*马明华 微软主管研究员
2021年CCF国际AIOps挑战赛程序委员会主席(第四届)
2021年博士毕业于清华大学,2020年在佐治亚理工学院做访问学者。主要研究方向是智能运维(AIOps)、软件可靠性。近年来在ICSE、FSE、ATC、EuroSys、VLDB、KDD、WebConf等软件工程、操作系统、数据库等领域发表30余篇论文,获得2018年软件可靠性工程ISSRE最佳论文奖。
分享论文:
Automatic Root Cause Analysis via Large Language Models for Cloud Incidents(EuroSys 2024)
基于大语言模型的云故障根因分析
本文为微软主管研究员马明华博士在2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会论文闪电分享环节的演讲内容整理而成。
很荣幸今天能在这里和大家分享我们在微软的一个研究工作:RCAssistant,一个帮助运维工程师进行故障根因诊断的助手。
背景介绍
随着云服务的快速发展,系统变得越来越复杂,故障的发生频率也随之增加,这对我们的生产生活造成了很大的影响,因此在故障发生之后需要工作人员迅速而准确地做出运维决策,而根因诊断正是其中非常重要的一个步骤。
现在的云服务系统是错综复杂的,比如微软的云服务系统是一个包含了很多子系统的庞大系统。运维人员在这样一个复杂系统产生的海量的数据中做根因诊断是非常困难的。所以我们提出一个根因诊断助手的设想,帮助运维工程师快速地进行根因诊断。我们设计的目标是使其能够自动系统中收集必要的信息,并利用大语言模型分析和诊断故障根因,提升诊断的效率和准确性。
