目录
前言:
思想与原理:
随机森林分类效果与什么因素有关:
经典的随机森林算法:
一、构建经典随机森林算法
1、思路
2、步骤:
3、代码实现
二、随机森林算法应用
建模步骤
Python代码实现(完整代码):
三、总结
随机森林算法总结:
优点:
缺点:
算法提升方向:
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言:
随机森林(Random Forest)是由Leo Breiman和Adele Cutler于2001年提出的一种集成学习方法,首次在其论文《Random Forests》中发表,用于解决分类和回归问题。它是一种决策树的集成方法,通过构建多棵决策树并进行集成,来提高预测性能和稳定性。
思想与原理:
随机森林的核心思想是通过构建多棵决策树,并将它们集成在一起,来提高整体模型的性能和鲁棒性。其基本原理如下:
-
随机选择样本: 在训练每棵决策树时,从训练集中随机抽取一部分样本(有放回抽样),用于构建决策树的训练集。这样可以增加模型的多样性,并减少过拟合的风险。
-
随机选择特征: 在训练每棵决策树时,从所有特征中随机选择一部分特征,用于构建决策树的节点。这样可以增加决策树之间的差异性,提高集成模型的性能。
-
集成预测: 对于分类问题,随机森林中的每棵决策树都会对样本进行分类,最终通过投票或取平均值的方式来确定最终的预测结果;对于回归问题,每棵决策树会对样本进行预测,最终通过取平均值的方式来确定最终的预测结果。
随机抽取样本和特征 -> | -> 对于每棵决策树: -> 随机选择一部分样本(有放回抽样) ->| | 开始 -> 集成预测 -> 对于分类问题: -> 对每棵决策树进行预测 -> 通过投票确定最终的预测结果 -> 结束| || -> 对于回归问题: -> 对每棵决策树进行预测 -> 取平均值确定最终的预测结果 -> 结束|| -> 随机选择一部分特征 ->
随机森林算法的随机性思想和集成学习的思想使得它在实践中表现出色,具有很高的预测性能和抗过拟合能力。由于其简单、灵活且易于实现,随机森林成为了机器学习领域中应用广泛的算法之
随机森林分类效果与什么因素有关:
-
树的数量(n_estimators): 随机森林中包含的决策树数量对分类效果有显著影响。通常情况下,随着树的数量增加,随机森林的分类效果会更好,因为集成了更多的决策树,减少了过拟合的风险。但是,增加树的数量也会增加计算成本,因此需要在效果和效率之间进行权衡。
-
每棵树的最大深度(max_depth): 决策树的最大深度控制了树的复杂度,即树能够学习的规则的复杂程度。较深的树可以更好地捕获数据中的复杂关系,但也更容易过拟合。因此,适当限制每棵树的最大深度可以提高随机森林的泛化能力,减少过拟合的风险。
通过调节这两个因素,可以优化随机森林的分类效果,以达到最佳的预测性能。
经典的随机森林算法:
-
Breiman's Random Forests: 这是Leo Breiman于2001年提出的最初版本的随机森林算法。它使用了随机抽样和随机选择特征的思想,并使用基尼系数或信息增益来选择最优划分特征。
-
Classification and Regression Trees (CART): CART是一种经典的决策树算法,可以用于构建随机森林。它使用基于基尼系数的方法来选择最优划分特征,并采用贪婪算法进行树的构建。
-
Extremely Randomized Trees (Extra-Trees): Extra-Trees是一种与传统随机森林略有不同的集成学习算法。它在每个节点上随机选择特征,并随机确定划分点,而不是使用基尼系数或信息增益来选择最优划分特征。
-
Isolation Forests: Isolation Forests是一种基于随机森林的异常检测算法。它使用了随机森林的思想,并通过随机选择特征和随机抽样样本来构建多棵决策树,然后利用树的高度来评估样本的异常程度。
这些经典的随机森林算法在原理和实现上略有不同,但都基于随机性的思想,并采用了多棵决策树的集成策略,以提高模型的泛化能力和鲁棒性。
一、构建经典随机森林算法
1、思路
对于每棵决策树:
- 随机抽样训练集,生成子数据集。
- 随机选择一部分特征。
- 使用子数据集和选定特征训练一棵决策树。
集成预测:
- 对于分类问题,对每棵决策树进行预测,并通过投票确定最终预测结果。
- 对于回归问题,对每棵决策树进行预测,并取平均值确定最终预测结果。
2、步骤:
对于每棵决策树:
- 随机抽样训练集,生成子数据集。
- 随机选择一部分特征。
- 使用子数据集和选定特征训练一棵决策树。
对于每个样本:
- 对每棵决策树进行预测。
- 对于分类问题,通过投票确定最终预测结果;
- 对于回归问题,取平均值确定最终预测结果。
3、代码实现
通过Python代码实现的随机森林算法,包括了构建随机森林和进行预测的过程。在构建随机森林时,对训练数据进行随机抽样并随机选择一部分特征,然后使用这些数据训练一棵决策树;在进行预测时,对每个样本使用所有决策树进行预测,并通过投票决定最终的预测结果。
from sklearn.tree import DecisionTreeClassifier
import numpy as np# 构建随机森林
def RandomForest(X_train, y_train, n_estimators, max_features=None, max_depth=None):forest = []n_samples = X_train.shape[0] # 训练集样本数量if max_features is None:max_features = int(np.sqrt(X_train.shape[1])) # 默认选择特征数量为特征总数的平方根for i in range(n_estimators):# 随机抽样生成子数据集sample_indices = np.random.choice(n_samples, n_samples, replace=True)# 随机选择特征feature_indices = np.random.choice(X_train.shape[1], max_features, replace=False)# 根据选定的样本和特征训练一棵决策树X_subset = X_train[sample_indices][:, feature_indices]y_subset = y_train[sample_indices]tree = DecisionTreeClassifier(max_depth=max_depth)tree.fit(X_subset, y_subset)# 将训练好的决策树和使用的特征索引保存到森林中forest.append((tree, feature_indices))return forest# 随机森林预测
