总结:
工业界推荐的精排模型全都是pointwise。
特征交叉01-FM
线性模型对输入的特征取加权和,作为对目标的预估。如果先做特征交叉,再用线性模型,通常可以取得更好的效果。如果做二阶特征交叉,那么参数量为O(特征数量平方),计算量大,而且容易造成过拟合。因式分解机(Factorized Machine, FM)用低秩矩阵分解的方式降低参数量,加速计算。任何可以用线性模型(比如线性回归、逻辑回归)解决的问题,都可以用 FM 解决。
已经不太常用

b是偏移项, 第二项是对 d 个特征的连加,其中 w下标 i表示每个特征的权重。把线性模型的输出记作 p,是对目标的预估,如果做二分类可以用 sigmoid 激活函数。
这个线性模型有 d+1个参数,线性模型的预测是特征的加权和,d个特征 x1到 xd只有相加,特征没有交叉。在推荐系统中,特征交叉是很有必要的,可以让模型的预测更准确。

前两项是线性模型,与前面一直,xixj 是两个特征的交叉,uij 是权重。两个特征不仅相加还可以相乘,可以提升模型的表达能力。举个梨子,假设特征是房屋的大小,还有周边楼盘的每平米的单价,目标是估计房屋的价格,仅用2个特征的加权和是估计不准房屋的价格的,如果做特征交叉两个特征相乘就可以把房价估计的很准,所以交叉特征有用。
如果有 d 个特征,那么模型参数量正比于 d^2,大多数参数是特征交叉的权重 u,如果 d 较小模型没有问题,但如果 d 很大,那么参数数量就太大了,计算代价会很大,而且容易出现 overfit。
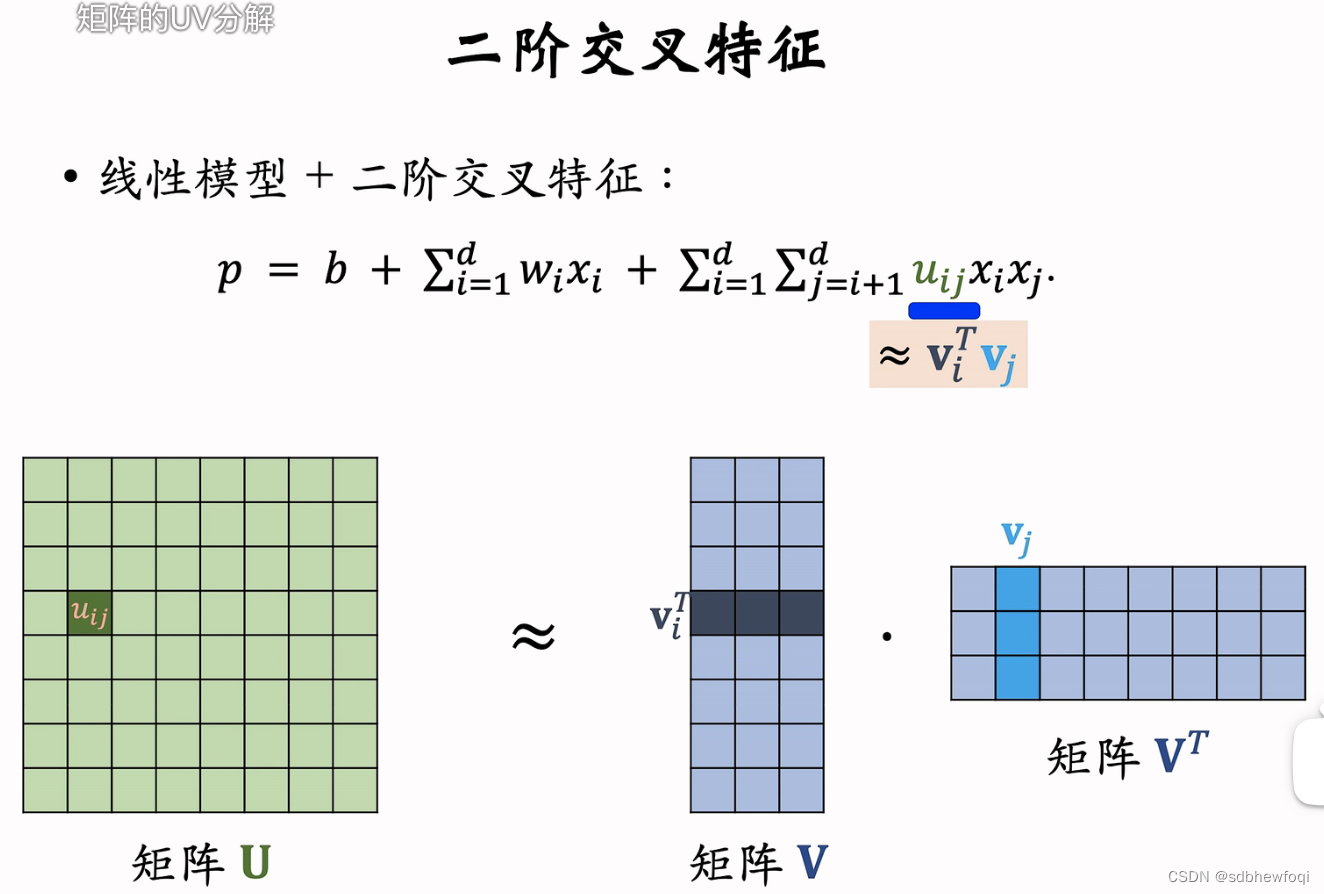
