文章目录
- 说一说JavaScript有几种方法判断变量的类型?
- 说一说defer和async区别?
- HTTP(超文本传输协议)是什么?
- 说一下浏览器输入URL发生了什么?
- 一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果)。
- 说一说虚拟地址空间有哪些部分
- 说一说 HashRouter 和 HistoryRouter的区别和原理?
- 1. HashRouter
- 2. HistoryRouter
- 说一下浮动?
- 说一说HTML语义化?
- XSS攻击是什么?
- 说一说创建ajax过程?
- UDP(用户数据报协议)是什么?
- 介绍一下几种 IO 模型
- IP协议的首部结构
- CSRF攻击是什么?
说一说JavaScript有几种方法判断变量的类型?
在JavaScript中,有几种方法可以判断变量的类型:
-
typeof操作符:typeof是最常用的判断变量类型的方法之一。它返回一个表示变量类型的字符串,例如"string"、"number"、"boolean"、"function"、"object"、"undefined"等。它对于大多数基本类型和函数都能给出准确的结果,但对于null和对象类型无法区分。 -
instanceof操作符:instanceof用于检查对象是否属于某个类或原型链中的构造函数。它通过检查对象的原型链来确定对象是否属于某个构造函数创建的实例。例如,obj instanceof Array可以检查obj是否是数组的实例。 -
Array.isArray()方法:Array.isArray()方法用来判断一个变量是否是数组类型。它返回一个布尔值,如果给定的变量是数组,返回true,否则返回false。 -
Object.prototype.toString.call()方法:这是一种较为底层的方法,可以判断几乎所有的数据类型。通过调用Object.prototype.toString方法并传入需要判断的变量作为上下文,然后使用call()方法调用,可以得到一个字符串,表示变量的具体类型。例如,Object.prototype.toString.call(obj)可以判断obj的具体类型。 -
isNaN()函数:isNaN()函数用于判断一个变量是否为NaN(非数字)。该函数会先尝试将参数转换为数字,然后再进行判断。如果成功转换为数字,返回false,否则返回true。注意,该方法对undefined、字符串、布尔值等非数字类型的判断也会返回true。
需要注意的是,尽管上述方法可以提供一定的类型判断能力,但在 JavaScript 中,由于其动态性和松散的类型约束,类型判断并不总是准确和可靠的。因此,在实际应用中,建议根据具体需求和上下文来综合判断变量的类型。
说一说defer和async区别?
defer和async是用于处理<script>标签中的两个属性,用于控制脚本的加载和执行的方式。它们有以下区别:
-
加载方式:使用
defer属性加载的脚本将按照文档顺序加载,但是在HTML解析完成后才会执行,而不会阻止HTML的解析和渲染过程。而使用async属性加载的脚本将异步加载并且不会阻塞HTML解析过程,加载完成后立即执行,可能会在HTML解析完成之前执行,因此执行顺序是不确定的。 -
执行时机:对于
defer属性,脚本会在整个文档解析完毕之后执行,但在DOMContentLoaded事件之前执行。这意味着脚本可以获取和操作整个文档的结构,包括DOM元素。而对于async属性,脚本在加载完成后立即执行,它的执行时机与其他脚本、样式和资源的加载情况有关,可能在DOMContentLoaded事件之前或之后执行。 -
顺序性:使用
defer属性加载的脚本会按照它们在文档中出现的顺序执行,即使脚本之间存在外部依赖关系。而使用async属性加载的脚本则是在加载完成后立即执行,不考虑脚本之间的顺序。 -
对脚本的依赖:使用
defer属性加载的脚本可以依赖于其他脚本文件,因为它们会在整个文档解析完毕之后执行。而使用async属性加载的脚本不会阻塞其他脚本的加载和执行,因此不能依赖其他脚本,要确保独立于其他脚本运行。
综上所述,defer和async属性都是用于优化脚本加载和执行的方式。defer保证脚本按照文档顺序执行,并在DOMContentLoaded事件之前执行,适用于依赖于文档结构的脚本。而async属性使脚本异步加载并立即执行,适用于独立于其他脚本的独立脚本文件。
HTTP(超文本传输协议)是什么?