架构介绍
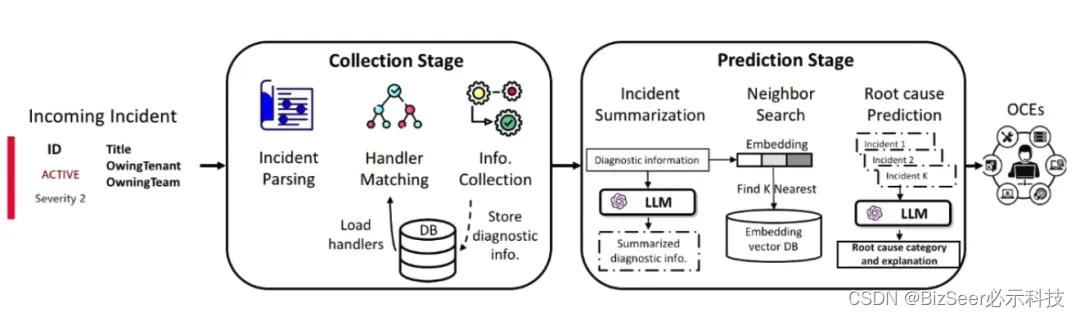
系统的整体架构包括两个部分,首先是数据采集阶段,然后是根因预测阶段。
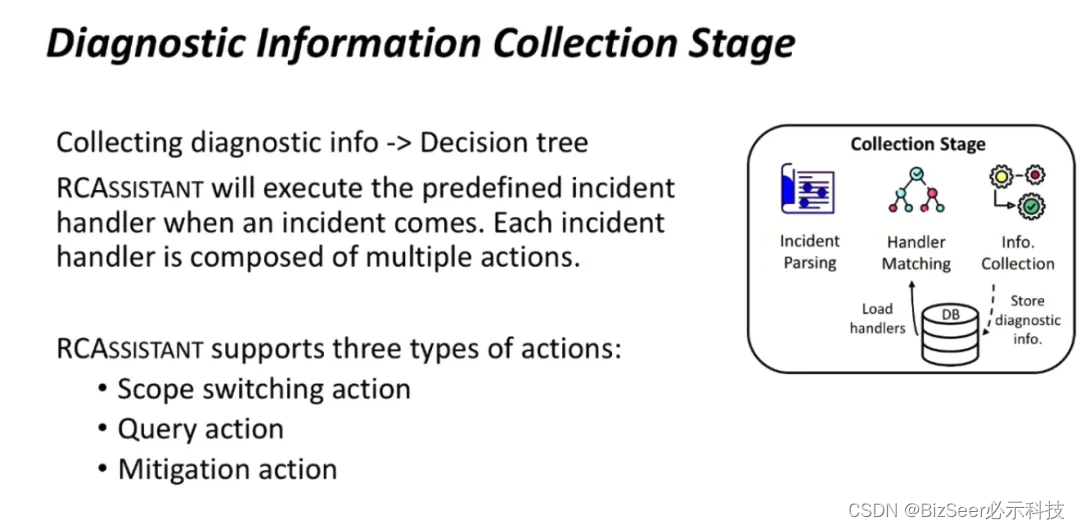
根据我们对实际数据的观察,发现了系统的两个特点:系统的故障会以不同的告警类型体现出来,属于同一告警类型的故障有相似的数据需求和诊断流程;单一来源的数据不足以进行故障诊断,分析故障需要多种来源的数据。
针对系统的特点,我们设计了一个专家系统式的数据采集工具,为不同的告警类型设计对应的处理模块来收集和分析多种来源的数据,并且我们通过在每个处理模块内部以决策树的形式排列一系列可复用的操作的形式来模拟运维工程师在实际操作时的决策过程。
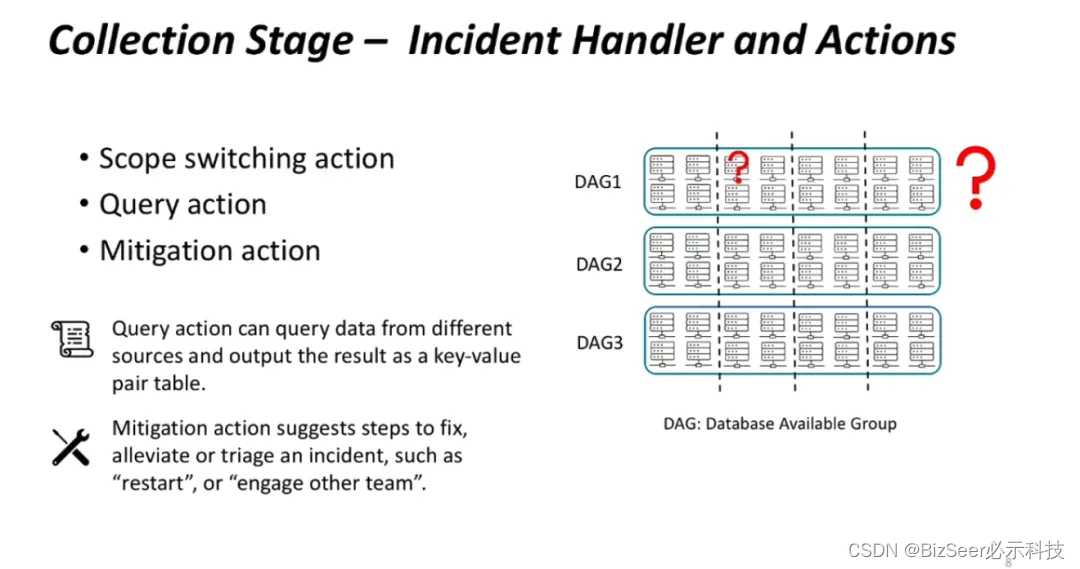
处理模块中的操作分为三种类型。首先是单元切换操作,在云服务系统中,从物理层或从逻辑层可以分成多个单元。其中单元切换操作可以根据故障的特点切换检测的单元,收集故障诊断需要的对应数据。其次是查询操作,它在发生故障之后检查系统的运行状态和特征,进而得到一些反馈结果。最后是修复操作,它能根据系统现状提供一些修复建议,比如快速重启系统,减轻故障对系统的影响。
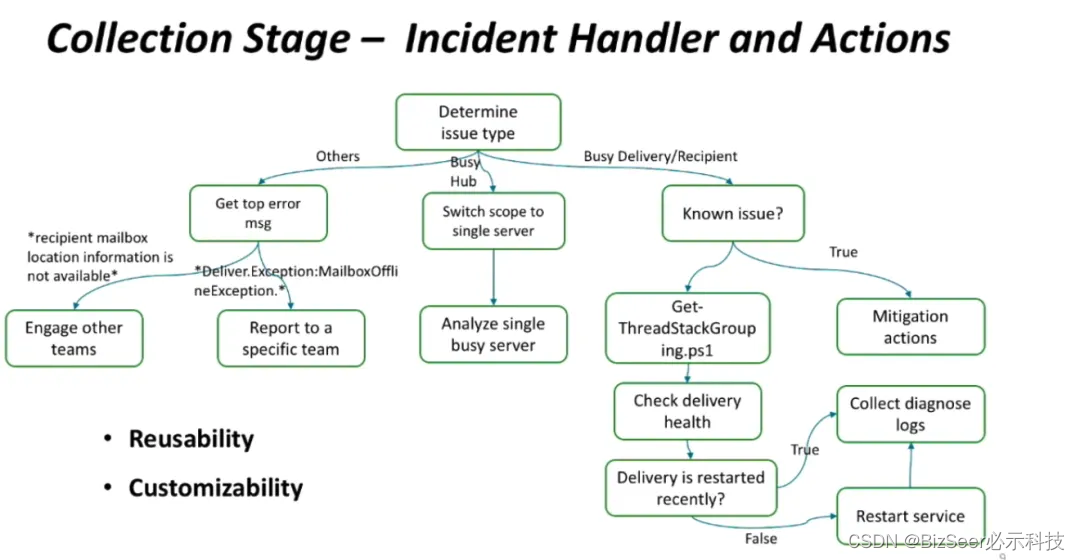
上图是一个处理模块的例子,展示了对故障相关信息进行收集和分析的决策树。我们希望处理模块中的操作是可复用的,并且可以根据不同团队的需求进行自定义。

