Neural Latents Benchmark ‘21: Evaluating latent variable models of neural population activity
挑战赛说明:
https://neurallatents.github.io/
挑战赛地址:
https://eval.ai/web/challenges/challenge-page/1256/overview
NeuralLatent 论文:
https://arxiv.org/abs/2109.04463
数据读取与模型评价代码仓库:
https://github.com/neurallatents/nlb_tools
摘要
神经记录的进步为以前所未有的细节研究神经活动提供了越来越多的机会。潜在变量模型 (lvm) 是分析跨不同神经系统和行为的这种丰富活动的有前途的工具,因为lvm不依赖于活动与外部实验变量之间的已知关系。然而,由于缺乏标准化,lvm在神经元群体活动方面的进展目前受到阻碍,导致方法被开发并以临时方式进行比较。为了协调这些建模工作,我们引入了一个基准套件,用于神经种群活动的潜在变量建模。我们从认知,感觉和运动领域整理了四个神经尖峰活动数据集,以推广适用于这些领域的各种活动的模型。我们将无监督评估确定为跨数据集评估模型的通用框架,并应用几个展示基准多样性的基线。
1. 介绍
神经科学的中心追求是了解大脑丰富的感觉,运动和认知功能是如何从神经元群体的集体活动中产生的。为此,我们正在目睹系统神经科学的巨大变化,因为十年来神经接口技术的快速发展已经开始使大量神经元群体的同时活动成为可能 [1]。因此,神经科学家越来越多地从各种大脑区域和各种行为中捕捉到高维度和动态的活动肖像。由此产生的数据集可能会阻碍传统的分析方法,这些方法是围绕一次或少数几个神经元的记录而设计的。
为了应对日益增加的数据复杂性,计算神经科学家正在产生强大的方法来揭示和解释神经种群活动的结构。一种新兴且特别有前途的方法集-称为潜在变量模型 (lvm)-表征神经元群体的协变模式,以揭示其内部状态 [2]。Lvm已被证明可用于总结和可视化人口活动,将活动与行为相关联以及询问介导人口级别计算的动态机制 [3,4,5,6,7]。
推进lvm在神经数据中的应用的一个关键机会是利用过去十年机器学习的巨大进步。然而,ML专家要产生影响存在很高的进入障碍,这可能是由于缺乏用于评估和比较lvm的标准化数据集和指标。为了解决这一差距,我们引入了神经潜伏期基准 (NLB),这是一系列基准套件,可以对神经数据进行lvm的标准化定量评估。这些套件将提供精选数据集、标准化api和示例代码库。
在这里,我们介绍了我们的第一个套件NLB '21,旨在通过对来自各种大脑区域,行为和数据集大小的数据集进行无监督建模来扩大LVM方法的潜在适用性。虽然lvm通常使用来自单个大脑区域和行为的数据进行开发和评估,但来自不同区域或行为的活动可能具有明显不同的结构,因此存在不同的建模挑战 [8]。NLB '21提供了来自猴子的跨运动,感觉和认知大脑区域的精选神经生理学数据集,其行为从预先计划的,刻板的运动到必须动态整合和采取行动的感觉输入。此外,由于神经科学数据集的大小可能会发生很大变化,并且不同的LVM可能或多或少具有数据效率,因此我们引入了数据缩放基准,以评估不同大小数据集上的LVM性能。 为了实现对lvm的一般评估,无论大脑区域,行为或数据集大小如何,我们采用了一种标准化的无监督评估指标,称为共同平滑( co-smoothing ) [9],它根据模型预测神经元活动的能力来评估模型。我们还提供二级评估指标,其适用性和实用性因数据集而异。为了确保可访问性和标准化,我们以Neurodata无国界格式提供数据集 [10],在EvalAI平台上托管基准和排行榜 [11],并提供演示数据预处理和提交的代码包。为了确保一致的评估并减轻过度拟合或超参数黑客攻击的问题,针对开发人员不可用的私人数据评估模型预测。