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于在网络上传输超媒体文档(如HTML、图片、视频等)的应用层协议。它是互联网上最常用的协议之一,用于在客户端和服务器之间传输信息。
HTTP使用客户端-服务器模型,客户端发起请求,而服务器响应请求。
在这个模型中,客户端通常是指浏览器,而服务器则是指存储和提供资源的主机。
HTTP的工作方式如下:
- 客户端发送HTTP请求到指定的服务器,并指定要获取的资源(例如网页、图片、视频等)以及其他请求参数。
- 服务器接收到请求后,根据请求的资源路径和参数进行处理,并生成相应的HTTP响应。
- 服务器将HTTP响应发送回客户端,响应中包含了请求的资源以及其他相关信息(例如状态码、响应头等)。
- 客户端接收到服务器的响应后,根据响应中的信息进行处理,例如展示网页、下载文件等。
HTTP协议在设计上简单并可扩展性强,它使用基于文本的交互格式,常见的是使用URL(Uniform Resource Locator)来标识资源,使用各种请求方法(如GET、POST、PUT、DELETE等)来描述请求的操作。此外,HTTP还支持使用加密协议(如HTTPS)来保护通信的安全性。
总之,HTTP协议是网络通信中的重要协议之一,它使得我们能够通过互联网快速、安全地传输超文本内容,并且在Web浏览、数据传输等方面具有广泛的应用。
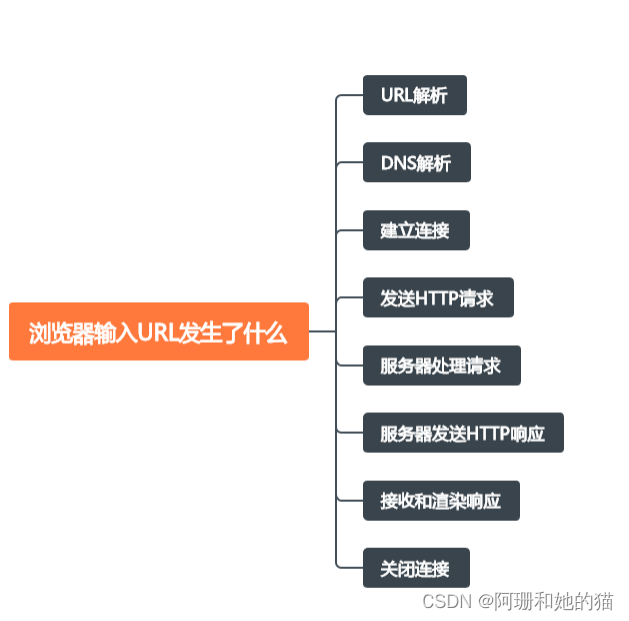
说一下浏览器输入URL发生了什么?
当在浏览器中输入一个URL(统一资源定位符)时,以下是大致的过程说明:
-
URL解析:浏览器首先解析输入的URL,将其分解为协议(如
HTTP、HTTPS)、主机(如www.example.com)、端口(可选,默认为协议的默认端口)、路径等组成部分。 -
DNS解析:浏览器需要将主机名解析为对应的IP地址,以便能够建立与服务器的连接。它会先检查缓存中是否有对应的IP地址,如果没有,就会向本地域名服务器或递归解析服务器发送DNS(域名系统)请求,获取主机名对应的IP地址。
-
建立连接:浏览器使用解析得到的服务器IP地址和端口号,与服务器建立TCP连接。在建立连接的过程中,还可能经过握手过程(如三次握手)来确保连接的可靠性。此步骤是在传输层进行的。
-
发送HTTP请求:一旦建立了与服务器的TCP连接,浏览器就会构建一个HTTP(或HTTPS)请求报文,并向服务器发送请求。该请求报文包括
请求方法(如GET、POST)、请求头(例如User-Agent、Cookies等)和请求体(如POST请求时携带的数据)等信息。 -
服务器处理请求:服务器接收到请求后,会进行相应的处理。这可能涉及到动态生成网页内容、访问数据库、处理请求参数等。
-
服务器发送HTTP响应:处理完请求后,
服务器将生成一个HTTP响应报文,其中包含了状态码(如200表示成功)、响应头(如Content-Type、Cache-Control等)和响应体(如请求的网页内容)等信息。 -
接收和渲染响应:浏览器接收到服务器的响应后,会解析响应报文,根据响应中的各种信息进行相应的处理。如果请求的是一个网页,浏览器会解析HTML、CSS和JavaScript,并将其渲染出来。
-
关闭连接:当请求完成后,浏览器会关闭与服务器的TCP连接。这也可以通过HTTP的持久连接来保持连接以便后续的请求。
