目录
- 文章导航
- 一、概率基础与性质
- 二、概型模型
- 1、古典概型
- 2、几何概型
- 3、伯努利试验概型
- 三、组合和排序
- 1、组合
- 2、排序
- 四、概率分布
- 1、离散型分布
- ①伯努利分布
- ②二项分布
- ③泊松分布
- 2、连续型分布
- ①均匀分布
- ②指数分布
- ③正态分布/高斯分布
- ④对数正态分布
- ⑥幂律分布
- ⑦帕累托分布
- ⑧韦伯分布
- 3、特定应用分布
- ①卡方分布
- ②学生T分布
- 五、期望与方差
- 1、期望
- 2、方差
- 3、结合
文章导航
【一 简明数据分析进阶路径介绍(文章导航)】
一、概率基础与性质
概率,是度量某一事件发生的可能性大小的数值。概率的基本性质包括:
- 非负性:对于任意事件A,有P(A) ≥ 0。
- 归一性:对于必然事件S,有P(S) = 1。
- 可加性:对于互斥事件A和B,有P(A∪B) = P(A) + P(B)。
案例:投掷一枚均匀的硬币,正面朝上的概率为P(正) = 0.5,反面朝上的概率为P(反) = 0.5。由于正面和反面是互斥的,所以P(正∪反) = P(正) + P(反) = 1。
二、概型模型
1、古典概型
是一类具有有限个“等可能”发生的基本事件的概率模型。其特点是:试验结果的有限性和每一个试验结果出现的等可能性。古典概型是概率论中最直观和最简单的模型,但它只适用于试验结果的有限性和等可能性的场合。
2、几何概型
它的特点与古典概型相似,也是等可能性,但它的实验结果(基本事件)是无限多个的。
3、伯努利试验概型
是关于独立重复试验序列的一类重要的概率模型。在相同的条件下重复地、相互独立地进行的一种随机试验,叫做伯努利试验。伯努利试验只有两种可能的结果,即“成功”和“失败”。
三、组合和排序
1、组合
组合是指从一个较大(n个)对象群体中取出一定数目(r个)对象,但不必知道所选对象的确切顺序。换句话说,组合关注的是对象的选择,而不是它们的排列顺序。
想象一个魔法师的帽子里有很多不同颜色、形状和大小的宝石。如果魔法师想从帽子里选出三颗宝石用于施展魔法,他关注的是选出了哪些宝石,而不是这些宝石被选出的具体顺序。因为无论这三颗宝石是按照什么顺序被选出的,它们组合在一起的效果都是一样的。
2、排序
排序,或者说排列,是指从一个较大(n个)对象群体中取出一定数目(r个)对象进行排序,并得出排序方式的总数目。与组合不同,排列不仅关注对象的选择,还关注它们的排列顺序。
一个小型赛车比赛,假设有十辆赛车参加比赛,我们需要确定前三名的具体排名。这里,不仅需要考虑哪三辆车将占据前三名的位置,还需要明确它们之间的具体排名顺序。因为第一名、第二名和第三名的顺序对于比赛结果来说是非常重要的。
四、概率分布
1、离散型分布
①伯努利分布
伯努利分布是一个离散型概率分布,它描述的是只有两种可能结果(通常记为0和1)的单次随机试验。例如,抛硬币的结果(正面或反面)就是一个伯努利试验。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # 假设伯努利试验成功的概率为 p
p = 0.6 # 假设成功的概率为60% # 生成伯努利分布的样本数据
n_samples = 1000 # 样本数量
bernoulli_samples = np.random.choice([0, 1], size=n_samples, p=[1-p, p]) # 创建一个计数数组,用于统计0和1的出现次数
counts = np.bincount(bernoulli_samples) # 准备x轴标签
x = np.arange(len(counts)) # 绘制条形图
plt.figure(figsize=(8, 6))
sns.barplot(x=x, y=counts, palette="Blues_d") # 设置x轴标签
plt.xlabel('Outcome')
plt.xticks(x, ['0 (Failure)', '1 (Success)']) # 设置y轴标签
plt.ylabel('Frequency') # 设置标题
plt.title(f'Bernoulli Distribution with p={p}') # 显示图形
plt.show()
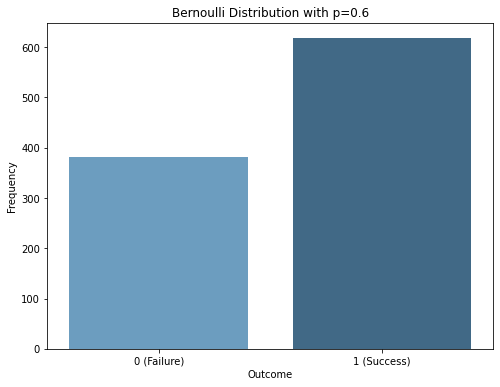
②二项分布
二项分布描述的是在n次独立的伯努利试验中,成功发生k次的概率。例如,抛硬币10次,正面朝上的次数。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import binom # 设置二项分布的参数
n = 10 # 试验次数
p = 0.5 # 成功概率 # 生成二项分布的概率质量函数(PMF)
k = np.arange(binom.ppf(0.01, n, p), binom.ppf(0.99, n, p))
pmf_values = binom.pmf(k, n, p) # 使用seaborn绘制条形图
plt.figure(figsize=(10, 6))