该手稿首先激发了lvm在解释神经科学数据方面的广泛使用。然后,我们详细介绍基准数据集和评估指标,并通过各种当前的LVM方法提供其应用示例。我们预计这个基准测试套件将为LVM开发人员和用户提供有价值的比较点,使社区能够识别并构建有前途的方法。
1.1科学动机与评价哲学
Lvm是一种基于神经元种群的部分观察来表征生物神经网络内部状态的强大方法。在神经元群体活动的应用中,lvm是将观察到的活动描述为潜在变量的组合的生成模型,这些潜在变量通常少于观察到的神经元的数量,并且通常表现出时间上的有序进展。神经数据的LVM方法基于经验发现,即大神经元群体中的神经元不是独立行动的,而是表现出协调的波动 [12,13,14]。我们将读者指向最近的评论 [2],以讨论如何将lvm用于神经科学见解。在nlb’21中,我们专注于不直接以测量的外部变量为条件的无监督lvm。 在不严格依赖外部变量的情况下,此类模型具有广泛的适用性,包括我们无法观察甚至无法知道影响神经群体响应的相关外部变量的设置。
为了理解lvm在探测神经电路中的效用,一个有用的类比是对人工网络进行逆向工程的任务,该人工网络接收一组输入,执行一些计算并产生一组输出。在输入和输出之间,人工网络具有一组中间表示,并且研究这些表示可以深入了解网络所采用的计算策略。同样,神经群体记录是处理信息和协调行为的生物神经网络的中间表示的观察结果。
然而,对于神经群体记录来说,理解这些表示的任务可能比人工网络更具挑战性,因为我们通常有一个或几个大脑区域中有限数量的神经元的记录,我们可能不知道解剖连通性,并且在外部可测量的输入和输出与所研究的大脑区域之间可能存在许多处理步骤。此外,观察到的神经元反应是高度可变的,看似嘈杂的 [3],使得理解神经群体活动的任务固有地具有统计学意义,并且非常适合潜在变量方法。
有许多潜在的方法可以用潜在变量对神经群体活动进行建模,不同的假设可能会导致看似 “正确” 的不同模型结构。鉴于潜在变量建模的这种不适定性质,我们寻求一种主要的评估方法,该方法在很大程度上与所评估的LVM的形式和结构无关。实际上,共同平滑评估 (在3.2节中定义) 是一种无监督的方法,仅评估lvm描述观察到的神经元活动本身的能力。这允许建模假设的灵活性,同时避免比较lvm的变化很大的结构的复杂复杂性。
1.2 相关工作
应用于神经数据的lvm的评估策略已经开发了许多新的lvm,以满足分析大规模神经群体记录的需要。对于上下文,我们在补充表3中记录了ML场所中此类神经数据lvm的出现。这些lvm在各种数据集上进行评估,这些数据集共同跨越大脑的许多区域。也使用其他动物模型 (大鼠 [15],小鼠 [16]) 和非电生理记录方式 (钙成像 [16],fMRI [17])。以前使用的数据集的多样性令人印象深刻,但缺乏标准化的数据集使得模型之间的比较变得困难。此外,即使两个lvm使用相同的数据集,它们也经常会报告不同的度量,或者相同度量的不同变体,如表3所示。非标准化评估使得跟踪该领域的状况变得极其困难。
计算神经科学中的现有基准。计算神经科学界最近围绕机器学习方法和神经数据的相互作用产生了几个基准。有些人专注于从原始神经生理学数据中提取尖峰活动 (动作电位或关联) 的挑战,例如,从双光子钙成像数据推断尖峰活动的spikefinder挑战 [18],以及从电生理记录中提取尖峰的SpikeForest [19]。其他基准评估单个神经元建模,以预测尖峰时间 [20],并从运动和体感皮质和海马的神经群体活动中解码外部可测量的变量 [21]。另外,Brain-Score评估了被训练来执行行为任务的深度神经网络的一致性以及与这些任务相关的大脑区域 (特别是腹侧视觉流) [22]。 与所有这些不同,nlb’21量化了lvm可以以无监督的方式描述神经元群体活动的程度。