总结起来,浏览器输入URL的过程可以概括为:URL解析、DNS解析、建立连接、发送请求、服务器处理请求、服务器发送响应、接收和渲染响应、关闭连接。这个过程涉及到浏览器的网络协议栈中不同层次的协议和各个环节的处理过程。
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果)。
这是一个经典的斐波那契数列问题。
青蛙跳上一个n级的台阶总共有多少种跳法,可以用动态规划的方法来解决。
假设f(n)表示青蛙跳上一个n级的台阶的跳法总数。根据题目的条件,青蛙可以从n-1级跳一步跳到第n级台阶,或者从n-2级跳两步跳到第n级台阶。因此,跳上一个n级的台阶的跳法总数等于跳上一个n-1级台阶的跳法总数加上跳上一个n-2级台阶的跳法总数。
即:f(n) = f(n-1) + f(n-2)
根据初始条件可知,f(1) = 1,f(2) = 2。
下面是一个使用动态规划解决该问题的示例代码(使用JavaScript语言):
function countJumpWays(n) {if (n === 1) {return 1;}if (n === 2) {return 2;}var dp = new Array(n + 1);dp[1] = 1;dp[2] = 2;for (var i = 3; i <= n; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];
}
你可以调用countJumpWays函数,并将n作为参数传递给它来获取跳上一个n级台阶的跳法总数。例如,countJumpWays(3)将返回3,表示跳上一个3级台阶共有3种不同的跳法。
说一说虚拟地址空间有哪些部分
虚拟地址空间是操作系统给每个进程提供的一种抽象概念,它将进程的内存地址空间划分为几个不同的部分,每个部分具有特定的作用和用途。
以下是虚拟地址空间中常见的几个部分:
-
代码段(Text Segment):也称为只读区域,存放着进程的可执行代码。在多个进程之间,该部分的内容是共享的,因为代码段是只读的,多个进程可以同时执行相同的代码。 -
数据段(Data Segment):也称为已初始化数据区域,存放着进程的全局变量、静态变量以及已经初始化的静态常量。在程序加载时,这些数据会被预先赋值。 -
BSS段(Block Started by Symbol):也称为未初始化数据区域,存放着进程的未初始化的全局变量和静态变量。在程序加载时,这个区域的数据会被初始化为零或空。 -
堆(Heap):是动态分配的内存区域,用于存放进程运行时动态分配的内存,如使用malloc、calloc等函数从堆中分配的内存。 -
栈(Stack):也称为执行栈,用于存放函数调用的局部变量、函数参数以及函数调用时的返回地址等信息。栈是自动分配和释放的,它的空间由系统自动管理。 -
共享库区域(Shared Libraries):存放着被多个进程共享的库文件,如动态链接库(DLL)或共享对象文件(SO)等。 -
内核空间(Kernel Space):是操作系统的内核部分使用的地址空间,不属于用户进程的虚拟地址空间。用户进程无法直接访问和操作内核空间,需要通过系统调用接口来进行交互。
虚拟地址空间的划分可以随操作系统和硬件平台的不同而变化,但以上列出的部分是在大多数操作系统中常见的。不同的部分具有不同的访问权限和地址范围,通过虚拟地址空间的划分,操作系统可以提供更高效、更安全的内存管理机制。
说一说 HashRouter 和 HistoryRouter的区别和原理?
