传奇开心果博文系列
- 系列博文目录
- Python自动化办公库技术点案例示例系列
- 博文目录
- 前言
- 一、重要作用解说
- 二、Python操作Excel的常用库介绍
- 三、数据处理和分析示例代码
- 四、自动化报表生成示例代码
- 五、数据导入和导出示例代码
- 六、数据可视化示例代码
- 八、数据校验和清洗示例代码
- 九、自动化数据处理示例代码
- 十、数据导入数据库示例代码
- 十一、xlrd库使用方法示例代码
- 十二、xlwt使用方法示例代码
- 十三、openpyxl使用方法示例代码
- 十四、pandas使用方法示例代码
- 十五、xlutils使用方法示例代码
- 十六、pyxlsb使用方法示例代码
- 十七、xlsxwriter使用方法示例代码
- 十八、pyexcel和pyexcel-xls使用方法示例代码
- 十九、归纳总结
系列博文目录
Python自动化办公库技术点案例示例系列
博文目录
前言
Python库操作Excel为数据处理、分析和报表生成提供了便利,使得数据的处理和分析变得更加高效和灵活。无论是个人使用还是在企业中的数据处理和报表生成,Python库操作Excel都是非常有用的工具。
一、重要作用解说


Python库操作Excel的重要作用主要有以下几个方面:
-
数据处理和分析:Excel是广泛的数据存储和处理工具,通过库操作Excel文件,可以方便地读取、处理和分析数据。你可以Python库来提取、转换、清洗和整理Excel中的数据,进行统计分析、计算和可视化等操作。
-
自动化报表生成:通过Python库操作Excel文件,可以自动化生成报表。你可以编写脚本来读取数据源,根据特定的逻辑和规则生成报表,并将结果写入到Excel文件中。这样可以节省大量手动操作的时间和精力。
-
数据导入和导出:Python库操作Excel可以方便地实现数据的导入和导出。你可以将数据从其他数据源(如数据库、CSV文件等)导入到Excel中,或者将Excel中的数据导出到其他格式(如CSV、JSON等)进行进一步处理和使用。
-
数据可视化:Python库操作Excel还可以用于数据可视化。你可以将数据从Excel中读取到Python中,然后使用各种数据可视化库(如Matplotlib、Seaborn等)对数据进行可视化展示,生成图表、图形和报表等。
-
数据交互:通过Python库操作Excel,可以实现数据的交互。你可以读取Excel中的数据,并#将其用于其他的数据处理、分析或者机器学习的任务中。同时,你也可以将处理过的数据写回到Excel文件中,以便后续的使用和共享。
-
数据校验和清洗:Excel文件中的数据可能存在格式错误、重复值、缺失值等问题,通过Python库操作Excel,可以进行数据校验和清洗。你可以使用库提供的功能来检查并修正数据的格式、删除重复值、填充缺失值等操作,从而保证数据的准确性和完整性。
-
自动化数据处理:使用Python库操作Excel,可以将繁琐的数据处理任务自动化。你可以编写脚本来读取、处理和写入Excel文件,避免手动操作的重复性劳动,提高工作效率。
-
数据导入数据库:Python库操作Excel还可以将Excel中的数据导入到数据库中。你可以使用库提供的功能将Excel中的数据读取到Python中,然后再将数据插入到数据库中,实现数据的持久化存储和管理。
总的来说,Python库操作Excel为数据处理、分析、报表生成和数据交互提供了强大的工具和功能。无论是个人使用还是在企业中的数据管理和处理,Python库操作Excel都能够发挥重要的作用。
二、Python操作Excel的常用库介绍


Python有多个库可以用于操作Excel文件,其中比较常用的包括:xlrd、xlwt、openpyxl和pandas。
-
xlrd:这个库用于读取Excel文件,可以提取Excel文件中的数据和元数据。它支持.xls格式的Excel文件,但不支持.xlsx格式。
-
xlwt:与xlrd相对应,xlwt库用于写入Excel文件。它可以创建新的Excel文件,添加数据、格式和样式,并保存为.xls格式。
-
openpyxl:这是一个功能强大的库,可以读取和写入Excel文件。它支持最新的.xlsx格式,并提供了许多操作Excel文件的功能,如读取数据、写入数据、修改样式和格式等。
-
pandas:pandas是一个数据分析和处理的强大库,也可以用于操作Excel文件。它提供了DataFrame对象,可以方便地读取、写入和处理Excel数据。使用pandas可以轻松地进行数据筛选、排序、分组等操作。
-
xlutils:这个库是基于xlrd和xlwt的扩展,提供了一些额外的功能,如复制工作表、合并工作簿等。
-
pyxlsb:这个库用于读取和写入Excel二进制文件(.xlsb格式),适用于处理大型Excel文件。
-
xlsxwriter:这个库专注于创建和写入.xlsx格式的Excel文件,并提供了丰富的功能,如设置单元格样式、插入图表等。
-
pyexcel和pyexcel-xls:这些库提供了简单易用的接口,用于读取和写入Excel文件,支持多种格式(包括.xls和.xlsx)。
根据具体的需求和使用场景,你可以选择适合的库来操作Excel文件。无论是读取数据、写入数据还是进行数据处理和分析,这些库都为你提供了不同的选择和灵活性。这些库都提供了简单而灵活的接口,使得Excel操作变得容易。