如何减少参数数量?重点关注交叉的特征的权重小 u,可以把所有的权重小 uij 组成矩阵大 U,小 uij是大 U 的第 i 行第 j 列的一个元素。矩阵大 U 有d 行和 d 列,d 的参数数量,U 是对称矩阵,可以对大 U 做低秩近似,用矩阵大 V 和大 V 转置来近似矩阵大 U,k 远小于 d,k 是超参,自己设置,k 越大,大 V 乘以大 V 转置就越接近矩阵大 U。
(将 uij近似为向量 vi和vj的内积,降低参数数量)

FM 用向量 vi 和 vj 的内积作为交叉特征的权重,FM的参数数量是矩阵 大 V 的大小,k 是超参数远比 d 小,FM 的好处在于参数数量更少,从 d^2降到 kd。使得推理的计算量更小不容易出现过拟合。

FM就是在线性模型后面加上交叉项,效果显著比线性模型好,好处是减少了参数数量。xhs 的召回和排序已经不再使用 FM。
17:12-17:37(理论6分钟,15分钟)
特征交叉02-DCN 深度交叉网络
Deep & Cross Networks (DCN) 译作“深度交叉网络”,可以用于召回双塔模型、粗排三塔模型、精排模型。DCN 由一个深度网络和一个交叉网络组成,交叉网络的基本组成单元是交叉层 (Cross Layer)。这节课最重点的部分就是交叉层。
DCN可以代替全连接层。
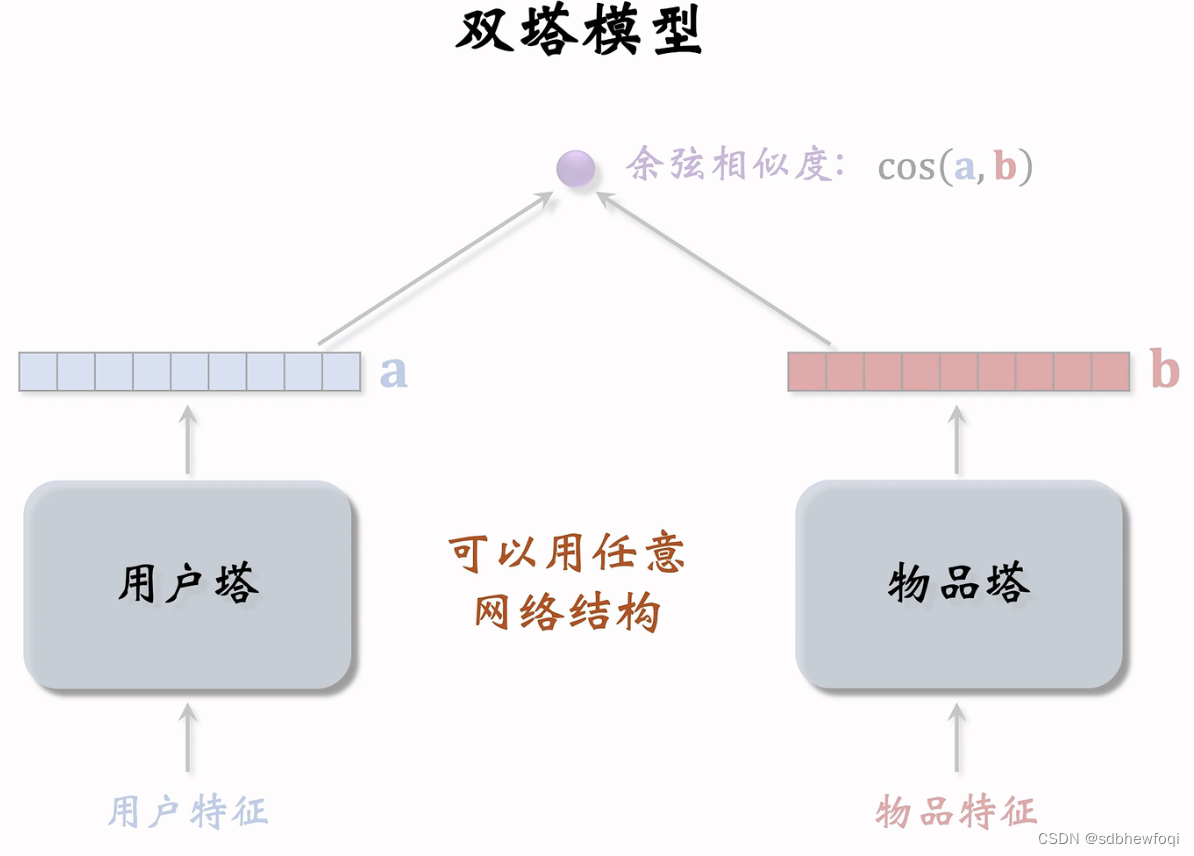
多目标排序模型
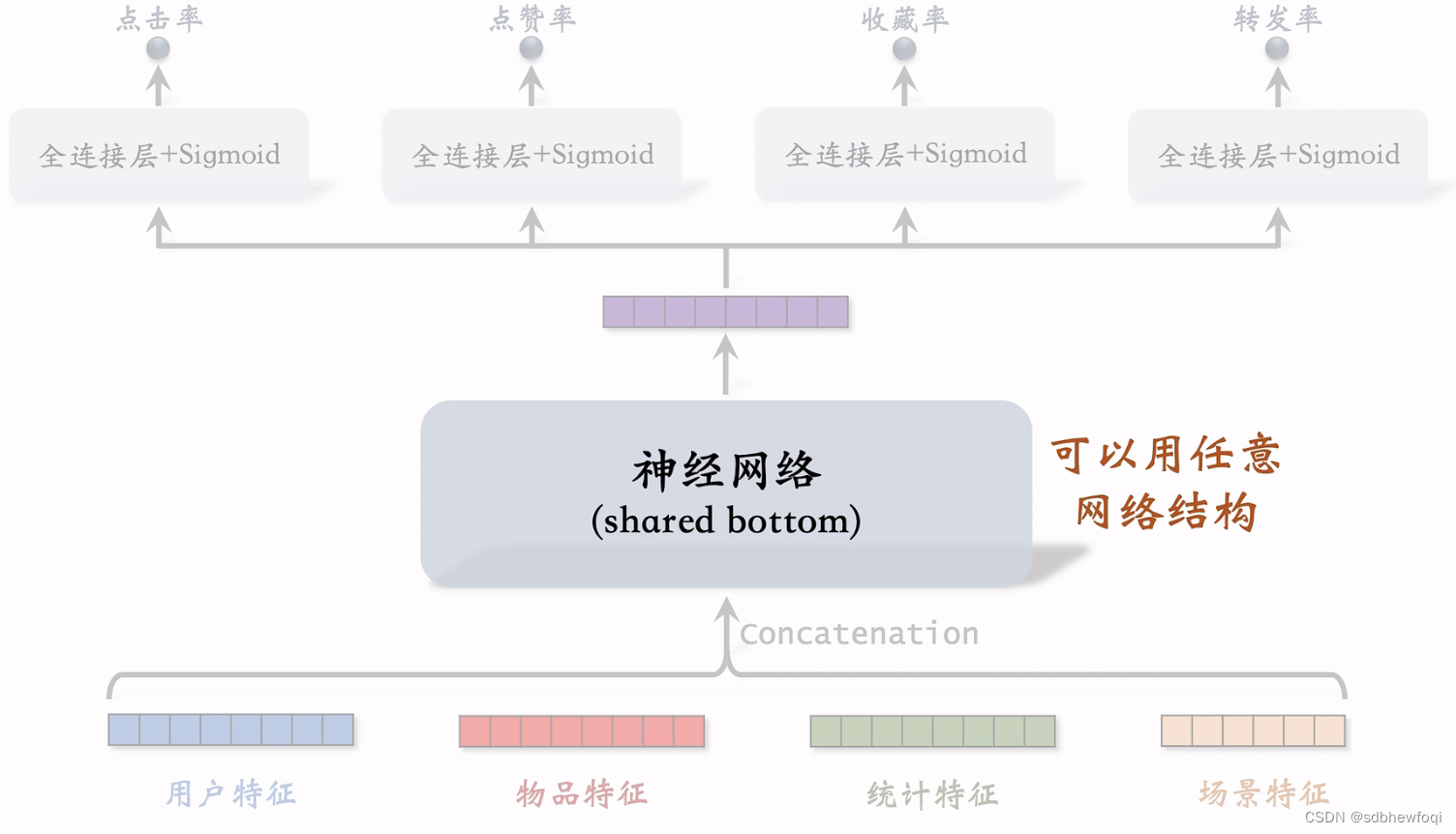
排序MMOE 模型,专家网络可以使用任意结构
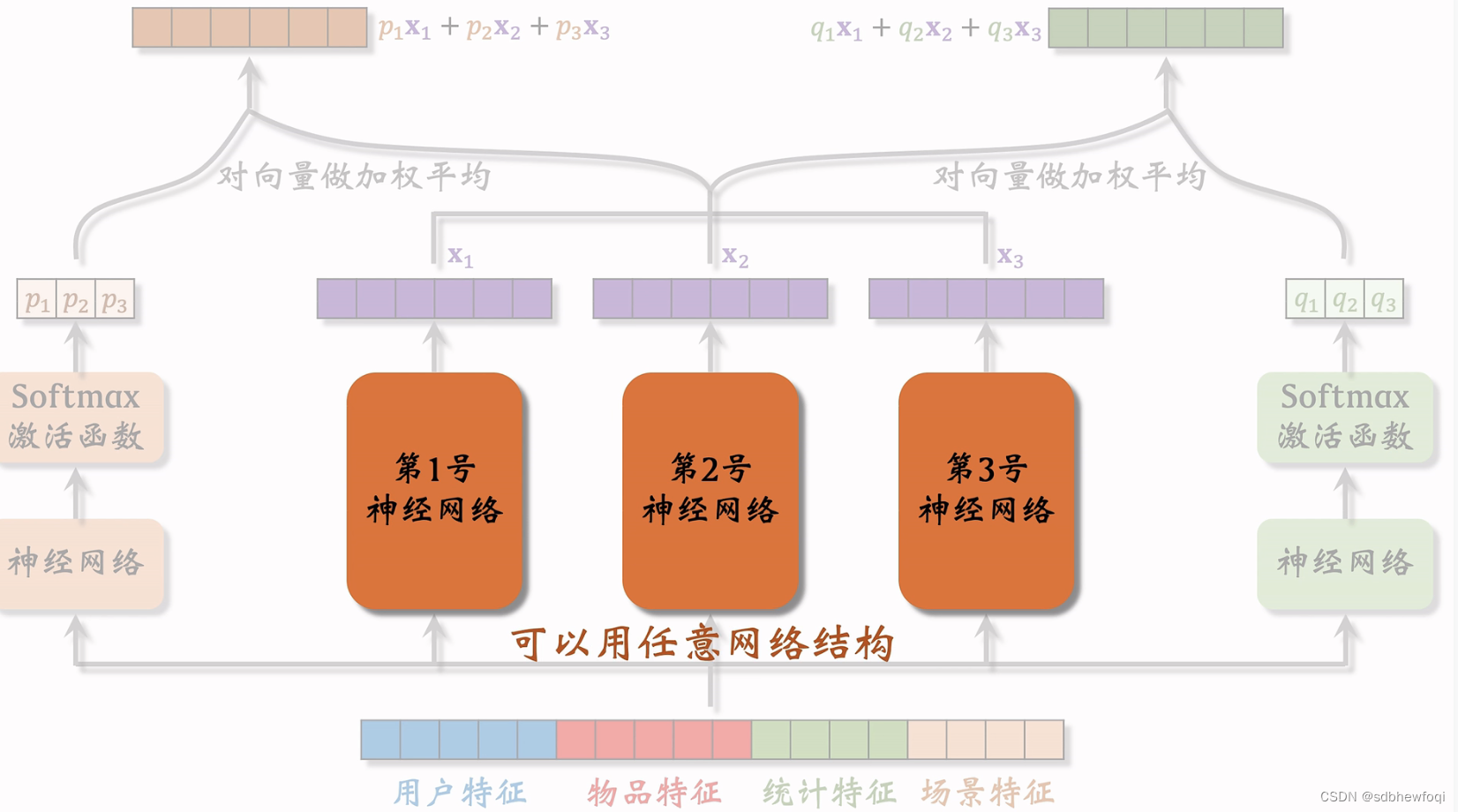
哪些模型可以应用DCN
- 双塔模型:物品塔和用户塔
- 多目标:shared bottom
- MMoE Multigate Mixture of Experts
交叉层是交叉网络的基本组成单元。
