本文将介绍如何使用哈希表来实现C++ STL库中的unordered_map和unordered_set容器。我们将会解释哈希表的基本原理,并给出具体的代码示例,帮助读者更好地理解和应用哈希表。
哈希原理讲解–链接入口
set和map的实现的文章,与unordered_map实现类似
对HashTable的改造
#pragma oncetemplate<class K>
struct Hashfunc
{size_t operator()(const K& key){return (size_t)key;}
};
//特化
template<>
struct Hashfunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto a : s){hash += a;hash *= 31;}return hash;}
};namespace hash_bucket
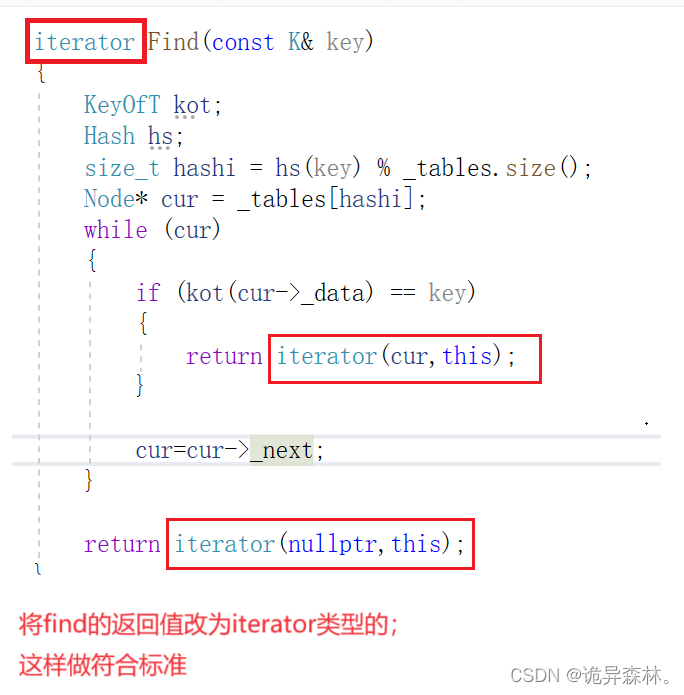
{template <class T>struct HashNode{HashNode<T>* _next;T _data;HashNode(const T& data):_next(nullptr),_data(data){}};// 前置声明template<class K, class T, class KeyOfT, class Hash>class HashTable;template<class K, class T, class KeyOfT, class Hash>struct _HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef _HTIterator<K, T, KeyOfT, Hash> Self;Node* _node;HT* _ht;_HTIterator(Node* node,HT* ht):_node(node),_ht(ht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();hashi++;//循环找出存在的哈希桶位置;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}hashi++;}if (hashi == _ht->_tables.size()){_node = nullptr;}return *this;}}bool operator!=(const Self & s){return _node != s._node;}bool operator ==(const Self& s){return _node == s._node;}};template<class K,class T,class KeyOfT, class Hash>class HashTable{template<class K,class T,class KeyOfT,class Hash>friend struct _HTIterator;typedef HashNode<T> Node;public:typedef _HTIterator<K, T, KeyOfT, Hash> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){// 找到第一个桶的第一个节点if (_tables[i]){return iterator(_tables[i], this);}}return end();}iterator end(){return iterator(nullptr, this);}HashTable(){_tables.resize(10, nullptr);_n = 0;}~HashTable(){for (size_t i= 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}iterator Find(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur,this);}cur=cur->_next;}return iterator(nullptr,this);}pair<iterator,bool> Insert(const T& data){KeyOfT kot;Hash hs;//查找是否有相同元素iterator it = Find(kot(data));if (it != end())return make_pair(it,false);//扩容if (_n == _tables.size()){vector<Node*> newTables(_tables.size() * 2, nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);} size_t hashi = hs(kot(data)) % _tables.size();Node* newnode = new Node(data);it = iterator(newnode, this);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(it,true);}bool Erase(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data)==key){if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}delete cur;_n--;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;size_t _n;};
}