评估生成模型延迟和输出。比较lvm的候选方法是评估模型的中间表示的质量。在ML中,这种中间潜在表示通常通过监督评估来评估,例如通过测量它们相对于数据类别的解纠缠 [23] 或在各种下游任务中的转移性能 [24]。然而,如前所述,监督评估在一些神经科学应用中可能是有限的,其中外部变量可能是神经元活动的不可靠或不完整的描述 (特别是在更高阶的大脑区域,例如那些潜在的认知)。因此,实现跨大脑区域和任务条件概括的性能指标需要无监督评估。
对潜在表示进行无监督评估的常见方法是通过与参考数据的一对一比较来评估模型输出的质量。这可以通过预测数据的保留部分来实现,如MLM (蒙面语言建模) [25] 或图像修复 [26]。当用作学习目标时,这些指标可能会冒着基于浅层数据相关性的 “捷径” 解决方案的风险 [26]。另一方面,传销方法在诱导高级语义表示方面已被证明是有效的 [25],证明在缺乏令人满意的监督指标的情况下将其用作第一个代理目标。
2 NLB ’21: Datasets
为了促进lvm的广泛应用,我们的数据集跨越了作为运动、感觉和认知功能基础的大脑区域,并跨越了各种行为。如下所述,每个数据集呈现一组独特的挑战来揭示神经潜伏期。我们注意到,虽然所有数据集都在以前的研究中使用过 (主要用于神经科学目的),但以前没有任何神经数据LVM评估基准,无论是使用这些数据还是我们知道的任何其他数据。
所有数据集均包含使用皮质内微电极阵列记录的电生理测量结果。将初步信号处理应用于原始电压记录以提取尖峰活性。尽管这种尖峰排序过程并不完善,并且是一个积极研究的主题,但我们将其视为与提取数据中潜在结构的过程不同的问题,从而以尖峰排序形式提供数据集。每个数据集的详细描述可以在附录中找到。所有数据集都可以通过NWB (神经数据无国界) 标准中的DANDI (神经生理学数据集成分布式档案) 获得 [27]。可以在 https://neurallatents.github.io/ 上找到链接。请注意,我们的基准测试使用来自较大数据集的选择记录会话,可能有许多其他会话。因此,与我们在这里介绍的数据相关的数据可能已经单独上传供公众使用 (例如,在DANDI上),但这些版本不包括用于nlb’21的特定录制会话。
MC_Maze .
迷宫数据集包括来自初级运动和背部运动前皮质的记录,而猴子以指示的延迟到达视觉呈现的目标,同时避免虚拟迷宫的边界 [28]。猴子达到了108的行为任务配置,其中每个任务配置使用目标位置,虚拟障碍数量和障碍位置的不同组合。这些不同的配置引起了各种各样的直线和曲线到达轨迹,并且猴子以随机顺序多次尝试每种配置,从而在给定的实验过程中记录了数千次试验。
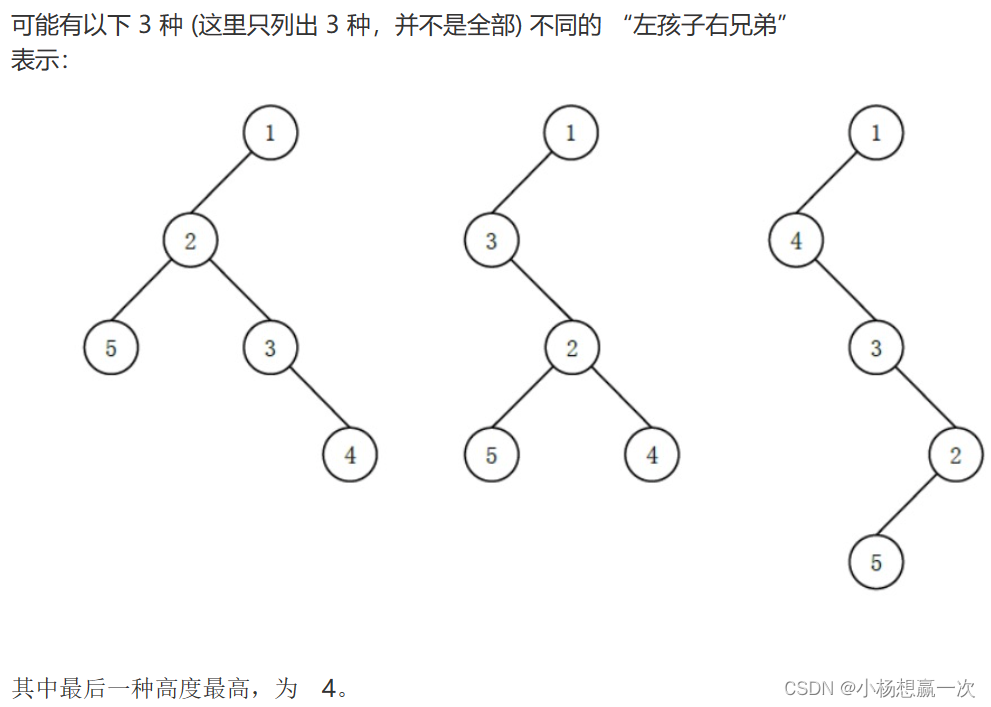
图1: nlb’21数据集跨越四个不同的大脑区域/任务组合。对于每个行为任务 (中间行),左上方的面板显示了数据集中神经元的放电率分布,而右上方突出显示了记录的大脑区域。下部面板显示与任务事件对齐的示例尖峰栅格。任务: 运动皮层 (MC) 数据集包括具有定型条件的中心指示延迟到达任务 (迷宫) 和随机目标任务 (RTT) 中的连续到达。来自体感皮层 (区域2) 的数据包括外部扰动的运动和目标定向的意志运动。来自背内侧额叶皮层 (DMFC) 的数据处于准备就绪 (RSG) 认知时间间隔再现任务期间。
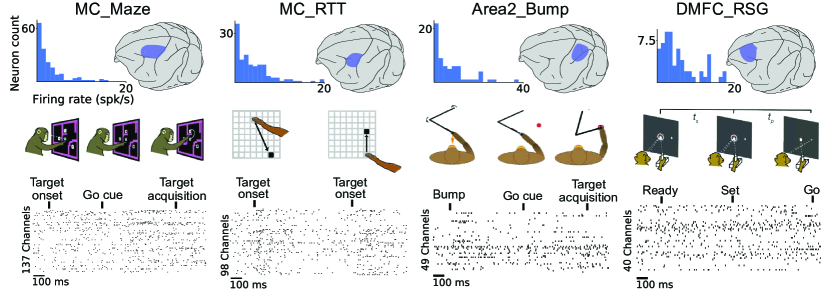
