件所需的格式即可。
🕘 2.2 案例实现
首先,我们创建好这些源文件,设置好路径并上传至HDFS的input中。
在 Eclipse 中创建项目,点击 File 菜单,选择 New -> Project,选择 Map/Reduce Project,点击 Next。
取名MapReduceDemo,点击 Finish。
此时在左侧的 Project Explorer 就能看到刚才建立的项目了。接着右键点击刚创建的 MapReduce 项目 src,选择 New -> Package,在 Package 处填写 com.mapreduce.invertedindex;
🕤 2.2.1 Map阶段实现
在 com.mapreduce.invertedindex包下新建自定义类Mapper类InvertedIndexMapper,该类继承Mapper类
该类的作用:将文本中的单词按照空格进行切割,并以冒号拼接,“单词:文档名称”作为key,单词次数作为value,都以文本方式传输至Combine阶段。
package com.mapreduce.invertedindex;import java.io.IOException;import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {private static Text keyInfo = new Text();// 存储单词和URL组合private static final Text valueInfo = new Text("1");// 存储词频,初始化为1// 重写map()方法,将文本中的单词进行切割,并通过write()将map()生成的键值对输出给Combine阶段。@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = StringUtils.split(line, " ");// 得到字段数组FileSplit fileSplit = (FileSplit) context.getInputSplit();// 得到这行数据所在的文件切片String fileName = fileSplit.getPath().getName();// 根据文件切片得到文件名for (String field : fields) {// key值由单词和URL组成,如"MapReduce:file1"keyInfo.set(field + ":" + fileName);context.write(keyInfo, valueInfo);}}
}
🕤 2.2.2 Combine阶段实现
根据Map阶段的输出结果形式,在 com.mapreduce.invertedindex包下,自定义实现Combine阶段的类InvertedIndexCombiner,该类继承Reducer类,对每个文档的单词进行词频统计,如下图所示。
该类作用:对Map阶段的单词次数聚合处理,并重新设置key值为单词,value值由文档名称和词频组成。
package com.mapreduce.invertedindex;import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {private static Text info = new Text();// 输入: <MapReduce:file3 {1,1..>// 输出: <MapReduce file3:2>// 重写reduce()方法对Map阶段的单词次数聚合处理。