对unordered_map和unordered_set的实现
unordered_set是一种集合存储的容器,它存储唯一的元素。我们同样可以使用哈希表来实现unordered_set,将元素映射到数组的索引。
- 插入操作:通过哈希函数计算元素的索引,如果索引位置为空,则直接插入;否则,使用开放地址法寻找下一个可用的槽进行插入。
- 查找操作:通过哈希函数计算元素的索引,然后比较该索引位置的元素是否与目标元素相等,如相等则返回存在;如不相等,则使用开放地址法依次查找下一个槽,直到找到相等的元素或者遇到空槽为止。
- 删除操作:通过哈希函数计算元素的索引,然后通过循环找到对应的元素,如果这个元素有前一个结点,那么就让前一个结点链上当前结点的下一个结点,然后删除当前结点;如果当前元素没有前一个结点,那么就表示删除该节点后,哈希桶的头结点将为空;
namespace fnc
{template<class K,class Hash=Hashfunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> insert(const K& k){return _ht.Insert(k);}iterator find(const K& k){return _ht.Find(k);}bool Erase(const K& k){return _ht.Erase(k);}private:hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;};
}
unordered_map是一种键值对存储的容器,它允许通过键快速查找对应的值。我们可以使用哈希表来实现unordered_map,将键映射到数组的索引,值存储在对应的槽中。
- 插入操作:通过哈希函数计算键的索引,如果索引位置为空,则直接插入;否则,使用开放地址法寻找下一个可用的槽进行插入。
- 查找操作:通过哈希函数计算键的索引,然后比较该索引位置的键是否与目标键相等,如相等则返回对应的值;如不相等,则使用开放地址法依次查找下一个槽,直到找到相等的键或者遇到空槽为止。
- 删除操作:通过哈希函数计算元素的索引,然后通过循环找到对应的元素,如果这个元素有前一个结点,那么就让前一个结点链上当前结点的下一个结点,然后删除当前结点;如果当前元素没有前一个结点,那么就表示删除该节点后,哈希桶的头结点将为空;
namespace fnc
{template<class K, class V, class Hash = Hashfunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator find(const K& k){return _ht.Find(k);}bool Erase(const K& k){return _ht.Erase(k);}V& operator[](const K& key){pair<iterator, bool> ret = insert(make_pair(key, V()));return ret.first->second;}private:hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};
}



测试
insert

find和erase
//find和erasevoid test_set2(){vector<int> v = { 3,1,5,15,45,7 };unordered_set<int> us;us.insert(3);us.insert(1);us.insert(5);us.insert(15);us.insert(45);us.insert(7);unordered_set<int>::iterator it = us.begin();while (it != us.end()){cout << *it << " ";++it;}cout << endl;if (us.find(15) != us.end()){cout << "15:在" << endl;}else{cout << "15:不在" << endl;}if (us.find(16) != us.end()){cout << "16:在" << endl;}else{cout<<"16:不在" << endl;}cout << endl;us.Erase(5);us.Erase(7);it = us.begin();while (it != us.end()){cout << *it << " ";++it;}cout << endl;}
}
void test_map2(){unordered_map<string, string> dict;dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("left", "左"));dict.insert(make_pair("right", "右"));for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;fnc::unordered_map<string, string>::iterator it = dict.find("sort");if (it!=dict.end()){cout <<"找到了:" << (*it).first << ":" << (*it).second << endl;}cout << endl;dict.Erase("left");for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}}

operator[]
void test_map3(){vector<string> v = { "香蕉","苹果","橙子","西瓜","香蕉","苹果","橙子","西瓜","香蕉","苹果","橙子" ,"香蕉","苹果" };unordered_map<string, int> dict;for (auto a : v){dict[a]++;}for (auto a : dict){cout << a.first << ":" << a.second << endl;}}