相关性描述的是⼀个⽂档和查询语句匹配的程度。ES 会对每个匹配查询条件的结果进⾏算分_score。_score 的评分越高,相关度越高。
ES 5.0之前使用TF-IDF 相关性算法, 5.0之后使用了BM25算法
TF-IDF
公式
score(q,d) = queryNorm(q)
· coord(q,d)
· ∑ (t.getBoost()
.tf(t in d)
· idf(t)
· norm(t,d)
) (t in q)
- score(q,d) 文档d对查询q的相关性得分
- queryNorm(q) 查询的规范化因子
- coord(q,d) 协调因子
- ∑ 文档d的查询q中每个词t的权重之和
- tf(t in d) 文档d中t词的词频(出现次数)
- idf(t) t词的逆文档频率
- t.getBoost() 已应用于查询的boost
- norm(t,d) 是字段长度归一值,与检索时字段的Boost (如果存在)相结合。
BM25
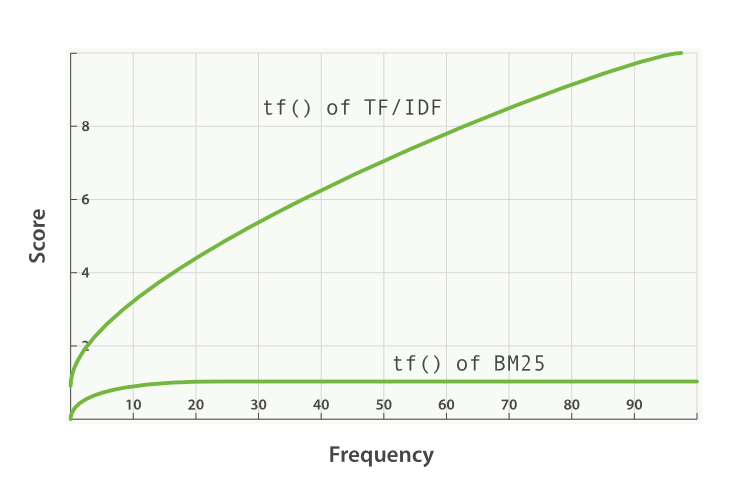
整体而言 BM25 就是对 TF-IDF 算法的改进,对于 TF-IDF 算法,TF(t) 部分的值越大,整个公式返回的值就会越大。BM25 就针对这点进行来优化,随着TF(t) 的逐步加大,该算法的返回值会趋于一个数值。如下图所示:
公式
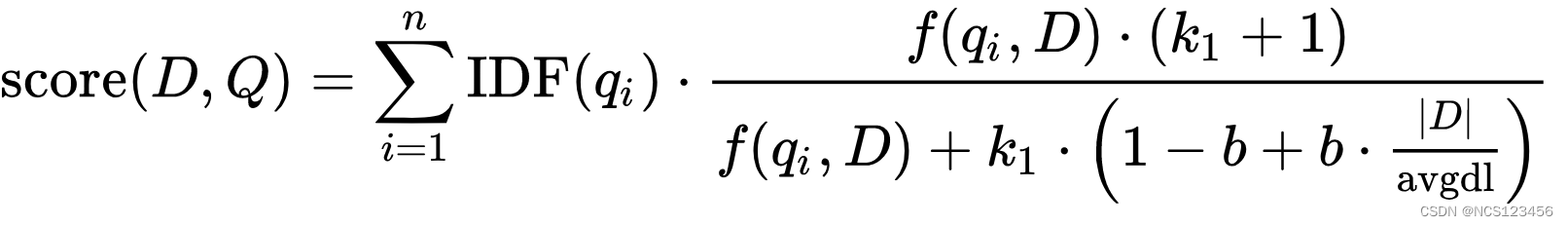
