IO概述
回想之前写过的程序,数据都是在内存中,一旦程序运行结束,这些数据都没有了,等下次再想使用这些数据,可是已经没有了。那怎么办呢?能不能把运算完的数据都保存下来,下次程序启动的时候,再把这些数据读出来继续使用呢?其实要把数据持久化存储,就需要把内存中的数据存储到内存以外的其他持久化设备(硬盘、光盘、U盘等)上。
- 当需要把内存中的数据存储到持久化设备上这个动作称为输出(写)Output操作。
- 当把持久设备上的数据读取到内存中的这个动作称为输入(读)Input操作。
因此我们把这种输入和输出动作称为IO操作。
File类
静态成员变量
import java.io.File;/*** java.io.File* 将操作系统中的 文件(file)、目录(directory)、路径(path) 封装成File对线* File对线提供方法对其操作,File与系统无关*/
public class FileDemo {public static void main(String[] args) {//File类 静态成员变量 与系统有关的路径分隔符 Windows的是分号,Linux的是冒号String pathSeparator = File.pathSeparator;System.out.println(pathSeparator);//File类 静态成员变量 与系统有关的默认名称分隔符 Windows的'\',Linux的是'/'String separator = File.separator;System.out.println(separator);}
}
构造函数
File文件和目录路径名的抽象表示形式。Java中把文件或者目录都封装成File对象。也就是说如果我们要去操作硬盘上的文件,或者文件夹只要找到File这个类即可。

路径分为绝对路径和相对路径:
- 绝对路径:在系统中具有唯一性
- /Users/kim/Desktop
- 相对路径:表示路径之间的相对关系
- 父目录(唯一性):/Users/kim
- 子目录(可多个):Desktop
import java.io.File;/*** java.io.File* 将操作系统中的 文件(file)、目录(directory)、路径(path) 封装成File对线* File对线提供方法对其操作,File与系统无关*/
public class FileDemo {public static void main(String[] args) {//File(String pathname) 传递路径名,可以是文件,也可以是目录File file1 = new File("/Users/kim/Desktop");System.out.println(file1);//File(String parent, String child) 传递父路径和子路径File file2 = new File("/Users/kim", "Desktop");System.out.println(file2);//File(File parent, String child) 传递封装成File对象的父路径 和 子路径File file3 = new File(file1, "java_io_study_banner.png");System.out.println(file3);//File(String url) 传递互联网路径地址File file4 = new File("\\samba.if010.com");System.out.println(file4);}
}
常用方法
创建完了File对象之后,那么File类中都有如下常用方法,可以获取文件相关信息


创建文件、目录方法
import java.io.File;
import java.io.IOException;/*** java.io.File* 创建功能(文件、目录)*/
public class FileDemo {public static void main(String[] args) throws IOException {//boolean mkdir(); 创建的目录名称是由File构造方法传递路径时指定boolean mkdirResult = new File("./Test").mkdir();if (mkdirResult) {System.out.println("【目录】创建成功, 开始创建【文件】");//boolean createNewFile(); 创建的文件名称是由File构造方法传递路径时指定boolean createNewFileResult = new File("./Test/test.txt").createNewFile();if (createNewFileResult){System.out.println("【文件】创建成功");} else {System.out.println("【文件】创建失败");}} else {System.out.println("【目录】 创建失败");}//boolean mkdirs(); 递归创建目录,创建的目录名称是由File构造方法传递路径时指定new File("./Test/a/b/c/d").mkdirs();}
}
删除文件、目录方法
import java.io.File;
import java.io.IOException;/*** java.io.File* 删除功能(文件、目录)*/
public class FileDemo {public static void main(String[] args) throws IOException {//boolean delete(); 删除的文件、目录在构造函数中指定//注意:该方法不走回收站,直接走硬盘删除(删除需谨慎)//注意:目录下如果有文件或者子目录,是无法删除该目录的boolean deleteFileResult = new File("./Test/test.txt").delete();boolean deleteDirResult = new File("./Test/a/b/c/d").delete();System.out.println(deleteFileResult);System.out.println(deleteDirResult);}
}
获取文件、目录方法
import java.io.File;
import java.io.IOException;/*** java.io.File* 获取功能(文件、目录)*/
public class FileDemo {public static void main(String[] args) throws IOException {File file = new File("upload/1689303023614.jpg");//String getName(); 返回路径中表示的文件或者目录名称(路径中的最后部分)String fileName = file.getName();System.out.println(fileName);//long length(); 返回路径中表示文件的字节数long fileSize = file.length();System.out.println(fileSize);//String getAbsolutePath(); 返回字符串类型的 绝对路径String absolutePath = file.getAbsolutePath();System.out.println(absolutePath);//File getAbsoluteFile(); 返回File对象类型的 绝对路径File absoluteFile = file.getAbsoluteFile();System.out.println(absoluteFile);//String getParent(); 返回字符串类型的 父目录名称,如果没有父目录,则返回nullString parent = file.getParent();System.out.println(parent);//File getParentFile(); 返回File对象类型的 父目录名称,如果没有父目录,则返回nullFile parentFile = file.getParentFile();System.out.println(parentFile);}
}
判断文件、目录方法
import java.io.File;
import java.io.IOException;/*** java.io.File* 判断功能(文件、目录)*/
public class FileDemo {public static void main(String[] args) throws IOException {File file = new File("upload/1689303023614.jpg");//boolean exists() 判断File对线封装的路径是否存在boolean result1 = file.exists();System.out.println(result1);//boolean isFile() 判断File对线封装的是否是文件boolean result2 = file.isFile();System.out.println(result2);//boolean isDirectory() 判断File对线封装的是否是目录boolean result3 = file.isDirectory();System.out.println(result3);}
}
list获取方法

