文章目录
- 论文地址
- 主要内容
- 主要贡献
- 模型图
- 技术细节
- 实验结果
论文地址
PeriodicLoRA: Breaking the Low-Rank Bottleneck in LoRA Optimization
主要内容
这篇文章的主要内容是介绍了一种名为PeriodicLoRA(PLoRA)的参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方法,旨在解决大型语言模型(Large Language Models,LLMs)微调过程中的低秩瓶颈问题。文章首先讨论了大型语言模型在自然语言处理任务中的应用越来越广泛,但全参数微调这些模型需要大量的计算资源。为了解决这一问题,研究者们开发了参数高效微调方法,其中LoRA(Low-Rank Adaptation)是最广泛使用的方法之一。LoRA通过优化低秩矩阵来减少微调过程中的内存使用,但与全参数微调相比,其性能仍有差距。
为了克服这一限制,文章提出了PLoRA方法,该方法通过多次累积低秩更新矩阵来实现更高的更新秩。PLoRA包含多个训练阶段,在每个阶段结束时,将LoRA权重卸载到主干参数中,然后重新初始化LoRA状态。实验结果表明,PLoRA具有更强的学习能力,最多可达LoRA学习能力的1.8倍,而且不会增加内存使用。此外,文章还介绍了一种基于动量的卸载策略,以减轻PLoRA训练过程中的不稳定性。
文章还讨论了相关工作,包括监督微调、参数高效微调、LoRA及其变体,并详细介绍了PLoRA方法的实现细节。此外,文章还提供了实验设置、数据集、实验结果和讨论,以及PLoRA方法的局限性和未来研究方向。最后,文章总结了PLoRA的贡献,并提供了参考文献列表。
主要贡献
文章的主要贡献可以总结为以下几点:
-
提出PLoRA方法:文章引入了PeriodicLoRA(PLoRA),这是一种新的参数高效微调(PEFT)方法,旨在突破LoRA微调中的低秩瓶颈。PLoRA通过在多个训练阶段中累积低秩更新矩阵来实现更高的更新秩,从而提高模型的学习能力。
-
实验验证:文章通过在不同PEFT设置下对LLaMA 7B模型进行指令微调,并在多主题多选题、数学推理以及语言理解和推理任务上评估性能,证明了PLoRA相比于相同秩的LoRA具有更好的性能,并且没有引入额外的内存开销。
-
深入分析:文章对PLoRA的训练过程进行了详细的分析,揭示了PLoRA相比于原始LoRA具有更强的学习能力。特别是,在不同任务中应用PLoRA后学习能力的提升。
-
公开调优结果:文章公开了在调整超参数方面的完整结果,为选择适当的PLoRA设置提供了参考。
-
方法的简化和效率:与现有的LoRA变体相比,PLoRA方法更为简单和高效,它通过周期性地卸载和重新初始化LoRA状态来实现高秩更新,而不是通过增加模型复杂性或内存开销。