三、数据处理和分析示例代码

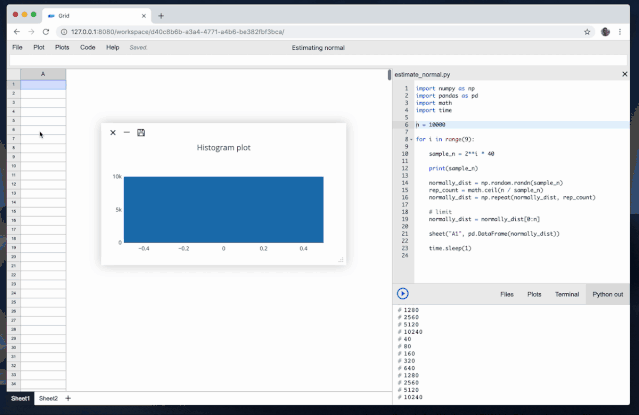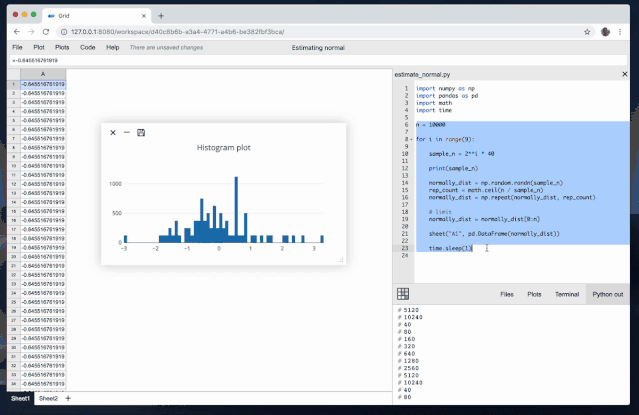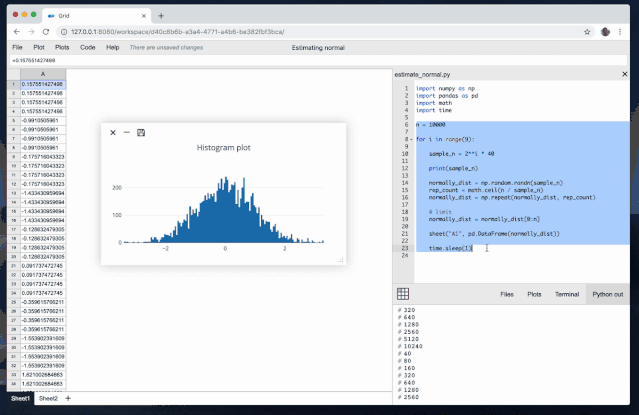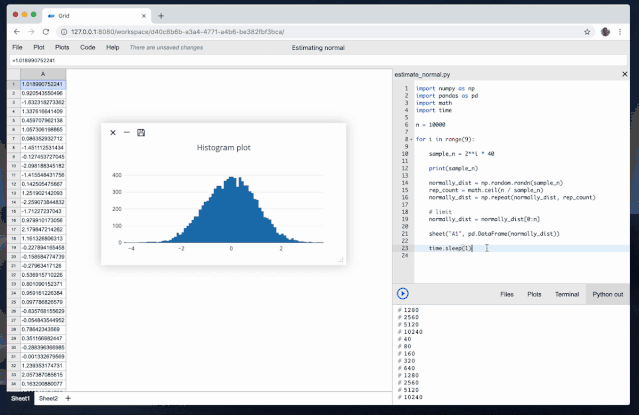
当使用Python库来操作Excel文件时,可以通过以下示例代码展示数据处理和分析的一些常见操作:
- 读取Excel文件:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 打印数据
print(data.head())
- 数据清洗与转换:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 删除重复行
data = data.drop_duplicates()# 处理缺失值
data = data.fillna(0)# 转换数据类型
data['列名'] = data['列名'].astype(int)# 打印数据
print(data.head())
- 统计分析与计算:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 统计描述性统计信息
summary = data.describe()# 计算列的和
total = data['列名'].sum()# 计算列的均值
mean = data['列名'].mean()# 打印结果
print(summary)
print("总和:", total)
print("均值:", mean)
- 数据可视化:
import pandas as pd
import matplotlib.pyplot as plt# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 绘制柱状图
plt.bar(data['列名'], data['列名'])
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
plt.title('柱状图')# 显示图形
plt.show()
以上示例代码展示了使用Python库来操作Excel文件进行数据处理和分析的一些常见操作。根据具体的需求,你可以结合具体的库和函数,进行更复杂的数据操作和分析。
四、自动化报表生成示例代码
通过Python库操作Excel文件,可以实现自动化报表生成,节省手动操作的时间和精力。以下是一个示例代码,展示如何读取数据源,根据特定的逻辑和规则生成报表,并将结果写入Excel文件中:
import pandas as pd# 读取数据源
data = pd.read_csv('data.csv')# 根据逻辑和规则生成报表
report_data = data.groupby('category')['sales'].sum()# 创建Excel文件并写入报表数据
writer = pd.ExcelWriter('report.xlsx', engine='xlsxwriter')
report_data.to_excel(writer, sheet_name='Report', startrow=1)# 设置报表样式
workbook = writer.book
worksheet = writer.sheets['Report']
header_format = workbook.add_format({'bold': True, 'border': True, 'bg_color': '#F0F0F0'})
worksheet.write('A1', 'Category', header_format)
worksheet.write('B1', 'Total Sales', header_format)# 保存Excel文件
writer.save()
上述示例代码中,首先使用pandas库读取数据源(这里以CSV文件为例),然后根据特定的逻辑和规则生成报表数据(这里使用groupby函数对category列进行分组并计算销售总额),接着创建一个Excel文件,并使用to_excel方法将报表数据写入到Excel文件中的指定工作表(这里指定为名为"Report"的工作表)。
接下来,使用xlsxwriter库对Excel文件进行进一步的处理,例如设置报表标题和样式。最后,使用writer.save()方法保存Excel文件。
通过编写类似的脚本,你可以根据实际需求读取不同的数据源,进行复杂的数据处理和计算,生成各种形式的报表,并将结果自动化地写入到Excel文件中。这样可以大大提高报表生成的效率和准确性。
五、数据导入和导出示例代码

通过Python库操作Excel文件,可以方便地实现数据的导入和导出。以下是一些示例代码,展示如何将数据从其他数据源导入到Excel中,或者将Excel中的数据导出到其他格式进行进一步处理和使用:
- 将数据从CSV文件导入到Excel中:
import pandas as pd# 读取CSV文件data = pd.read_csv('data.csv')# 将数据写入Excel文件