import java.io.File;
import java.io.IOException;/*** java.io.File* 遍历功能(文件、目录)*/
public class FileDemo {public static void main(String[] args) throws IOException {File file = new File("upload");//String[] list() 获取File对象封装的路径中文件和目录名称String[] lss = file.list();for (String name : lss){System.out.println(name);}//File[] listFiles() 获取File对象封装的路径中文件和目录名称File[] lsf = file.listFiles();for (File name : lsf){System.out.println(name);}}
}
**注意:**在获取指定目录下的文件或者文件夹时必须满足下面两个条件
- 指定的目录必须是存在的
- 指定的必须是目录。否则容易引发返回数组为null,出现NullPointerException
文件过滤器
通过listFiles()方法,我们可以获取到一个目录下的所有文件和文件夹,但能不能对其进行过滤呢?比如我们只想要一个目录下的指定扩展名的文件,或者包含某些关键字的文件夹呢?
我们是可以先把一个目录下的所有文件和文件夹获取到,并遍历当前获取到所有内容,遍历过程中在进行筛选,但是这个动作有点麻烦,Java给我们提供相应的功能来解决这个问题。
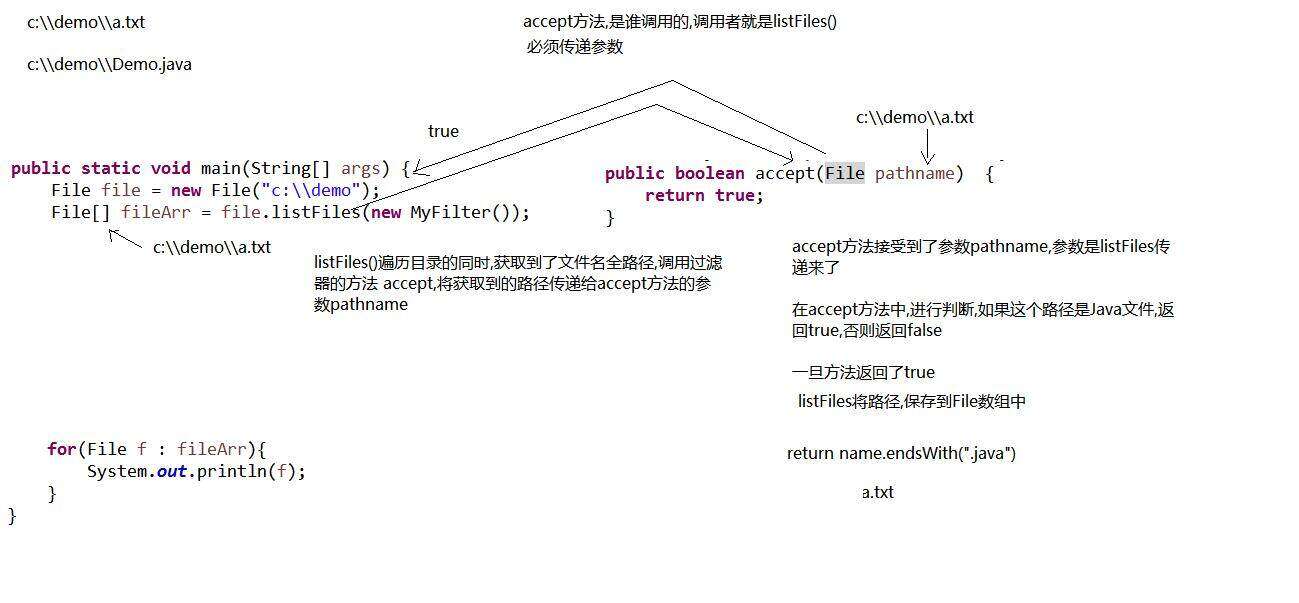
查阅File类的API,在查阅时发现File类中重载的listFiles方法,并且接受指定的过滤器。


FileFilter 过滤器中的accept方法接受一个参数,这个参数就当前文件或文件夹对象
当我们需要过滤文件名称时就可以使用FilenameFilter这个过滤器,当我们想对当前文件或文件夹进行过滤,就可以使用FileFilter ,比如需要当前目录下的所有文件夹,就可以使用FileFilter 过滤器。
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;/*** java.io.File* 文件获取过滤器* 遍历目录时,可以根据需要,只获取满足条件的文件或目录* 遍历目录的方法listFile() 以重载形式* listFile(FileFilter filter)传递FileFilter接口的实现类* 自定义FileFilter接口的实现类,重写accept方法*/
public class FileDemo {public static void main(String[] args) throws IOException {File file = new File("upload");File[] fName = file.listFiles(new MyFilter());for (File name : fName){System.out.println(name);}}
}/*** 自定义过滤器,实现FileFilter接口,重写方法accept*/
class MyFilter implements FileFilter {/*** 对 pathname 进行判断,如果文件是jpg则返回true,反之false* @param pathname The abstract pathname to be tested* @return*/@Overridepublic boolean accept(File pathname) {String name = pathname.getName();return name.endsWith(".jpg");}
}
分析一下代码的流程:
递归遍历目录
递归,指在当前方法内调用自己的这种现象
public void method(){System.out.println(“递归的演示”);//在当前方法内调用自己method();
}
递归分为两种,直接递归和间接递归。
- 直接递归称为方法自身调用自己
- 间接递归可以A方法调用B方法,B方法调用C方法,C方法调用A方法
import java.io.File;/*** 对一个目录下的所有内容进行遍历输出*/
public class FileDemo {public static void main(String[] args) {File dir = new File("Test");getAllDir(dir);}/*** 定义方法,实现目录遍历*/public static void getAllDir(File dir){//调用方法listFile对目录进行遍历File[] dirArr = dir.listFiles();for (File f : dirArr){System.out.println(f);//判断f是否是目录,如果是这再调用自己进行遍历if (f.isDirectory()){getAllDir(f);}}}
}
注意:递归一定要有条件限定,保证递归能够停止下来,否则会发生栈内存溢出。在递归中虽然有限定条件,但是递归次数不能太多。否则也会发生栈内存溢出。
文件搜索功能实现:
import java.io.File;
import java.io.FileFilter;
import java.util.ArrayList;
import java.util.List;/*** 遍历目录,获取目录下的指定格式文件* 1、遍历多级目录,使用递归方法实现* 2、遍历的过程中,使用过滤器筛选文件*/
public class FileDemo {public static void main(String[] args) {//创建File对象File file = new File("/Users/kim/Documents/Code/TestJava/TestJava/Test");//创建ArrayList对象,便于存储搜索结果List<File> searchResult = new ArrayList<File>();//调用搜索方法getSearchResult(file,"3410",searchResult);//打印输出结果for (File f : searchResult){System.out.println(f);}}/*** 按照传入的文件名进行搜索的方法,递归遍历实现* @param file File类型 传入要进行搜索的File对象* @param findname String类型 传入要匹配的文件或目录名称* @param result ArrayList类型 传入用于存放结果的数组*/public static void getSearchResult(File file, String findname, List<File> result){//调用File对象方法listFiles()获取,并将过滤器传入File[] searchDir = file.listFiles(new MyFilter(findname));for (File f : searchDir){//判断f对象是否是目录,如果不是这直接添加到用于存放结果的数组,反之在进行判断检索if (f.isDirectory()){//判断该目录是否匹配要检索的名称//如果匹配则加入用于存放结果的数组,并再次调用自己检索自己目录下是否也有匹配的文件或文件名//反之,不匹配,这直接调用自己检索自己目录下是否也有匹配的文件或文件名if (f.getName().toLowerCase().contains(findname)) {result.add(f);getSearchResult(f, findname, result);} else {getSearchResult(f, findname, result);}} else {result.add(f);}}}
}/*** 自定义过滤器,实现FileFilter接口功能*/
class MyFilter implements FileFilter {private String findname;public MyFilter(String findname) {this.findname = findname;}@Overridepublic boolean accept(File pathname) {if (pathname.isDirectory()) {return true;} else {return pathname.getName().toLowerCase().contains(findname);}}
}
字节流
输出流 OutputStream
OutputStream此抽象类,是表示输出字节流的所有类的超类。操作的数据都是字节,定义了输出字节流的基本共性功能方法。