该公式前半部分是IDF, 后半部分是TF + NORM
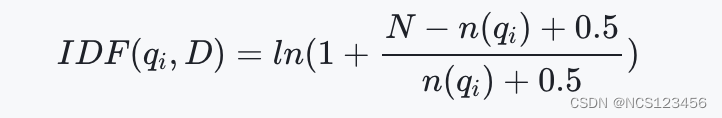
- IDF(qi,D):查询项的逆文档频率
- N:索引中的文档总数
- n(qi) : 索引字段中包含查询项的文档数量
- f(qi,D): 查询项在文档D中出现的频次
- k1: 这个参数控制着词频结果在词频饱和度中的上升速度。默认值为1.2。值越小饱和度变化越快,值越大饱和度变化越慢
- b: 这个参数控制着字段长归一值所起的作用,0.0会禁用归一化,1.0会启用完全归一化。默认值为0.75
- |D|: 代表文档的长度,
- avgdl: 代表索引中平均字段长度
explain
PUT /blogs_index
{"settings": {"index": {"number_of_shards": 1,"number_of_replicas": 0}},"mappings": {"dynamic": false,"properties": {"title": {"type": "text","analyzer": "ik_smart"},"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}
}POST /blogs_index/_bulk
{"index":{"_id":"1"}}
{"title":"es的相关度","content":"这是关于es的相关度的文章"}