迷宫数据集在其行为丰富性 (任务配置的数量),跨重复试验的刻板行为 (每个任务配置数十次重复) 和高总试验计数 (数千) 的组合中是例外的-这些属性支持平均神经元活动在重复试验中作为一个简单的,第一遍去噪策略 [3],同时在任务条件下保留足够的多样性,以允许对种群活动的结构进行丰富的调查 [29]。此外,指示的延迟范式允许在呈现go提示之前进行运动准备,这使得与准备和执行相关的神经过程能够完全分离 [28,30]。 由于指示的延迟范式和缺乏不可预测的任务事件,执行阶段的种群活动在很大程度上是可预测的,基于准备时神经种群的状态,创建一个独特的情况下,活动可以很好地建模为一个自主的动态系统 [30,31,32,4]。凭借其独特的属性,迷宫数据集已广泛用于神经科学研究-特别是,它们对于揭示运动准备和执行过程中神经种群活动结构的大量见解至关重要 [28,31,33,34,35,36,37,38,39,40]。它们也被用于单独验证几个lvm [41,32,42,8]。
MC_Maze由一个完整的会话组成,其中包含2869个总试验和182个神经元,并同时监测手部运动学。我们希望这个数据集可以作为LVM开发的基本但通用的基线 (类似于 “神经科学MNIST”)。此外,为了支持表征lvm数据效率的数据扩展基准,我们提供了三个扩展数据集,每个数据集来自单独的实验会话,分别包含500,250和100训练试验以及100测试试验。我们将该数据集的缩放版本分别称为MC_Maze -L、MC_Maze -M、MC_Maze -S。每个缩放数据集仅包含27个条件和神经元计数,范围从142到162。DANDI [43] 上还有许多其他迷宫数据集。
MC_RTT
尽管迷宫数据集包含丰富的行为,但它们的刻板印象仍可能限制观察到的神经信号的潜在复杂性 [29]。此外,自然运动很少被定型或整齐地分为试验。随机目标任务数据集 [44] 也包含运动皮层数据,但引入了不同的建模挑战。它包含在各种位置开始和结束的连续点对点到达,不包括延迟期,并且具有高度可变的长度,几乎没有 (如果有的话) 重复。这些属性排除了简单的试验平均方法来消除观察到的尖峰活动的噪声。此外,我们使用连续数据流的随机片段来评估模型。随机片段的不可预测性 (例如,新的目标可能出现在数据窗口中的任何点) 意味着自主动力学的简化是一个较差的近似 (在 [32,8] 中讨论)。
MC_RTT跨越15分钟的连续到达,人为地分成1351个600毫秒的 “试验”,包括130个神经元和同时监测的手部运动学。Zenodo [44] 上还有许多其他的RTT数据集。在此基准下成功建模的前提是能够从单次试验数据中推断出潜在的表示形式,并推断出人口活动中存在不可预测的输入。
Area2_Bump
体感区域可能与运动区域具有显着不同的动力学 [45],这是由于它们处理感觉反馈的独特作用,这对我们进行协调运动的能力至关重要。Area2_Bump包括来自体感皮层 [46] 区域2的神经记录,该区域接收和处理本体感受信息或有关身体运动的信息。这些数据被记录为猴子执行简单的视觉引导到达任务,其中每个试验包括使用manipulandum到达视觉呈现的目标。然而,在随机50% 的试验中,manipulandum在到达提示之前意外地在随机方向上碰撞了猴子的手臂,需要纠正反应 [46]。
Area2_Bump包括462个试验和65个神经元,以及相关的手部运动学和摄动信息。成功的模型可能需要推断输入以帮助描述感觉扰动后的活动,并且还应该对低神经元计数具有鲁棒性。
DMFC_RSG