data.to_excel('output.xlsx', index=False)
- 将数据从Excel导出为CSV文件:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx')# 将数据写入CSV文件
data.to_csv('output.csv', index=False)
- 将数据从数据库导入到Excel中:
import pandas as pd
import sqlite3# 连接数据库
conn = sqlite3.connect('database.db')# 查询数据
query = "SELECT * FROM table"
data = pd.read_sql(query, conn)# 将数据写入Excel文件
data.to_excel('output.xlsx', index=False)# 关闭数据库连接
conn.close()
- 将数据从Excel导出为JSON文件:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx')# 将数据写入JSON文件
data.to_json('output.json', orient='records')
通过使用不同的Python库(如pandas、xlrd、openpyxl等),你可以根据不同的数据源和需求,将数据方便地导入到Excel中或从Excel导出到其他格式。这样可以实现数据的灵活处理和交互,满足不同场景下的数据需求。
六、数据可视化示例代码
通过Python库操作Excel文件,可以将数据读取到Python中,并使用各种数据可视化库对数据进行可视化展示。以下是一个示例代码,展示如何读取Excel中的数据,并使用Matplotlib库进行数据可视化:
import pandas as pd
import matplotlib.pyplot as plt# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 绘制折线图
plt.plot(data['日期'], data['销售额'])
plt.xlabel('日期')
plt.ylabel('销售额')
plt.title('销售额趋势图')# 显示图形
plt.show()
上述示例代码中,首先使用pandas库读取Excel文件中的数据(这里以名为"Sheet1"的工作表为例),然后使用matplotlib.pyplot库绘制折线图。在这个示例中,我们假设Excel文件中有两列数据,分别是日期和销售额。通过plt.plot函数将日期作为横轴,销售额作为纵轴绘制折线图,然后使用plt.xlabel、plt.ylabel和plt.title函数设置图表的标签和标题。
通过类似的方式,你可以根据具体的需求和数据类型,使用不同的数据可视化库(如Seaborn、Plotly等)进行更丰富的数据可视化展示。你可以绘制柱状图、饼图、散点图、热力图等,根据数据的特点和目标,选择合适的图表类型进行展示。这样可以更直观地呈现数据,帮助理解和分析数据,以及生成图表、图形和报表等。##七、数据交互示例代码
是的,通过Python库操作Excel,可以实现数据的交互。你可以读取Excel中的数据,并将其用于其他的数据处理、分析或者机器学习的任务中。同时,你也可以将处理过的数据写回到Excel文件中,以便后续的使用和共享。

以下是一个示例代码,展示如何读取Excel中的数据,并将其用于数据处理的任务中:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 数据处理
# ...# 将处理后的数据写回到Excel文件中
data.to_excel('processed_data.xlsx', index=False)
上述示例代码中,首先使用pandas库读取Excel文件中的数据(这里以名为"Sheet1"的工作表为例)。然后,你可以根据具体的需求对数据进行处理、分析或者机器学习的任务。在这个示例中,我们省略了具体的数据处理部分。
最后,使用to_excel方法将处理后的数据写回到Excel文件中。在这个示例中,我们将数据写入了一个名为"processed_data.xlsx"的新Excel文件中。你可以根据实际需求指定不同的文件名和路径。
通过类似的方式,你可以根据具体的数据处理任务,读取Excel中的数据,并将其用于其他的数据处理、分析或者机器学习的任务中。处理后的数据也可以通过Python库写回到Excel文件中,方便后续的使用和共享。这样可以实现数据的交互,提高数据处理的效率和灵活性。
八、数据校验和清洗示例代码

通过Python库操作Excel文件,可以进行数据校验和清洗,以确保数据的准确性和完整性。以下是一些示例代码,展示如何使用Python库进行数据校验和清洗:
- 检查并修正数据格式:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 检查数据格式
data['列名'] = pd.to_numeric(data['列名'], errors='coerce')# 打印错误的数据行
print(data[data['列名'].isnull()])# 修正数据格式