sns.barplot(x=k, y=pmf_values, color="skyblue") # 设置标题和轴标签
plt.title(f'Binomial Distribution (n={n}, p={p})')
plt.xlabel('Number of Successes')
plt.ylabel('Probability') # 显示图形
plt.show()
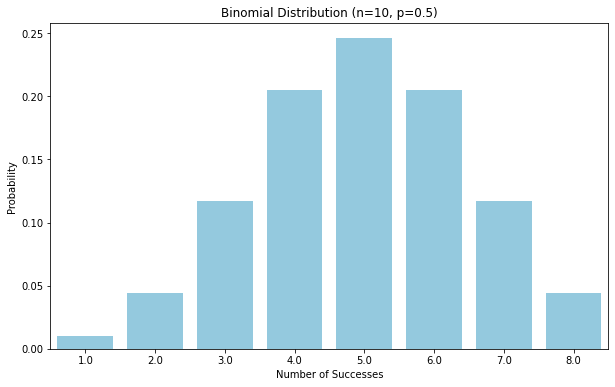
③泊松分布
泊松分布是一种描述单位时间(或空间)内随机事件发生的次数的离散概率分布。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import poisson # 设置泊松分布的参数
mu = 7 # 平均发生次数(泊松分布的λ参数) # 生成泊松分布的概率质量函数(PMF)的k值范围
k = np.arange(poisson.ppf(0.01, mu), poisson.ppf(0.99, mu)) # 计算对应k值的泊松分布概率
pmf_values = poisson.pmf(k, mu) # 使用seaborn绘制条形图
plt.figure(figsize=(10, 6))
sns.barplot(x=k, y=pmf_values, color="skyblue") # 设置标题和轴标签
plt.title(f'Poisson Distribution (λ={mu})')
plt.xlabel('Number of Events')
plt.ylabel('Probability') # 显示图形网格
plt.grid(True) # 显示图形
plt.show()
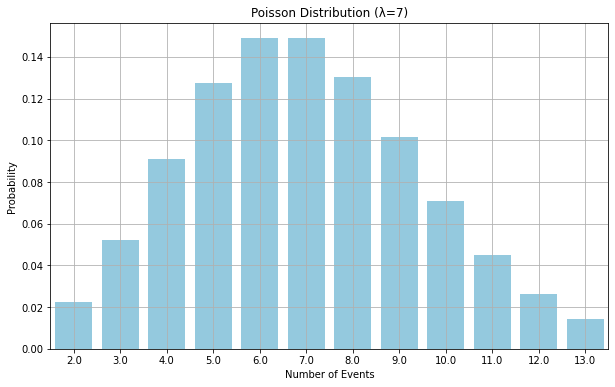
2、连续型分布
①均匀分布
在均匀分布中,所有可能的取值都具有相同的概率。例如,抛一个公平的六面骰子,每个数字出现的概率都是1/6。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 生成均匀分布的样本数据
a = 0 # 分布的下界
b = 10 # 分布的上界
n_samples = 1000 # 样本数量
uniform_samples = np.random.uniform(a, b, size=n_samples) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(uniform_samples, kde=True, bins=30, color="skyblue", alpha=0.7, label='Uniform Distribution') # 设置标题和轴标签
plt.title('Uniform Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()

②指数分布
指数分布是一种连续概率分布,描述了事件之间的时间间隔。例如,顾客到达商店的时间间隔。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 生成指数分布的样本数据
lambda_param = 0.5 # 指数分布的λ参数,控制分布的速率
n_samples = 1000 # 样本数量
exponential_samples = np.random.exponential(scale=1/lambda_param, size=n_samples) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(exponential_samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Exponential Distribution') # 设置标题和轴标签
plt.title('Exponential Distribution (λ={})'.format(lambda_param))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
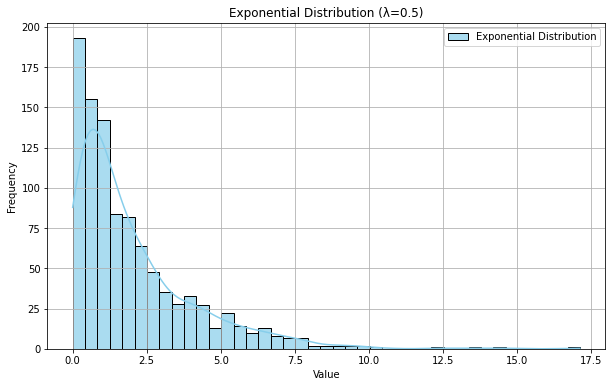
③正态分布/高斯分布
正态分布是一种连续概率分布,其概率密度函数曲线呈钟形,关于均值对称,是最常见的连续型概率分布。它描述了许多自然现象,例如人的身高或考试的分数。高斯分布由均值和标准差决定。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 生成正态分布的样本数据
mean = 0 # 正态分布的均值
std_dev = 1 # 正态分布的标准差
n_samples = 1000 # 样本数量
normal_samples = np.random.normal(mean, std_dev, size=n_samples) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(normal_samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Normal Distribution') # 设置标题和轴标签
