当我们想要下载网页的图片时,发现网页的图片太多了,无从下手,那我们写一个脚本来爬取呗。
这次的脚本是专门针对某个外国网站使用的,因此仅供参考思路。
在测试的过程中,我发现网站使用了发爬虫机制,具体就是JavaScript动态渲染html代码,你中间使用python抓包没有JavaScript渲染过,所以BeautiSoup就不能解析HTML里面的<img>标签中的带有完整图片链接的src属性。
当我们关闭浏览器的JavaScript,网页就拒绝显示了,因此如何绕过这个是个问题。
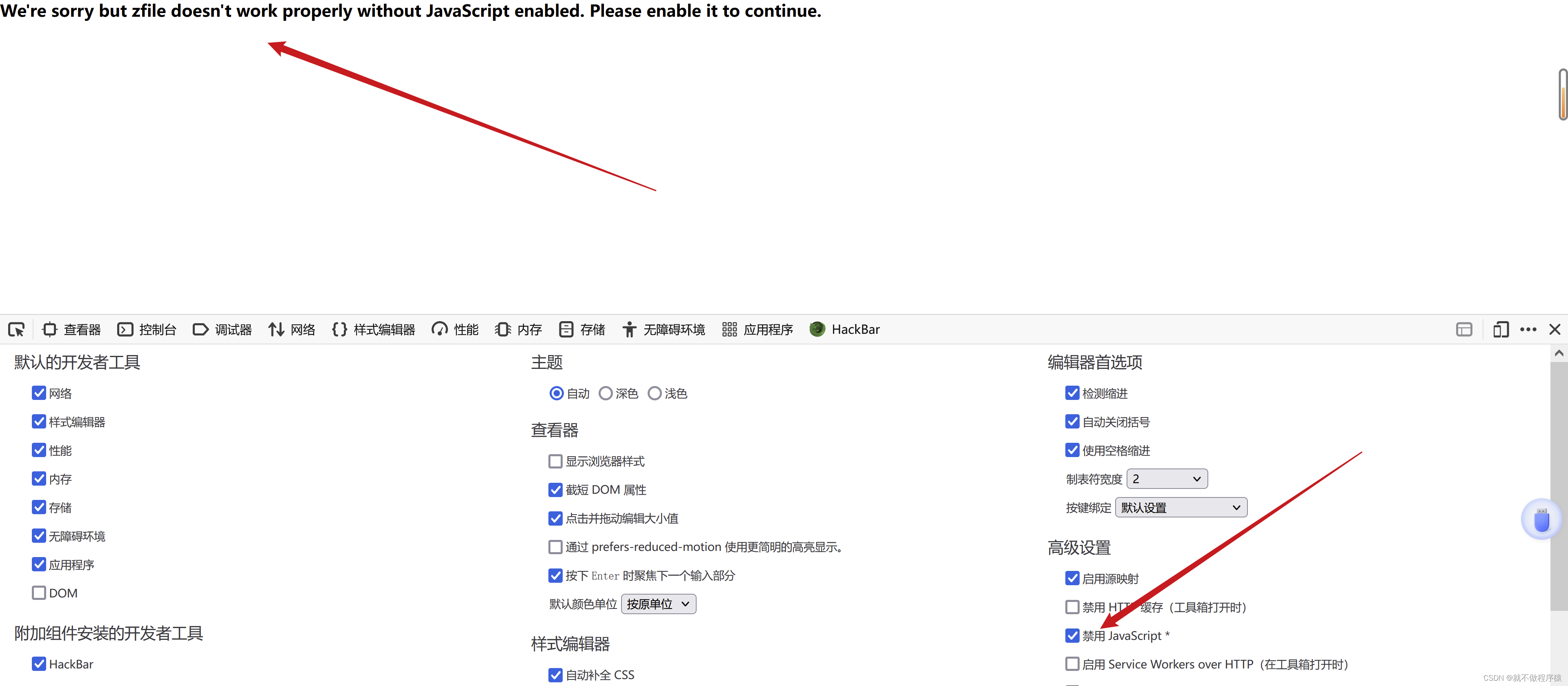
实话实说,我没从代码层面绕过JavaScript动态渲染,但是我们如果在python中加入这个功能的目的是什么?不就是为了找到完整的、带有<img>标签的HTML源码嘛
那我们直接用现有的呗!在哪里?

这不就得到了!然后我们把这个源码放进一个txt文件中,python读取这个文件不就行啦?
import requests
from bs4 import BeautifulSoup
import selenium
from selenium import webdriver
import time
import winsound#模拟浏览器行为,绕过简单的反爬虫机制
options = webdriver.ChromeOptions()
options.add_argument("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.59 Safari/537.36")
driver = webdriver.Chrome(options=options)# 设置代理和自定义请求头,因为我爬的是外网,所以加了代理
proxies = {'http': 'http://192.168.43.244:7890','https': 'http://192.168.43.244:7890',
}#设置请求头部,这里我用burp抓包抓的头部,更加模拟真实用户请求
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.59 Safari/537.36",'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Upgrade-Insecure-Requests': '1','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'none','Sec-Fetch-User': '?1','Te': 'trailers','Connection': 'close',
}# 定义文件(图片)下载路径
download_folder = 'E:/XXX/YYY/' # 从文件中读取HTML内容,这里的111.txt是为了让BeautifulSoup读取的
file_path = 'D:/XXX/111.txt'
with open(file_path, 'r', encoding='utf-8') as file:html_content = file.read()# 使用 BeautifulSoup 解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')# 查找所有的img标签并获取其src属性值
img_tags = soup.find_all('img')
image_links = [tag.get('src') for tag in img_tags]# 定义用于存储访问结果的列表
access_results = []# 遍历所有图片链接并尝试访问
for link in image_links:try:response = requests.get(link, headers=headers, proxies=proxies)if response.status_code == 200:access_results.append(f'Successfully accessed: {link}')#下载图片file_name = link.split('/')[-1]# 拼接保存路径save_path = download_folder + file_namewith open(save_path, 'wb') as f:f.write(response.content)print(f'Downloaded: {file_name}')else:access_results.append(f'Failed to access: {link}, Status code: {response.status_code}')except requests.exceptions.RequestException as e:access_results.append(f'Failed to access: {link}, Error: {e}')# 输出访问结果
for result in access_results:print(result)
winsound.Beep(1000, 500) # 爬取完毕响铃提示直接运行,可以看到下载成功了,当然在运行过程中,因为网络问题会出现下载失败的问题,可以多运行几次,进行覆盖。

虽然这算是个半自动爬虫,但是在网页有很多图片的时候,会大大提高效率,这种手动绕过JavaScript动态渲染也是初学者可以使用的思路。