政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎机器学习
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文涵盖使用内置 API 进行训练和验证(如 Model.fit()、Model.evaluate() 和 Model.predict())时的训练、评估和预测(推理)模型。
一般来说,无论您是使用内置循环还是编写自己的循环,模型训练和评估在每种 Keras 模型中的工作方式都是严格相同的,包括顺序模型、使用功能 API 构建的模型以及通过模型子类化从头编写的模型。
本文作者政安晨使用Kaggle的线上环境进行实战演绎。
我线上选择的是CPU版本:

当我需要做训练的时候,点击右上角可以切换为GPU版本。
导入
# We import torch & TF so as to use torch Dataloaders & tf.data.Datasets.
import torch
import tensorflow as tfimport os
import numpy as np
import keras
from keras import layers
from keras import ops应用程序接口概述:第一个端到端示例
向模型的内置训练循环传递数据时,应使用:
* NumPy 数组(如果您的数据较小且适合在内存中使用)
* keras.utils.PyDataset 的子类
* tf.data.Dataset 对象
* PyTorch 数据加载器实例
在接下来的几段中,我们将使用 MNIST 数据集作为 NumPy 数组,以演示如何使用优化器、损失和度量。之后,我们将仔细研究其他选项。
让我们考虑下面的模型(在这里,我们使用函数式 API 构建模型,但它也可以是顺序模型或子类模型):
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)model = keras.Model(inputs=inputs, outputs=outputs)以下是典型的端到端工作流程,包括:
* 训练
* 在原始训练数据生成的保留集上进行验证
* 在测试数据上进行评估
在这个例子中,我们将使用 MNIST 数据。
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()# Preprocess the data (these are NumPy arrays)
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255y_train = y_train.astype("float32")
y_test = y_test.astype("float32")# Reserve 10,000 samples for validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]演绎如下:

我们指定训练配置(优化器、损失、指标):
model.compile(optimizer=keras.optimizers.RMSprop(), # Optimizer# Loss function to minimizeloss=keras.losses.SparseCategoricalCrossentropy(),# List of metrics to monitormetrics=[keras.metrics.SparseCategoricalAccuracy()],
)我们调用 fit(),它将把数据切成大小为 batch_size 的 "批次",并在给定的时间内反复迭代整个数据集,从而训练模型。
print("Fit model on training data")
history = model.fit(x_train,y_train,batch_size=64,epochs=2,# We pass some validation for# monitoring validation loss and metrics# at the end of each epochvalidation_data=(x_val, y_val),
)咱们将要训练时,按照刚才提到的,将Kaggle的环境从CPU改为GPU。
接下来继续我们的训练。
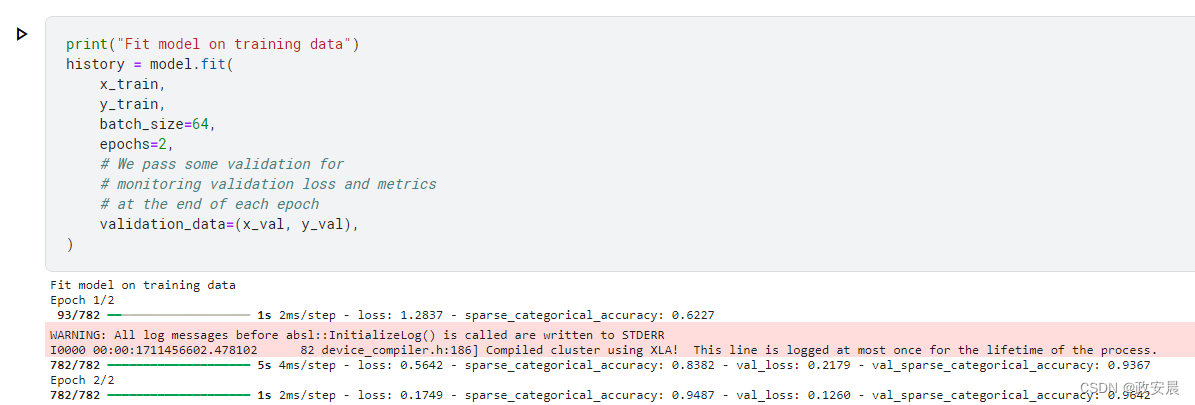
返回的历史对象记录了训练过程中的损失值和度量值:

我们通过 evaluate() 在测试数据上对模型进行评估:
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(x_test, y_test, batch_size=128)
print("test loss, test acc:", results)# Generate predictions (probabilities -- the output of the last layer)
# on new data using `predict`
print("Generate predictions for 3 samples")
predictions = model.predict(x_test[:3])
print("predictions shape:", predictions.shape)演绎如下:

现在,让我们来详细回顾一下这个工作流程的各个部分:
编译()方法:指定损失、度量和优化器
要使用 fit() 训练一个模型,需要指定一个损失函数、一个优化器,还可以选择一些监控指标。
您可以将这些参数作为编译()方法的参数传递给模型:
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[keras.metrics.SparseCategoricalAccuracy()],
)度量参数应该是一个列表--你的模型可以有任意数量的度量参数。
如果模型有多个输出,可以为每个输出指定不同的损耗和度量,还可以调节每个输出对模型总损耗的贡献。
请注意,如果您对默认设置感到满意,在许多情况下,可以通过字符串标识符来指定优化器、损耗和度量作为快捷方式:
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["sparse_categorical_accuracy"],
)为便于以后重用,让我们把模型定义和编译步骤放在函数中;我们将在本文的不同示例中多次调用它们。
def get_uncompiled_model():inputs = keras.Input(shape=(784,), name="digits")x = layers.Dense(64, activation="relu", name="dense_1")(inputs)x = layers.Dense(64, activation="relu", name="dense_2")(x)outputs = layers.Dense(10, activation="softmax", name="predictions")(x)model = keras.Model(inputs=inputs, outputs=outputs)return modeldef get_compiled_model():model = get_uncompiled_model()model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["sparse_categorical_accuracy"],)return modelKeras提供许多内置优化器、损耗和指标
一般来说,您不必从头开始创建自己的损失、度量或优化器,因为您需要的东西很可能已经是 Keras API 的一部分:
优化器:
SGD()(with or without momentum)RMSprop()Adam()- etc.
损失:
MeanSquaredError()KLDivergence()CosineSimilarity()- etc.
度量:
AUC()Precision()Recall()- etc.
定制损失
如果需要创建自定义损失,Keras 提供了三种方法。
第一种方法是创建一个接受输入 y_true 和 y_pred 的函数。下面的示例显示了一个计算真实数据与预测之间均方误差的损失函数:
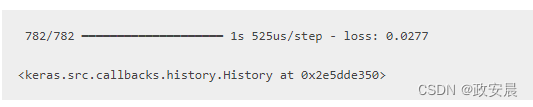
def custom_mean_squared_error(y_true, y_pred):return ops.mean(ops.square(y_true - y_pred), axis=-1)model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=custom_mean_squared_error)# We need to one-hot encode the labels to use MSE
y_train_one_hot = ops.one_hot(y_train, num_classes=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)结果如下:
如果需要一个除了 y_true 和 y_pred 之外还能接收其他参数的损失函数,可以子类化 keras.losses.Loss 类并实现以下两个方法:
__init__(self):在调用损失函数时接受要传递的参数
call(self,y_true,y_pred):使用目标(y_true)和模型预测(y_pred)计算模型的损失
比方说,您想使用均方误差,但要加上一个项,以抑制预测值偏离 0.5(我们假设分类目标是单击编码的,取值在 0 和 1 之间)。
这将激励模型不要过于自信,从而有助于减少过度拟合(不试试怎么知道行不行!)。
具体做法如下:
class CustomMSE(keras.losses.Loss):def __init__(self, regularization_factor=0.1, name="custom_mse"):super().__init__(name=name)self.regularization_factor = regularization_factordef call(self, y_true, y_pred):mse = ops.mean(ops.square(y_true - y_pred), axis=-1)reg = ops.mean(ops.square(0.5 - y_pred), axis=-1)return mse + reg * self.regularization_factormodel = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=CustomMSE())y_train_one_hot = ops.one_hot(y_train, num_classes=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)结果如下:

自定义指标
如果您需要的度量指标不是 API 的一部分,您可以通过子类化 keras.metrics.Metric 类轻松创建自定义度量指标。您需要实现 4 个方法:
__init__(self),您将在其中为度量创建状态变量。
update_state(self,y_true,y_pred,sample_weight=None),使用目标 y_true 和模型预测 y_pred 更新状态变量。
result(self),使用状态变量计算最终结果。
reset_state(self),用于重新初始化度量器的状态。
状态更新和结果计算是分开的(分别在 update_state() 和 result() 中),因为在某些情况下,结果计算可能非常昂贵,而且只能定期进行。
下面是一个简单的示例,展示了如何实现 CategoricalTruePositives 指标,该指标用于计算有多少样本被正确分类为属于给定类别:
class CategoricalTruePositives(keras.metrics.Metric):def __init__(self, name="categorical_true_positives", **kwargs):super().__init__(name=name, **kwargs)self.true_positives = self.add_variable(shape=(), name="ctp", initializer="zeros")def update_state(self, y_true, y_pred, sample_weight=None):y_pred = ops.reshape(ops.argmax(y_pred, axis=1), (-1, 1))values = ops.cast(y_true, "int32") == ops.cast(y_pred, "int32")values = ops.cast(values, "float32")if sample_weight is not None:sample_weight = ops.cast(sample_weight, "float32")values = ops.multiply(values, sample_weight)self.true_positives.assign_add(ops.sum(values))def result(self):return self.true_positives.valuedef reset_state(self):# The state of the metric will be reset at the start of each epoch.self.true_positives.assign(0.0)model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[CategoricalTruePositives()],
)
model.fit(x_train, y_train, batch_size=64, epochs=3)结果如下:

处理不符合标准特征的损失和指标
绝大多数损失和度量指标都可以通过 y_true 和 y_pred 计算得出,其中 y_pred 是模型的输出,但并非所有损失和度量指标都可以通过 y_true 和 y_pred 计算得出。例如,正则化损失可能只需要激活一层(在这种情况下没有目标),而这种激活可能不是模型的输出。
在这种情况下,可以在自定义层的调用方法中调用 self.add_loss(loss_value)。以这种方式添加的损失会被添加到训练过程中的 "主 "损失(传递给 compile() 的损失)中。
下面是一个添加活动正则化的简单示例(请注意,所有 Keras 层都内置了活动正则化,本层只是为了提供一个具体示例):
class ActivityRegularizationLayer(layers.Layer):def call(self, inputs):self.add_loss(ops.sum(inputs) * 0.1)return inputs # Pass-through layer.inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)# Insert activity regularization as a layer
x = ActivityRegularizationLayer()(x)x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, name="predictions")(x)model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)# The displayed loss will be much higher than before
# due to the regularization component.
model.fit(x_train, y_train, batch_size=64, epochs=1)结果如下:

请注意,当通过 add_loss() 传递损失时,调用 compile() 时就可以不使用损失函数了,因为模型已经有了要最小化的损失。
请看下面的 LogisticEndpoint 层:它将 targets 和 logits 作为输入,并通过 add_loss() 跟踪交叉熵损失。
class LogisticEndpoint(keras.layers.Layer):def __init__(self, name=None):super().__init__(name=name)self.loss_fn = keras.losses.BinaryCrossentropy(from_logits=True)def call(self, targets, logits, sample_weights=None):# Compute the training-time loss value and add it# to the layer using `self.add_loss()`.loss = self.loss_fn(targets, logits, sample_weights)self.add_loss(loss)# Return the inference-time prediction tensor (for `.predict()`).return ops.softmax(logits)您可以在有两个输入(输入数据和目标)的模型中使用它,编译时不需要损失参数,就像这样:
inputs = keras.Input(shape=(3,), name="inputs")
targets = keras.Input(shape=(10,), name="targets")
logits = keras.layers.Dense(10)(inputs)
predictions = LogisticEndpoint(name="predictions")(targets, logits)model = keras.Model(inputs=[inputs, targets], outputs=predictions)
model.compile(optimizer="adam") # No loss argument!data = {"inputs": np.random.random((3, 3)),"targets": np.random.random((3, 10)),
}
model.fit(data)演绎结果如下:

自动分隔验证暂留集
在你看到的第一个端到端示例中,我们使用 validation_data 参数将 NumPy 数组(x_val、y_val)的元组传递给模型,以便在每个历时结束时评估验证损失和验证指标。
这里还有一个选项:参数 validation_split 可以自动保留部分训练数据用于验证。
例如,validation_split=0.2 表示 "使用 20% 的数据进行验证",validation_split=0.6 表示 "使用 60% 的数据进行验证"。
计算验证的方法是,在任何洗牌之前,从 fit() 调用收到的数组中提取最后 x% 的样本。
请注意,只有在使用 NumPy 数据训练时才能使用 validation_split。
model = get_compiled_model()
model.fit(x_train, y_train, batch_size=64, validation_split=0.2, epochs=1)演绎结果如下:

使用 tf.data 数据集进行培训和评估
在过去的几段中,我们已经了解了如何处理损失、度量值和优化器,还了解了当数据以 NumPy 数组形式传递时,如何在 fit() 中使用 validation_data 和 validation_split 参数。
另一种方法是使用类似迭代器的东西,比如 tf.data.Dataset、PyTorch DataLoader 或 Keras PyDataset。
tf.data API 是 TensorFlow 2.0 中的一组实用工具,用于以快速、可扩展的方式加载和预处理数据。
无论您使用的后端是 JAX、PyTorch 还是 TensorFlow,您都可以使用 tf.data 训练您的 Keras 模型。
您可以将 Dataset 实例直接传递给 fit()、evaluate() 和 predict() 方法:
model = get_compiled_model()# First, let's create a training Dataset instance.
# For the sake of our example, we'll use the same MNIST data as before.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)# Now we get a test dataset.
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(64)# Since the dataset already takes care of batching,
# we don't pass a `batch_size` argument.
model.fit(train_dataset, epochs=3)# You can also evaluate or predict on a dataset.
print("Evaluate")
result = model.evaluate(test_dataset)
dict(zip(model.metrics_names, result))演绎结果如下:

请注意,数据集会在每个轮次结束时重置,因此可以在下一个轮次重复使用。
如果只想在该数据集的特定批次上运行训练,可以传递 steps_per_epoch 参数,指定在进入下一个 epoch 之前,模型应使用该数据集运行多少训练步骤。
model = get_compiled_model()# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)# Only use the 100 batches per epoch (that's 64 * 100 samples)
model.fit(train_dataset, epochs=3, steps_per_epoch=100)结果如下:

您也可以在 fit() 中传递 Dataset 实例作为 validation_data 参数:
model = get_compiled_model()# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)model.fit(train_dataset, epochs=1, validation_data=val_dataset)结果如下:

在每个历时结束时,模型将遍历验证数据集,并计算验证损失和验证指标。
如果只想对该数据集的特定批次运行验证,可以传递 validation_steps 参数,指定在中断验证并进入下一个 epoch 之前,模型应使用验证数据集运行多少个验证步骤:
model = get_compiled_model()# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)model.fit(train_dataset,epochs=1,# Only run validation using the first 10 batches of the dataset# using the `validation_steps` argumentvalidation_data=val_dataset,validation_steps=10,
)结果如下:
![]()
请注意,每次使用后,验证数据集都会重置(这样您就可以始终在相同的样本上进行历时评估)。
在使用数据集对象进行训练时,不支持参数 validation_split(从训练数据中生成保留集),因为该功能需要对数据集的样本进行索引,而数据集 API 一般无法做到这一点。





![[Linux_IMX6ULL驱动开发]-基础驱动](https://img-blog.csdnimg.cn/direct/4ca5ef08cd2a4d67a7ef3c5327b843d7.png)