文章目录
- 1)准备 Kubernetes 集群
- 2)安装 helm
- 3)配置 Helm chart
- 4)使用 Helm 部署 Kafka 集群
- 5)测试验证
- 6)更新集群
- 7)删除集群
部署 Raft Kafka(Kafka 3.3.1 及以上版本引入的 KRaft 模式)在 Kubernetes (k8s) 上,可以简化 Kafka 集群的管理,因为它不再依赖于 Zookeeper。
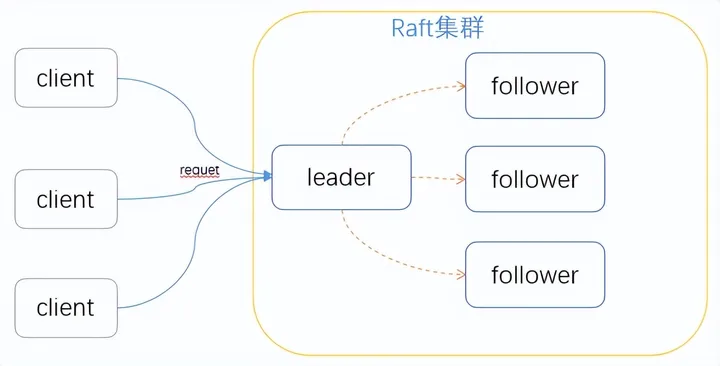
关于Raft Kafka 介绍和物理机部署可以参考我以下文章:
- 为何Kafka在2.8版本开始会“抛弃”Zookeeper?
- 深度解析 Raft 协议与KRaft实战演示
以下是部署 Raft Kafka 集群的基本步骤:
1)准备 Kubernetes 集群
确保你有一个运行中的 Kubernetes 集群,并且已经配置了 kubectl 命令行工具。
部署教程如下:
- 【云原生】k8s 离线部署讲解和实战操作
- 【云原生】k8s 环境快速部署(一小时以内部署完)
2)安装 helm
下载地址:https://github.com/helm/helm/releases
# 下载包
wget https://get.helm.sh/helm-v3.9.4-linux-amd64.tar.gz
# 解压压缩包
tar -xf helm-v3.9.4-linux-amd64.tar.gz
# 制作软连接
ln -s /opt/helm/linux-amd64/helm /usr/local/bin/helm
# 验证
helm version
helm help
3)配置 Helm chart
如果你使用 Bitnami 的 Kafka Helm chart,你需要创建一个 values.yaml 文件来配置 Kafka 集群。在该文件中,你可以启用 KRaft 模式并配置其他设置,如认证、端口等。
# 添加下载源
helm repo add bitnami https://charts.bitnami.com/bitnami
# 下载
helm pull bitnami/kafka --version 26.0.0
# 解压
tar -xf kafka-26.0.0.tgz# 修改配置
vi kafka/values.yaml
以下是一个 values.yaml 的示例配置:
image:registry: registry.cn-hangzhou.aliyuncs.comrepository: bigdata_cloudnative/kafkatag: 3.6.0-debian-11-r0listeners:client:containerPort: 9092# 默认是带鉴权的,SASL_PLAINTEXTprotocol: PLAINTEXTname: CLIENTsslClientAuth: ""controller:replicaCount: 3 # 控制器的数量persistence:storageClass: "kafka-controller-local-storage"size: "10Gi"# 目录需要提前在宿主机上创建local:- name: kafka-controller-0host: "local-168-182-110"path: "/opt/bigdata/servers/kraft/kafka-controller/data1"- name: kafka-controller-1host: "local-168-182-111"path: "/opt/bigdata/servers/kraft/kafka-controller/data1"- name: kafka-controller-2host: "local-168-182-112"path: "/opt/bigdata/servers/kraft/kafka-controller/data1"broker:replicaCount: 3 # 代理的数量persistence:storageClass: "kafka-broker-local-storage"size: "10Gi"# 目录需要提前在宿主机上创建local:- name: kafka-broker-0host: "local-168-182-110"path: "/opt/bigdata/servers/kraft/kafka-broker/data1"- name: kafka-broker-1host: "local-168-182-111"path: "/opt/bigdata/servers/kraft/kafka-broker/data1"- name: kafka-broker-2host: "local-168-182-112"path: "/opt/bigdata/servers/kraft/kafka-broker/data1"service:type: NodePortnodePorts:#NodePort 默认范围是 30000-32767client: "32181"tls: "32182"# Enable Prometheus to access ZooKeeper metrics endpoint
metrics:enabled: truekraft:enabled: true
添加以下几个文件:
- kafka/templates/broker/pv.yaml
{{- range .Values.broker.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:name: {{ .name }}labels:name: {{ .name }}