FileOutputStream类
OutputStream有很多子类,其中子类FileOutputStream可用来写入数据到文件。FileOutputStream类,即文件输出流,是用于将数据写入File的输出流。


import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;/*** 字节输出流* java.io.OutputStream 所有字节输出流的超类* 作用:从Java程序,写文件* 字节:这样流每次只操作文件中的一个字节** 方法:* write(int b) 写入一个字节* write(byte[] b) 写入字节数组* write(byte[] b, int off, int len) 写入字节数组,第一个int是开始字节位置,第二个int是指定个数* close() 关闭资源,释放与次流相关资源** FileOutputStream是OutputStream的子类* 写入数据文件,学习父类方法* 构造方法* File 封装文件* String 字符串文件名** 流对象使用步骤* 1、创建流子类对象,绑定数据目的* 2、调用流对象方法write()* 3、关闭资源** 注意:流对象的构造方法,可以创建文件,如果文件存在,直接覆盖*/
public class OutputStreamDemo {public static void main(String[] args) throws IOException {FileOutputStream fos = new FileOutputStream("/Users/kim/Documents/Code/TestJava/TestJava/Test/test.txt");//写字节fos.write('a');//写字节数组byte[] bytes = {97,98,99,100,101};fos.write(bytes);//写指定指引部分fos.write(bytes,1,2);//写字符串的简便方式fos.write("\t 你好".getBytes());//上面的FileOutputStream构造方法会直接覆盖文件,所以慎用//给文件续写和换行的构造方法// FileOutputStream(File file, boolean append)// FileOutputStream(String name, boolean append)File file = new File("/Users/kim/Documents/Code/TestJava/TestJava/Test/test.txt");FileOutputStream fos2 = new FileOutputStream(file, true);// \r\n 是换行的意思,可以写在上一行的末尾,也可以卸载下一行的开头fos2.write("aaa\r\nzz".getBytes());fos.close();}
}
输入流InputStream
InputStream此抽象类,是表示字节输入流的所有类的超类。定义了字节输入流的基本共性功能方法。

- int read():读取一个字节并返回,没有字节返回-1
- int read(byte[]):读取一定量的字节数,并存储到字节数组中,返回读取到的字节数
FileInputStream类
InputStream有很多子类,其中子类FileInputStream可用来读取文件内容。FileInputStream 从文件系统中的某个文件中获得输入字节。


import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;/*** 字节输入流* java.io.InputStream 所有字节输入流的超类* 作用:读取任意文件,每次只读取一个字节* 方法:read方法* int read() 读取一个字节* int read(byte[] byte) 读取一定量的字节数存储到字节数组中** FileInputStream是InputStream的子类* 构造方法* File 封装文件* String 字符串文件名** 使用步骤* 1、创建字节输入流对象* 2、调用read方法读取* 执行一次,就会自动读取下一个字节,且返回是字节的int值* 如果到达了末尾,则会返回-1* 为了提高效率,传入数组进行读取会比较好* 3、关闭资源*/
public class InputStreamDemo {public static void main(String[] args) throws IOException {File file = new File("/Users/kim/Documents/Code/TestJava/TestJava/Test/test.txt");FileInputStream fis = new FileInputStream(file);int i = fis.read();System.out.println(i);//循环方式读取文件全部内容int len = 0;while ( len != -1 ){len = fis.read();System.out.print((char)len);}//通过字节数组读取全部内容byte[] bytes = new byte[1024];int len = 0;while ( (len = fis.read(bytes)) != -1 ) {System.out.print(new String(bytes, 0, len));}fis.close();}
}
关于IO的异常处理
在实际开发中,对IO的异常一般都是用try....catch....
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;/*** IO的异常处理* try catch finally** 注意:* 1、保证流对象的作用于范围足够* 2、catch里面打印异常便于处理问题* 3、注意流对象创建失败后的关闭资源是否需要*/
public class OutputStreamDemo {public static void main(String[] args){File file = new File("/Users/kim/Documents/Code/TestJava/TestJava/Test/test.txt");FileOutputStream fos = null;//try的外面声明变量,里面建立对象try {fos = new FileOutputStream(file);fos.write('a');} catch (IOException e) {System.out.println(e.getMessage());} finally {//一定要判断fos是否为null,只有不为null时,才可以关闭资源if (fos != null) {try {fos.close();} catch (IOException e) {System.out.println(e.getMessage());}}}}
}
案例:文件复制
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;/*** 字节流复制文件* 采用数组缓冲提升复制效率,FileInputStream 读取字节数组,FileOutputStream 写入字节数组*/
public class CopyDemo {public static void main(String[] args) {//创建File对象,绑定拷贝目标和拷贝目的File copyTarget = new File("./Test/1689303812029.jpg");File copyDestination = new File("./Test/1689303812029_backup.jpg");//定义流对象变量FileInputStream fis = null;FileOutputStream fos = null;try {//创建输入、输出流对象,绑定拷贝目标和拷贝目的fis = new FileInputStream(copyTarget);fos = new FileOutputStream(copyDestination);//通过字节数组读取全部内容byte[] text = new byte[1024];int len = 0;while ( (len=fis.read(text)) != -1 ){//通过字节数组写入全部内容fos.write(text,0, len);}} catch (IOException e){System.out.println("[Error] Copy error");} finally {if (fis != null){try {fis.close();} catch (IOException e){System.out.println("[Error] source close error");}}if (fos != null){try {fos.close();} catch (IOException e){System.out.println("[Error] source close error");}}}}
}
字符编码表
我们知道计算机底层数据存储的都是二进制数据,而我们生活中的各种各样的数据,如何才能和计算机中存储的二进制数据对应起来呢?
这时老美他们就把每一个字符和一个整数对应起来,就形成了一张编码表,老美他们的编码表就是ASCII表。其中就是各种英文字符对应的编码。
编码表:其实就是生活中字符和计算机二进制的对应关系表。
- ascii: 一个字节中的7位就可以表示。对应的字节都是正数。0-xxxxxxx
- iso-8859-1:拉丁码表 latin,用了一个字节用的8位。1-xxxxxxx 负数
- GB2312:简体中文码表。包含6000-7000中文和符号。用两个字节表示。两个字节第一个字节是负数,第二个字节可能是正数
- GBK:目前最常用的中文码表,2万的中文和符号。用两个字节表示,其中的一部分文字,第一个字节开头是1,第二字节开头是0
- GB18030:最新的中文码表,目前还没有正式使用
- unicode:国际标准码表:无论是什么文字,都用两个字节存储。
- Java中的char类型用的就是这个码表。char c = ‘a’;占两个字节
- Java中的字符串是按照系统默认码表来解析的。简体中文版 字符串默认的码表是GBK
- UTF-8:基于unicode,一个字节就可以存储数据,不要用两个字节存储,而且这个码表更加的标准化,在每一个字节头加入了编码信息(后期到api中查找)
能识别中文的码表:GBK、UTF-8;正因为识别中文码表不唯一,涉及到了编码解码问题,对于我们开发而言;常见的编码 GBK UTF-8 ISO-8859-1。
文字—>(数字):这叫编码 byte[] “abc”.getBytes()
(数字)—>文字:这叫解码 new String(byte[] bytes)
字符流
输出流Writer
查阅API,发现有一个Writer类,Writer是写入字符流的抽象类。其中描述了相应的写的动作。