data['列名'] = data['列名'].fillna(0).astype(int)# 打印数据
print(data.head())
- 删除重复值:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 删除重复行
data = data.drop_duplicates()# 打印数据
print(data.head())
- 填充缺失值:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 填充缺失值
data = data.fillna(0)# 打印数据
print(data.head())
在上述示例代码中,首先使用pandas库读取Excel文件中的数据(这里以名为"Sheet1"的工作表为例)。然后,根据具体的需求进行数据校验和清洗操作。
在第一个示例中,我们使用pd.to_numeric函数将特定列的数据转换为数字格式,通过errors='coerce'参数将无法转换的数据设为缺失值。然后,打印出含有错误数据的行,并修正数据格式。
在第二个示例中,我们使用drop_duplicates方法删除重复的行。
在第三个示例中,我们使用fillna方法将缺失值填充为指定的值(这里填充为0)。
通过类似的方式,你可以根据具体的数据校验和清洗需求,使用Python库操作Excel文件进行数据处理。根据不同的情况,你可以使用不同的函数和方法来检查并修正数据的格式、删除重复值、填充缺失值等,以确保数据的准确性和完整性。
九、自动化数据处理示例代码
通过Python库操作Excel文件,可以实现自动化的数据处理任务。你可以编写脚本来读取、处理和写入Excel文件,避免手动操作的重复性劳动,提高工作效率。
以下是一个示例代码,展示如何使用Python库自动化数据处理任务:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 数据处理
# ...# 将处理后的数据写回到Excel文件中
data.to_excel('processed_data.xlsx', index=False)
在上述示例代码中,首先使用pandas库读取Excel文件中的数据(这里以名为"Sheet1"的工作表为例)。然后,你可以根据具体的需求对数据进行处理。在这个示例中,我们省略了具体的数据处理部分。
最后,使用to_excel方法将处理后的数据写回到Excel文件中。在这个示例中,我们将数据写入了一个名为"processed_data.xlsx"的新Excel文件中。你可以根据实际需求指定不同的文件名和路径。
通过编写类似的脚本,你可以根据实际需求读取不同的Excel文件,进行复杂的数据处理和计算,然后将结果自动化地写入到Excel文件中。这样可以大大提高数据处理的效率和准确性,避免手动操作的重复性劳动。同时,你可以根据需要将脚本进行定时任务的调度,实现数据处理任务的自动化执行。
十、数据导入数据库示例代码

通过Python库操作Excel文件,可以将Excel中的数据导入到数据库中,实现数据的持久化存储和管理。以下是一个示例代码,展示如何将Excel中的数据导入到数据库中:
import pandas as pd
import sqlite3# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 连接数据库
conn = sqlite3.connect('database.db')# 将数据写入数据库表
data.to_sql('table_name', conn, if_exists='replace', index=False)# 关闭数据库连接
conn.close()
在上述示例代码中,首先使用pandas库读取Excel文件中的数据(这里以名为"Sheet1"的工作表为例)。然后,使用sqlite3库建立与数据库的连接。
接下来,使用to_sql方法将数据写入到数据库表中。在这个示例中,我们将数据写入到名为"table_name"的数据库表中。如果该表已经存在,我们使用if_exists='replace'参数来替换原有的表。你可以根据实际需求指定不同的表名和数据库操作。
最后,使用close方法关闭数据库连接。
通过类似的方式,你可以根据具体的需求读取Excel中的数据,并将其导入到不同类型的数据库中(如SQLite、MySQL、PostgreSQL等)。这样可以实现数据的持久化存储和管理,方便后续的数据处理、查询和分析。同时,你也可以根据需要在数据库中进行数据清洗、转换和计算等操作,以满足不同的业务需求。
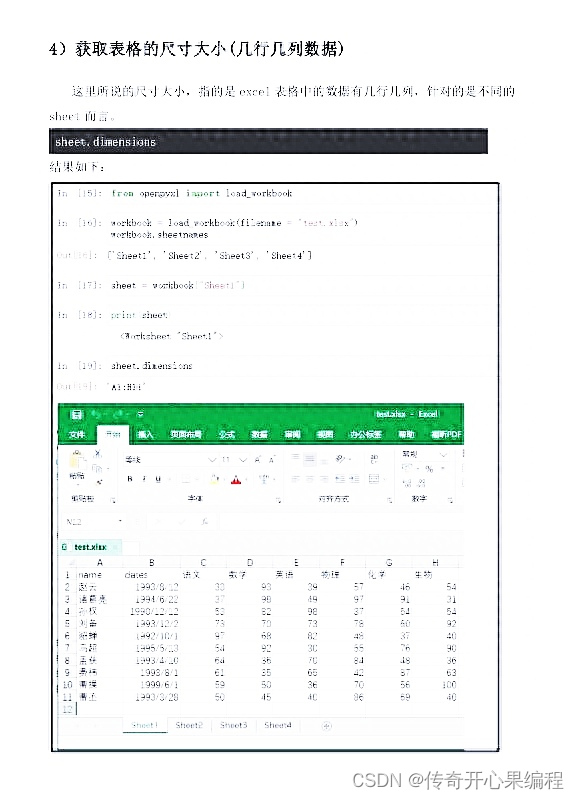
十一、xlrd库使用方法示例代码

xlrd是一个Python库,用于读取Excel文件。它可以提取.xls格式的Excel文件中的数据和元数据,但不支持.xlsx格式。
以下是一个使用xlrd库读取Excel文件的示例代码:
import xlrd# 打开Excel文件
workbook = xlrd.open_workbook('data.xls')# 获取所有工作表名称
sheet_names = workbook.sheet_names()