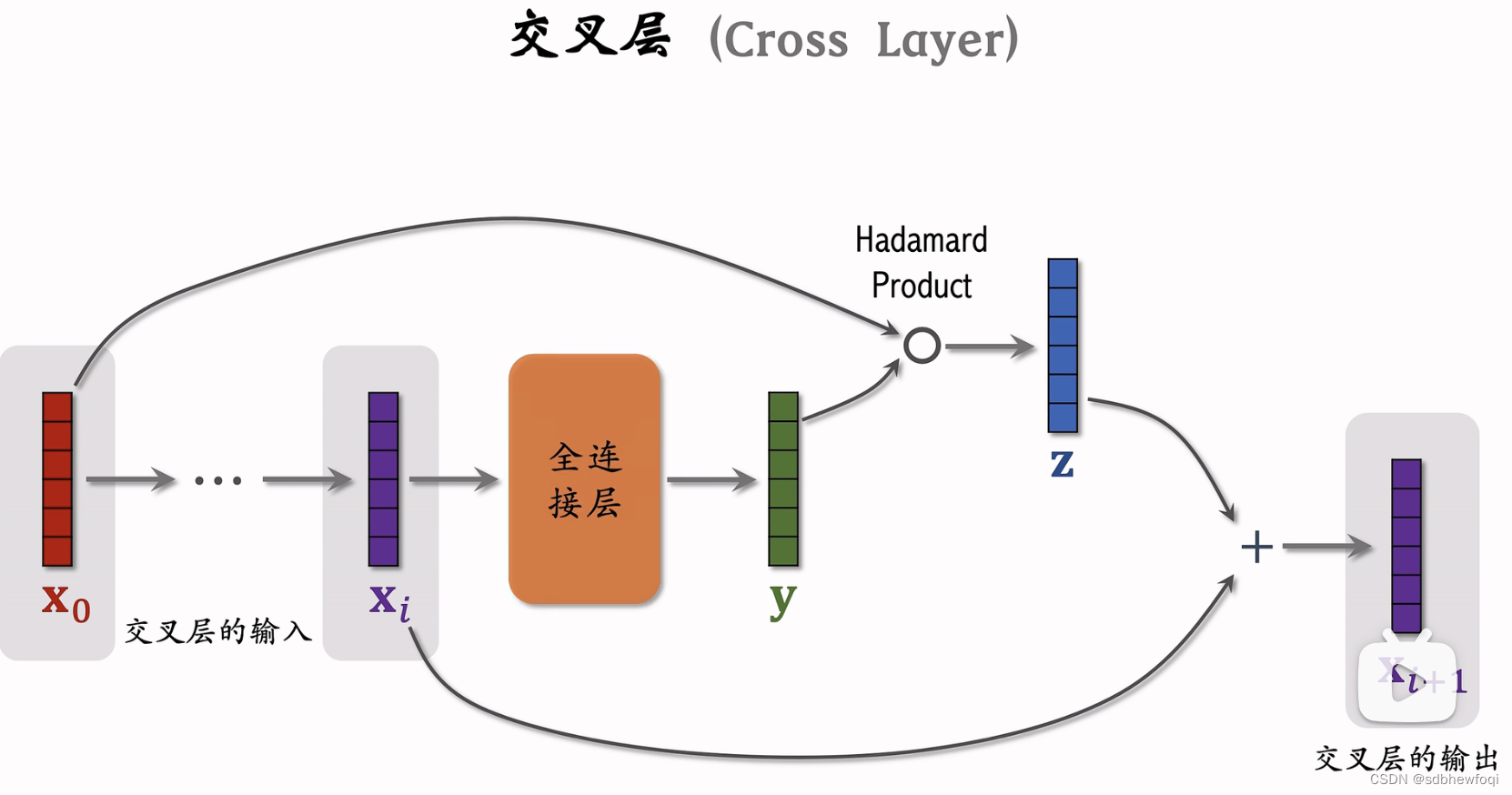
输入为 x0 经过 i 层之后输出为 xi,详细讲解第 i 个交叉层结构。把向量 xi 输入全连接层,全连接输出向量y,把最底层的输入向量 x0 与 向量y 做哈达玛乘积(逐元素相乘),如果 x0与 y 都是8维向量,那么他们的乘积也是8维的向量,把输出的向量记作 z,向量 xi 和 z分别是输入和输出,两个向量的形状一样,两个向量相加得到 xi+1,类似于resnet中的跳跃连接。
向量 xi+1是第 i个交叉层的输出,x0和 xi 是交叉层的输入,这个交叉层的参数全都在于『全连接层』中,其余操作是向量哈达玛乘积和向量加法,无参数。
Hadamard Product:哈达玛乘积,逐元素相乘。
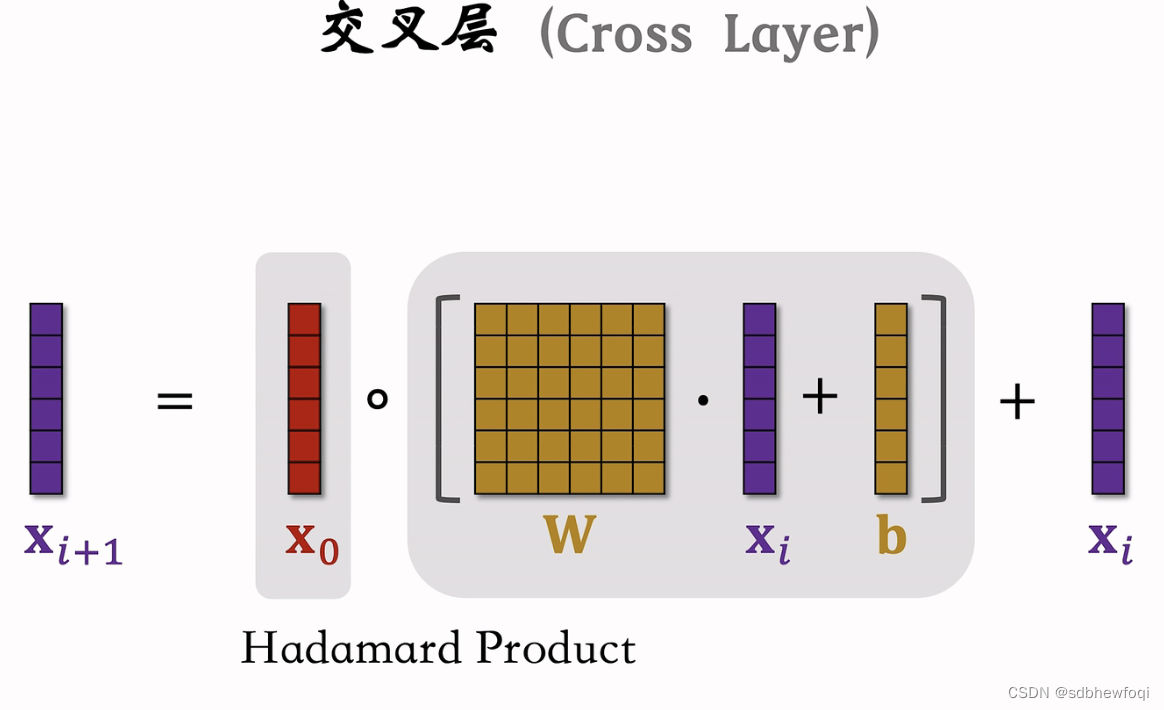
可以把交叉层写成这样的公式,交叉层的输入是两个向量 x0和 xi,x0是整个神经网络最底层的输入,xi 是神经网络第 i层的输入。全连接层的输出是向量和输入 xi 的大小一样。矩阵 W 和向量 b 是全连接层中的参数(也是交叉层的全部参数),参数需要在训练中用梯度去更新。
输入x0和全连接层的输出做哈达玛乘积(要求左右两边向量形状相同),将结果与向量 xi 相加。将输入与输出相加是 resnet 中的跳跃链接,防止梯度消失。
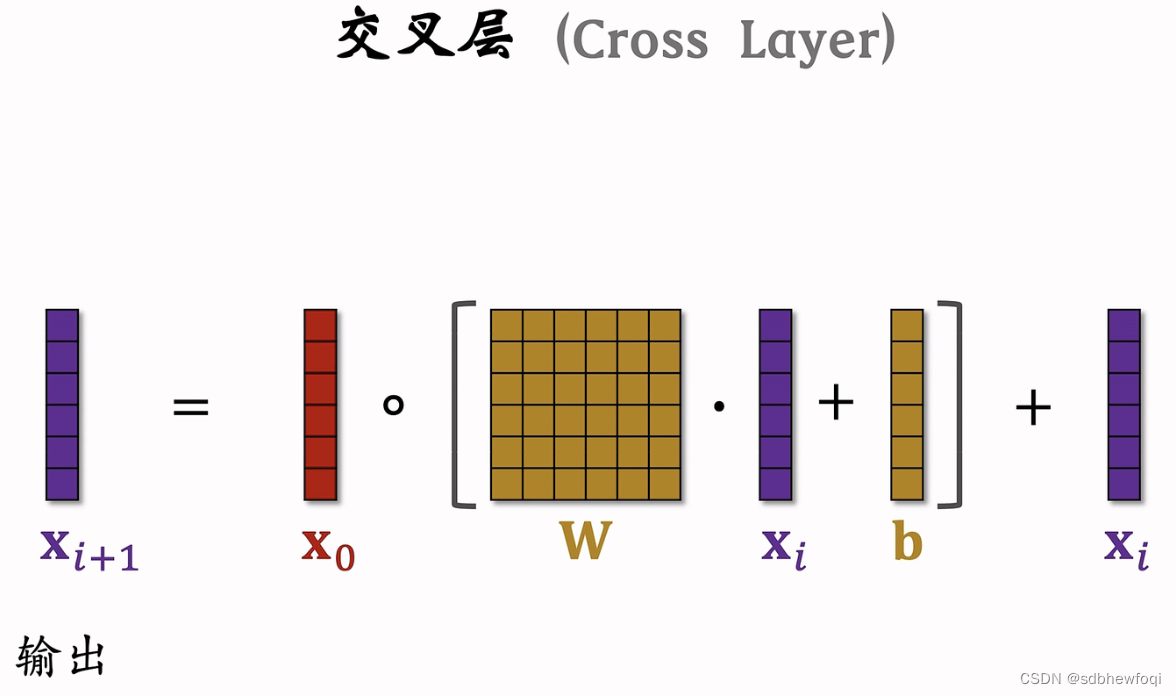
xi+1是交叉层的输出,形状和 x0和xi 是一样的,每个交叉层的输入和输出都是形状一样向量的。
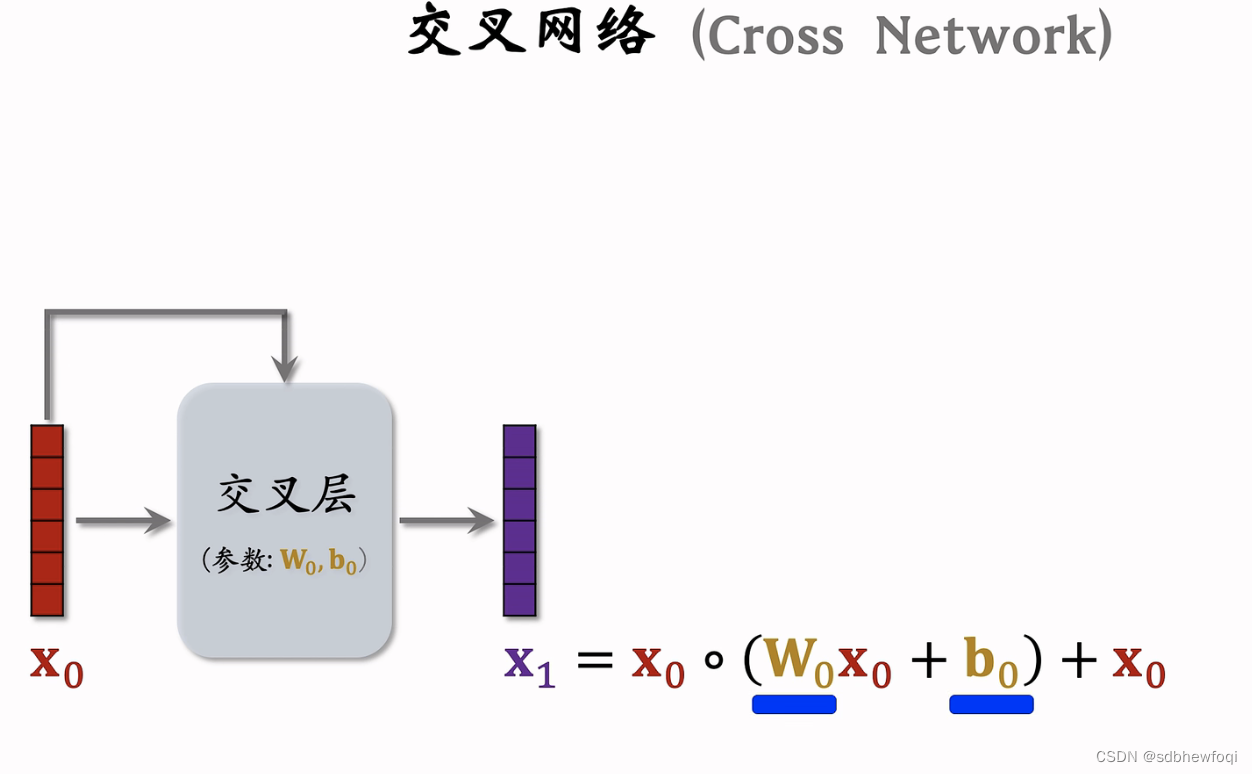
向量 x0是交叉网络的输入,送入交叉层,交叉层输出向量 x1。