接下来介绍第二个阶段,即使用大语言模型的根因预测阶段。在这个阶段我们设计的目标是可以预测出一个故障根因的具体类别,并且以运维工程师可以理解的自然语言的形式给出相应的解释。

在这部分我们设计了一些基于思维链的提示词,在输入中提供一些历史故障和诊断信息的例子,向模型展示如何分析故障信息。
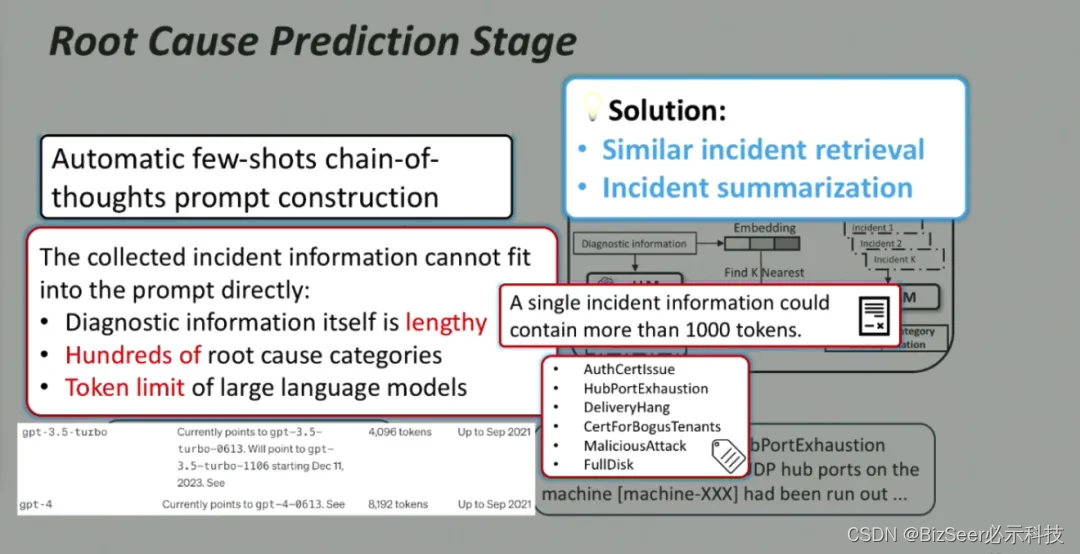
由于大模型有输入长度限制,但是故障的上下文需要包含故障发生时和历史上的相关信息,完全超过了现有模型的输入长度限制,无法在提示词中直接嵌入故障的上下文。
针对这一问题,我们设计了两个解决方案,一是查找历史上相似的故障,二是总结故障的上下文信息。