@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {int sum = 0;// 统计词频for (Text value : values) {sum += Integer.parseInt(value.toString());}int splitIndex = key.toString().indexOf(":");// 重新设置value值由URL和词频组成info.set(key.toString().substring(splitIndex + 1) + ":" + sum);// 重新设置key值为单词key.set(key.toString().substring(0, splitIndex));context.write(key, info);}
}
🕤 2.2.3 Reduce阶段实现
根据Combine阶段的输出结果形式,在同一包下,自定义实现Reducer类InvertedIndexReducer,该类继承Reducer。
该类作用:接收Combine阶段输出的数据,按照最终案例倒排索引文件需求的样式,将单词作为key,多个文档名称和词频连接作为value,输出到目标目录。
package com.mapreduce.invertedindex;import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {private static Text result = new Text();// 输入: <MapReduce file3:2>// 输出: <MapReduce file1:1;file2:1;file3:2;>@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 生成文档列表String fileList = new String();for (Text value : values) {fileList += value.toString() + ";";}result.set(fileList);context.write(key, result);}
}
🕤 2.2.4 Runner程序主类实现
在同一个包下编写MapReduce程序运行主类InvertedIndexDriver。
该类作用:设置MapReduce工作任务的相关参数,设置完毕,运行主程序即可。
package com.mapreduce.invertedindex;import java.io.IOException;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.service.api.records.Configuration;public class InvertedIndexDriver {public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(InvertedIndexDriver.class);job.setMapperClass(InvertedIndexMapper.class);job.setCombinerClass(InvertedIndexCombiner.class);job.setReducerClass(InvertedIndexReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/InvertedIndex/input"));// 指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/InvertedIndex/output"));// 向yarn集群提交这个jobboolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}
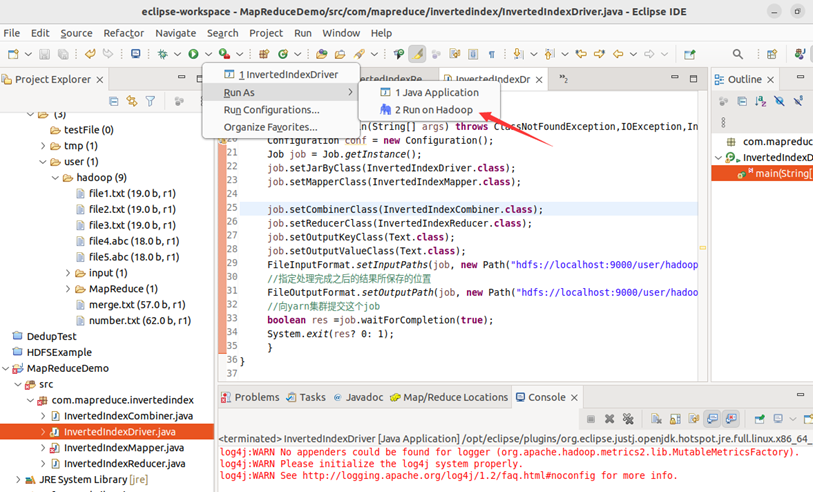