HashRouter和HistoryRouter是React Router库中两种常用的路由模式。
它们有不同的URL管理方式以及对应的原理和工作原理。
1. HashRouter
- URL管理方式:
HashRouter使用URL的片段标识符(#)来管理路由。例如,URL可以是http://example.com/#/home,其中#/home是路由标识符。 - 原理:
HashRouter通过监听URL的hashchange事件来感知URL的变化,从而触发对应的路由切换。它将路由信息存储在URL的片段标识符中,不会影响到服务器端处理URL的能力。 - 工作原理:当用户点击页面中的链接或者调用相关的API进行路由切换时,HashRouter会更新URL的片段标识符,并通过触发
hashchange事件来通知应用程序进行页面更新。
2. HistoryRouter
- URL管理方式:HistoryRouter使用HTML5 history API来管理URL。它使用浏览器的
pushState和replaceState方法来修改URL,没有片段标识符(#)的存在。例如,URL可以是http://example.com/home。 - 原理:HistoryRouter利用HTML5 history API中的
pushState和replaceState方法,来修改URL并将路由信息保存在浏览器的历史记录中。它使用浏览器历史记录栈来管理路由的切换。 - 工作原理:当用户点击页面中的链接或者调用相关的API进行路由切换时,HistoryRouter会使用
pushState或replaceState方法修改URL,并通过浏览器的前进或后退按钮来触发对应的路由切换。
区别:
- HashRouter使用URL的片段标识符来管理路由,而HistoryRouter使用
HTML5 history API来管理路由。 - HashRouter不需要服务器端额外的配置,而
HistoryRouter需要服务器端的支持来处理路由。
无论是HashRouter还是HistoryRouter,在React Router中使用时,功能和用法都是相似的,只是URL的管理方式略有不同。选择使用哪种方式取决于你的项目需求以及服务器端的配置能力。
说一下浮动?
浮动(Floating)是CSS中一种常用的布局技术,它可以使元素脱离普通文档流,并根据指定的方向进行漂浮定位。当元素浮动时,它会尽量往指定的方向移动,并尽量占据可用空间的最左侧或最右侧。
浮动元素的常用属性是float,可以设置为left(向左浮动)或right(向右浮动)。
当元素浮动之后,它会腾出自身的空间,剩下的元素会围绕着浮动元素进行排列。
使用浮动布局可以实现以下效果:
- 创建多列布局:通过将不同的元素浮动到左侧或右侧,可以实现多列布局效果。
- 图片和文字环绕:将图片浮动到左侧或右侧,可以使文字围绕在图片周围,实现文字环绕效果。
- 响应式布局:通过浮动元素,可以实现在不同屏幕尺寸下元素的自动换行和重排。
然而,浮动元素也有一些需要注意的问题:
- 浮动元素高度塌陷:浮动元素会脱离文档流,可能导致父元素的高度塌陷。需要通过使用清除浮动(clear float)的方法来解决这个问题。
- 布局错乱:如果不正确地使用和管理浮动,可能导致布局错乱,元素重叠或覆盖等问题。需要注意对浮动元素的清除、包裹和处理。
- 对齐和对齐行为:浮动元素可能导致与其他元素之间的对齐和对齐行为的改变。需要适当调整元素的样式来实现预期的布局效果。
在现代的CSS布局中,浮动的使用已经逐渐被新的布局模型(如Flexbox和Grid)取代。这些新的布局技术提供更灵活、更强大的布局能力,同时能够更好地处理布局问题和兼容性。因此,在使用布局技术时,建议优先考虑使用Flexbox和Grid来实现布局需求。
说一说HTML语义化?