FileWriter类
查阅FileOutputStream的API,发现FileOutputStream用于写入诸如图像数据之类的原始字节的流。要写入字符流,请考虑使用 FileWriter。打开FileWriter的API介绍。用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。

import java.io.FileWriter;
import java.io.IOException;/*** 字符输出流* java.io.Writer 所有字符输出流的超类* 写文件,写文本文件** 方法:* write(int c) 写入一个字符* write(char[] cbuf) 写入字符数组* writr(char[] cbuf, int off, int len) 写入字节数组部分,开始位和长度* write(String str) 写入字符串** Write类的子类对象FileWrite* 构造方法* File File对象* String 文件名** 注意:字符输出流写入数据的时候要执行flush刷新方法*/
public class FileWriterDemo {public static void main(String[] args) throws IOException {FileWriter fw = new FileWriter("./Test/test.txt");//写入字符fw.write('a');//写入字符数组char[] chars = {'a','b','c','d','e'};fw.write(chars);//写入字符数组部分内容fw.write(chars, 0, 3);//写入字符串fw.write("\nHello World");fw.flush();fw.close();}
}
输入流Reader
我们读取拥有中文的文件时,使用的字节流在读取,那么我们读取到的都是一个一个字节。只要把这些字节去查阅对应的编码表,就能够得到与之对应的字符。API中是否给我们已经提供了读取相应字符的功能流对象,Reader,读取字符流的抽象超类。

- read():读取单个字符并返回
- read(char[]):将数据读取到数组中,并返回读取的个数
FileReader类
查阅FileInputStream的API,发现FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。打开FileReader的API介绍。用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。

import java.io.FileReader;
import java.io.IOException;/*** 字符输出流,读取文本文件* (注意:只能读取文本文件)* java.io.Reader 所有字符输入流的超类** 方法* int read() 读取一个字符* int read(char[] c) 读取字符数组** FileReader是Reader的子类* 构造方法* File File对象* String 文件名*/
public class FileReaderDemo {public static void main(String[] args) throws IOException {FileReader fw = new FileReader("./Test/test.txt");//读取一个字符的方式读取文本文件int len = 0;while ( (len = fw.read()) != -1 ){System.out.print((char)len);}//读取字符数组的方式读取文本文件char[] chars = new char[1024];int len2 = 0;while ( (len2 = fw.read(chars)) != -1 ){System.out.print(new String(chars,0,len2));}fw.close();}
}
flush()和close()的区别
- flush():将流中的缓冲区缓冲的数据刷新到目的地中,刷新后,流还可以继续使用
- close():关闭资源,但在关闭前会将缓冲区中的数据先刷新到目的地,否则丢失数据,然后在关闭流。流不可以使用。如果写入数据多,一定要一边写一边刷新,最后一次可以不刷新,由close完成刷新并关闭
转换流
字符流(FileReader、FileWriter),其中说如果需要指定编码和缓冲区大小时,可以在字节流的基础上,构造一个InputStreamReader或者OutputStreamWriter
OutputStreamWriter类
查阅OutputStreamWriter的API介绍,OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的字符编码表,将要写入流中的字符编码成字节。它的作用的就是,将字符串按照指定的编码表转成字节,在使用字节流将这些字节写出去。

import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;/*** 转换流* java.io.OutputStreamWriter 继承 Writer类* 字符输出流,写文本文件,可以将字节流转成字符流** 构造方法* OutputStreamWriter(OutputStream out)* OutputStream:传入字节输出流,OutputStream是抽象类,所以要出入子类FileOutputStream* OutputStreamWriter(OutputStream out, String charsetName)* OutputStream:传入字节输出流,OutputStream是抽象类,所以要出入子类FileOutputStream* String:传入编码表的名字(GBK、UTF-8)*/
public class OutputStreamWriterDemo {public static void main(String[] args) throws IOException {//创建字节输出流,绑定文件名FileOutputStream fos = new FileOutputStream("./Test/utf.txt");//创建转换流对象,传入字节输出流和指定的编码表名称OutputStreamWriter osw = new OutputStreamWriter(fos,"utf-8");//转换流写入字符串osw.write("Hello World!");//OutputStreamWriter属字符输出流,所以记得flush一下osw.flush();osw.close();}
}
OutputStreamWriter流对象,它到底如何把字符转成字节输出的呢?
其实在OutputStreamWriter流中维护自己的缓冲区,当我们调用OutputStreamWriter对象的write方法时,会拿着字符到指定的码表中进行查询,把查到的字符编码值转成字节数存放到OutputStreamWriter缓冲区中。然后再调用刷新功能,或者关闭流,或者缓冲区存满后会把缓冲区中的字节数据使用字节流写到指定的文件中。
InputStreamReader类
查阅InputStreamReader的API介绍,InputStreamReader 是字节流通向字符流的桥梁:它使用指定的字符编码表读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。