{"index":{"_id":"2"}}
{"title":"相关度","content":"这是关于相关度的文章"}
{"index":{"_id":"3"}}
{"title":"es","content":"这是关于关于es和编程的必看文章"}
{"index":{"_id":"4"}}
{"title":"关注我,系统学习es","content":"这是关于es的文章,介绍了一点相关度的知识"}GET /blogs_index/_analyze
{"text": ["es的相关度"],"field": "title"
}{"tokens" : [{"token" : "es","start_offset" : 0,"end_offset" : 2,"type" : "ENGLISH","position" : 0},{"token" : "的","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 1},{"token" : "相关","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "度","start_offset" : 5,"end_offset" : 6,"type" : "CN_CHAR","position" : 3}]
}GET /blogs_index/_search
{"query": {"match": {"title": "es的相关度"}},"explain": true
}文档总分
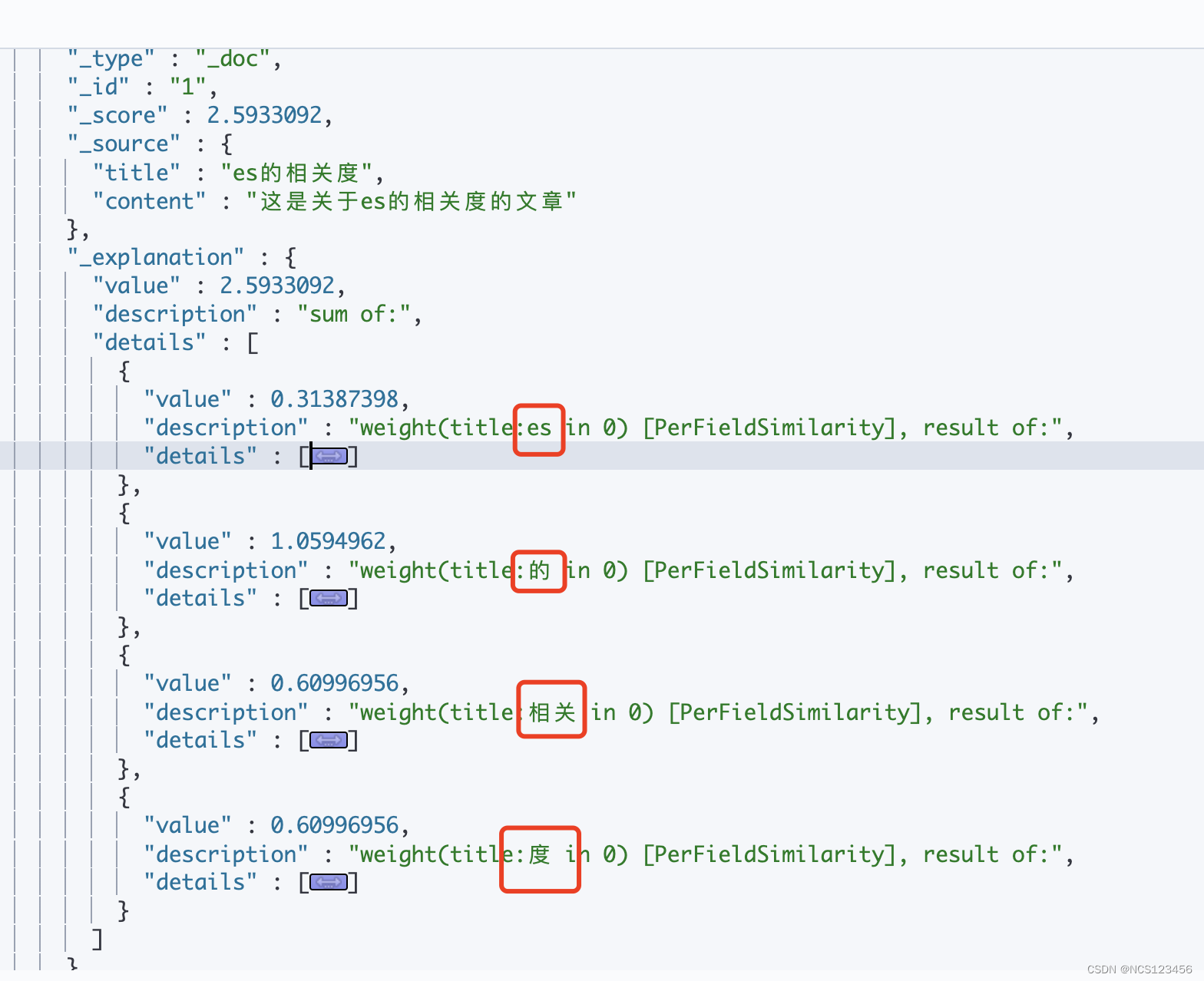
查询结果中文档一得分2.5933092是有四个分词es,的,相关,度的分数相加所得
2.5933092 = 0.31387398 + 1.0594962 + 0.60996956 + 0.60996956
单个词得分

词es在分档1中的得分是0.31387398,如图描述是由boost * idf * tf 所得
0.31387398 = 2.2 * 0.35667494 * 0.40000004
单个词idf得分
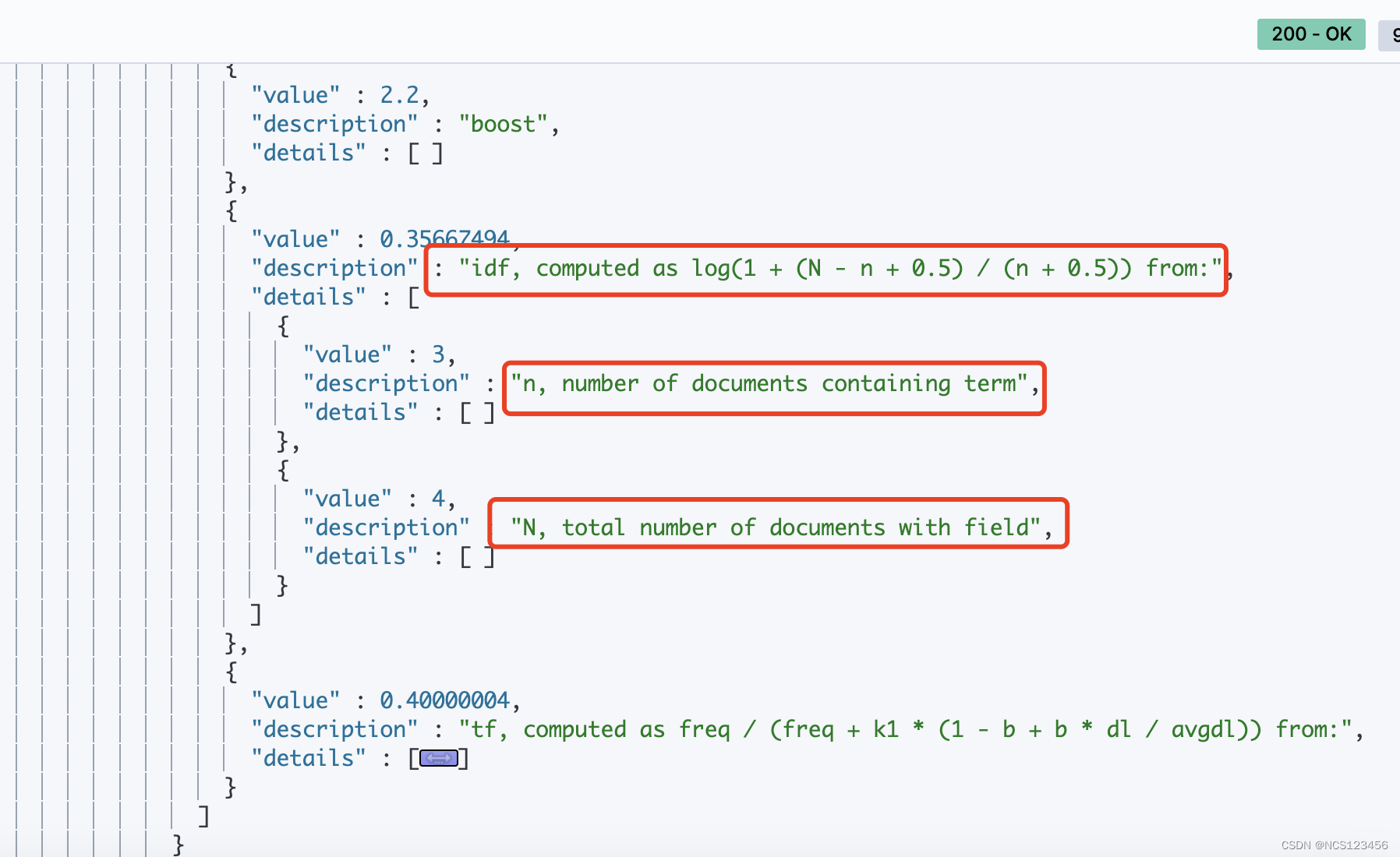
词es在分档1中的idf得分0.35667494
0.35667494 = In(1 + (4 - 3 + 0.5) / (3 + 0.5)) = In (1 + 3/7) = In(10/7)
单个词tf得分
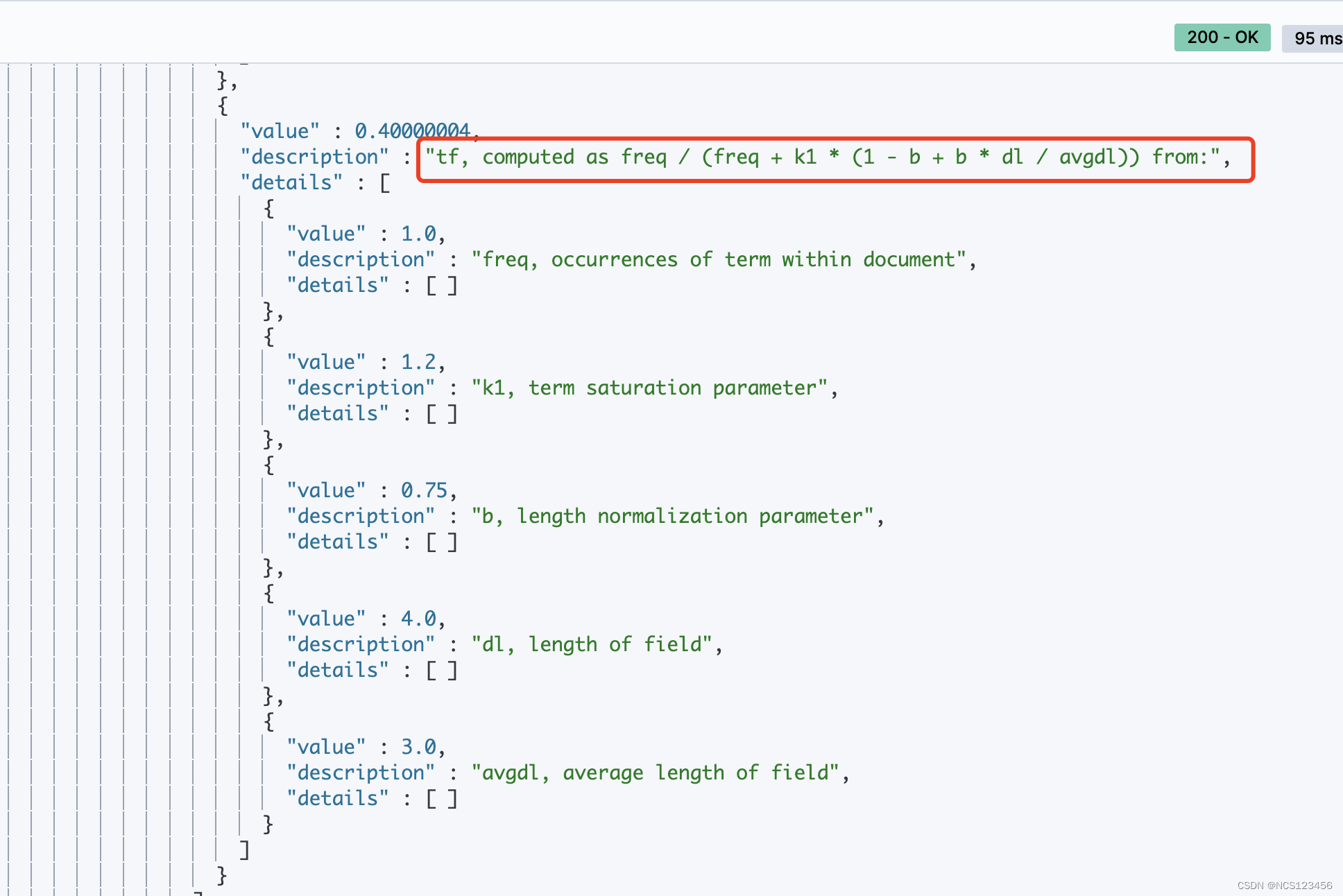
词es在分档1中的tf得分0.40000004, dl是文档1中title的分词数4, avgdl是整个索引title的平均分词数
0.40000004 = 1 / (1 + 1.2 *(1 - 0.75 + 0.75 * 4 / 3))= 1 / 2.5
更改BM25 参数 k1 和 b 的值
在介绍BM25算法时,我们知道 k1 参数【默认值1.2】控制着词频结果在词频饱和度中的上升速度。b 参数【默认值0.75】控制着字段长归一值所起的作用。
那么我们就可以通过手动定义这两个参数的值,从而去改变相关性算分。
只能在创建index的时候定义字段的similarity ,在后续,可以通过关闭索引,更新索引设置,开启索引这个过程进行更新 my_bm25 的 参数值。这样可以无须重建索引又能试验不同的相似度算法配置。
PUT /blogs_index
{"settings": {"similarity": {"my_bm25": {"type": "BM25","b": 0.8,"k1": 1.5}}},"mappings": {"dynamic": false,"properties": {"title": {"type": "text","analyzer": "ik_smart","similarity": "my_bm25"},"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}
}参考文献
[1]. https://www.cnblogs.com/geeks-reign/p/Okapi_BM25.html
[2]. Okapi BM25: a non-binary model
[3]. ES系列13:彻底掌握相关度:从TF-IDF、BM25到对相关度的控制