这些贡献表明,PLoRA是一个有前景的方法,可以在保持参数效率的同时提高大型语言模型在特定任务上的性能,尤其是在资源受限的情况下。此外,文章的实验结果和分析为未来的研究提供了有价值的见解和方向。
模型图
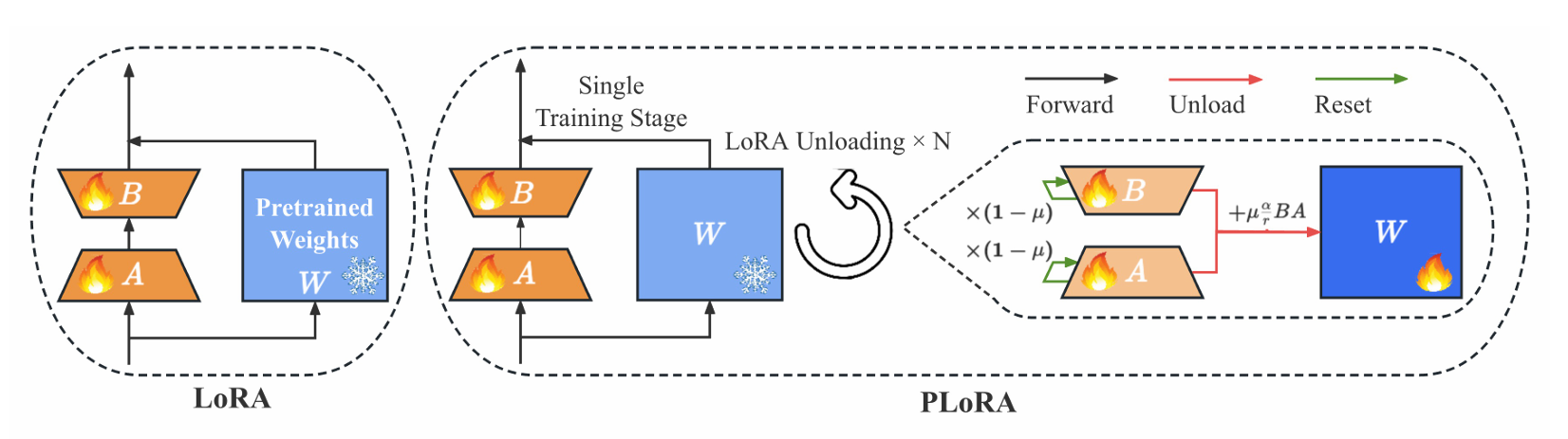
在LoRA训练中,只有矩阵A和B被更新,而模型权重被冻结(用蓝色表示)。然后,在完成所有训练之后,使用训练后的矩阵A和B来更新模型权重。
而在PLoRA方法中,在每次小批量训练之后,在继续训练之前,转移LoRA中矩阵A和B的权重以更新模型权重并重置它们自己。此循环在一个历元内重复N次。在图中,浅橙色表示小批量的学习能力,而橙色表示截至当前的累积学习能力。
PLoRA就是在训练过程中练一个小的LoRA然后加到预训练模型权重后面,然后LoRA重置,接着练,一个训练过程可以得到好多个LoRA矩阵,练好一个加一个,直到训练过程结束。
技术细节
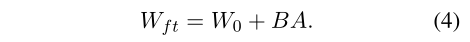
首先LoRA就是一次训练过程中,只训练A、B两个低秩矩阵,W预训练参数冻结。
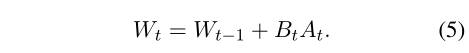
简单来说,PLoRA就是一次训练过程中,逐渐训练多个A、B矩阵,训练好一组就把他们加到预训练模型参数中,冻结,然后重新初始化一组A、B,继续只训练A、B,过了两个epoch觉得差不多就再加到W冻结,再开一组A、B,因此,一次训练过程可以得到多组A、B
(人多力量大了)
因此:
PLoRA方法的得到的预训练模型的参数:
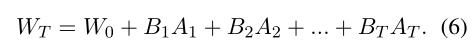
例如一次训练过程,搞出了T组A、B,其实相当于有个T个秩为r的矩阵来学习了。
然后有选择地更新LoRA,将BA乘积按(1−m)缩放,将A和B矩阵按m缩放。这种方法解决了由于数据集可变性而导致的小批量损失不一致的问题。
可以看一段伪代码加深理解:
import torch
import torch.nn as nn
from torch.optim import AdamW# 假设我们有一个预训练的Transformer模型
class TransformerModel(nn.Module):# ... Transformer模型的定义 ...def forward(self, x):# ... 前向传播的实现 ...return x# 初始化模型和优化器
model = TransformerModel()
optimizer = AdamW(model.parameters(), lr=1e-4)# 初始化LoRA的权重矩阵A和B
rank = 10 # 假设我们选择的秩为10
A = torch.randn(model_dim, rank) # 随机初始化A