plt.title('Normal/Gaussian Distribution (μ={}, σ={})'.format(mean, std_dev))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
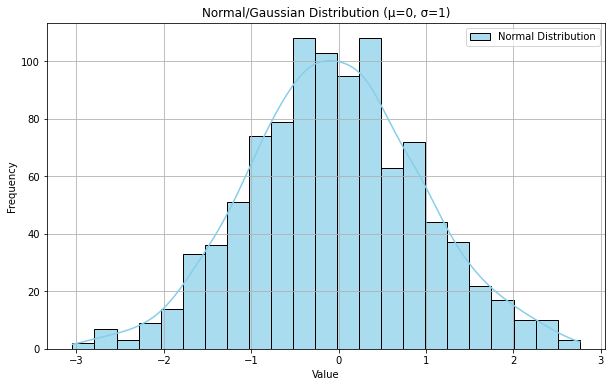
④对数正态分布
如果一个随机变量的对数服从正态分布,那么该变量服从对数正态分布。它常用于描述某些偏态分布的数据,如某些金融资产的收益。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 生成对数正态分布的样本数据
mu = 0 # 对数正态分布的均值(对数尺度)
sigma = 1 # 对数正态分布的标准差(对数尺度)
n_samples = 1000 # 样本数量
normal_samples = np.random.normal(mu, sigma, size=n_samples)
lognormal_samples = np.exp(normal_samples) # 对正态分布样本取指数得到对数正态分布样本 # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(lognormal_samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Log-normal Distribution') # 设置标题和轴标签
plt.title('Log-normal Distribution (μ={}, σ={})'.format(mu, sigma))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
⑥幂律分布
描述了事件发生的频率与其排名之间的关系,常用于描述社会网络、城市规模等现象。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 幂律分布的参数
xmin = 1 # 幂律分布的最小值
alpha = 2.5 # 幂律分布的指数参数(也称为形状参数) # 生成幂律分布的样本数据
def generate_powerlaw_samples(xmin, alpha, size): samples = [] while len(samples) < size: # 使用逆变换采样生成符合幂律分布的样本 u = np.random.rand(size) x = xmin * (1 - u) ** (-1 / alpha) # 过滤掉超出范围的样本 samples.extend(x[x > 0].tolist()) # 如果生成的样本足够,则退出循环 if len(samples) >= size: break return np.array(samples[:size]) n_samples = 100 # 样本数量
powerlaw_samples = generate_powerlaw_samples(xmin, alpha, n_samples) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(powerlaw_samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Power-law Distribution') # 设置标题和轴标签
plt.title('Power-law Distribution (xmin={}, α={})'.format(xmin, alpha))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
⑦帕累托分布
常用于描述社会、经济现象中的不平等性,如财富和收入的分布。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 帕累托分布的参数
xm = 1 # 最小尺度参数(也称为位置参数)
alpha = 1.5 # 形状参数(也称为形状指数) # 生成帕累托分布的样本数据
def generate_pareto_samples(xm, alpha, size): u = np.random.rand(size) samples = xm / (u ** (1 / alpha) - 1) return samples n_samples = 100 # 样本数量
pareto_samples = generate_pareto_samples(xm, alpha, n_samples) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(pareto_samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Pareto Distribution') # 设置标题和轴标签