print(sheet_names)# 根据工作表名称获取工作表对象
worksheet = workbook.sheet_by_name('Sheet1')# 获取工作表的行数和列数
num_rows = worksheet.nrows
num_cols = worksheet.ncols
print(f"总行数:{num_rows},总列数:{num_cols}")# 遍历每一行数据
for row_index in range(num_rows):row_data = worksheet.row_values(row_index)print(row_data)
上述示例代码首先使用xlrd.open_workbook函数打开一个名为"data.xls"的Excel文件。然后,通过sheet_names方法获取所有工作表的名称,并打印出来。
接下来,通过sheet_by_name方法根据工作表的名称获取工作表对象(这里以名为"Sheet1"的工作表为例)。使用nrows和ncols属性可以获取工作表的行数和列数,并打印出来。
最后,通过遍历每一行数据的方式,使用row_values方法获取每一行的数据,并打印出来。
需要注意的是,xlrd库只支持读取.xls格式的Excel文件,对于.xlsx格式的Excel文件,你可以考虑使用其他的库,如openpyxl或pandas。
十二、xlwt使用方法示例代码
xlwt是一个Python库,用于写入Excel文件。它可以创建的Excel文件,添加数据、格式和样式,并保存为.xls格式。
以下是一个使用xlwt库写入Excel文件的示例代码:
import xlwt# 创建一个新的Excel文件
workbook = xlwt.Workbook()# 创建一个工作表
worksheet = workbook.add_sheet('Sheet1')# 写入数据
worksheet.write(0, 0, 'Hello')
worksheet.write(0, 1, 'World')# 设置单元格样式
style = xlwt.XFStyle()
font = xlwt.Font()
font.bold = True
style.font = font
worksheet.write(0, 0, 'Hello', style)# 保存Excel文件
workbook.save('output.xls')
上述示例代码首先使用xlwt.Workbook函数创建一个新的Excel文件。然后,使用add_sheet方法创建一个名为"Sheet1"的工作表。
接下来,使用write方法向工作表中写入数据。在这个示例中,我们在第一行第一列(索引为0)写入了"Hello",在第一行第二列(索引为1)写入了"World"。
然后,我们使用xlwt.XFStyle和xlwt.Font来设置单元格的样式。在这个示例中,我们将第一行第一列的单元格设置为粗体字体。
最后,使用save方法将Excel文件保存为名为"output.xls"的文件。
通过类似的方式,你可以使用xlwt库创建新的Excel文件,并根据需要添加数据、格式和样式。最后,使用save方法将Excel文件保存到指定路径。这样可以实现对Excel文件的写入操作。
十三、openpyxl使用方法示例代码

openpyxl是一个功能强大的Python库,用于读取和写入Excel文件。它支持最新的.xlsx格式,并提供了许多操作Excel文件的功能,如读取数据、写入数据、修改样式和格式等。
以下是一个使用openpyxl库读取和写入Excel文件的示例代码:
from openpyxl import load_workbook
from openpyxl.styles import Font, Alignment
from openpyxl.utils import get_column_letter# 读取Excel文件
workbook = load_workbook('data.xlsx')# 获取所有工作表名称
sheet_names = workbook.sheetnames
print(sheet_names)# 根据工作表名称获取工作表对象
worksheet = workbook['Sheet1']# 获取工作表的行数和列数
num_rows = worksheet.max_row
num_cols = worksheet.max_column
print(f"总行数:{num_rows},总列数:{num_cols}")# 遍历每一行数据
for row in worksheet.iter_rows(min_row=1, max_row=num_rows, min_col=1, max_col=num_cols):for cell in row:print(cell.value)# 写入数据
worksheet['A1'] = 'Hello'
worksheet['B1'] = 'World'# 设置单元格样式
font = Font(bold=True)
alignment = Alignment(horizontal='center', vertical='center')
worksheet['A1'].font = font
worksheet['A1'].alignment = alignment# 保存Excel文件