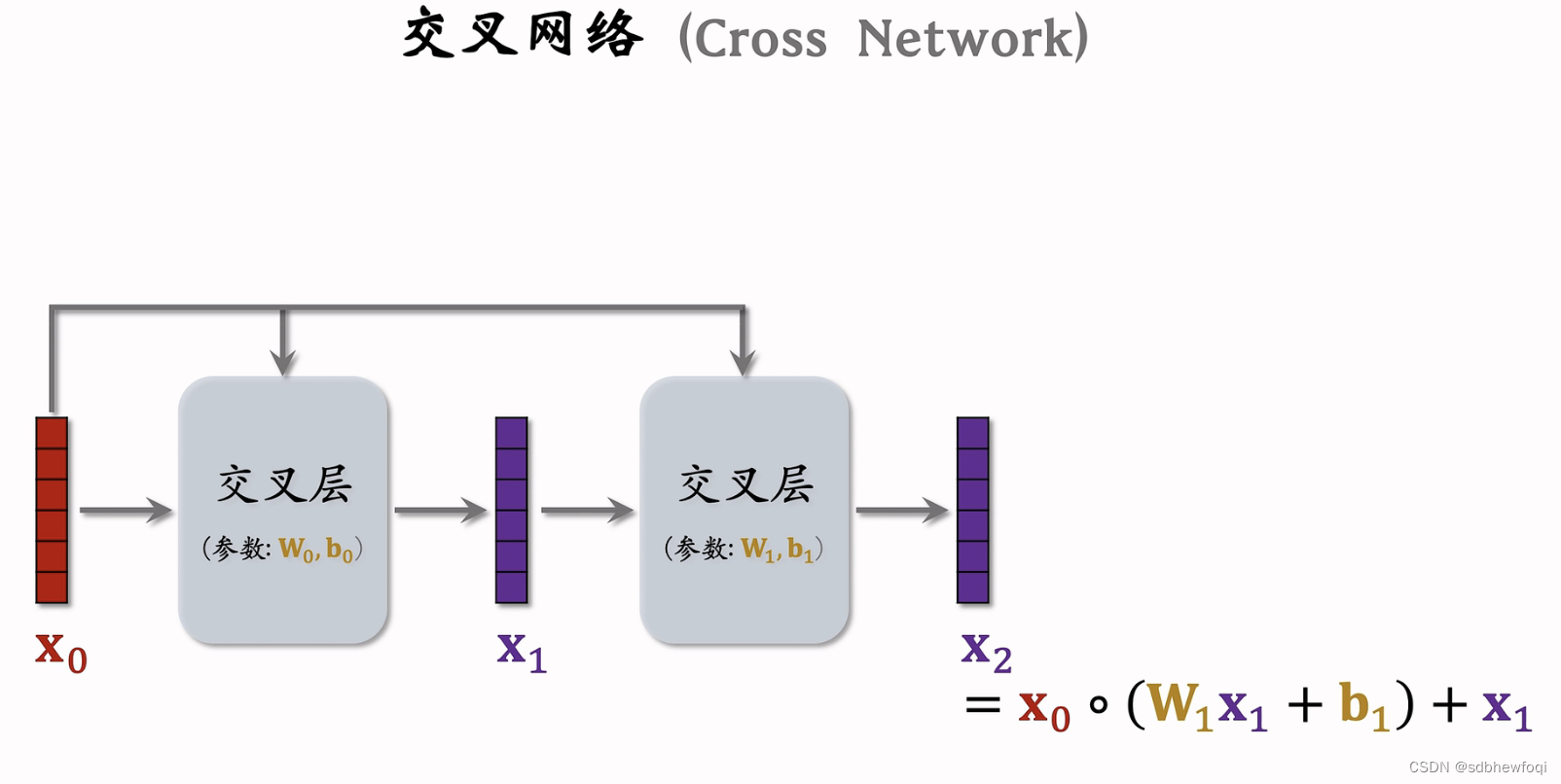
把上一层的输出 x1输入下一个交叉层,x0还需要输入,这个交叉层输出向量 x2。
可以一直重复这个结构。
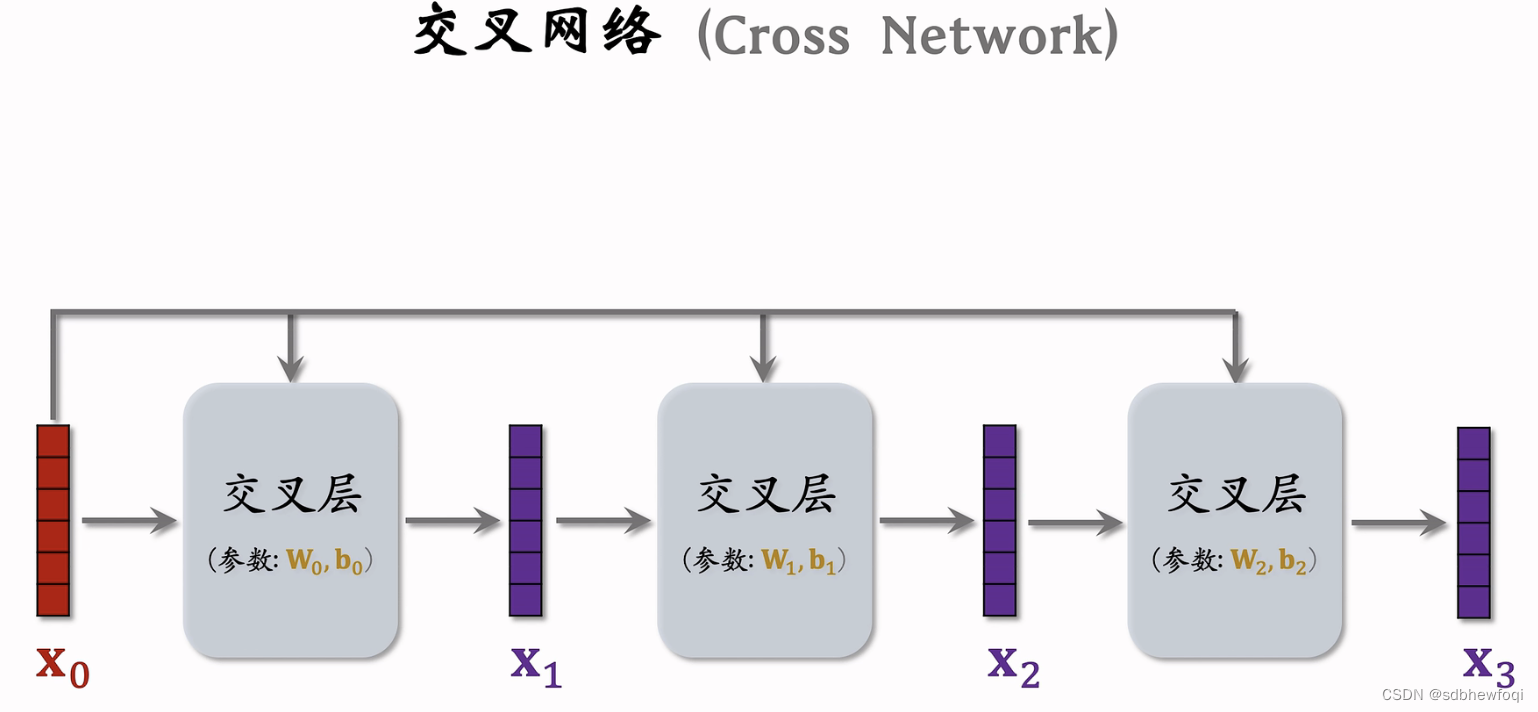
x3为交叉网络的输出。

第二个已经没用了,大家没必要去看了。
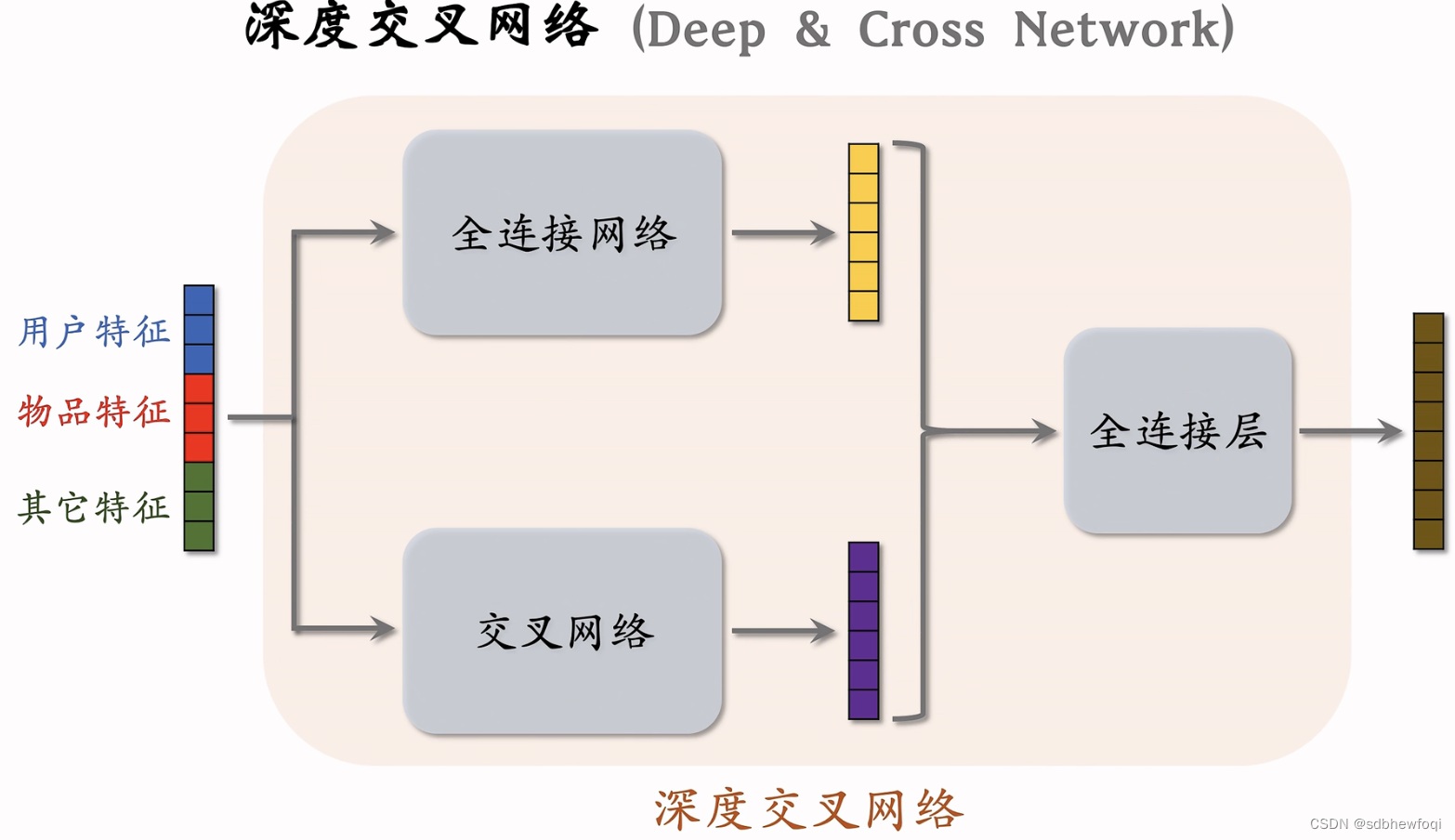
DCN将交叉网络与普通的全连接网络结合起来。
推荐系统中召回和排序模型的输入是用户特征,物品特征,其他特征,做 concatenate然后输入两个神经网络,上面为全连接网络,下面为交叉网络,两个网络并联,两个网络各输出一个向量,将两个向量 concatenation输入一个全连接层,输入一个向量。
双塔中的用户塔和物品塔都可以是DCN,MMOE中的专家神经网络也可以是 DCN。
22:36-23:04(理论7分钟,18分钟)
特征交叉03-LHUC(PPnet)
这节课介绍 LHUC 这种神经网络结构,只能用于精排。LHUC 的起源是语音识别,后来被应用到推荐系统,快手将其称为 PPNet,现在已经在业界广泛落地。与 DCN 类似。
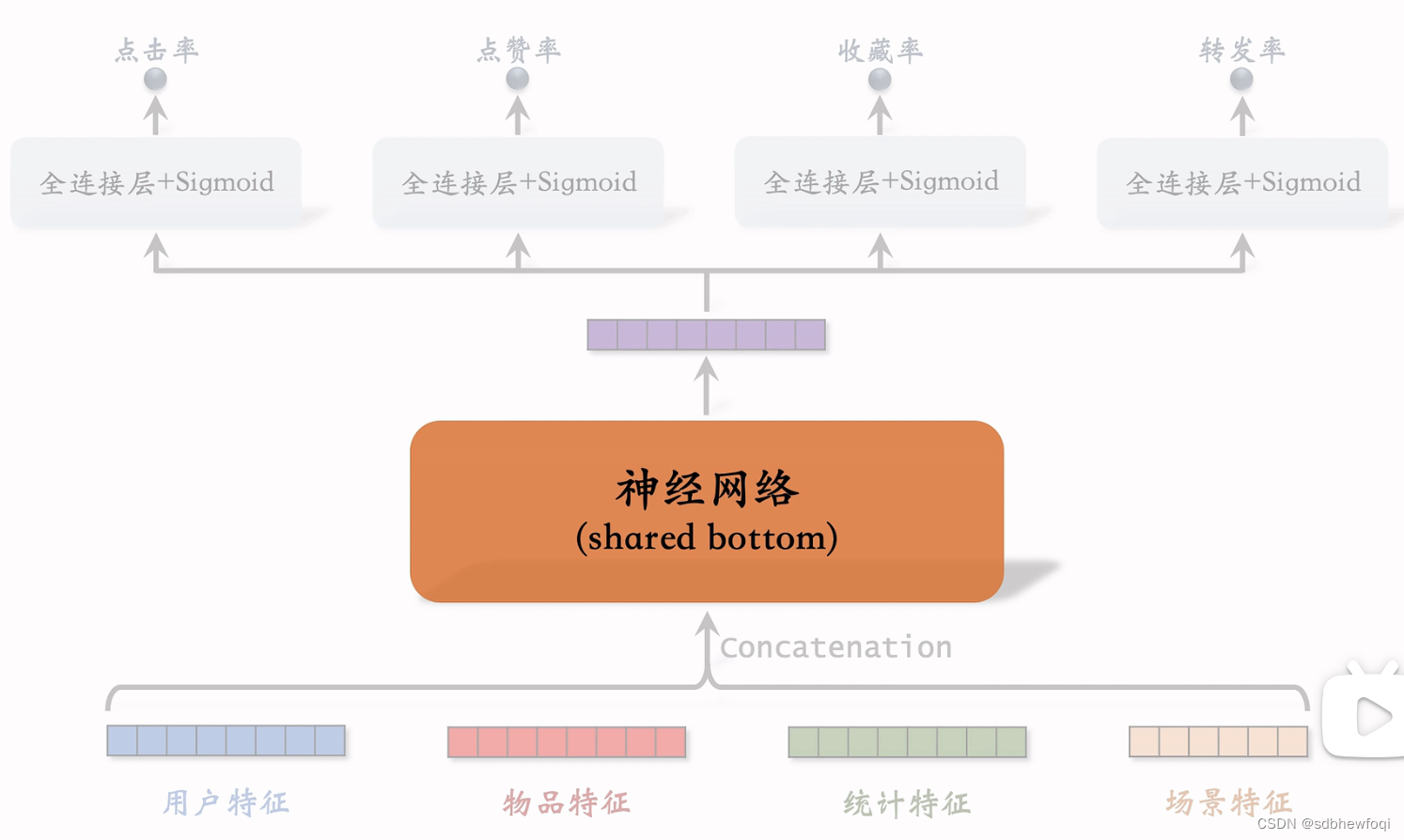
这是标准的排序模型,shared bottom用什么网络都可以。

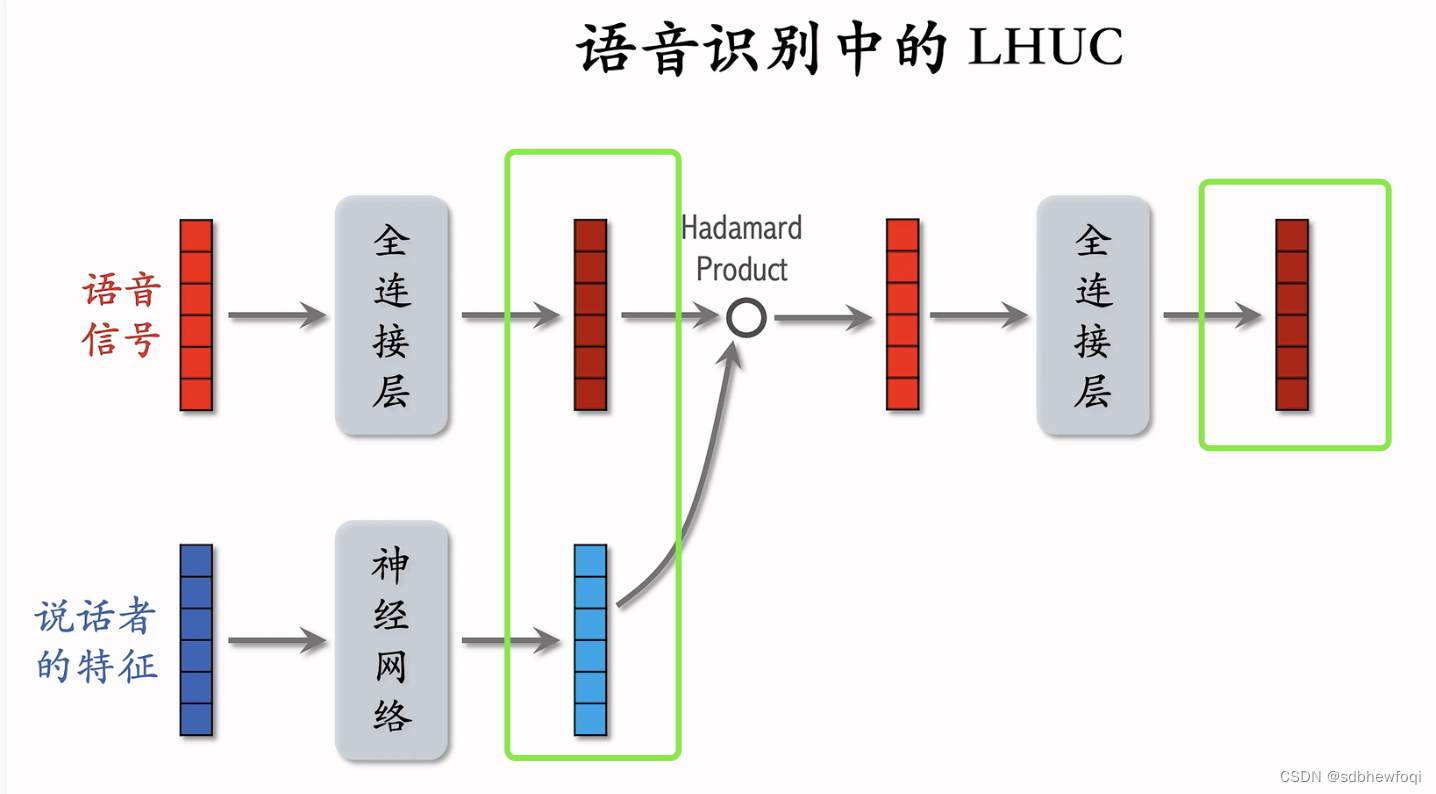
语音识别的输入是一段语音信号,我们希望用神经网络对输入的信号进行变换得到更有效的表征,然后识别出语音中的文字。 语音是人说的,不同的人声音不一样,所以最好加入个性化(说话者特征),最简单的特征是说话者的 id emb。