B = torch.zeros(model_dim, rank) # 初始化B为零# 训练循环
num_stages = 5 # 假设我们有5个训练阶段
for stage in range(num_stages):# 在每个阶段,我们只更新A和Bfor data, target in train_loader:optimizer.zero_grad()# 假设我们有一个函数来应用LoRA权重更新updated_weights = apply_lora_weights(model, A, B)# 执行前向传播和损失计算output = model(data)loss = loss_fn(output, target)# 反向传播和参数更新loss.backward()optimizer.step()# 阶段结束时,将更新的权重应用到模型的主干参数上apply_updated_weights_to_model(model, updated_weights)# 重置A和B为初始状态A = torch.randn(model_dim, rank)B = torch.zeros(model_dim, rank)# 应用LoRA权重更新的函数
def apply_lora_weights(model, A, B):# 这里应该是将LoRA的权重更新应用到模型的特定层上# 具体实现取决于模型的结构和LoRA的实现细节pass# 将更新的权重应用到模型的函数
def apply_updated_weights_to_model(model, updated_weights):# 这里应该是将累积的LoRA权重更新应用到模型的主干参数上# 具体实现取决于模型的结构和LoRA的实现细节pass# 假设的损失函数和数据加载器
loss_fn = nn.CrossEntropyLoss()
train_loader = ... # 你的数据加载器# 开始训练
train(model, loss_fn, optimizer, num_epochs)
实验结果
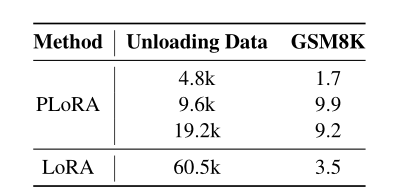
基于经验证据,文章将4.8k数据设置为训练期间PLoRA的卸载点。
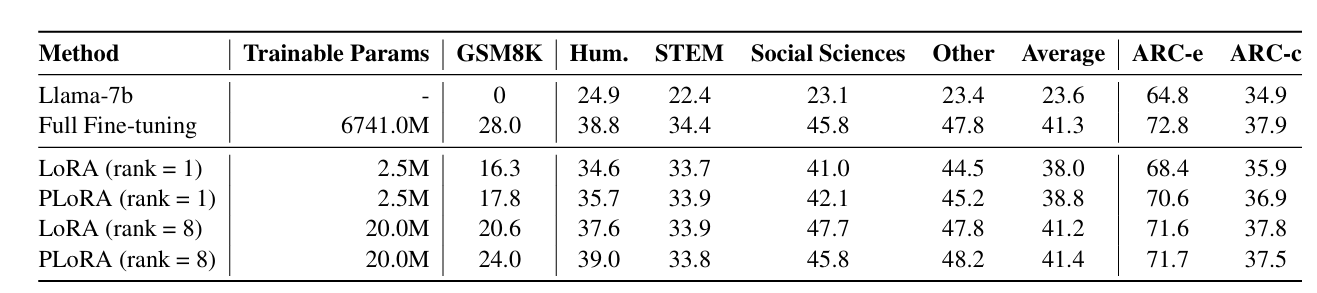
PLoRA在复杂任务的表现更好
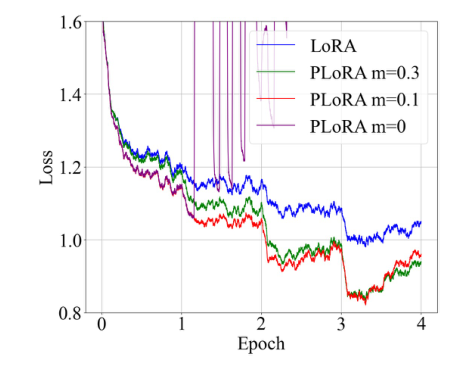
调整缩放参数的影响
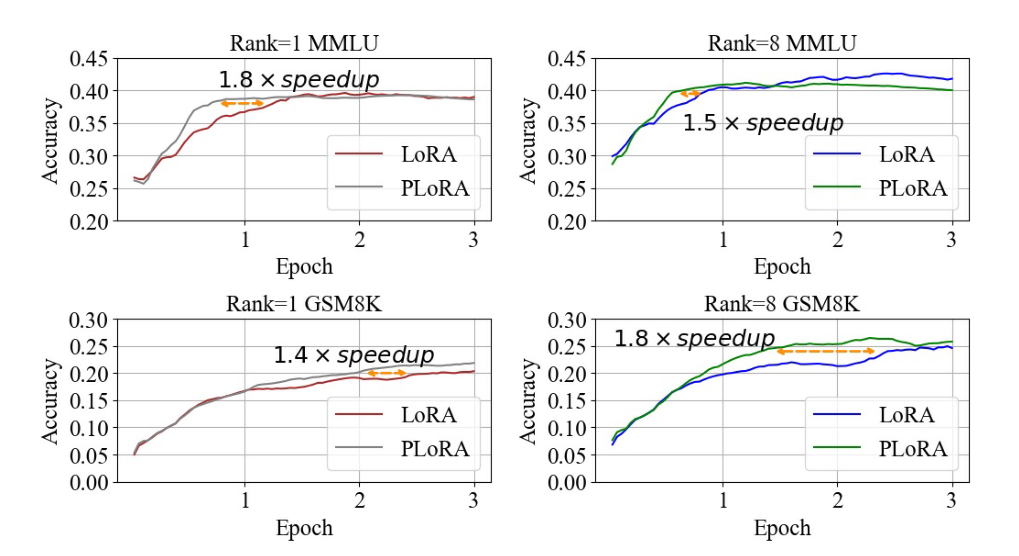
PLoRA在复杂任务上收敛更快
还有一些实验结果,先这样


![[Qt学习笔记]Qt实现自定义控件SwitchButton开关按钮](https://img-blog.csdnimg.cn/direct/d19e813ce8d64486a793ff429d1e8210.png#pic_center)