书接上回
上次发了几张图,给了几个MySQL Explain的场景,链接在这儿:你是不是MySQL老司机?来看看这些explain结果你能解释吗?MySQL 夺命6连问
我们依次来分析下这6个问题。
在分析之前,我们先来了解一下MySQL中的排序。
MySQL 排序主要有以下几种方式:
- 文件排序(Filesort)
- 索引排序(Index Order)
文件排序(Filesort)
文件排序还是比较有歧义的。字面意思就是使用文件排序,但是实际又不是只使用文件,根据具体情况而定,也就是文件排序不一定涉及磁盘文件的读写。
在使用文件排序算法时,MySQL会先尝试是不是可以在排序缓冲区(Sort Buffer)中排序,如果内存放不下要排序的数据集,MySQL才会选择使用磁盘临时文件。
这里有两个关键点需要注意:
- 先尝试排序缓冲区(Sort Buffer)排序,缓冲区大小不够才使用文件
- 使用文件是使用临时文件
我们只是MySQL有一个配置是Sort_buffer_size,用来配置一个连接的排序缓冲区,MySQL在排序时使用这个缓冲区。
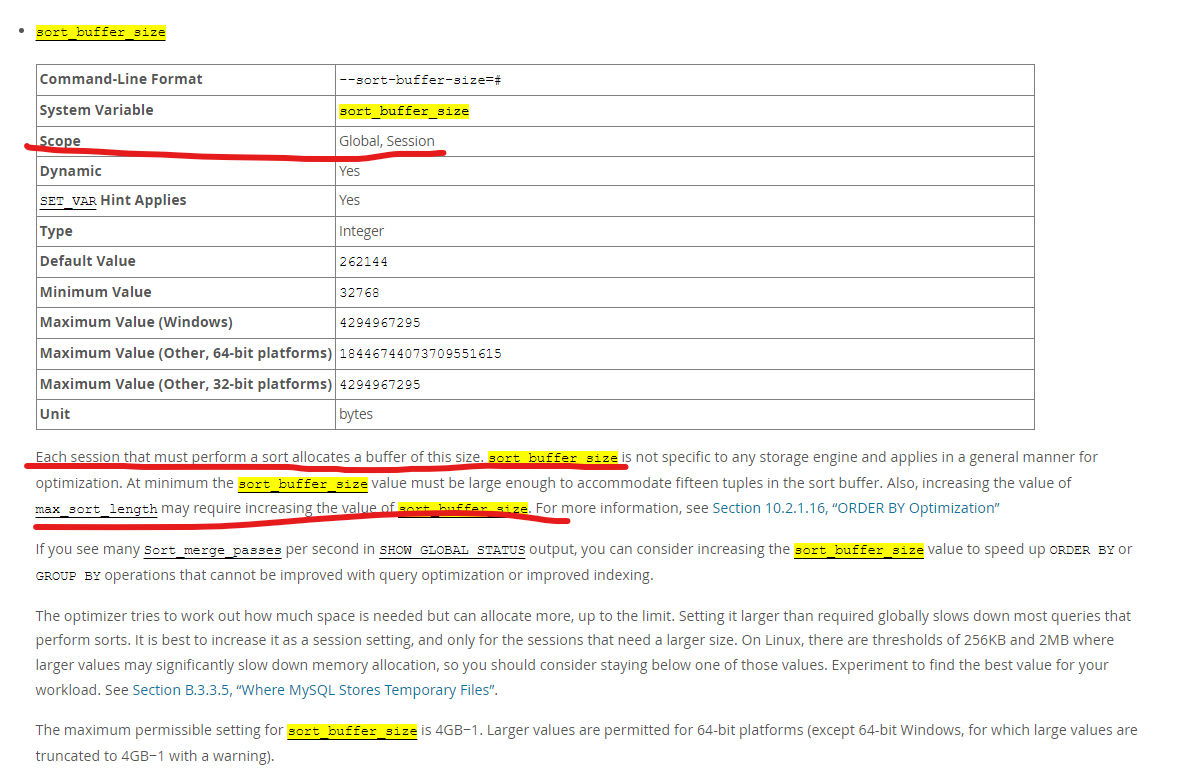
另外一点就是临时文件,我们要知道临时文件不一定涉及文件读写,因为临时文件可能是在内存中也可能是在硬盘上。这个需要你根据实际情况来决定使用硬盘还是内存。如果使用基于内存的临时文件系统,那么在Linux临时文件系统中,向临时文件写数据会先写入内存,如果内存空间不足那么才会将内存中的数据交换到磁盘。
看看kernel.org对临时文件系统的解释:
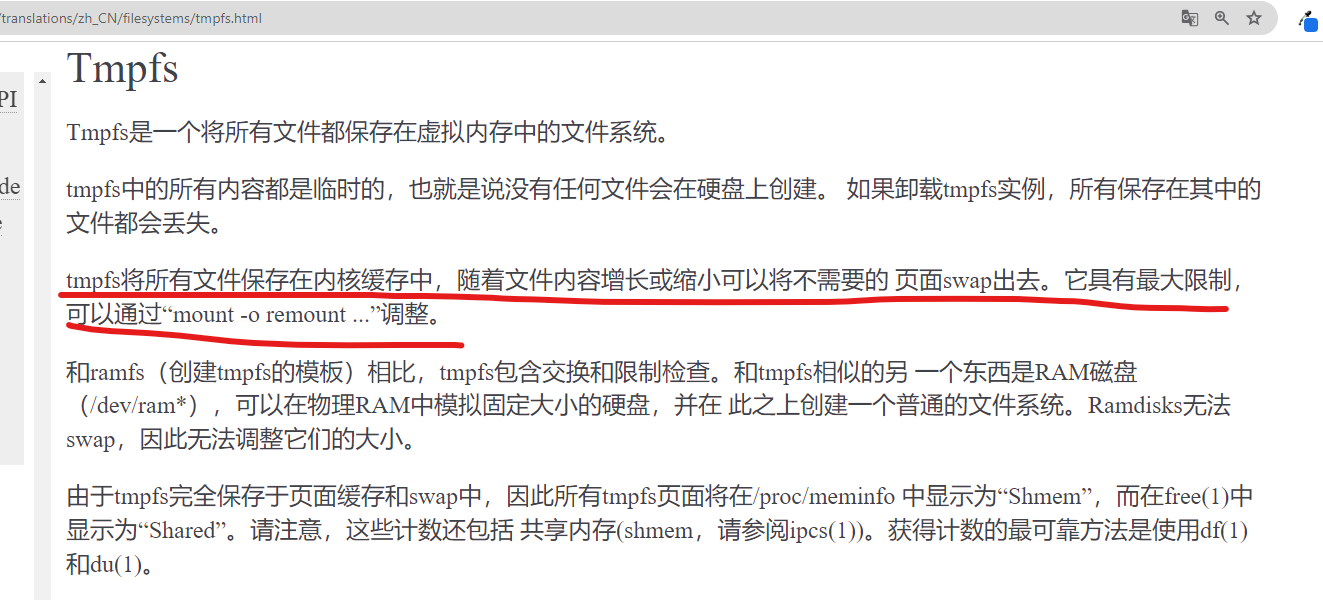
如果你使用硬盘的文件系统,比如:xfs,ext4等速度虽然不如tmpfs,但是更稳定。
怎么查询MySQL 临时文件配置
show variables like 'tmpdir'COPY
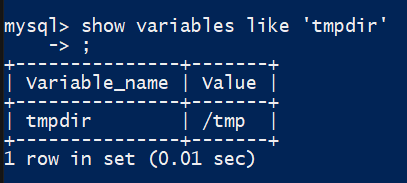
我们看到值是/tmp,然后在使用df -h /tmp来查看是什么文件系统:

总结思考
以上两点让我们可以做一些优化:
- 如果涉及排序,可以把sort_buffer_size设置大点
- 如果使用Tmpfs就把MySQL物理内存配置的大点
- 如果使用xfs/ext4就用高速SSD硬盘
文件排序流程
当然,以下是结构化的过程描述:
-
MySQL根据Where条件匹配行
-
然后在Sort Buffer中存一下排序所需要的列值(排序键值,行指针,以及查询所需的列)
-
Sort Buffer满的时候使用快速排序算法进行排序,然后将排序好的数据写入临时文件中,同时还得记录一下这个文件,一般是记录文件描述符,就是一个int值(在Linux系统中)
-
对上面的步骤循环,直到所有扫描完所有Where条件匹配到的行
-
到这儿的时候,MySQL可能已经得到了非常多的临时文件(MySQL中交Chunk)
-
然后使用归并排序并和到一个结果文件
-
然后读取这个文件返回结果集
那么在使用Filesort进行排序是,MySQL使用快速排序对Sort buffer中的数据进行排序,然后使用归并排序对临时文件进行排序。
快排:
归并排:

索引排序(Index Order)
索引排序就比较简单了,就是如果查询可以使用索引,那么MySQL就使用扫描索引进行排序。如果是正序Explain的Extra列会显示空,如果是倒叙那么Explain就显示backword index scan。
索引的组织结构就是B+树,天然有序。
Backward index scan是MySQL 8.0提供的优化特性。
几个例子
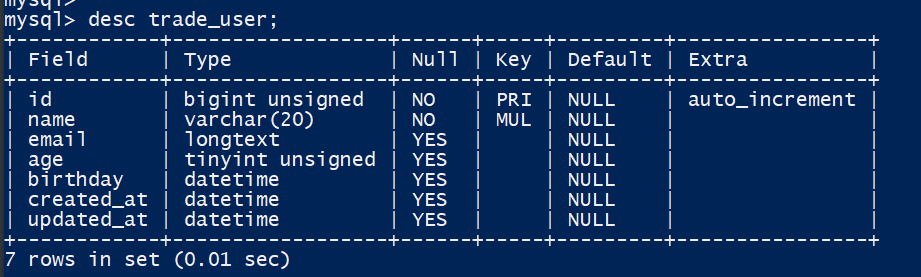
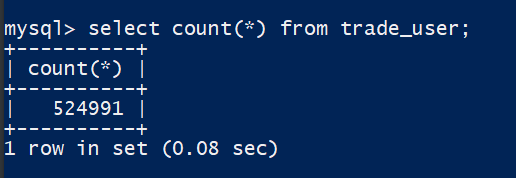
我们有一张trade_user表,表结构数据行数如下:
-
表结构
-
数据行
使用文件排序
我们现在来使用name字段进行排序,
explain select * from trade_user order by name asc limit 10;COPY
Type列为ALL,Extra列为Using filesort。
这表示对trade_order表进行全表扫描,排序使用文件排序算法。
explain结果如下:

使用索引排序
现在我们修改一下表结构,对name字段增加索引:
alter table trade_user add index idx_name (name);
show indexes from trade_user;COPY
我们可以看到idx_name索引是visible的,这是MySQL 8.0的新特性,索引是否对优化器可见。

我们来执行刚才的SQL:
explain select * from trade_user order by name asc limit 10;COPY
这次我们执行会看到: Type列为Index, Extra列为NULL。

这个就是使用了索引进行排序。
现在我们修改一下SQL,把asc修改为desc。
explain select * from trade_user order by name desc limit 10;COPY
我们看到输出和刚才的差别是:Extra列显示Backward index scan,这就是使用了MySQL 8.0的反向索引扫描

文件排序和索引排序的差别
文件排序
我们先把idx_name设置为不可见来分析下执行过程:
alter table trade_user alter index idx_name invisible;-- 这里我们添加一个analyze
explain analyze select * from trade_user order by name desc limit 10;COPY
输出如下:

我们可以在输出中看到:
Table scan on trade_user (cost=52799 rows=521335) (actual time=0.0305..236 rows=524991 loops=1)COPY
这个SQL需要进行全表扫描,开销很大,数据行越多,开销越大。
索引排序
我们先把idx_name设置为可见来分析下执行过程:
alter table trade_user alter index idx_name visible;-- 这里我们添加一个analyze
explain analyze select * from trade_user order by name desc limit 10;COPY
输出如下:
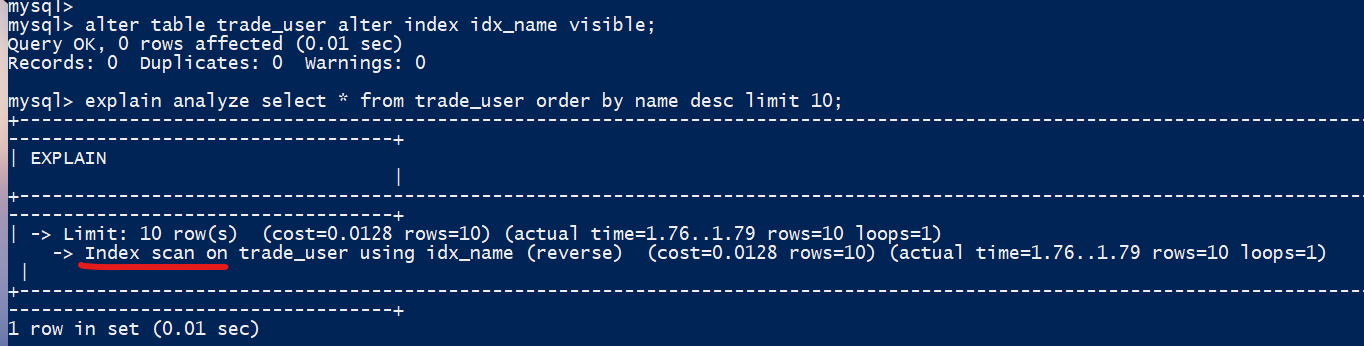
我们可以在输出中看到:
Index scan on trade_user using idx_name (reverse) (cost=0.0128 rows=10) (actual time=1.76..1.79 rows=10 loops=1)COPY
索引排序的开销就很小。
analyze怎么看
倒序看,我们看下我们刚才的两个输出怎么看:
-- 文件排序
3 -> Limit: 10 row(s) (cost=52799 rows=10) (actual time=281..281 rows=10 loops=1)
2 -> Sort row IDs: trade_user.`name` DESC, limit input to 10 row(s) per chunk (cost=52799 rows=521335) (actual time=281..281 rows=10 loops=1)
1 -> Table scan on trade_user (cost=52799 rows=521335) (actual time=0.0382..221 rows=524991 loops=1)-- 索引排序1 -> Limit: 10 row(s) (cost=0.0128 rows=10) (actual time=1.76..1.79 rows=10 loops=1)
2 -> Index scan on trade_user using idx_name (reverse) (cost=0.0128 rows=10) (actual time=1.76..1