workbook.save('output.xlsx')
上述示例代码首先使用load_workbook函数从名为"data.xlsx"的Excel文件中加载工作簿对象。然后,通过sheetnames属性获取所有工作表的名称,并打印出来。
接下来,使用workbook['Sheet1']方式根据工作表的名称获取工作表对象(这里以名为"Sheet1"的工作表为例)。使用max_row和max_column属性可以获取工作表的行数和列数,并打印出来。
然后,使用iter_rows方法遍历每一行数据,并通过cell.value获取单元格的值。
接着,使用类似的方式向工作表中写入数据。在这个示例中,我们将"Hello"写入到A1单元格,将"World"写入到B1单元格。
最后,通过设置单元格的字体和对齐方式,实现单元格样式的修改。
通过类似的方式,你可以使用openpyxl库读取和写入Excel文件,并进行更多复杂的操作,如合并单元格、修改公式、设置筛选器等。openpyxl还提供了许多其他功能,如处理图表、保护工作表等,可以满足各种对Excel文件的操作需求。
十四、pandas使用方法示例代码

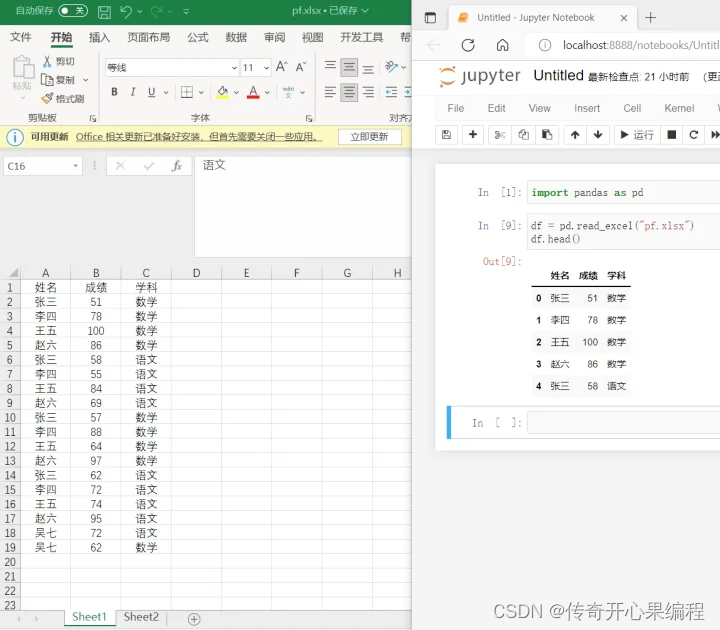
pandas是一个功能强大的数据分析和处理库,也可以用于操作Excel文件。它提供了DataFrame对象,方便地读取、写入和处理Excel数据。使用pandas可以轻松进行数据筛选、排序、分组等操作。
以下是一个使用pandas库读取和写入Excel文件的示例代码:
import pandas as pd# 读取Excel文件
data = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 打印数据的前几行
print(data.head())# 数据筛选
filtered_data = data[data['Column1'] > 10]# 数据排序
sorted_data = data.sort_values(by='Column2')# 数据分组和聚合
grouped_data = data.groupby('Column3').sum()# 写入数据到Excel文件
filtered_data.to_excel('filtered_data.xlsx', index=False)
在上述示例代码中,首先使用pd.read_excel函数读取名为"data.xlsx"的Excel文件中的数据(这里以名为"Sheet1"的工作表为例)。然后,使用head方法打印数据的前几行。
接下来,我们展示了一些常见的数据操作。通过使用类似data['Column1'] > 10的条件进行数据筛选,可以获取满足条件的子集数据。使用sort_values方法可以根据指定列的值对数据进行排序。使用groupby方法可以根据指定列对数据进行分组,并应用聚合函数(如sum)进行汇总计算。
最后,使用to_excel方法将筛选后的数据写入到名为"filtered_data.xlsx"的Excel文件中。通过设置index=False参数,可以避免将索引列写入到Excel文件中。
pandas库提供了丰富的数据操作和处理功能,包括数据清洗、转换、透视表等。它是进行数据分析和处理的重要工具,尤其适用于结构化数据的处理和分析。
十五、xlutils使用方法示例代码
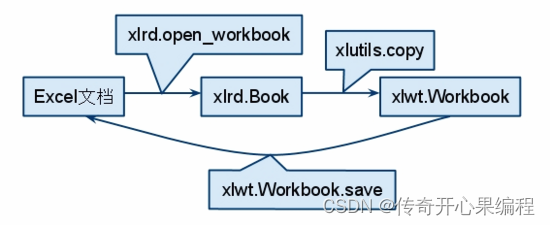
xlutils是一个基于xlrd和xlwt的扩展库,提供了一些额外的功能,如复制工作表、合并工作簿等。它可以在已有的Excel文件上进行操作,对现有的工作表进行复制、移动、修改等操作。
以下是一些xlutils库提供的常用功能示例:
- 复制工作表:可以使用
copy方法将一个工作表复制到同一工作簿中或不同的工作簿中。
import xlrd
import xlwt
from xlutils.copy import copy# 读取Excel文件
workbook = xlrd.open_workbook('data.xls')
# 创建一个可写的副本
workbook_copy = copy(workbook)
# 获取要复制的工作表
worksheet = workbook.sheet_by_name('Sheet1')
# 在副本中创建一个新的工作表,并复制数据
worksheet_copy = workbook_copy.add_sheet('Sheet1_copy')
for row in range(worksheet.nrows):for col in range(worksheet.ncols):worksheet_copy.write(row, col, worksheet.cell_value(row, col))
# 保存副本
workbook_copy.save('data_copy.xls')
- 合并工作簿:可以使用
copy方法将多个工作簿中的工作表合并为一个新的工作簿。
import xlrd
import xlwt
from xlutils.copy import copy# 打开要合并的工作簿1
workbook1 = xlrd.open_workbook('data1.xls')