import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;/*** 转换流* java.io.InputStreamReader 继承 Reader类* 字符输入流,读取文本文件,可以将字节流转成字符流** 构造方法* InputStreamReader(InputStream in)* InputStream:传入字节输出流,InputStream是抽象类,所以要出入子类FileInputStream* InputStreamReader(InputStream in, String charsetName)* InputStream:传入字节输出流,InputStream是抽象类,所以要出入子类FileInputStream* String:传入编码表的名字(GBK、UTF-8)*/
public class InputStreamReaderDemo {public static void main(String[] args) throws IOException {//创建字节输入流,绑定文件FileInputStream fis = new FileInputStream("./Test/utf.txt");//创建转换流读取字节输入流对象,并指定使用utf-8编码表InputStreamReader isr = new InputStreamReader(fis,"utf-8");int len = 0;char[] chars = new char[1024];while ( (len = isr.read(chars)) != -1 ){System.out.print(new String(chars,0,len));}}
}
注意:在读取指定的编码的文件时,一定要指定编码格式,否则就会发生解码错误,而发生乱码现象
转换流和子类区别
发现有如下继承关系:
- OutputStreamWriter
- FileWriter
- InputStreamReader
- FileReader
父类和子类的功能有什么区别呢?
OutputStreamWriter和InputStreamReader是字符和字节的桥梁:也可以称之为字符转换流。字符转换流原理:字节流+编码表。
FileWriter和FileReader:作为子类,仅作为操作字符文件的便捷类存在。当操作的字符文件,使用的是默认编码表时可以不用父类,而直接用子类就完成操作了,简化了代码。
//默认字符集。
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt")); //指定GBK字符集。
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"),"GBK"); FileReader fr = new FileReader("a.txt");
这三句代码的功能是一样的,其中第三句最为便捷,但是一旦要指定其他编码时,绝对不能用子类,必须使用字符转换流,具备以下条件可以使用:
- 操作的是文件
- 使用默认编码
总结:
字节—>字符 : 看不懂的—>看的懂的。 需要读。输入流。 InputStreamReader
字符—>字节 : 看的懂的—>看不懂的。 需要写。输出流。 OutputStreamWriter
缓冲流
读取文件中数据的操作,读取数据量大的文件时,读取的速度会很慢,很影响我们程序的效率,Java中提高了一套缓冲流,它的存在,可提高IO流的读写速度,缓冲流,根据流的分类分类字节缓冲流与字符缓冲流。
字节缓冲流
字节缓冲流根据流的方向,共有2个
- 写入数据到流中,字节缓冲输出流 BufferedOutputStream
- 读取流中的数据,字节缓冲输入流 BufferedInputStream
它们的内部都包含了一个缓冲区,通过缓冲区读写,就可以提高了IO流的读写速度
BufferedOutputStream输出流
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;/*** 字节输出流的缓冲流* java.io.BufferedOutputStream* 提高原有输出流的写入效率* BufferedOutputStream 继承 OutputStream* 方法:write() 字节、字节数组** 构造方法* BufferedOutputStream(OutputStream out)* 传递任意字节输出流,传递的是哪个字节流就对那个字节流提高效率*/
public class BufferedOutputStreamDemo {public static void main(String[] args) throws IOException {//创建字节输出流对象,绑定对应文件FileOutputStream fos = new FileOutputStream("./Test/test.txt");//创建字节输出缓冲流对象,构造方法中传递字节输出流对象BufferedOutputStream bos = new BufferedOutputStream(fos);//写入字节bos.write('q');//写入字节数组byte[] bytes = "Hello".getBytes();bos.write(bytes);bos.close();fos.close();}
}
BufferedInputStream输入流
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;/*** 字节输入流的缓冲流* java.io.BufferedInputStream* 提高原有输入流的写入效率* BufferedInputStream 继承 InputStream* 方法:read() 字节、字节数组** 构造方法* BufferedInputStream(InputStream out)* 传递任意字节输入流,传递的是哪个字节流就对那个字节流提高效率*/
public class BufferedInputStreamDemo {public static void main(String[] args) throws IOException {FileInputStream fis = new FileInputStream("./Test/test.txt");BufferedInputStream bis = new BufferedInputStream(fis);int len = 0;byte[] bytes = new byte[1024];while ( (len = bis.read(bytes)) != -1 ){System.out.print(new String(bytes,0,len));}fis.close();bis.close();}
}
字符缓冲流
- 字符缓冲输入流 BufferedReader
- 字符缓冲输出流 BufferedWriter
BufferedWriter输出流
import java.io.*;/*** 字符缓冲输出流* java.io.BufferedWriter 继承 Writer* 方法:write() 字符、字符数组、字符串* 特有方法:newLine() 作用:文本中换行,具有与平台无关性** 构造方法:* BufferedWriter(Writer w) 传递任意字符输出流*/
public class BufferedWriterDemo {public static void main(String[] args) throws IOException {//创建字符流对象,绑定文件FileWriter fw =new FileWriter("./Test/test.txt");BufferedWriter bw = new BufferedWriter(fw);bw.write("Hello");bw.newLine();bw.write("World");bw.flush();bw.close();}
}
BufferedReader输入流
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;/*** 字符缓冲输入流* java.io.BufferedReader 继承 Reader* 功能:read() 字符、字符数组* 特有功能:* String readLine() 读取文本行* 返回值 String 类型,如果读取到末尾则返回null* 这里要注意 String s = null; 和 String s = "null"; 的区别** 构造方法* BufferedReader(Reader r) 传入任意的字符输入流对象*/
public class BufferedReaderDemo {public static void main(String[] args) throws IOException {FileReader fr = new FileReader("./Test/test.txt");BufferedReader br = new BufferedReader(fr);String text = "";while ( (text = br.readLine()) != null ) {System.out.println(text);}br.close();}
}
四种文件复制方式的效率比较
方式1: 采用基本的流,一次一个字节的方式复制 共耗时 12352 毫秒
方式2: 采用基本的流,一个多个字节的方式赋值 共耗时 4 毫秒
方式3: 采用高效的流,一次一个字节的方式复制 共耗时 99 毫秒
方式4: 采用高效的流,一个多个字节的方式赋值 共耗时 4 毫秒