def RandomForestPredict(X_test, forest):predictions = []for sample in X_test:tree_predictions = []# 对每棵决策树进行预测for tree, feature_indices in forest:# 根据决策树使用的特征索引获取样本对应的特征X_subset = sample[feature_indices].reshape(1, -1)# 对样本进行预测prediction = tree.predict(X_subset)tree_predictions.append(prediction)# 投票决定最终的预测结果final_prediction = np.argmax(np.bincount(tree_predictions))predictions.append(final_prediction)return predictions
二、随机森林算法应用
基于随机森林算法实现对乳腺癌数据集进行分类。数据集包含了乳腺肿瘤样本的特征,以及它们是良性还是恶性的分类标签。我们可以使用随机森林模型来预测一个肿瘤是良性还是恶性。
建模步骤
-
准备数据集: 加载乳腺癌数据集和空气质量数据集,并进行必要的数据预处理。
-
数据预处理: 包括数据清洗、特征选择、特征缩放、数据编码等。
-
构建随机森林模型: 使用乳腺癌数据集构建一个复杂的随机森林分类器。
-
模型评估: 在测试集上评估模型的性能,包括准确率、精确率、召回率、F1值等指标。
-
可视化结果: 使用Matplotlib展示数据处理结果,如特征重要性、模型预测结果等。
Python代码实现(完整代码):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler# 加载乳腺癌数据集
cancer = load_breast_cancer()
X = pd.DataFrame(cancer.data, columns=cancer.feature_names)
y = cancer.target# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 构建随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 模型评估
accuracy = accuracy_score(y_test, y_pred)
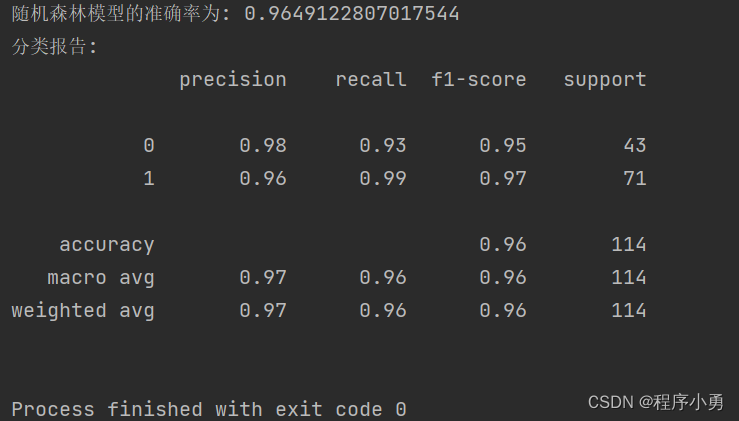
print("随机森林模型的准确率为:", accuracy)
print("分类报告:")
print(classification_report(y_test, y_pred))# 可视化特征重要性
feature_importances = rf_model.feature_importances_
sorted_indices = np.argsort(feature_importances)[::-1]
sorted_features = X.columns[sorted_indices]
plt.figure(figsize=(20, 12))
plt.barh(sorted_features, feature_importances[sorted_indices])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Feature Importance of Random Forest Classifier')
plt.show()
执行结果:精确率96%

可视化数据特征图
三、总结
随机森林算法总结:
随机森林(Random Forest)是一种集成学习方法,通过构建多个决策树并集成它们的预测结果来进行分类或回归。随机森林具有以下特点:
-
集成学习方法: 随机森林通过构建多个决策树并结合它们的预测结果来降低模型的方差,提高模型的泛化能力。
-
随机性: 随机森林引入了随机抽样样本和随机选择特征的机制,使得每棵决策树都具有差异性,提高了模型的多样性。
-
适用性广泛: 随机森林适用于分类和回归问题,对于大型数据集和高维特征具有良好的适应性。
优点:
-
准确性高: 随机森林通常具有很高的准确性,能够在处理各种类型的数据集时获得良好的性能。
-
抗过拟合: 由于随机森林采用了多棵决策树的集成策略,并引入了随机性,因此具有较强的抗过拟合能力。
-
对特征重要性的评估: 随机森林可以通过特征重要性来评估每个特征对预测的贡献程度,提供了有用的特征选择信息。
-
处理高维数据: 随机森林可以处理高维数据和大规模数据集,且不需要进行特征降维或特征选择。
缺点:
-
计算资源消耗较大: 随机森林中包含多棵决策树,因此在训练和预测过程中可能需要较多的计算资源。
-
模型可解释性较差: 随机森林是一种黑盒模型,难以解释每个决策树的具体逻辑,对于模型的解释性较差。
-
参数调节不直观: 虽然随机森林不需要过多的调参工作,但是调节一些参数如树的数量、树的深度等并不是非常直观。
算法提升方向:
-
集成策略改进: 引入更多的随机性或者尝试其他集成方法来提高模型性能。
-
特征工程优化: 提取更有价值的特征,改善模型的预测能力。
-
模型解释性提升: 改进随机森林模型的解释性,使得模型的预测结果更容易理解和解释。
-
并行化处理: 探索并行化处理的方法来加速模型的训练过程。
-
模型调优: 对模型参数进行调优,以进一步提高模型的性能和泛化能力。
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟


![[leetcode]06拿硬币](https://img-blog.csdnimg.cn/img_convert/5873fa23bfda9622a92921bb244418cd.png)