lhuc网络结构:把语音信号输入fc,输出向量。把说话者的特征输入另一个nn,输出另一个向量。
nn 包含多个 fc,最后一个 fc 的激活函数是 sigmoid*2,单独作用到每个元素上。蓝色向量每一个都介于0-2之间。红色和蓝色的向量形状必须完全一致,因为要计算哈达玛乘积。
将语音信号特征和说话者特征相融合。语音信号有的特征被放大,有的特征被缩小,可以做到个性化。
哈达玛乘积得到向量,形状和输入向量一致,把这个向量输入下一个fc,输出形状相同的向量。
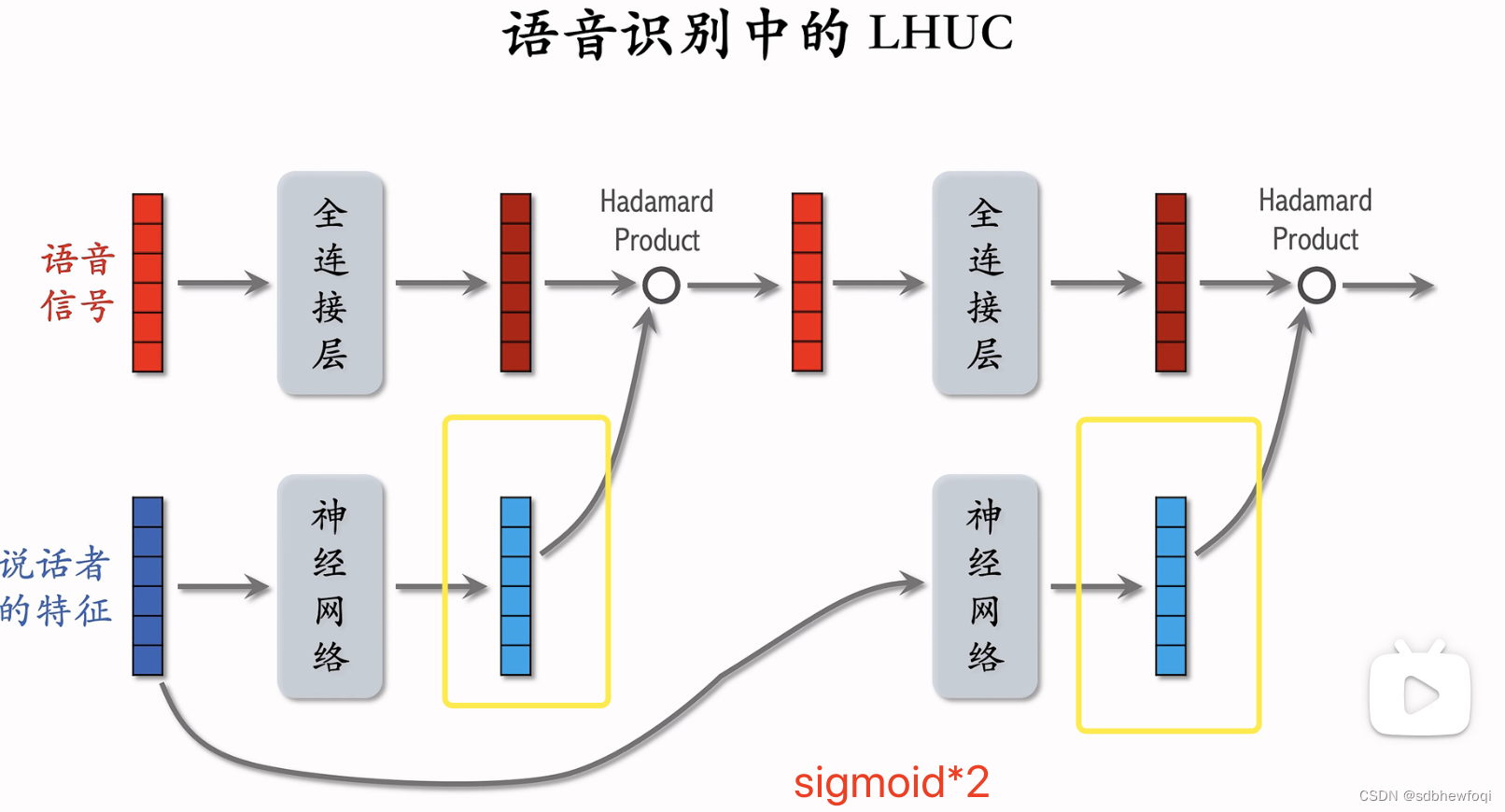
把说话者特征也输入到一个 nn。这个 nn 有多个 fc,最后一个 fc 激活函数也是sigmoid*2,输出向量是对说话者的表征。
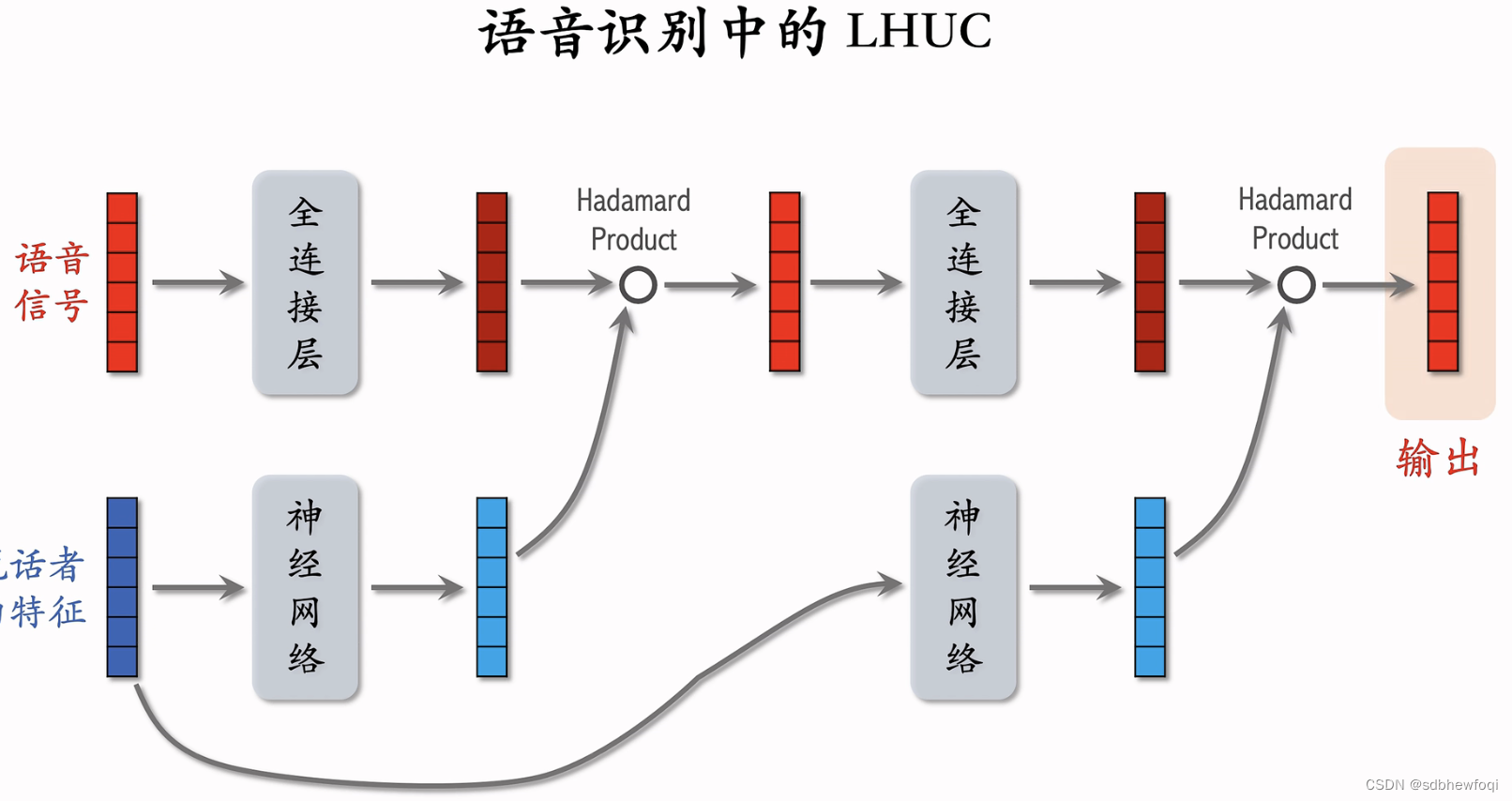
上栗子,LHUC只重复了 2个模块,重复了2次哈达玛乘积,实践中可以更深。
都是说话者特征!都是 sigmoid*2!与语音信号做哈达玛乘积会放大和缩小特征实现个性化。
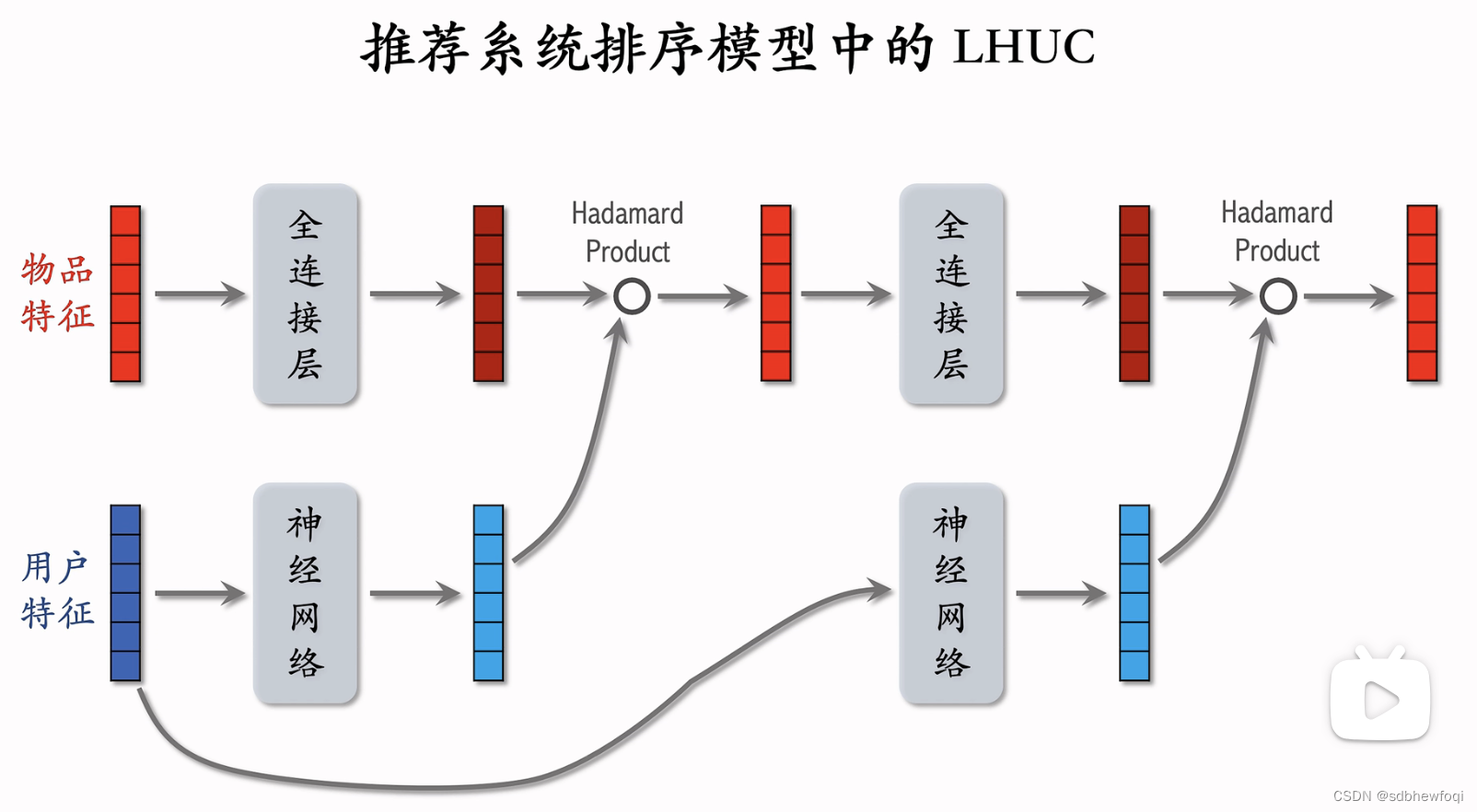
在推荐系统中,输入为物品特征(语音信号),用户特征(说话者特征)。
23:06-23:24(4,18)
特征交叉04-SENet和Bilinear 交叉
这节课介绍几种方法:
- 1. SENet 是计算机视觉中的一种技术,可以用在推荐系统中对特征做动态加权。
- 2. 双线性(bilinear)特征交叉可以提升排序模型的表现。有很多种 bilinear 交叉的方法。
- 3. FiBiNet 是将 SENet 与 Bilinear 模型结合。
- 4. 这两种方法用在排序模型上都有收益。

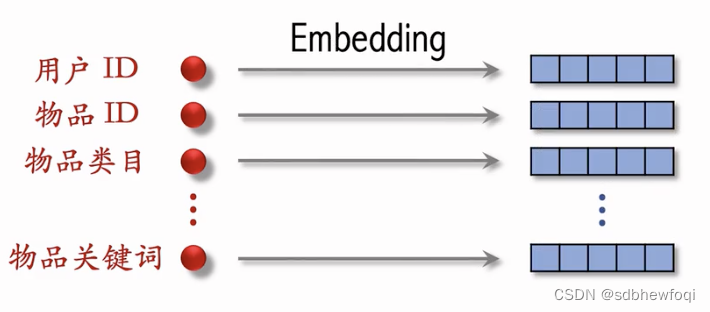