# 打开要合并的工作簿2
workbook2 = xlrd.open_workbook('data2.xls')# 创建一个新的工作簿
merged_workbook = xlwt.Workbook()# 合并工作表
for sheet in workbook1.sheets():worksheet_copy = merged_workbook.add_sheet(sheet.name)for row in range(sheet.nrows):for col in range(sheet.ncols):worksheet_copy.write(row, col, sheet.cell_value(row, col))for sheet in workbook2.sheets():worksheet_copy = merged_workbook.add_sheet(sheet.name)for row in range(sheet.nrows):for col in range(sheet.ncols):worksheet_copy.write(row, col, sheet.cell_value(row, col))# 保存合并后的工作簿
merged_workbook.save('merged_data.xls')
xlutils库提供了一些方便的方法来操作Excel文件,通过结合xlrd和xlwt的功能,可以实现更多高级的操作,如复制工作表、合并工作簿等。这使得处理Excel文件变得更加灵活和便捷。
十六、pyxlsb使用方法示例代码

pyxlsb是一个用于读取和写入Excel二进制文件(.xlsb格式)的库。相比于传统的.xls或.xlsx格式,.xlsb是一种二进制格式,适用于处理大型Excel文件。
以下是一个使用pyxlsb库读取和写入Excel二进制文件的示例代码:
from pyxlsb import open_workbook# 读取Excel二进制文件
with open_workbook('data.xlsb') as wb:# 获取所有工作表的名称sheet_names = wb.sheetsprint(sheet_names)# 读取指定工作表中的数据with wb.get_sheet(0) as sheet:for row in sheet.rows():values = [item.v for item in row]print(values)# 写入Excel二进制文件
from pyxlsb import Workbook# 创建一个新的工作簿
with Workbook('output.xlsb') as wb:# 创建一个工作表with wb.new_sheet('Sheet1') as sheet:# 写入数据sheet.append(['Hello', 'World'])
在上述示例代码中,首先使用open_workbook函数读取名为"data.xlsb"的Excel二进制文件。通过访问sheets属性可以获取到所有工作表的名称。然后,使用get_sheet方法获取指定工作表的数据,并遍历每一行数据。
接下来,展示了如何使用pyxlsb库进行Excel二进制文件的写入操作。首先使用Workbook函数创建一个新的工作簿对象。然后,使用new_sheet方法创建一个名为"Sheet1"的工作表,并使用append方法向工作表中写入数据。
pyxlsb库提供了读取和写入Excel二进制文件的功能,适用于处理大型Excel文件。通过这个库,你可以灵活地操作Excel二进制文件,读取数据、写入数据等操作变得更加高效和便捷。
十七、xlsxwriter使用方法示例代码
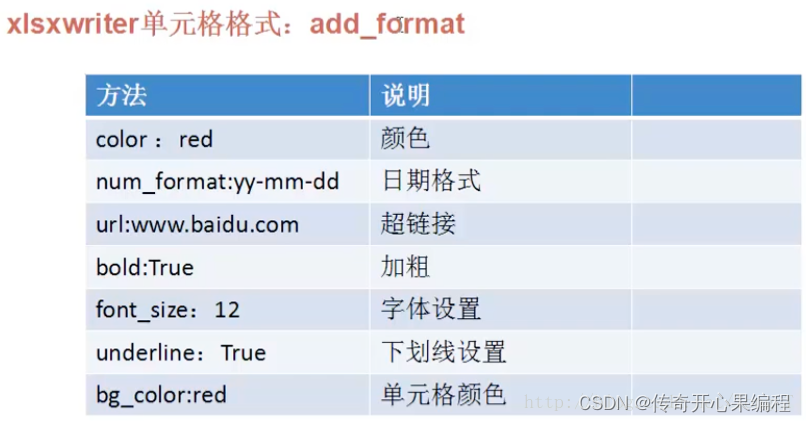
xlsxwriter是一个专注于创建和写入.xlsx格式的Excel文件的库。它提供了丰富的功能,如设置单元格样式、插入图表、添加公式等。
以下是一个使用xlsxwriter库创建和写入.xlsx格式的Excel文件的示例代码:
import xlsxwriter# 创建一个新的Excel文件
workbook = xlsxwriter.Workbook('output.xlsx')# 添加一个工作表
worksheet = workbook.add_worksheet('Sheet1')# 设置单元格样式
bold = workbook.add_format({'bold': True})
currency_format = workbook.add_format({'num_format': '$#,##0'})# 写入数据和样式
worksheet.write('A1', 'Item', bold)
worksheet.write('B1', 'Price', bold)
worksheet.write('A2', 'Apple')
worksheet.write('B2', 0.99, currency_format)
worksheet.write('A3', 'Banana')
worksheet.write('B3', 1.25, currency_format)# 插入图表
chart = workbook.add_chart({'type': 'column'})