spec:storageClassName: {{ $.Values.broker.persistence.storageClass }}capacity:storage: {{ $.Values.broker.persistence.size }}accessModes:- ReadWriteOncelocal:path: {{ .path }}nodeAffinity:required:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- {{ .host }}
---
{{- end }}
- kafka/templates/broker/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:name: {{ .Values.broker.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
- kafka/templates/controller-eligible/pv.yaml
{{- range .Values.controller.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:name: {{ .name }}labels:name: {{ .name }}
spec:storageClassName: {{ $.Values.controller.persistence.storageClass }}capacity:storage: {{ $.Values.controller.persistence.size }}accessModes:- ReadWriteOncelocal:path: {{ .path }}nodeAffinity:required:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- {{ .host }}
---
{{- end }}
- kafka/templates/controller-eligible/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:name: {{ .Values.controller.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
4)使用 Helm 部署 Kafka 集群
# 先准备好镜像
docker pull docker.io/bitnami/kafka:3.6.0-debian-11-r0
docker tag docker.io/bitnami/kafka:3.6.0-debian-11-r0 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.6.0-debian-11-r0
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.6.0-debian-11-r0# 开始安装
helm install kraft ./kafka -n kraft --create-namespace
NOTES
[root@local-168-182-110 KRaft-on-k8s]# helm upgrade kraft
Release "kraft" has been upgraded. Happy Helming!
NAME: kraft
LAST DEPLOYED: Sun Mar 24 20:05:04 2024
NAMESPACE: kraft
STATUS: deployed
REVISION: 3
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 26.0.0
APP VERSION: 3.6.0** Please be patient while the chart is being deployed **Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:kraft-kafka.kraft.svc.cluster.localEach Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:kraft-kafka-controller-0.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092kraft-kafka-controller-1.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092kraft-kafka-controller-2.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092kraft-kafka-broker-0.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092kraft-kafka-broker-1.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092kraft-kafka-broker-2.