注:运行结果处的报错可以无视。
Web UI查看:
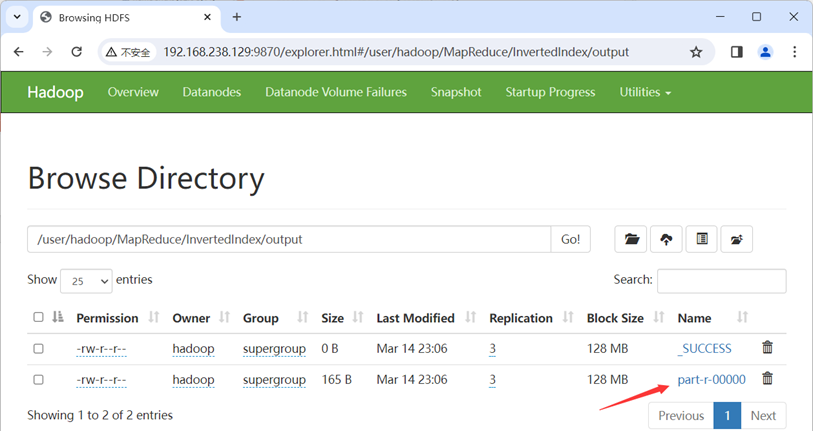
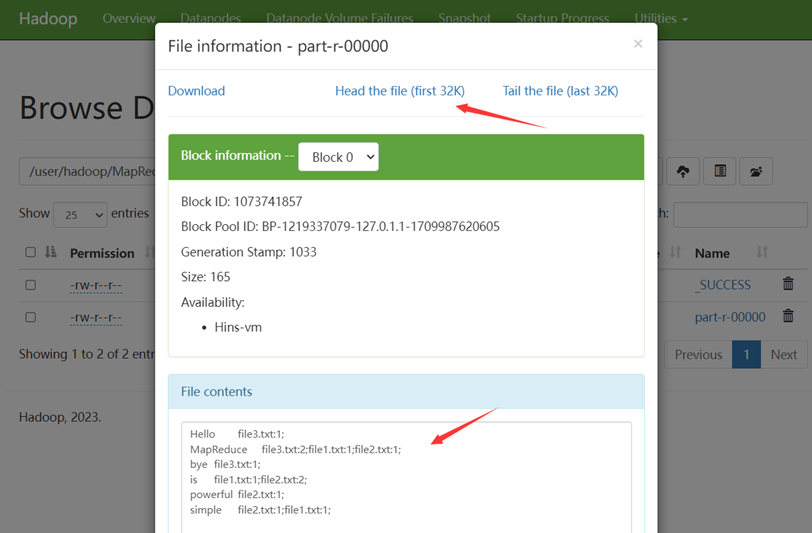
终端查看:
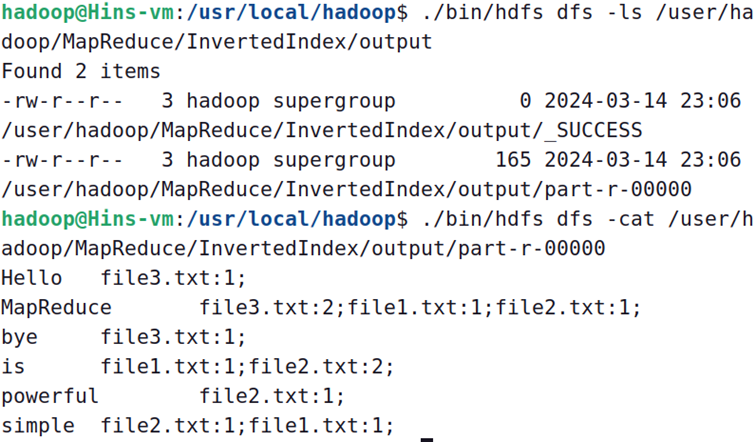
Eclipse IDE查看:
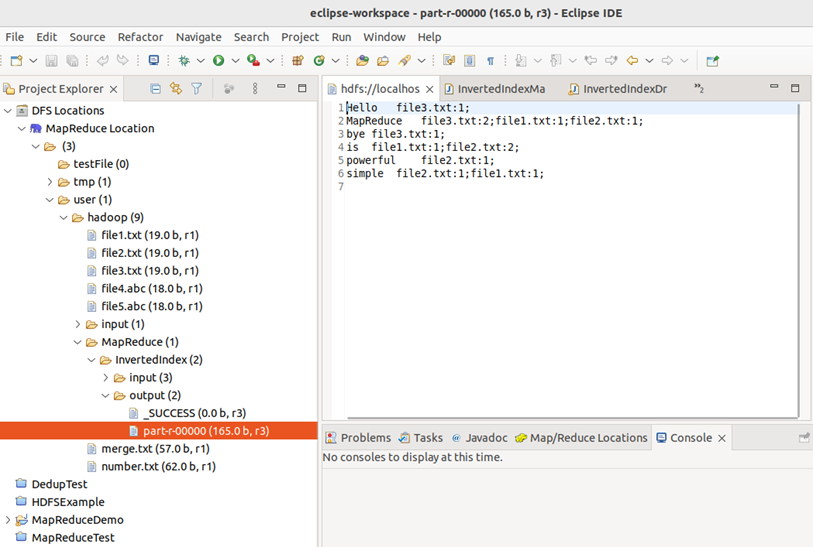
MapReduce的程序可以用Eclipse编译运行或使用命令行编译打包运行,下面是用命令行编译打包运行的方法:
将驱动类代码修改一下:
public class InvertedIndexDriver {public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {......FileInputFormat.setInputPaths(job, new Path(args[0]));// 指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path(args[1]));// 向yarn集群提交这个jobboolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}
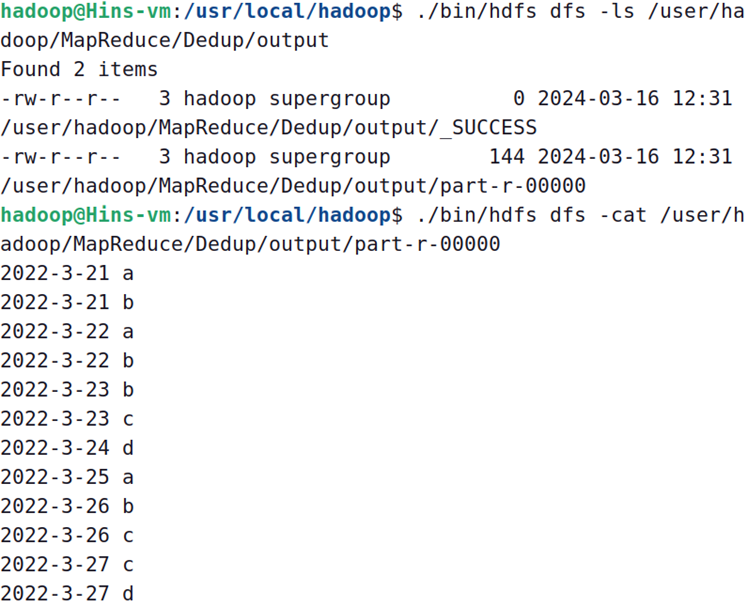
运行前如有output文件夹,需要先删了:
hadoop@Hins-vm:/usr/local/hadoop$ ./bin/hdfs dfs -rm -r /user/hadoop/MapReduce/InvertedIndex/output
打包为jar文件的操作详见HDFS分布式文件系统的 4.6节
🔎 传送门:HDFS分布式文件系统
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,并到HDFS中查看生成的文件:
hadoop@Hins-vm:/usr/local/hadoop$ ./bin/hadoop jar ./myapp/InvertedIndex.jar ./MapReduce/InvertedIndex/input ./MapReduce/InvertedIndex/output
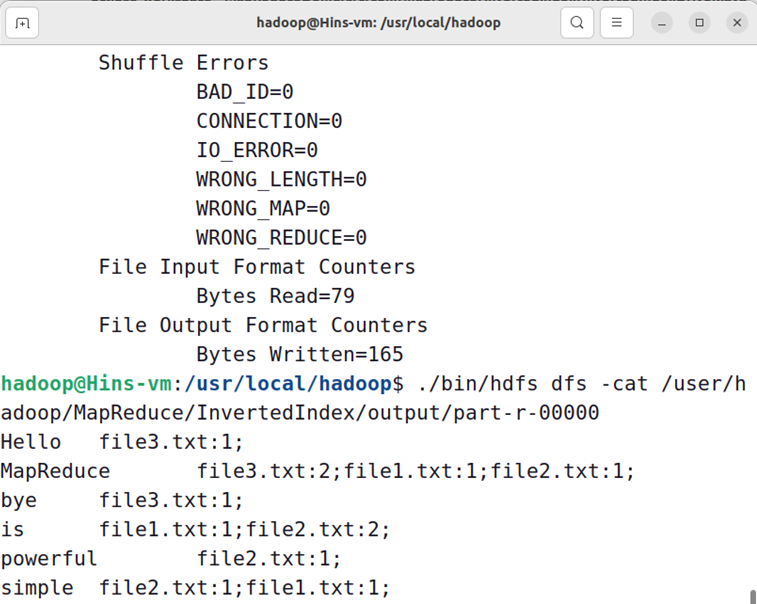
🕒 3. 数据去重
数据去重主要是为了掌握利用并行化思想来对数据进行有意义的筛选,数据去重指去除重复数据的操作。在大数据开发中,统计大数据集上的多种数据指标,这些复杂的任务数据都会涉及数据去重。
🕘 3.1 案例分析
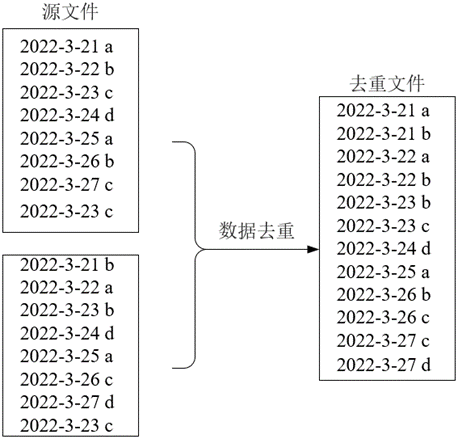
现有两个源文件file4.txt和file5.txt,内容分别如下,编程实现对两个文件合并后的数据内容去重:
file4.txt
2022-3-21 a
2022-3-22 b
2022-3-23 c
2022-3-24 d
2022-3-25 a
2022-3-26 b
2022-3-27 c
2022-3-23 c
file5.txt
2022-3-21 b
2022-3-22 a
2022-3-23 b
2022-3-24 d
2022-3-25 a
2022-3-26 c
2022-3-27 d
2022-3-23 c
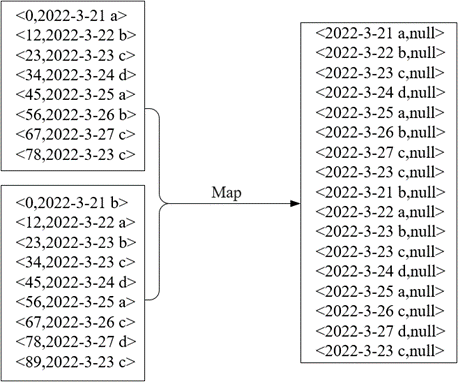
🕤 3.1.1 Map阶段
在Map阶段将读取的每一行数据作为键,如2022-3-21 a,由于MapReduce程序对数据去重是以键值对的形式解析数据,需要将每一行数据当作整体进行去重,所以将每一行数据作为键,而值在数据去重中作用不大,这里将值设置为null满足<Key,Value>的格式。