背内侧额叶皮层 (DMFC) 是一个高级认知区域,对LVMs提出了独特的挑战。高水平区域的神经元对不同的感觉刺激和运动参数表现出混合的选择性 [47]。此外,认知任务中的行为和任务变量通常无法直接观察到,这使得推断内部状态的任务更加关键。此外,DMFC的输入层和输出层不像其他感觉或运动皮层那样清晰描绘 [48]。DMFC_RSG包含来自DMFC的记录,而一只猴子执行了 “Ready-Set-Go” 时间间隔再现任务 [49]。在任务中,动物估计两个视觉线索之间的时间间隔,然后通过将眼睛或手移向目标线索来生成匹配的间隔。独特的是,这个时间间隔本身就是一个变量,动物必须根据感官信息进行推断,然后根据它们的内部时间估计进行繁殖。 多种响应方式,目标位置,时间间隔和时间先验导致总共40个任务条件 [49]。
DMFC_RSG包括1289个试验和54个神经元,以及相关联的任务定时、条件和反应时间信息。高性能lvm可能需要平衡输入和内部驱动的动态,并且再次对低神经元计数具有鲁棒性。
3. 流水线和评价指标
除了我们作为这项工作的一部分提供的各种神经数据集之外,我们还引入了一个评估框架,用于跨多个轴评估lvm,这可能有助于社区评估不同的设计选择如何影响模型与神经科学应用中各种潜在挑战的相关性。并帮助来自系统神经科学各个领域的用户确定哪些方法与他们的应用最相关
正如引言中所述,lvm表征了跨空间 (即神经元) 和时间的神经群体活动的协调,使得高性能模型应该能够预测它们无法直接访问的神经元时间点的活动。因此,我们的主要评估指标衡量了LVM预测保持神经元活动的能力 (co-smoothing, 在3.2节中描述)。我们还使用衡量LVM预测时间点的能力的二级指标 (forward prediction, 在3.3节中描述),以及特定于数据集的其他二级指标 (behavioral prediction, PSTH-matching, 在3.3节中描述)。
图2: 评估流水线.
a. 数据集被分成几个部分, 以实现对候选模型的严格评估 (在3.1节中描述)
b. 在评估阶段, 用户提交针对非公开数据 (保存在EvalAI服务器上)发放率的预测, 这包含四个方面:
- co-smoothing (主要指标,3.2节), 评价模型预测其它神经元的发放的能力
- PSTH-matching (二级度量,3.3节), 评价 PSTHs 的匹配程度
- behavioral prediction (二级度量,3.3节), 评价解码的精度
- forward prediction (二级度量,3.3节), 评价模型预测在接下来的时刻发放的能力

3.1 评估策略和流水线
为了支持评估, 除了为我们的数据集定义 train/val/test 拆分外, 我们还将神经元和时间点指定为 held-in 或 held-out, 对于 train/val, held-in 和 held-out 都是可用的(spike+behavior), test 部分的数据则只保留 held-in 部分, 保留的测试数据仅存储在EvalAI服务器上 (图2)。
在评估时, 用户需要提交 train/val/test 数据集上的预测发放率. 对于 train/val 部分, 提交结果被用来训练一个简单的线性解码器用来预测行为, 此时 held-out 部分不参与评估, 对于 test 部分, 几个指标都会被考虑到: co-smoothing (primary metric), as well as match to PSTH, forward prediction, and behavioral decoding using the linear decoder (secondary metrics). Model predictions are submitted on EvalAI in 5 ms bins.