推荐系统用到的离散特征(红点),做 emb得到很多向量。
senet主要对这些特征进行变化。
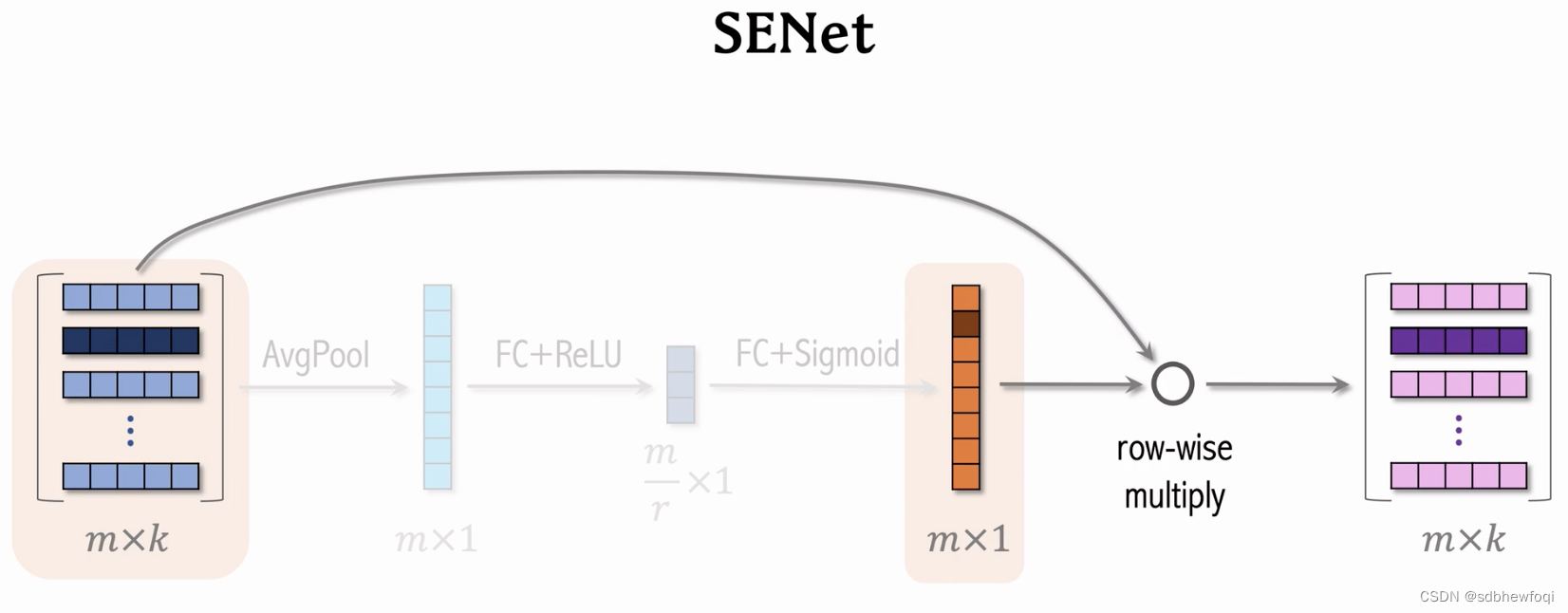
假设有 m个特征,每个特征 k 维,把所有特征表示为 m*k 的矩阵,对矩阵的行做 avg pool得到一个 m 维向量,向量的每个元素对应一个离散特征。比方说第一个特征对应用户 id。
用一个fc 与 relu 激活函数将一个 m 维的向量压缩为 m/r 的向量,r是压缩比例(大于1)。
再用一个 fc+sigmoid恢复出一个 m 维的向量,橙色向量的元素都介于0-1之间,使用橙色向量对输入向量进行加权,把向量逐行乘在矩阵上,得到粉色矩阵,大小与输入矩阵一样。
比方说学出物品 id 对物品重要性不高,那么就给物品 id emb降权。
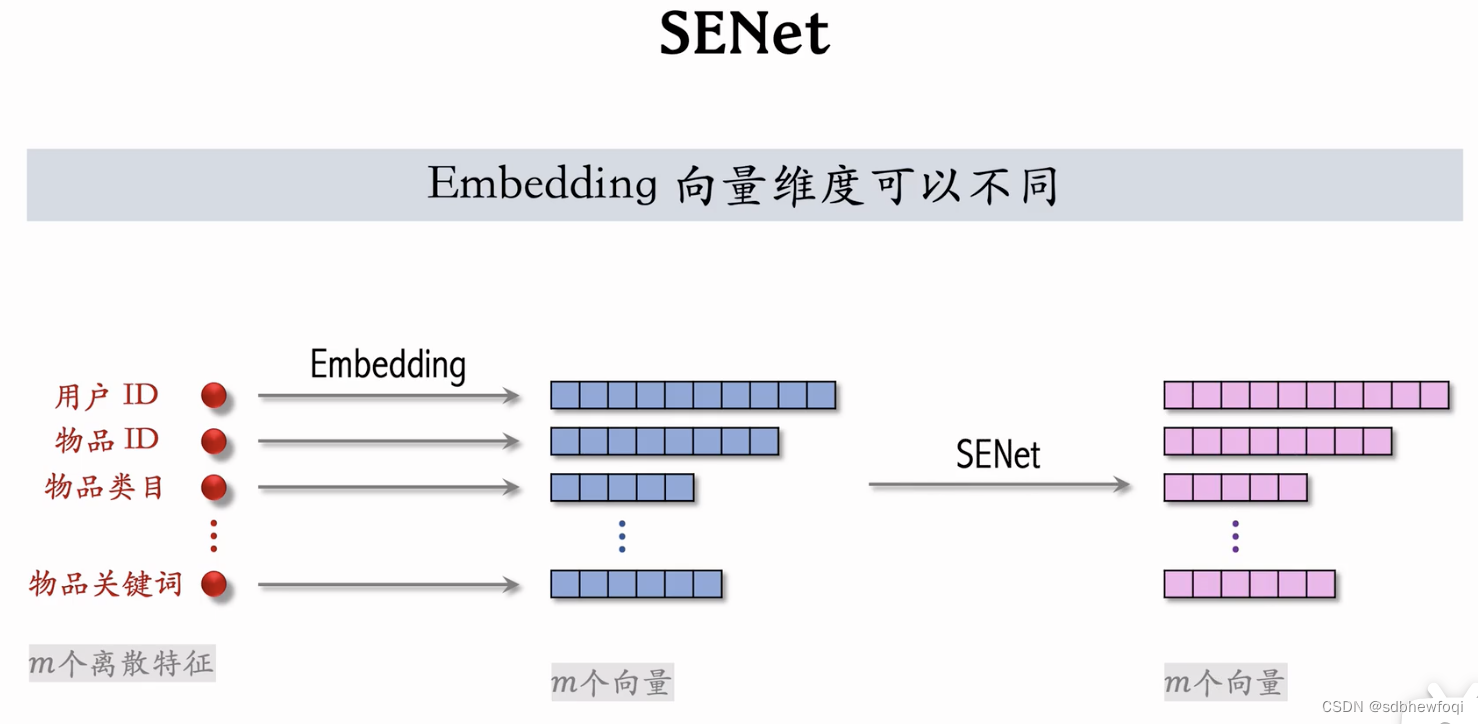
但 m个向量的维度可以不同(可以不同时等于 k),不会影响 senet。
senet 对每个向量做 avg pool,得到 m 维向量,再用2个 fc得到另一个 m 维向量,用来对 m 个向量做加权。最终 senet输出右边 m 个向量,与左边蓝色形状完全相同。

概括:
- 本质对离散特征做 field-wise 加权。
- m个特征,m 个 fields,权重向量 m维。 senet 会根据所有特征自动判断每个 field的特征重要性,重要的field权重高。
上面 senet 对特征做 field wise加权,下一部分是field 之间的特征交叉。 把两个 field 做交叉得到一个新的特征。比方说,把用户所在地点和物品所在地点各自做 emb,然后把两个向量做交叉。
具体讲怎样交叉两个向量?