import java.io.*;/*** 采用4种方式复制,输出各自复制所需要的时间* 方式1: 采用基本的流,一次一个字节的方式复制* 方式2: 采用基本的流,一个多个字节的方式赋值* 方式3: 采用高效的流,一次一个字节的方式复制* 方式4: 采用高效的流,一个多个字节的方式赋值*/
public class CopyStreamDemo {private static File copyTargetFile = new File("/Users/kim/Documents/Code/resource/mac_launchpad_03.png");private static File copyDestinationFile_01 = new File("./Test/mac_launchpad_01.png");private static File copyDestinationFile_02 = new File("./Test/mac_launchpad_02.png");private static File copyDestinationFile_03 = new File("./Test/mac_launchpad_03.png");private static File copyDestinationFile_04 = new File("./Test/mac_launchpad_04.png");public static void main(String[] args) throws IOException {StreamIntCopy(copyTargetFile,copyDestinationFile_01);StreamByteCopy(copyTargetFile,copyDestinationFile_02);BuffereIntCopy(copyTargetFile,copyDestinationFile_03);BuffereByteCopy(copyTargetFile,copyDestinationFile_04);}/*** 方式1: 采用基本的流,一次一个字节的方式复制*/public static void StreamIntCopy(File copyTargetFile,File copyDestinationFile) throws IOException {//开始计时long start = System.currentTimeMillis();FileInputStream fis = new FileInputStream(copyTargetFile);FileOutputStream fos = new FileOutputStream(copyDestinationFile);int len = 0;while ( (len = fis.read()) != -1 ){fos.write(len);}fis.close();fos.close();//结束计时long end = System.currentTimeMillis();//打印耗时多少毫秒System.out.println("方式1: 采用基本的流,一次一个字节的方式复制 共耗时 \t" +(end - start)+ " 毫秒");}/*** 方式2: 采用基本的流,一个多个字节的方式赋值*/public static void StreamByteCopy(File copyTargetFile,File copyDestinationFile) throws IOException {//开始计时long start = System.currentTimeMillis();FileInputStream fis = new FileInputStream(copyTargetFile);FileOutputStream fos = new FileOutputStream(copyDestinationFile);int len = 0;byte[] bytes = new byte[1024*10];while ( (len = fis.read(bytes)) != -1 ){fos.write(bytes,0,len);}fis.close();fos.close();//结束计时long end = System.currentTimeMillis();//打印耗时多少毫秒System.out.println("方式2: 采用基本的流,一个多个字节的方式赋值 共耗时 \t" +(end - start)+ " 毫秒");}/*** 方式3: 采用高效的流,一次一个字节的方式复制*/public static void BuffereIntCopy(File copyTargetFile,File copyDestinationFile) throws IOException {//开始计时long start = System.currentTimeMillis();FileInputStream fis = new FileInputStream(copyTargetFile);BufferedInputStream bis = new BufferedInputStream(fis);FileOutputStream fos = new FileOutputStream(copyDestinationFile);BufferedOutputStream bos = new BufferedOutputStream(fos);int len = 0;while ( (len = bis.read()) != -1 ){bos.write(len);}bis.close();bos.close();//结束计时long end = System.currentTimeMillis();//打印耗时多少毫秒System.out.println("方式3: 采用高效的流,一次一个字节的方式复制 共耗时 \t" +(end - start)+ " 毫秒");}/*** 方式4: 采用高效的流,一个多个字节的方式赋值*/public static void BuffereByteCopy(File copyTargetFile,File copyDestinationFile) throws IOException {//开始计时long start = System.currentTimeMillis();FileInputStream fis = new FileInputStream(copyTargetFile);BufferedInputStream bis = new BufferedInputStream(fis);FileOutputStream fos = new FileOutputStream(copyDestinationFile);BufferedOutputStream bos = new BufferedOutputStream(fos);int len = 0;byte[] bytes = new byte[1024*10];while ( (len = bis.read(bytes)) != -1 ){bos.write(bytes,0,len);}bis.close();bos.close();//结束计时long end = System.currentTimeMillis();//打印耗时多少毫秒System.out.println("方式4: 采用高效的流,一个多个字节的方式赋值 共耗时 \t" +(end - start)+ " 毫秒");}
}
流的操作规律
IO流中对象很多,解决问题(处理设备上的数据时),把IO流进行了规律的总结(四个明确):
-
明确一:要操作的数据是数据源还是数据目的?
- 源:InputStream、Reader
- 目的:OutputStream、Writer
- 先根据需求明确要读,还是要写
-
明确二:要操作的数据是字节还是文本呢?
- 源:InputStream (字节)、Reader (文本)
- 目的:OutputStream (字节)、Writer (文本)
- 已经明确到了具体的体系上
-
明确三:明确数据所在的具体设备
- 源设备:硬盘(文件、File开头)、内存(数组、字符串)、键盘(System.in)、网络(Socket)
- 目的设备:硬盘(文件、File开头)、内存(数组、字符串)、屏幕(System.out)、网络(Socket)
- 完全可以明确具体要使用哪个流对象
-
明确四:是否需要额外功能呢?
- 额外功能:
- 转换吗?转换流。InputStreamReader OutputStreamWriter
- 高效吗?缓冲区对象。BufferedXXX
- 额外功能:
- Object- InputStream- FileInputStream- BufferedInputStream- OuputStream - FileOutputStream- BufferedOuputStream- Writer- OutputStreamWriter- FileWriter- BufferedWriter- Reader- InputStreamReader- FileReader- BufferedReader
Properties类
Properties类介绍
Properties类表示了一个持久的属性集。Properties可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
特点:
- Hashtable的子类,map集合中的方法都可以用
- 该集合没有泛型。键值都是字符串
- 它是一个可以持久化的属性集,键值可以存储到集合中,也可以存储到持久化的设备(硬盘、U盘、光盘)上。键值的来源也可以是持久化的设备
- 有和流技术相结合的方法

