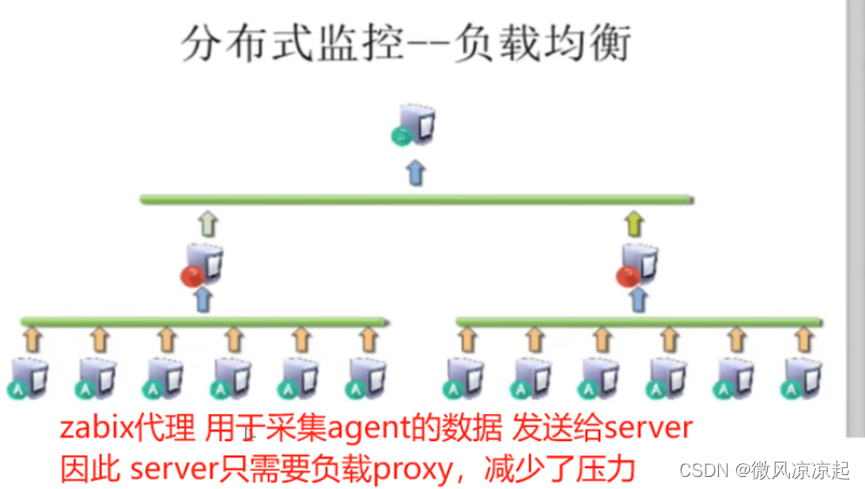
目录
1. 引言
2.RNN原理与时间步展开
3.LSTM与GRU工作机制与优势
3.1.LSTM(Long Short-Term Memory)
3.2.GRU(Gated Recurrent Unit)
4.应用案例
4.1文本生成
4.2情感分析
5.总结
1. 引言
循环神经网络(Recurrent Neural Network,RNN)是一种专门用于处理序列数据的神经网络结构。序列数据是指具有前后依赖关系的数据,如文本、语音、时间序列等。RNN通过引入循环单元,使得网络能够捕捉序列中的长期依赖关系,从而在处理这类数据时具有显著优势。
本文将深入探讨RNN的基本原理、时间步展开,详细介绍两种改进型RNN——长短时记忆网络(LSTM)与门控循环单元(GRU)的工作机制与优势,并通过应用案例展示RNN在文本生成与情感分析任务中的实际应用。更多Python在人工智能中的使用方法,欢迎关注《Python人工智能实战》栏目!
2.RNN原理与时间步展开
原理:RNN的核心思想是在处理序列数据时,不仅考虑当前时刻的输入,还通过内部状态(隐藏状态)传递之前时刻的信息。每个时间步,RNN都会接收到一个新的输入,并结合当前隐藏状态计算新的隐藏状态及输出。这种递归结构使得RNN能够捕捉到输入序列中的时间依赖性。
时间步展开:为了便于理解和训练,RNN的时间递归结构可以通过“展开”成一个有向图的形式展现。对于一个序列长度为T的输入X = (x_1, x_2, ..., x_T),RNN将在时间步t处进行如下计算:
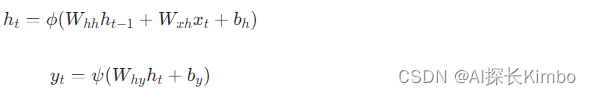
其中:
h_t为时间步t的隐藏状态。x_t为时间步t的输入。W_{hh}、W_{xh}、W_{hy}分别为隐层到隐层、输入到隐层、隐层到输出的权重矩阵。b_h、b_y分别为隐层和输出层的偏置向量。\phi和\psi分别为隐层和输出层的激活函数(如tanh、ReLU或softmax等)。
3.LSTM与GRU工作机制与优势
虽然标准的RNN在处理短期依赖关系时表现良好,但对于长期依赖关系,它往往会出现梯度消失或梯度爆炸的问题。为了解决这个问题,出现了两种改进的RNN结构:长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)。
3.1.LSTM(Long Short-Term Memory)
LSTM通过引入门控机制解决了标准RNN在长期依赖学习中的梯度消失/爆炸问题。LSTM单元包含输入门(i_t)、遗忘门(f_t)、输出门(o_t)以及细胞状态(c_t)。各门控负责控制信息的流入、遗忘和输出,细胞状态则作为长期记忆载体。
-
输入门决定当前时刻新信息的多少进入细胞状态:

-
遗忘门控制前一时刻细胞状态中哪些信息应被遗忘:

-
更新细胞状态,结合输入门和遗忘门的结果:
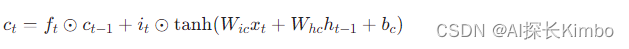
-
输出门决定当前细胞状态中哪些信息应作为隐藏状态输出:

-
最终隐藏状态:

3.2.GRU(Gated Recurrent Unit)
GRU是一种简化版的LSTM,它合并了输入门和遗忘门为一个更新门(z_t),同时将细胞状态与隐藏状态合并为单一隐藏状态。GRU通过两个门控机制——重置门(r_t)和更新门来控制信息流动:
-
重置门决定前一时刻信息是否应被丢弃:

-
更新门控制新旧信息融合的比例:

-
候选隐藏状态,结合当前输入和部分遗忘的前一隐藏状态:

-
最终隐藏状态,根据更新门混合前一隐藏状态和候选隐藏状态:

优势:LSTM与GRU均通过门控机制有效地捕捉长期依赖,避免梯度消失问题。LSTM由于具有独立的细胞状态和精细的门控设计,更适合处理复杂序列中的远距离依赖。GRU结构更为简洁,参数更少,训练速度通常更快,且在许多任务中表现出与LSTM相当甚至更好的性能。
4.应用案例
4.1.文本生成
RNN在文本生成领域具有广泛应用。通过训练一个基于RNN的语言模型,我们可以生成具有连贯性和语法正确性的文本。具体来说,我们可以将文本序列作为RNN的输入,然后在每个时间步预测下一个单词或字符。通过不断迭代这个过程,我们就可以生成完整的句子或段落。
下面是一个简单的文本生成示例代码,使用Python和TensorFlow库实现:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense # 定义模型参数
vocab_size = 10000 # 词汇表大小
embedding_dim = 128 # 词嵌入维度
rnn_units = 256 # RNN单元数 # 构建模型
model = Sequential([ Embedding(vocab_size, embedding_dim, input_length=max_seq_length), SimpleRNN(rnn_units), Dense(vocab_size, activation='softmax')
]) # 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型(此处省略数据加载和预处理步骤)
model.fit(x_train, y_train, epochs=10, batch_size=64) # 生成文本
def generate_text(model, start_string): input_chars = [char2idx[c] for c in start_string] input_data = tf.expand_dims(input_chars, 0) for i in range(100): # 生成100个字符 predictions = model.predict(input_data) next_index = tf.math.argmax(predictions[0], axis=-1).numpy() next_char = idx2char[next_index] input_chars.append(next_index) input_data = tf.expand_dims(input_chars, 0) print(next_char, end='') # 使用模型生成文本
generate_text(model, "这是一个") 上述代码在训练完成后,使用generate_text函数生成文本。函数从给定的起始字符串开始,不断预测下一个字符并添加到输出中,直到达到指定的长度(这里为100个字符)。输出结果将是一串由模型生成的文本,例如:“这是一个非常有趣的例子,它展示了如何使用RNN进行文本生成……”
4.2.情感分析
情感分析是RNN在自然语言处理领域的另一个重要应用,旨在判断文本所表达的情感倾向。RNN可以很好地处理这种任务,因为它能够捕获文本中的上下文信息,从而更准确地判断情感。通过训练一个基于RNN的情感分类器,我们可以对输入的文本进行情感分析,判断其是积极、消极还是中性的情感倾向。
在情感分析任务中,我们通常将文本转换为词向量序列,并作为RNN的输入。RNN在处理文本序列时,会逐步积累信息并生成每个时间步的输出。最后,我们可以将RNN的最后一个时间步的输出作为整个文本的情感表示,并通过一个分类器进行情感分类。
下面是一个简化的情感分析示例代码,同样使用Python和TensorFlow库实现:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences # 假设我们有一些文本数据和对应的情感标签(积极或消极)
texts = ["I love this movie", "This is an amazing place", "I feel very sad today", "I hate this weather"]
labels = [1, 1, 0, 0] # 1表示积极情感,0表示消极情感 # 文本预处理:分词和序列填充
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
padded_sequences = pad_sequences(sequences) # 构建RNN模型
model = Sequential([ Embedding(input_dim=1000, output_dim=64, input_length=max_seq_length), SimpleRNN(64), Dense(1, activation='sigmoid') # 使用sigmoid激活函数进行二分类
]) # 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # 训练模型(此处省略数据划分为训练集和测试集)
model.fit(padded_sequences, labels, epochs=10, batch_size=32) # 情感分析预测
def predict_sentiment(model, text): sequence = tokenizer.texts_to_sequences([text])[0] padded_sequence = pad_sequences([sequence], maxlen=max_seq_length) prediction = model.predict(padded_sequence)[0][0] return "Positive" if prediction > 0.5 else "Negative" # 使用模型进行情感分析预测
sentiment = predict_sentiment(model, "I really enjoyed that concert.")
print(sentiment) # 输出: Positive 上述代码在训练完成后,定义了一个predict_sentiment函数来进行情感分析预测。函数首先将输入的文本转换为词向量序列,并进行填充处理。然后,它使用训练好的模型对填充后的序列进行预测,并根据预测结果判断情感倾向(积极或消极)。最后,代码使用示例文本进行情感分析预测,并打印输出结果。如果预测值大于0.5,则输出为“Positive”,表示积极情感;否则输出为“Negative”,表示消极情感。
5.总结
总结而言,循环神经网络凭借其内在的时间循环特性,成为处理序列数据的理想选择。LSTM与GRU作为RNN的增强版本,通过引入门控机制有效解决了长期依赖学习问题,在文本生成与情感分析等任务中展现了强大的建模能力。实践中,根据任务需求和数据特性选择合适的RNN变体,能够实现对序列数据的高效理解和精准建模。