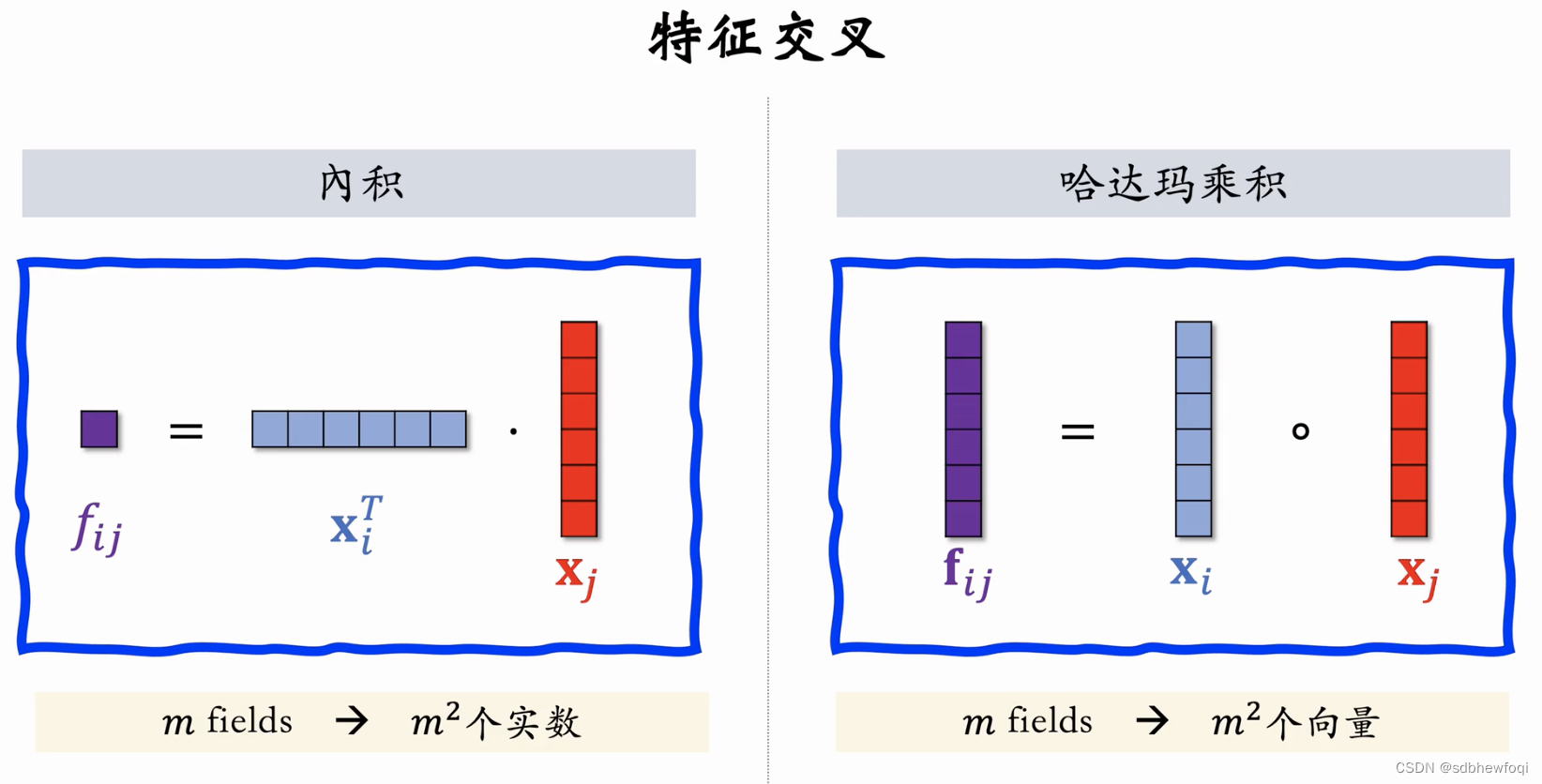
内积和哈达玛乘积是两个最简单的特征交叉方法。
内积:xi,xj 是两个特征的 emb,fij 是实数。
如果有 m 个 fields(m种离散特征)则有 m^2个实数。推荐中 m数量不大,也就几十。
---
哈达玛:
如果有 m 个 fields,则有 m^2个向量(太多)。通常来说用哈达玛乘积做特征交叉,必须要人工选择一些 pair,而不能对 m 个 fields 两两交叉。
以上都要求特征的维度一致,即 k 维向量。形状不一样就不能计算内积和哈达玛乘积。
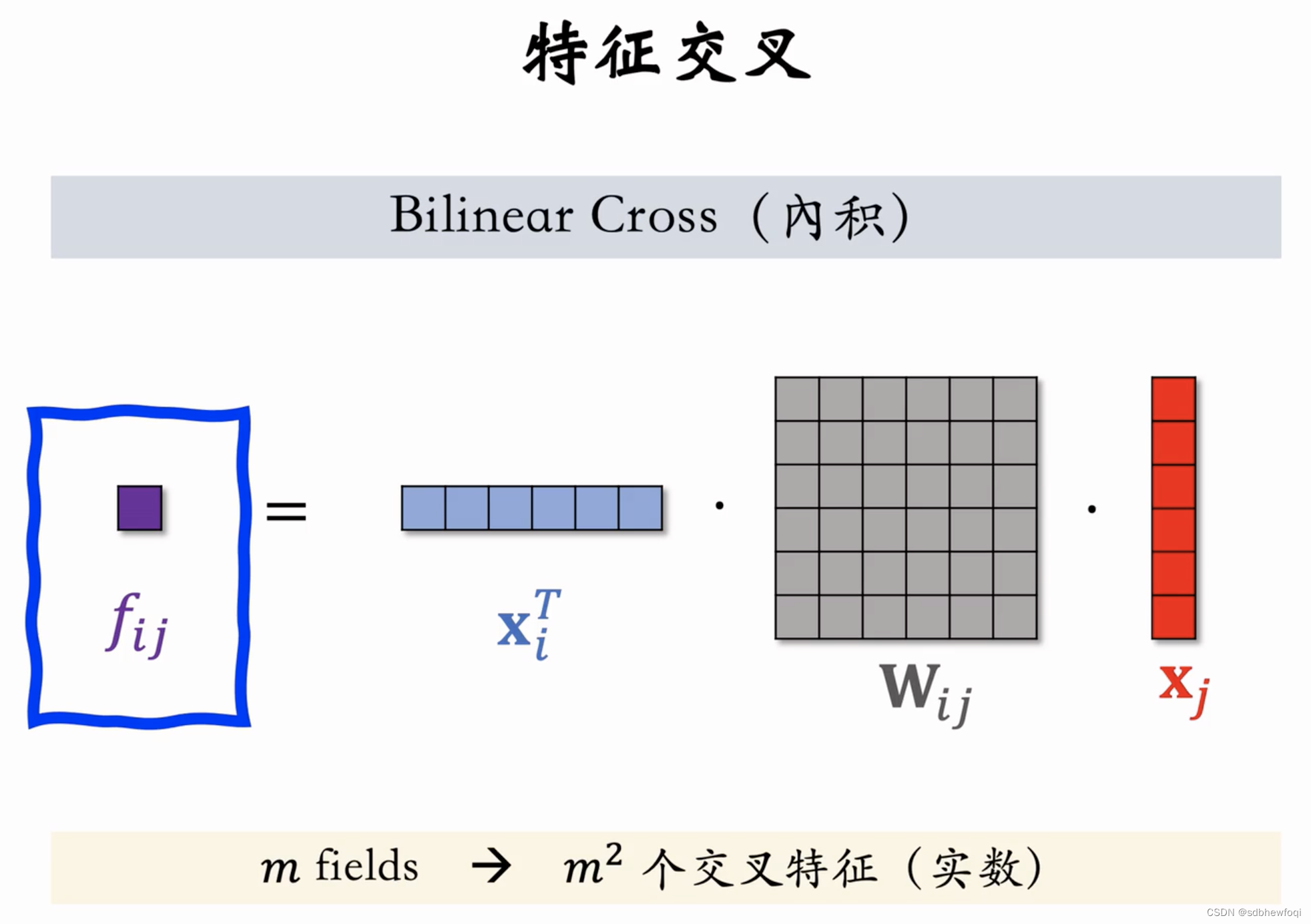
bi cross 一种更先进的特征交叉方法,有内积和哈达玛乘积两种交叉方式。
xi,xj是特征 emb,形状可以相同也可以不同。fij 是实数。
m^2个 fij (交叉特征的数量)还好。但是 wij 太多了不行,实际需要很多的 wij矩阵(举例 ab之间需要,ac 之间还需要)
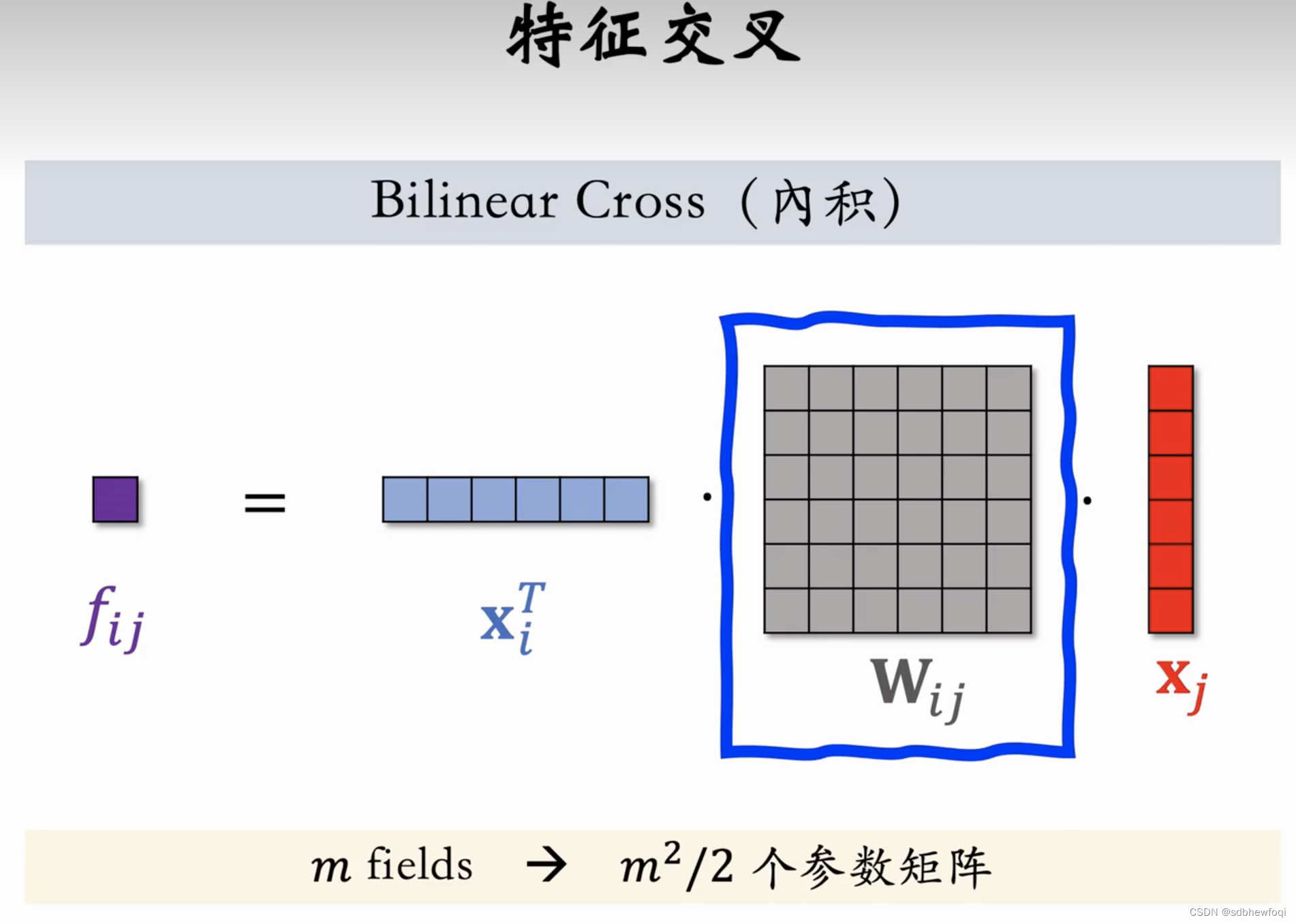
若有 m个离散特征(fields),则有 m^2/2个参数矩阵。假如每个参数矩阵大小都是64*64,有1000个参数矩阵,那么 bi cross 的参数量是400万,参数量太大不可行。
需要人工指定重要的特征做交叉,不能所有特征做两两交叉。