import java.util.Properties;
import java.util.Set;/*** 集合对象,Properties集合,继承Hashtable,实现HashMap,能与IO流交互的集合* setProperty(String key, String value) 等同于Map中的put,设置* getProperty(String key) 等同于Map中的get,获取,查询不存在的键会返回null*/
public class PropertiesDemo {public static void main(String[] args) {Properties pro = new Properties();//设置键值对pro.setProperty("姓名","张三");pro.setProperty("年龄","18");//通过键获取值String name = pro.getProperty("姓名");//stringPropertyNames方法,获取所有键值对,返回的是一个set集合Set<String> s = pro.stringPropertyNames();for (String key : s){System.out.println(key + " " + pro.getProperty(key));}}
}
stroe() 方法存储到文件
import java.io.FileWriter;
import java.io.IOException;
import java.util.Properties;/*** 集合对象,Properties集合,继承Hashtable,实现HashMap,能与IO流交互的集合** Properties集合的特有方法,store* store(OutputStream out, String comments)* store(Writer w, String comments)* 传递任意的字节或者字符输出流,将集合中的简直对写入到文件当中*/
public class PropertiesDemo {public static void main(String[] args) throws IOException {Properties properties = new Properties();properties.setProperty("name", "zhangsan");properties.setProperty("age", "18");properties.setProperty("email", "11111@qq.com");FileWriter fw = new FileWriter("./Test/test.properties");//调用集合的方法load,传递字符输出流和描述说明字符串//注意:1、描述说明字符串不要写中文; 2、不需要flush刷新,这个store方法里帮我们完成了;properties.store(fw, "Test Properties File");//传入后就可以关闭字符输入流fw.close();}
}
load() 方法读取文件
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;/*** 集合对象,Properties集合,继承Hashtable,实现HashMap,能与IO流交互的集合** Properties集合的特有方法,load* load(InputStream in)* load(Reader r)* 传递任意的字节或者字符输入流,流对象读取文件中的键值对,并保存到集合*/
public class PropertiesDemo {public static void main(String[] args) throws IOException {Properties properties = new Properties();FileReader fr = new FileReader("./config.properties");//调用集合的方法load,传递字符输入流properties.load(fr);//传入后就可以关闭字符输入流fr.close();System.out.print(properties);}
}
序列化流与反序列化流
用于从流中读取对象的操作流 ObjectInputStream,称为反序列化流;用于向流中写入对象的操作流 ObjectOutputStream,称为序列化流;它的特点就是用于操作对象,可以将对象写入到文件中,也可以从文件中读取对象。
ObjectOutputStream 对象序列化流
ObjectOutputStream 将 Java 对象的基本数据类型和图形写入 OutputStream。可以使用 ObjectInputStream 读取(重构)对象。通过在流中使用文件可以实现对象的持久存储。
注意:只能将支持 java.io.Serializable 接口的对象写入流中,没有实现会报NotSerializableException错误