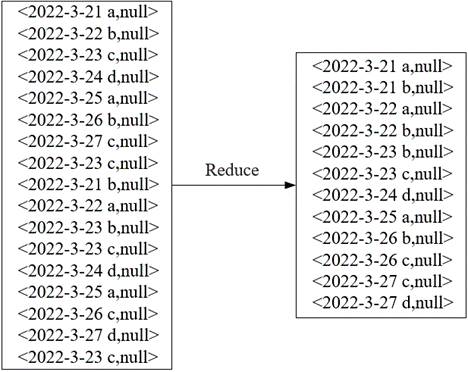
🕤 3.1.2 Reduce阶段
在Reduce阶段,将MapTask输出的键值对作为Reduce阶段输入的键值对,通过ReduceTask中的Shuffle对同一分区中键相同键值对合并,达到数据去重的效果。
🕘 3.2 案例实现
首先,我们创建好这些源文件,设置好路径并上传至HDFS的input中。
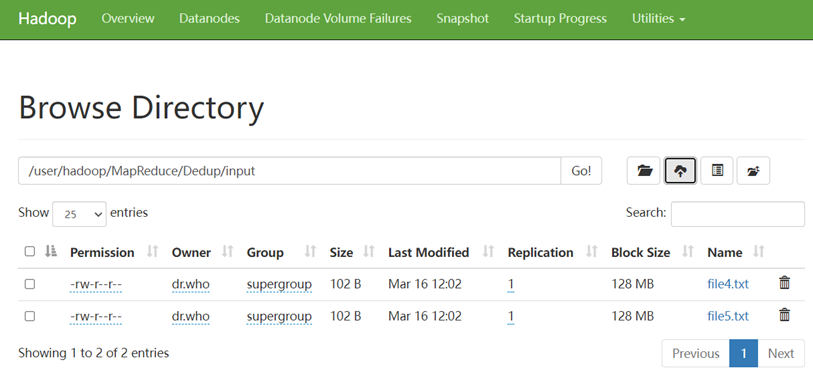
在MapReduceDemo项目下新建包 com.mapreduce.dedup
🕤 3.2.1 Map阶段实现
在 com.mapreduce.dedup包下新建自定义类Mapper类DedupMapper,该类继承Mapper类
该类作用:读取数据集文件将TextInputFormat默认组件解析的类似<0,2022-3-21 a>键值对修改为<2022-3-21 a,null>
package com.mapreduce.dedup;import java.io.IOException;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class DedupMapper extends Mapper<LongWritable, Text, Text, NullWritable> {private static Text field = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {field = value;context.write(field, NullWritable.get());}
}
🕤 3.2.2 Reduce阶段实现
在同一包下新建自定义类Reducer类DedupReducer,该类继承Reducer类
该类作用:仅接受Map阶段传递过来的数据,根据Shuffle工作原理,键值key相同的数据就会被合并,因此输出的数据就不会出现重复数据了。
package com.mapreduce.dedup;import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class DedupReducer extends Reducer<Text, NullWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context)throws IOException, InterruptedException {context.write(key, NullWritable.get());}
}
🕤 3.2.3 Runner程序主类实现
在同一个包下编写MapReduce程序运行主类DedupRunner。
package com.mapreduce.dedup;import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.service.api.records.Configuration;public class DedupRunner {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(DedupRunner.class);job.setMapperClass(DedupMapper.class);job.setReducerClass(DedupReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/Dedup/input"));// 指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/Dedup/output"));job.waitForCompletion(true);}