在获取历史上相似故障的阶段,我们采用的方法和运维工程师的实践经验是一致的:系统发生故障时,首先搜索历史上是否已经发生过相似的故障,之前的解决方案是什么,当前的故障是否可以使用类似的解决方案。现在我们也是让大模型按照这个思路执行,查找历史上相似的故障和解决方案,借鉴历史上的处理经验。
在如何寻找历史上相似故障方面,我们还有一个基于数据的发现,即在故障发生之后,很多故障会在短时间内重现的,为了减轻这一现象的影响,我们在计算相似度的时候引入了时间加权。

在设计整体的相似度的公式时,我们既考虑了历史故障的文本相似度,在这里使用的文本嵌入工具是fastText,也考虑了时间加权的影响。

上图展示了对当前故障以及历史上相似故障的上下文进行的总结。在这部分我们充分利用了大模型的能力,并且总结的效果达到了运维工程师预期。

简单来说,我们的工作,RCAssistant,就是让大语言模型根据当前的故障信息去寻找历史上出现的最相似的故障,然后给出对当前故障的分类和解释。
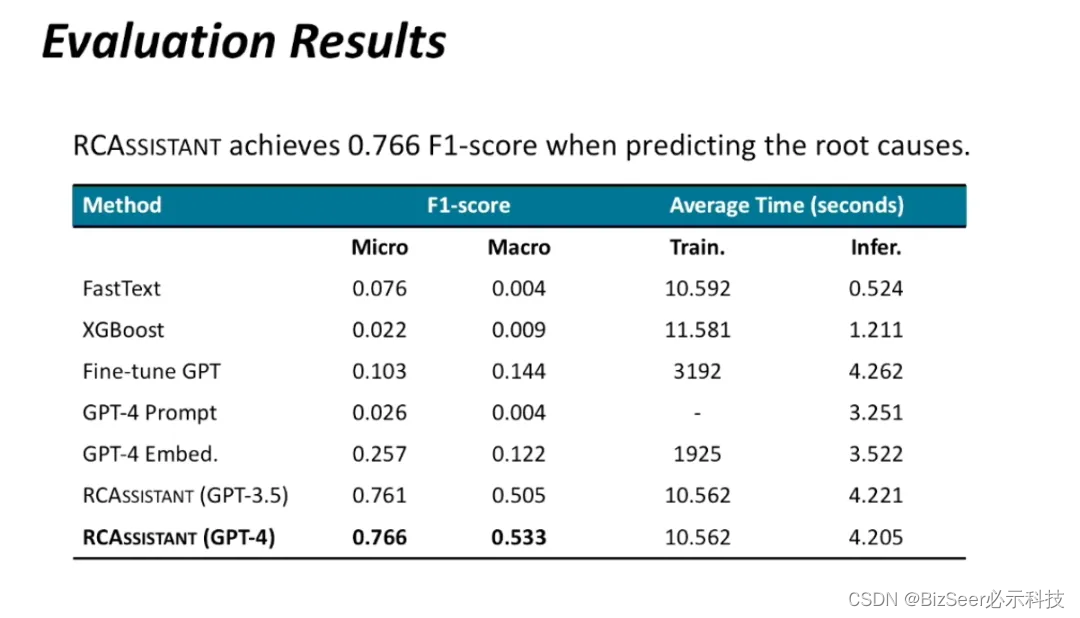
我们使用了来自微软的真实数据集进行对比试验,这个数据集收集了微软内部系统超过一年的故障信息。实验表明我们提出的方法明显优于对比的基准方法,并且不需要过高的推理时间。
总 结

我们提出的RCAssistant,提供了一种端到端的故障根因诊断的解决方案,首先是对故障相关的上下文信息进行采集,然后利用大语言模型来预测它的根因类别并给出解释。并且目前这套系统已经在微软的一些系统上做了部署得到满意的结果。
完整演讲视频,请关注CCF OpenAIOps社区视频号