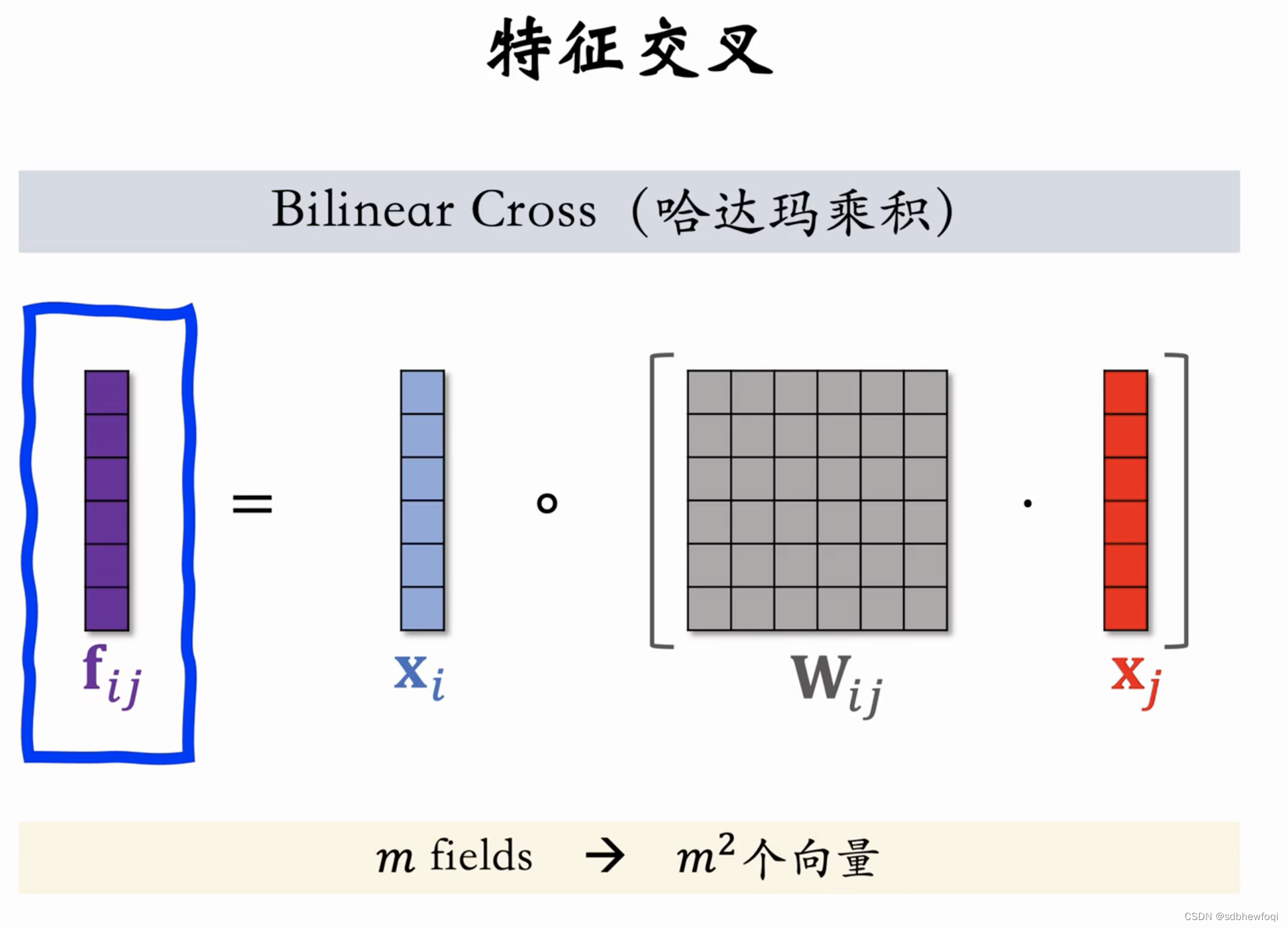
区别用哈达玛乘积替换内积。先求括号内容,再求哈达玛乘积,输出 fij 向量。
特征间两两交叉,m 个 fields 产生 m^2个向量。m^2个向量做 concat,得到的向量维度太大且大多数是无意义的。还是要人工指定 pair。

1. senet让重要特征权重大;
2. 让两种特征的 emb 向量做特征交叉。
FiBiNet

把 senet 和 bi cross结合起来就是 fibinet。
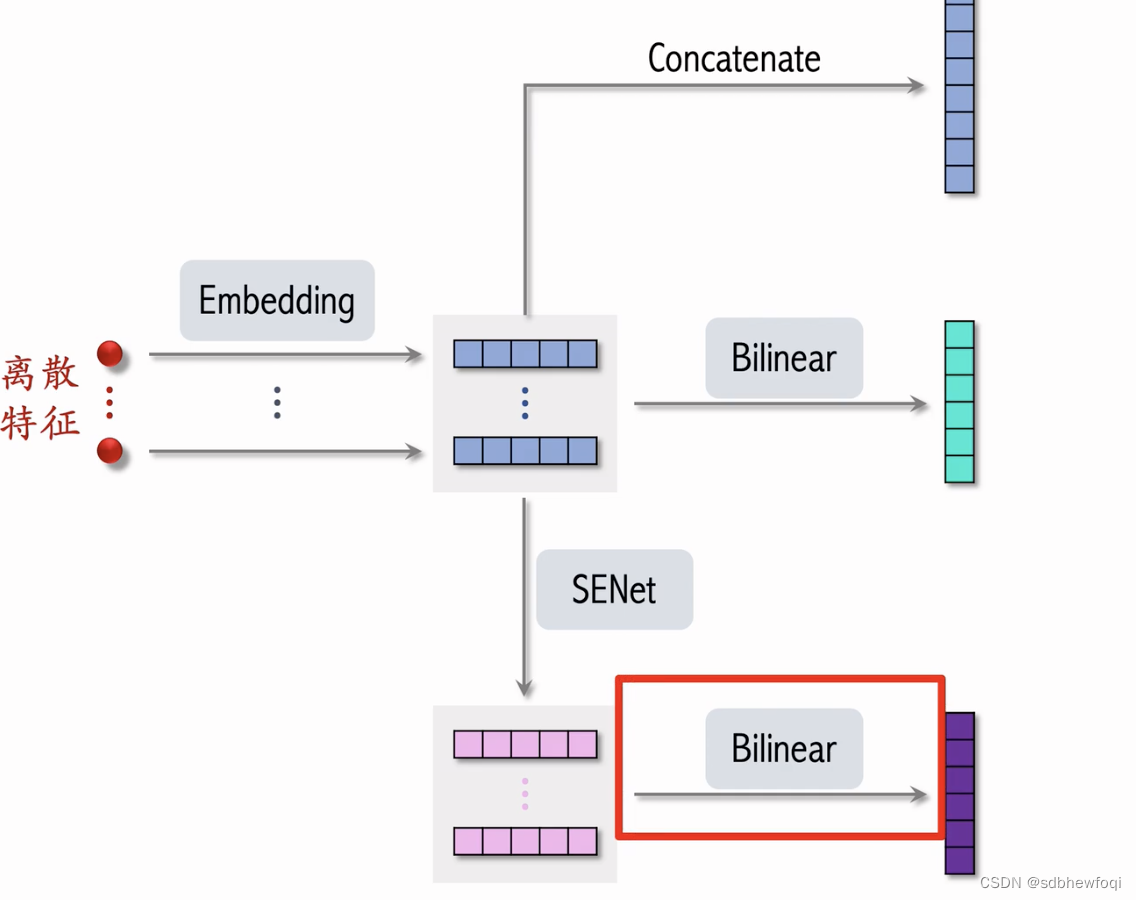
离散特征(用户 id,物品 id,物品类目)-> emb-> 用一个向量表示一个特征。这些特征做 concat得到一个高维向量(以前把这个向量直接作为排序模型的输入)。
fibinet 则对emb做 bi cross 得到很多交叉特征,拼接为一个向量。
senet 对 emb向量做加权得到同样大小的向量。小红书没有用红框的 bi corss,直接对 senet的输出做 concat。
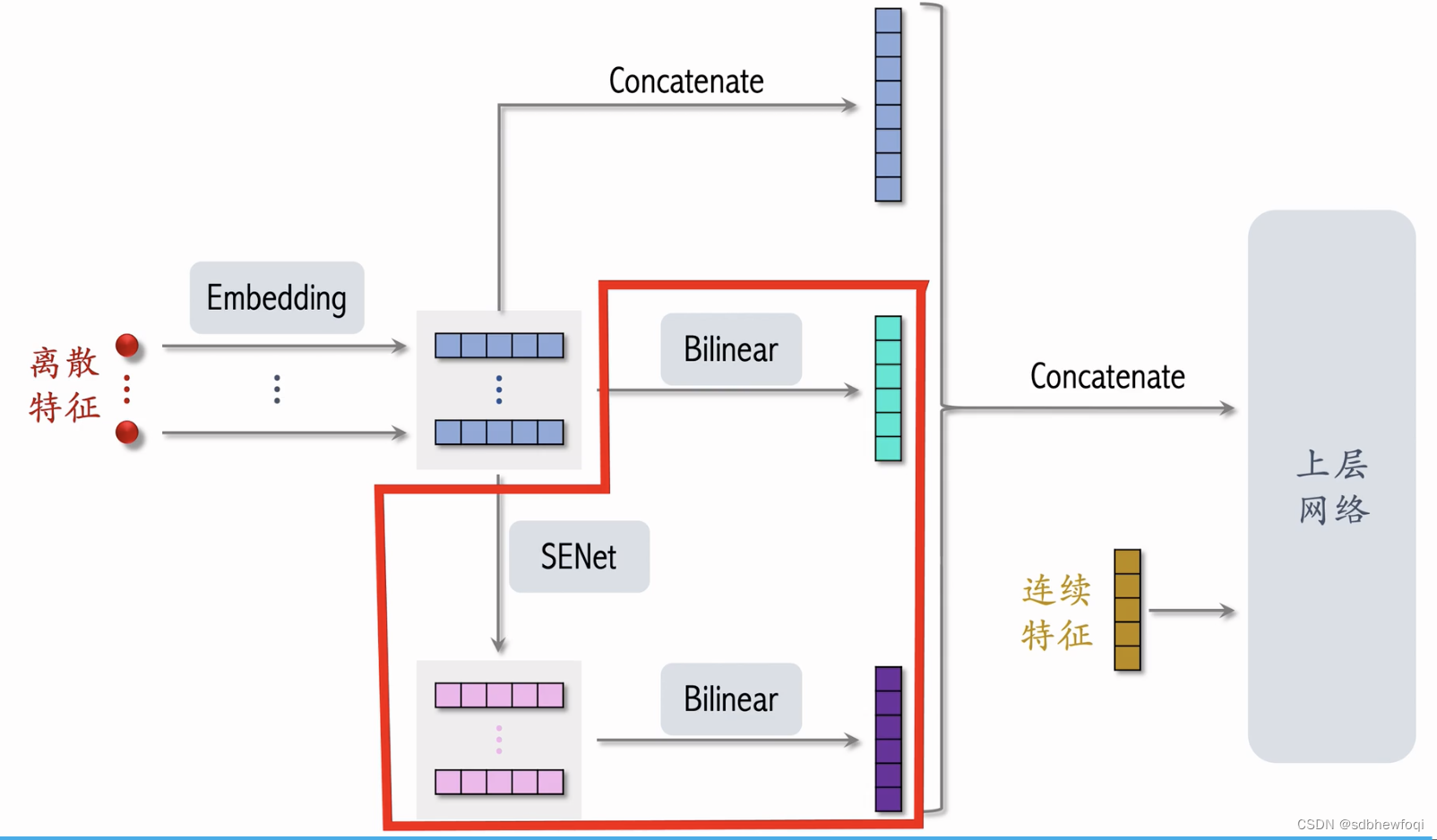
完整结构。红框为与其他简单精排模型的区别。senet 和 bi cross 在精排模型中有效。借鉴方法但没有照搬。
23:24-00:04 (8,40)