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092To create a pod that you can use as a Kafka client run the following commands:kubectl run kraft-kafka-client --restart='Never' --image registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.6.0-debian-11-r0 --namespace kraft --command -- sleep infinitykubectl exec --tty -i kraft-kafka-client --namespace kraft -- bashPRODUCER:kafka-console-producer.sh \--broker-list kraft-kafka-controller-0.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092,kraft-kafka-controller-1.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092,kraft-kafka-controller-2.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092,kraft-kafka-broker-0.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092,kraft-kafka-broker-1.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092,kraft-kafka-broker-2.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092 \--topic testCONSUMER:kafka-console-consumer.sh \--bootstrap-server kraft-kafka.kraft.svc.cluster.local:9092 \--topic test \--from-beginning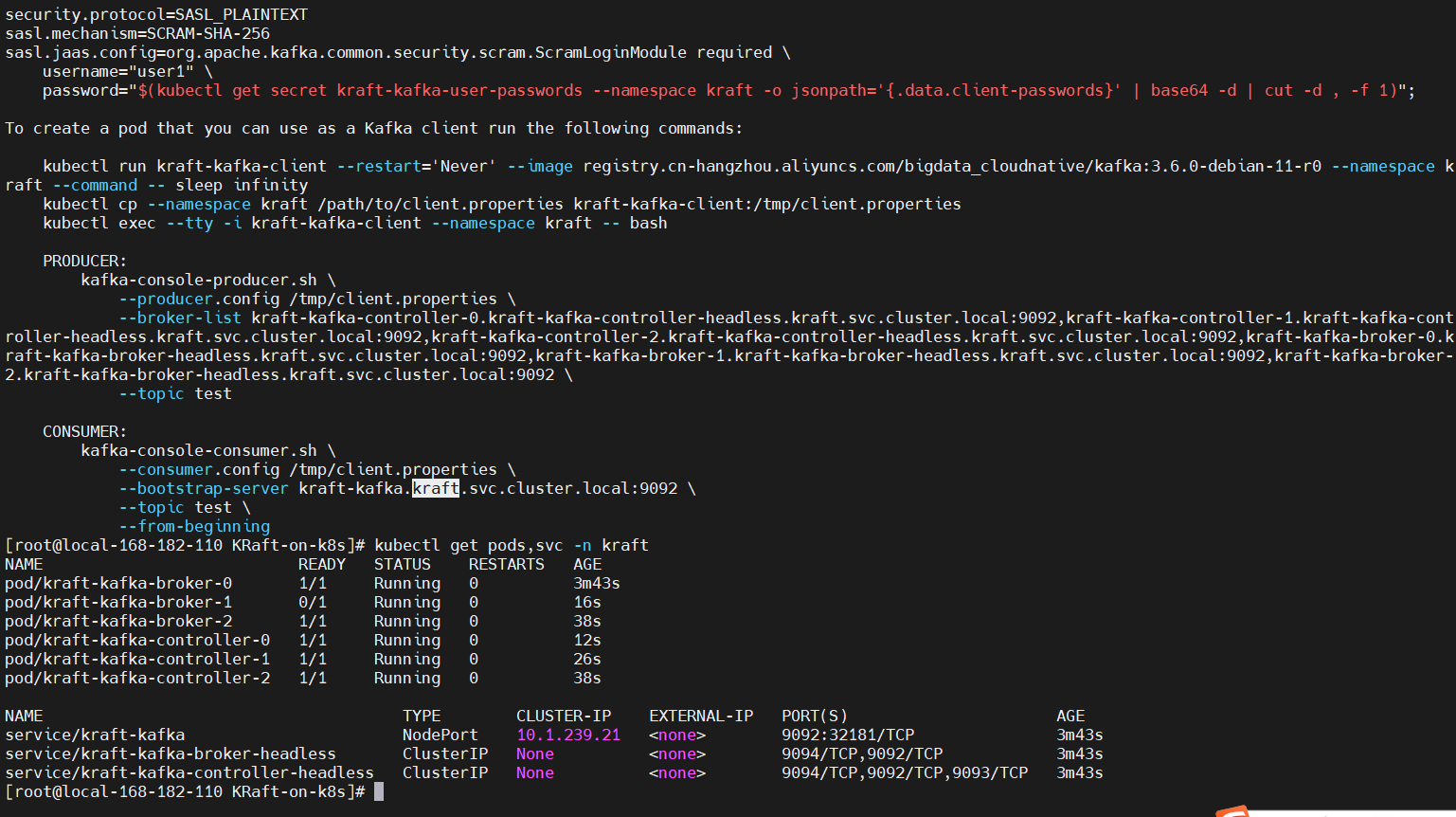
5)测试验证
# 创建客户端
kubectl run kraft-kafka-client --restart='Never' --image registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.6.0-debian-11-r0 --namespace kraft --command -- sleep infinity
创建客户端
kafka-topics.sh --create --topic test --bootstrap-server kraft-kafka-controller-0.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092 --partitions 3 --replication-factor 2# 查看详情
kafka-topics.sh --describe --bootstrap-server kraft-kafka-controller-0.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092 --topic test# 删除topic
kafka-topics.sh --delete --topic test --bootstrap-server kraft-kafka-controller-0.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092
生产者和消费者
# 生产者
kafka-console-producer.sh \--broker-list kraft-kafka-controller-0.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092,kraft-kafka-controller-1.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092,kraft-kafka-controller-2.kraft-kafka-controller-headless.kraft.svc.cluster.local:9092,kraft-kafka-broker-0.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092,kraft-kafka-broker-1.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092,kraft-kafka-broker-2.kraft-kafka-broker-headless.kraft.svc.cluster.local:9092 \--topic test# 消费者
kafka-console-consumer.sh \--bootstrap-server kraft-kafka.kraft.svc.cluster.local:9092 \--topic test \--from-beginning
6)更新集群
helm upgrade kraft ./kafka -n kraft
7)删除集群
helm uninstall kraft -n kraft
Raft Kafka on k8s 部署实战操作就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~