plt.title('Pareto Distribution (xm={}, α={})'.format(xm, alpha))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
⑧韦伯分布
常用于描述设备的故障时间分布。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import weibull_min # 设置随机种子以获得可重复的结果
np.random.seed(0) # 韦伯分布的参数
c = 1 # 尺度参数
k = 2 # 形状参数 # 生成韦伯分布的样本数据
size = 1000 # 样本数量
samples = weibull_min.rvs(k, size=size, scale=c) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Weibull Distribution') # 设置标题和轴标签
plt.title('Weibull Distribution (c={}, k={})'.format(c, k))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()

3、特定应用分布
①卡方分布
卡方分布通常用于检验观测频率与期望频率之间的差异,或者检验一个或多个变量的独立性。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import chi2 # 设置随机种子以获得可重复的结果
np.random.seed(0) # 卡方分布的参数
df = 3 # 自由度 # 生成卡方分布的样本数据
size = 1000 # 样本数量
samples = chi2.rvs(df, size=size) # 使用seaborn的histplot绘制直方图
plt.figure(figsize=(10, 6))
sns.histplot(samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Chi-Squared Distribution') # 设置标题和轴标签
plt.title('Chi-Squared Distribution (df={})'.format(df))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
②学生T分布
T分布用于小样本统计推断,特别是当总体标准差未知时。T检验就是基于T分布的。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt # 设置随机种子以获得可重复的结果
np.random.seed(0) # 学生T分布的参数
df = 3 # 自由度 # 生成学生T分布的样本数据
size = 500 # 样本数量
samples = np.random.standard_t(df, size) # 创建一个图形和轴对象
plt.figure(figsize=(10, 6)) # 使用seaborn的histplot绘制直方图
sns.histplot(samples, kde=True, bins='auto', color="skyblue", alpha=0.7, label='Student\'s t-Distribution') # 设置标题和轴标签
plt.title('Student\'s t-Distribution (df={})'.format(df))
plt.xlabel('Value')
plt.ylabel('Frequency') # 显示图例
plt.legend() # 显示网格
plt.grid(True) # 显示图形
plt.show()
五、期望与方差
1、期望
期望,也称为均值,是随机变量所有可能取值的平均值。它反映了随机变量在大量重复试验中的平均水平。
一个抽奖活动,每次抽奖都有机会获得不同数量的奖金。如果抽奖次数足够多,你获得的平均奖金金额就是期望。比如,抽奖活动有50%的概率获得10元,50%的概率获得20元,那么期望就是(10元×50% + 20元×50%)= 15元。
2、方差
方差则是用来描述随机变量取值与其期望之间的偏离程度。方差越大,说明随机变量的取值越离散,波动越大;方差越小,说明取值越集中,波动越小。
一个射击游戏,玩家的目标是击中靶心。如果大部分玩家的射击结果都集中在靶心附近,那么射击结果的方差就很小,说明玩家的射击水平比较稳定。但如果射击结果分散在靶子的各个角落,甚至打到靶子外面,那么方差就很大,说明玩家的射击水平不够稳定。
3、结合
将期望和方差结合在一个案例中。假设你正在考虑投资两种不同的股票。股票A的期望收益率较高,但方差也很大,意味着它有可能带来高额回报,但同样存在较大的风险。而股票B的期望收益率较低,但方差较小,相对稳定。在做出投资决策时,你需要根据自己的风险承受能力和投资目标来权衡这两个因素。