HTML语义化是指在编写HTML代码时,使用具有语义意义的标签来描述页面内容的结构和含义。它强调使用恰当的HTML标签来表示页面中各个部分的意义和功能,使得代码更具可读性、可维护性和可访问性。
以下是HTML语义化的一些好处:
-
易于理解和维护:使用语义化标签可以使代码更易于被他人理解和维护。通过标签本身的含义,人们可以快速了解页面的结构和内容意义,减少了对代码的解释和查找的需要。
-
提升可访问性:语义化标签对于网页的可访问性至关重要。屏幕阅读器等辅助技术能够根据语义化标签更好地理解页面结构和内容,并将其传达给有视觉障碍的用户。
-
改善搜索引擎优化(SEO):搜索引擎对于语义化标签具有更好的理解和解析能力,可以更准确地理解页面内容的结构和意义,从而提高网页的搜索排名。
-
代码可读性:使用语义化标签可以使代码的结构更清晰和可读性更好。标签本身具有表达意义的特点,可以准确地描述页面中各个部分的含义和功能,使得代码更易于理解和维护。
下面是一些常见的HTML语义化标签示例:
<header>:页面的头部,通常包含站点的标题、导航栏等。<nav>:页面的导航部分,包含页面的导航链接。<main>:页面的主要内容部分。<article>:独立的文章、博客等内容。<aside>:文章或页面的相关辅助内容。<section>:页面中的一个独立的区块。<footer>:页面的页脚部分,通常包含版权信息和联系方式等。
需要注意的是,语义化标签的使用应该结合实际情况,避免过度使用导致标签的滥用。在使用标签时,要考虑页面的结构和内容含义,并选择最合适的标签来描述和表达。
XSS攻击是什么?
XSS(跨站脚本攻击)是一种常见的Web安全漏洞,它允许攻击者将恶意脚本注入到受信任的网页中,然后在用户的浏览器上执行这些恶意脚本。XSS攻击通常利用网页应用程序对用户输入的不完全过滤或验证来实现。
XSS攻击可以分为以下三种类型:
-
存储型XSS:攻击者将恶意脚本存储在目标网站的服务器上,当其他用户访问受影响的页面时,恶意脚本会被传递给他们的浏览器并执行。这种类型的攻击主要针对需要持久存储用户输入的网站功能,如留言板、评论功能等。 -
反射型XSS:攻击者通过诱使用户点击特制的恶意链接,将恶意脚本作为参数包含在URL中。当用户点击链接并访问目标网页时,服务器从参数中获取并注入恶意脚本,浏览器解析后执行。这种类型的攻击通常是一次性的,只会影响点击了恶意链接的用户。 -
DOM型XSS:攻击者通过修改页面的DOM(文档对象模型)来实现攻击。恶意脚本修改页面上的DOM元素,使得用户的浏览器在解析页面时执行这些恶意脚本。与其他类型的XSS攻击不同,DOM型XSS攻击不需要向服务器发送恶意脚本,而是直接在用户的浏览器上进行操作。
XSS攻击可能导致以下安全问题:
- 窃取用户敏感信息,如登录凭据、个人信息等。
- 欺骗用户进行恶意操作,如转账、修改密码等。
- 在受攻击网站上显示恶意内容,诱导用户点击恶意链接或下载恶意文件。
为了防范XSS攻击,开发人员应该采取以下安全措施:
- 对用户输入进行严格的验证和过滤,特别是对特殊字符和HTML标签进行转义处理。
- 使用安全的编码函数来对用户输入进行编码,如使用HTML实体编码。
- 设置合适的
Content Security Policy(CSP)来限制页面可以加载的外部资源。 - 使用
HTTP Only标记来限制JavaScript对敏感的cookie的访问。 - 遵循安全编码的最佳实践,在设计和开发过程中考虑安全性,并进行安全审计和测试。
通过以上措施,可以帮助减少XSS攻击对网站和用户的威胁。
说一说创建ajax过程?
创建AJAX(Asynchronous JavaScript and XML)的过程主要涉及以下几个步骤:
- 创建
XMLHttpRequest对象:首先,使用JavaScript创建XMLHttpRequest对象,该对象用于与服务器进行通信。不同的浏览器可能具有不同的创建方式,可以通过以下代码创建:
var xhr;
if (window.XMLHttpRequest) {// 非IE浏览器xhr = new XMLHttpRequest();
} else if (window.ActiveXObject) {// IE浏览器xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
- 设置回调函数:在创建
XMLHttpRequest对象后,需要为其设置回调函数,以处理服务器返回的响应。回调函数用于处理异步请求的结果。常见的回调函数包括onreadystatechange和onload。例如:
xhr.onreadystatechange = function() {if (xhr.readyState === 4 && xhr.status === 200) {// 处理响应结果}
};
- 发送请求:使用XMLHttpRequest对象发送HTTP请求。可以使用open()方法设置请求的类型(GET或POST)和URL,然后通过send()方法发送请求。例如:
xhr.open("GET", "url", true);
xhr.send();
- 处理响应:当服务器返回响应时,会触发之前设置的回调函数。在回调函数中,可以获取服务器返回的数据,并根据需要进行处理。例如,通过responseText属性获取文本数据,通过responseXML属性获取XML数据。处理方式可以是更新网页内容、展示数据等。
xhr.onreadystatechange = function() {if (xhr.readyState === 4 && xhr.status === 200) {// 处理响应结果var response = xhr.responseText;// 更新网页内容或其他操作}
};
上述步骤是基本的AJAX请求流程。通过AJAX,可以实现异步加载数据、无需刷新页面更新内容等,提高用户体验。需要注意的是,AJAX请求可能涉及跨域访问的安全性问题,需要在服务器端进行相应配置,以确保请求的安全性和正确性。
UDP(用户数据报协议)是什么?