chart.add_series({'values': '=Sheet1!$B$2:$B$3'})
worksheet.insert_chart('D2', chart)# 关闭工作簿
workbook.close()
在上述示例代码中,首先使用xlsxwriter.Workbook函数创建一个新的Excel文件,命名为"output.xlsx"。
然后,使用add_worksheet方法添加一个名为"Sheet1"的工作表。
接下来,使用add_format方法创建一些单元格样式,如加粗字体和货币格式。
然后,使用write方法向指定的单元格写入数据和样式。例如,将"Item"和"Price"分别写入到A1和B1单元格,并应用加粗字体样式。将"Apple"和0.99写入到A2和B2单元格,并应用货币格式。将"Banana"和1.25写入到A3和B3单元格。
接着,使用add_chart方法创建一个柱状图,并使用add_series方法设置图表的数据源范围。最后,使用insert_chart方法将图表插入到D2单元格。
最后,使用workbook.close方法关闭工作簿,完成Excel文件的创建和写入。
通过使用xlsxwriter库,你可以轻松地创建和写入.xlsx格式的Excel文件,并应用丰富的功能和样式。这使得生成具有专业外观和复杂数据分析的Excel报表成为可能。
十八、pyexcel和pyexcel-xls使用方法示例代码

pyexcel和pyexcel-xls是两个简单易用的库,提供了读取和写入Excel文件的接口,并支持多种格式,包括.xls和.xlsx。
下面是使用pyexcel和pyexcel-xls库进行读取和写入Excel文件的示例代码:
import pyexcel as pe# 读取Excel文件
data = pe.get_array(file_name='data.xlsx')
# 打印数据
print(data)# 写入Excel文件
data = [["Item", "Price"],["Apple", 0.99],["Banana", 1.25]
]
sheet = pe.Sheet(data)
sheet.save_as("output.xlsx")
在上述示例代码中,首先使用get_array函数从名为"data.xlsx"的Excel文件中读取数据,并将其存储在一个二维数组中。然后,使用print语句打印读取到的数据。
接下来,展示了如何使用pyexcel和pyexcel-xls库进行Excel文件的写入操作。首先创建一个二维数组data,表示要写入的数据。然后,使用Sheet类将数据转换为一个Sheet对象。最后,使用save_as方法将Sheet对象保存为名为"output.xlsx"的Excel文件。
pyexcel和pyexcel-xls库提供了简单易用的接口,使得读取和写入Excel文件变得非常方便。无论是.xls还是.xlsx格式的文件,你都可以使用这些库来处理Excel数据,进行数据导入、导出等操作。
十九、归纳总结

要灵活运用Python库操作Excel,可以考虑以下几个方面:
-
选择适合的库:根据具体需求和Excel文件格式选择合适的Python库。例如,xlrd和xlwt适用于.xls格式,openpyxl适用于.xlsx格式,pandas可以处理多种格式。了解每个库的功能和特点,选择最适合你的需求的库。
-
数据读取:使用库提供的读取方法,如xlrd的
open_workbook()、openpyxl的load_workbook()或pandas的read_excel(),来读取Excel文件中的数据。可以指定读取的工作表、行列范围等参数,灵活控制读取的数据。 -
数据写入:使用库提供的写入方法,如xlwt的
Workbook()、openpyxl的Workbook()或pandas的to_excel(),来创建新的Excel文件或向已有文件中写入数据。可以设置单元格样式、格式、公式等,以满足特定的需求。 -
数据处理:利用Python的数据处理和分析库(如pandas)对读取的Excel数据进行处理。可以进行数据筛选、排序、聚合、转换等操作,以及进行数据分析和可视化。
-
异常处理:在操作Excel时,要考虑到可能出现的异常情况,如文件不存在、工作表不存在、数据格式错误等。使用try-except语句来捕获和处理异常,保证程序的稳定性和可靠性。
-
优化性能:对于大型Excel文件或需要处理大量数据的情况,可以考虑优化性能。例如,使用迭代器遍历大型数据集,减少内存消耗;使用批量写入方法来提高写入速度等。
-
结合其他库和工具:Python有许多其他强大的库和工具,可以与Excel操作库结合使用,实现更复杂的功能。例如,结合图表库(如matplotlib)来生成图表并插入到Excel文件中;结合Web框架(如Flask)和数据库库来实现Excel文件的导入和导出等。
-
实践和尝试:通过实际的项目和练习,不断尝试和实践Python库操作Excel的技术。挑战自己,探索更多的用法和技巧,提高对库的熟练度和理解。



灵活运用Python库操作Excel需要结合具体场景和需求,根据需要选择合适的库和方法,并在实践中不断优化和提升。通过不断学习和实践,你将能够灵活应用Python库来处理各种Excel操作任务。