}
🕒 4. TopN
TopN分析法是指从研究对象中按照某一个指标进行倒序或正序排列,取其中最大的N个数据,并对这N个数据以倒序或正序的方式进行输出分析的方法。
🕘 4.1 案例分析
假设有数据文件num.txt,要求以降序的方式获取文件内容中最大的5个数据,并将这5个数据保存到一个文件中。
10 3 8 7 6 5 1 2 9 4
11 12 17 14 15 20
19 18 13 16
(1)在Map阶段,可以使用TreeMap数据结构保存TopN的数据,TreeMap是一个有序的键值对集合,默认会根据键进行排序,也可以自行设定排序规则,TreeMap中的firstKey()可以用于返回当前集合最小值的键。
(2)在Reduce阶段,将MapTask输出的数据进行汇总,选出其中的最大的5个数据即可满足需求。
(3)要想提取文本中5个最大的数据并保存到一个文件中,需要将ReduceTask的数量设置为1,这样才不会把文件中的数据分发给不同的ReduceTask处理。
🕘 4.2 案例实现
首先,我们创建好这些源文件,设置好路径并上传至HDFS的input中。
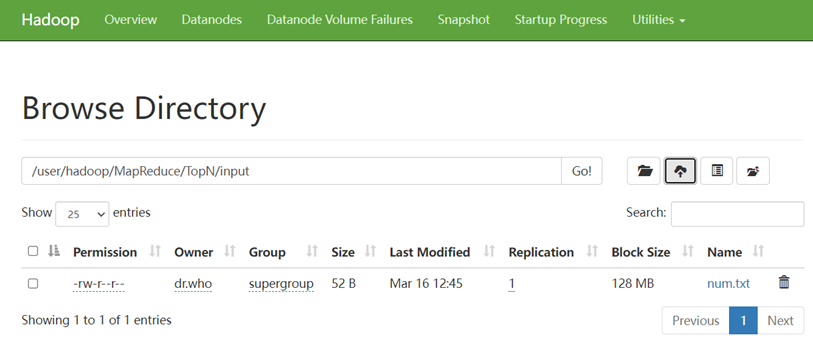
在MapReduceDemo项目下新建包 com.mapreduce.topn
🕤 4.2.1 Map阶段实现
在 com.mapreduce.topn包下新建自定义类Mapper类TopNMapper,该类继承Mapper类
该类作用:先将文件中的每行数据进行切割提取,并把数据保存到TreeMap中,判断TreeMap是否大于5,如果大于5就需要移除最小的数据。由于数据是逐行读取,如果这时就向外写数据,那么TreeMap就保存了每一行的最大5个数,因此需要在cleanup()方法中编写context.write()方法,这样就保证了当前MapTask中TreeMap保存了当前文件最大的5条数据后,再输出到Reduce阶段。
package com.mapreduce.topn;import java.util.TreeMap;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class TopNMapper extends Mapper<LongWritable, Text, NullWritable, IntWritable> {private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>();@Overridepublic void map(LongWritable key, Text value, Context context) {String line = value.toString();String[] nums = line.split(" ");for (String num : nums) {repToRecordMap.put(Integer.parseInt(num), " ");if (repToRecordMap.size() > 5) {repToRecordMap.remove(repToRecordMap.firstKey());}}}@Overrideprotected void cleanup(Context context) {for (Integer i : repToRecordMap.keySet()) {try {context.write(NullWritable.get(), new IntWritable(i));} catch (Exception e) {e.printStackTrace();}}}