UDP(User Datagram Protocol,用户数据报协议)是一种在网络通信中常用的传输层协议。它与传输控制协议(TCP)相对,提供了一种无连接、不可靠的数据传输方式。
UDP协议的特点如下:
-
无连接性:UDP不建立持久的连接,数据包在发送前不需要进行握手过程。每个UDP数据包(也称为数据报)都是独立的,可以独立地进行发送和接收。
-
不可靠性:UDP协议不提供可靠的数据传输机制,即发送方无法保证接收方是否成功接收到数据。UDP不会进行数据重传或流量控制,因此不能保证数据的完整性和可靠性。
-
快速和高效:由于UDP不需要建立连接和维护状态,因此传输效率较高。它的报头较小且不需要进行复杂的连接管理,因此速度较快。
-
适用于实时应用:UDP适用于实时应用场景,如音频、视频、游戏等,因为它能够提供快速的数据传输,而对于丢包等问题,可以通过应用层进行处理。
由于UDP的不可靠性,它常常与上层协议配合使用,如基于UDP的实时传输协议(RTP)用于音视频传输,基于UDP的域间多播协议(IGMP)用于组播传输。
总的来说,UDP是一种简单、高效的传输协议,适用于那些要求传输速度快、实时性强的场景,但不适用于对数据可靠性和完整性要求较高的应用。
介绍一下几种 IO 模型
在计算机领域中,IO(Input/Output)模型用于描述计算机与外部设备之间进行数据输入和输出的方式。以下是几种常见的IO模型:
1. 阻塞IO模型(Blocked IO):
阻塞IO模型是最基本的IO模型之一。当应用程序执行IO操作时,它会一直阻塞(即暂停执行),直到IO操作完成。在这种模型中,应用程序不会进行其他任何操作,直到IO操作完全完成。阻塞IO模型适用于对低负载和低并发性能要求不高的应用程序。
2. 非阻塞IO模型(Non-Blocked IO):
非阻塞IO模型的特点是应用程序发起IO操作后,不会一直等待IO操作完成。即使数据未准备好或者无法立即进行IO操作,应用程序也可以继续执行其他操作。通过不断轮询IO状态,应用程序可以选择等待数据准备好后再执行IO操作,或者将控制权返还给应用程序。这种模型通常需要使用轮询或者事件驱动的方式来检查IO状态。
3. IO多路复用模型(IO Multiplexing):
IO多路复用模型通过一个线程来同时管理多个IO操作。它使用一个特定的系统调用(如select、poll、epoll等)来监听多个IO事件。当任意的IO事件就绪时,应用程序将被通知并可以处理相应的IO操作。在这种模型中,应用程序可以同时处理多个IO操作,而不需要为每个IO操作创建一个单独的线程。这种模型适用于并发性能要求较高的应用程序。
4. 信号驱动IO模型(Signal-driven IO):
信号驱动IO模型是一种异步IO模型。它使用信号来通知应用程序IO操作的完成。当应用程序发起IO操作并设置信号处理函数后,应用程序可以继续执行其他操作而不需要等待IO操作完成。当IO操作完成后,系统会发送一个信号给应用程序,触发相应的信号处理函数。这种模型通常需要使用操作系统提供的信号机制来实现。
5. 异步IO模型(Asynchronous IO):
异步IO模型是在信号驱动IO模型的基础上进一步发展的。在异步IO模型中,应用程序发起IO操作后不会等待IO操作完成,而是继续执行其他操作。当IO操作完成后,操作系统将通知应用程序,并将数据传递给应用程序。与信号驱动IO模型相比,异步IO模型更为高效,因为它避免了频繁的信号处理机制。
每种IO模型都有其适用的场景和优缺点。选择合适的IO模型取决于应用程序的需求和性能要求。
IP协议的首部结构
IP(Internet Protocol)协议的首部结构描述了IP包中的头部信息。IP协议是互联网中数据传输的核心协议之一。以下是IP协议的首部结构:
0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