import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;/*** IO流对象,实现对象序列化的持久化存储* ObjectOutputStream 写对象,实现序列化** 构造方法* ObjectOutputStream(OutputStream out) 传递任意的字节输出流** 方法* void writeObject(Object obj) 写出对象的方法*/
public class ObjectOutputStreamDemo {public static void main(String[] args) throws IOException {//创建字节输出流,绑定文件FileOutputStream fos = new FileOutputStream("./Test/person.temp");//创建写出对象的序列化流对象,传递字节输出流对象ObjectOutputStream oos = new ObjectOutputStream(fos);//调用序列化流对象的方法writeObject,写出对象oos.writeObject(new PersonTest("zhangsan", 18));//关闭字节输出流对象fos.close();}
}/*** 这是一个用来测试的类,实现 Serializable 接口*/
class PersonTest implements Serializable{private String name;private int age;public PersonTest() {}public PersonTest(String name, int age) {this.name = name;this.age = age;}public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; }@Overridepublic String toString() {return "PersonTest{" + "name='" + name + '\'' + ", age=" + age + '}';}
}
ObjectInputStream 对象反序列化流
ObjectInputStream 对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化,支持java.io.Serializable接口的对象才能从流读取。


import java.io.*;/*** IO流对象,实现对象反序列化,* ObjectInputStream 读对象,实现读取反序列化** 构造方法* ObjectInputStream(InputStream in) 传递任意的字节输入流** 方法* Object readObject() 读取反序列化对象的方法*/
public class ObjectInputStreamDemo {public static void main(String[] args) throws IOException, ClassNotFoundException {//创建字节输入流,绑定序列化文件FileInputStream fis = new FileInputStream("./Test/person.temp");//创建反序列化流,传递字节输入流ObjectInputStream ois = new ObjectInputStream(fis);//调用反序列化流的方法,readObject读取对象PersonTest p = (PersonTest)ois.readObject();System.out.println(p);fis.close();}
}
transient 瞬态关键字
当一个类的对象需要被序列化时,某些属性不需要被序列化,这时不需要序列化的属性可以使用关键字transient修饰。只要被transient修饰了,序列化时这个属性就不会被序列化了,同时静态修饰也不会被序列化,因为序列化是把对象数据进行持久化存储,而静态的属于类加载时的数据,不会被序列化
也就是说有两种情况不会被序列化:
- 第一种:加了
transient瞬态修饰; - 第二种:加了
static静态修饰;
/*** 这是一个用来测试的类,实现 Serializable 接口*/
public class PersonTest implements Serializable{private String name;private transient /*瞬态*/ int age;public PersonTest() {}public PersonTest(String name, int age) {this.name = name;this.age = age;}public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; }@Overridepublic String toString() {return "PersonTest{" + "name='" + name + '\'' + ", age=" + age + '}';}
}
序列号
当反序列化对象时,如果对象所属的class文件在序列化之后进行的修改,那么进行反序列化也会发生异常InvalidClassException。发生这个异常的原因如下:
- 该类的序列版本号与从流中读取的类描述符的版本号不匹配
- 该类包含未知数据类型
- 该类没有可访问的无参数构造方法
Serializable标记接口,该接口给需要序列化的类,提供了一个序列版本号。serialVersionUID. 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
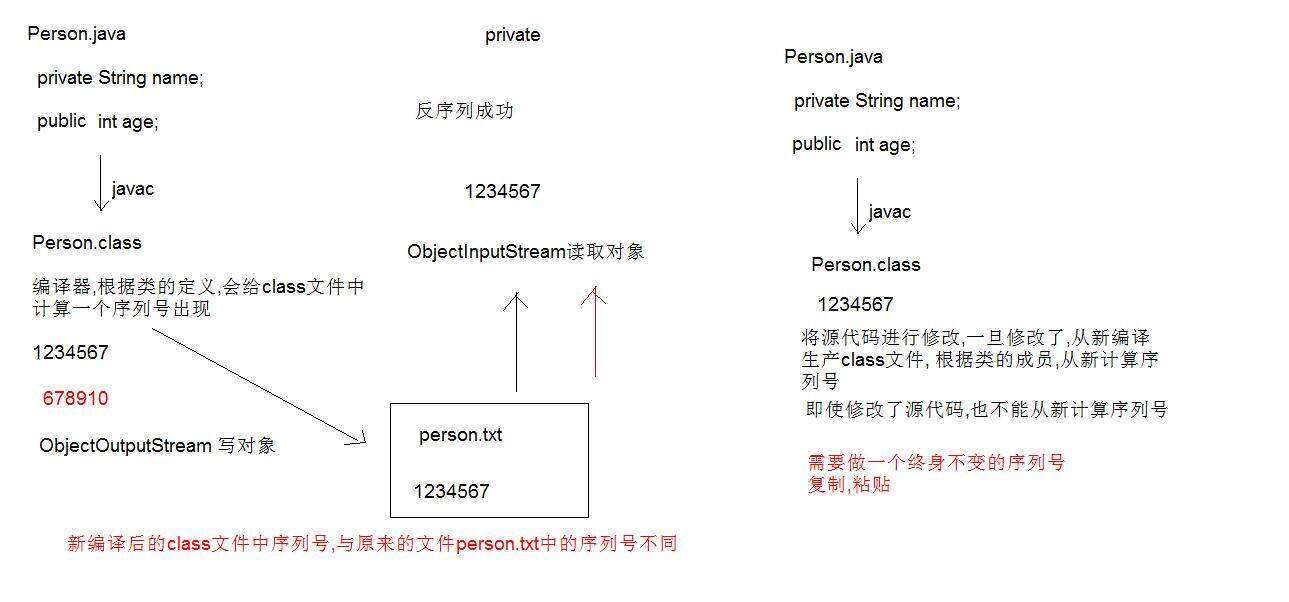
如何解决序列号的冲突问题呢?
我们可以给类显示声明一个序列版本号,示例如下:
/*** 这是一个用来测试的类,实现 Serializable 接口*/
public class PersonTest implements Serializable{private String name;private int age;/*** 给类显示声明一个序列版本号*/private static final long serialVersionUID = 246091633;public PersonTest(String name, int age) {this.name = name;this.age = age;}public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; }@Overridepublic String toString() {return "PersonTest{" + "name='" + name + '\'' + ", age=" + age + '}';}
}
打印流
打印流的概述
打印流添加输出数据的功能,使它们能够方便地打印各种数据值表示形式.
打印流根据流的分类:
- 字节打印流 PrintStream
- 字符打印流 PrintWriter
方法:
- void print(String str) 输出任意类型的数据,
- void println(String str) 输出任意类型的数据,自动写入换行操作
import java.io.FileNotFoundException;
import java.io.PrintWriter;/*** 打印流* PrintWriter* PrintStream* 特点:* 1、此流不负责数据源,只负责数据目的* 2、为其他输出流添加功能* 3、永远不会抛IO异常,但是可能会抛出其他异常** 两个打印流方法都是一致的,两个流的区别在于构造方法* PrintWriter* 构造方法,接收File类型,接收字符串文件名,接收字节输出流OutputStream,接收字符输出流Writer* PrintStream* 构造方法,接收File类型,接收字符串文件名,接收字节输出流OutputStream*/
public class PrintWriterDemo {public static void main(String[] args) throws FileNotFoundException {PrintWriter pw = new PrintWriter("./Test/test.txt");pw.println(100);pw.flush();pw.close();}
}
打印流完成数据自动刷新
import java.io.*;/*** 打印流* PrintWriter* 开启自动刷新功能* 条件:* 1、输出的数据目的必须是流对象 OutputStream Writer* 2、必须调用的方法是println、printf、format三个中的其中一个*/
public class PrintWriterDemo {public static void main(String[] args) throws IOException {FileOutputStream fos = new FileOutputStream("./Test/test.txt");PrintWriter pr = new PrintWriter(fos, true);pr.println("Hello World 01 !");fos.close();}
}
commons-IO
获取下载
官网下载地址:https://commons.apache.org/proper/commons-io/download_io.cgi
本站下载地址:https://resource.if010.com/jar_tools/commons-io-2.13.0-bin.zip
FilenameUtils
这个工具类是用来处理文件名(译者注:包含文件路径)的,他可以轻松解决不同操作系统文件名称规范不同的问题
常用方法:
- getExtension(String path); 获取文件的扩展名
- getName(); 获取文件名
- isExtension(String fileName,String ext); 判断fileName是否是ext后缀名
FileUtils
提供文件操作(移动文件,读取文件,检查文件是否存在等等)的方法。
常用方法:
- readFileToString(File file); 读取文件内容,并返回一个String
- writeStringToFile(File file, String content); 将内容content写入到file中
- copyDirectory(File srcDir, File destDir); 文件夹复制
- copyFile(File srcFile, File destFile); 文件夹复制
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import java.io.File;
import java.io.IOException;public class commonsIODemo {public static void main(String[] args) throws IOException {/*** FilenameUtils工具类演示*///获取文件名的扩展名String extensionName = FilenameUtils.getExtension("abc.java");//获取文件名String fileName = FilenameUtils.getName("abc.java");//判断fileName是否是java后缀名boolean extensionPanDuan = FilenameUtils.isExtension("abc.java", "java");/*** FileUtils工具类演示*///读取文本文件String s = FileUtils.readFileToString(new File("./Test/test.txt"));System.out.println(s);//将字符串追加写入到文件当中FileUtils.writeStringToFile(new File("./Test/test.txt"), "你好!世界!", true);//复制文件FileUtils.copyFile(new File("./Test/1689303812029.jpg"),new File("./Test/1689303812029_bak.jpg"));//复制文件夹FileUtils.copyDirectory(new File("./Test"),new File("./Test2"));}
}
![[自动化测试] 读取CSV 文件](https://img-blog.csdnimg.cn/5d56cba78d64410eaf5279e6cde41f93.png)



![NSS [MoeCTF 2022]baby_file](https://img-blog.csdnimg.cn/img_convert/430eb4a78dfdef8dd67c4c0e669f9609.png)