}
🕤 4.2.2 Reduce阶段实现
在同一包下新建自定义类Reducer类TopNReducer,该类继承Reducer类
该类作用:首先TreeMap自定义排序规则,当需求取最大值时,只需要在compare()方法中返回正数即可满足倒序排序,reduce()方法依然要满足时刻判断TreeMap中存放数据是前5个数,并最终遍历输出最大的5个数。
package com.mapreduce.topn;import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;public class TopNReducer extends Reducer<NullWritable, IntWritable, NullWritable, IntWritable> {private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>(new Comparator<Integer>() {// 返回一个基本类型的整型,谁大谁排后面.// 返回负数表示:01小于02// 返回0表示:表示: 01和02相等// 返回正数表示: 01大于02。public int compare(Integer a, Integer b) {return b - a;}});public void reduce(NullWritable key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {for (IntWritable value : values) {repToRecordMap.put(value.get(), " ");if (repToRecordMap.size() > 5) {repToRecordMap.remove(repToRecordMap.firstKey());}}for (Integer i : repToRecordMap.keySet()) {context.write(NullWritable.get(), new IntWritable(i));}}
}
🕤 4.2.3 Runner程序主类实现
在同一个包下编写MapReduce程序运行主类TopNRunner。
package com.mapreduce.topn;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.service.api.records.Configuration;public class TopNRunner {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(TopNRunner.class);job.setMapperClass(TopNMapper.class);job.setReducerClass(TopNReducer.class);job.setNumReduceTasks(1);job.setMapOutputKeyClass(NullWritable.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/TopN/input"));FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/TopN/output"));boolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}

❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页