IP协议的首部包含以下字段:
Version(4 bits):表示IP协议的版本号,通常为4(IPv4)或6(IPv6)。- IHL(Internet Header Length,4 bits):表示IP首部的长度,以32位字(4字节)为单位。最小值为5,表示20字节的首部长度,最大值为15,表示60字节的首部长度。
- Type of Service(8 bits):用于指定IP包的服务类型,例如优先级、延迟要求、吞吐量等。
- Total Length(16 bits):表示整个IP包的长度,包括首部和数据部分,以字节为单位。
- Identification(16 bits):用于标识IP包的唯一标识符,用于重组分片数据包。
- Flags(3 bits):用于指示是否有更多的分片以及分片位置。
- Fragment Offset(13 bits):用于指示当前分片在原始IP包中的偏移量。
- Time to Live(8 bits):表示IP包的生存时间,用于防止数据包在网络中无限循环。
- Protocol(8 bits):指示IP包中承载的上层协议类型,例如TCP(6)、UDP(17)等。
- Header Checksum(16 bits):用于校验IP首部的完整性。
- Source Address(32 bits):发送方的IP地址。
- Destination Address(32 bits):接收方的IP地址。
Options(可选):用于扩展IP首部的选项字段,长度可变。Padding(可选):填充字段,用于保证IP首部长度为32位字(4字节)的倍数。
注意:以上描述的是IPv4包的首部结构,IPv6包的首部结构有所不同。IPv6采用固定的40字节首部,而选项部分则变为扩展首部。
CSRF攻击是什么?
CSRF(Cross-Site Request Forgery)攻击是一种Web安全漏洞,也被称为“跨站请求伪造”攻击。它利用了Web应用程序对于用户身份验证的信任,通过伪造用户请求,以用户的身份执行未经用户授权的操作。
在CSRF攻击中,攻击者会利用受害者已经在某个网站上登录过的凭证,诱使受害者访问包含恶意代码的第三方网站。该第三方网站会向目标网站发送伪造的请求,这些请求看起来像是受害者本人发送的。由于目标网站信任来自已登录用户的请求,它会认为这些伪造请求是合法的并执行。
CSRF攻击可以造成以下危害:
- 身份盗窃:攻击者可以通过CSRF攻击,以受害者的身份执行操作,如更改密码、发送恶意邮件等。
- 数据篡改:攻击者可以以受害者的身份提交更改数据的请求,导致数据被篡改。
- 资金损失:如果目标网站涉及财务操作,攻击者可以伪造请求进行转账或购买商品等,导致资金损失。
为了防止CSRF攻击,可以采取以下措施:
使用随机化的请求令牌(CSRF token):目标网站为每个用户生成一个唯一的令牌,并将其嵌入到表单或请求中。服务器在处理请求时会验证令牌是否匹配,从而确认请求的合法性。设置同源策略(Same-Origin Policy):浏览器通过同源策略限制页面中的Javascript代码对其他源的请求。这可以防止跨域请求被自动执行。- 使用验证码:对于一些敏感的操作,可以使用验证码来确认用户的身份。
- 将敏感操作需要进一步验证:对于一些涉及财务或安全操作的请求,可以要求用户输入密码或进行多因素身份验证来进一步确认身份。
通过以上措施的综合应用,可以大大减少CSRF攻击的风险,并提高Web应用程序的安全性。



![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)](https://img-blog.csdnimg.cn/9220d7cfb95244bc8d7053d6e4cf36d7.png)