通过仅要求用户提交针对特定神经元时间激发速率的预测,我们不会对训练候选lvm或执行推理的方法施加特定限制。例如,方法可以利用提供的行为数据作为附加信息来指导学习其潜在表示,如 [50] 中所做的。另请注意,我们指定了val分割作为报告消融和分析的标准,尽管用户可以自由地使用其他分割来验证其模型。
Primary evaluation metric: Co-smoothing
Our primary evaluation metric is the log-likelihood of held-out neurons’ activity. As mentioned previously, the test data is split into held-in and held-out neurons (Figure 2a). Given the training data and the held-in neurons in the test data, the user submits the predicted firing rates λ \lambda λ of the held-out neural activity y p y^{p} yp. We use a Poisson observation model in the log-likelihood such that the probability of the held-out spike count of neuron n n n at time point t t t is p ( y n , t p = P o i s s o n ( y n , t p ; λ n , t ) p(y^{p}_{n, t} = Poisson(y^{p}_{n, t}; \lambda_{n,t}) p(yn,tp=Poisson(yn,tp;λn,t) The overall log-likelihood L ( λ ; y p ) ℒ(\lambda;y^{p}) L(λ;yp) is the sum of the log-likelihoods over all held-out neurons n n n and time points t t t. To normalize the log-likelihood score, we convert it to bits per spike using the mean firing rates of each held-out neuron [51]. Bits per spike is computed as follows:
b i t s / s p i k e = 1 n s p l o g 2 ( ( L ( λ ; y p ) ) − ( L ( λ n , : ; y n , t p ) ) ) bits/spike=\frac{1}{n_{sp}log2}((ℒ(\lambda;y^{p}))-(ℒ(\lambda_{n,:};y^{p}_{n,t}))) bits/spike=nsplog21((L(λ;yp))−(L(λn,:;yn,tp)))
where λ n , : \lambda_{n,:} λn,: is the mean firing rate for the neuron n n n and n s p n_{sp} nsp is its total number of spikes. Thus, a positive bits per spike (bps) value indicates that the model infers a neuron’s time-varying activity better than a flat mean firing rate.
The approach of predicting the activity of held-out neurons conditioned on the held-in neurons on test data is referred to as co-smoothing [9] and provides a generalization of leave-neuron-out accuracy measures now commonly used in the neuroscience community [9, 12, 32, 52, 15]. Co-smoothing assumes that the latent variables underlying the activity of held-out neurons can be inferred from the training neurons supplied at test time. While this may not hold for all neurons in a population, the observation that latent representations are distributed across many neurons provides strong support for this assumption (reviewed in [12, 3]).
这一部分最好阅读原文,翻译可能造成误解。
3.3Secondary metrics
Behavioral decoding.
行为解码。将神经活动与行为相关联是对神经数据进行建模的常见目标,并且通常通过识别潜在状态与感兴趣的行为变量之间的关系来解释神经潜在变量。因此,考虑到推断的潜在变量,我们将行为解码准确性作为次要基准度量。
对于MC_Maze,MC_RTT和Area2_Bump数据集,通过将来自训练速率的岭回归模型拟合到行为数据并测量来自测试速率的预测的R2来评估行为解码。尽管使用更复杂的解码器可以实现更好的解码性能,但我们选择对所有模型实施线性映射,以防止过于复杂的解码器补偿不良的潜在变量估计。对于所有三个数据集,使用的行为数据是猴手速度; 已知许多运动学变量与感觉运动活动相关,但是某些变量 (例如位置) 变化缓慢,从而很容易通过对神经活动进行大量平滑来使解码性能饱和。我们假设手的速度将提供足够具有挑战性的解码目标,以区分由不同模型推断的表示的质量。
对于DMFC_RSG,行为解码更难以评估 (如前所述)。然而,先前的工作表明,神经种群状态变化的速率或神经速度与 t p t_p tp,即准备就绪的提示与猴子的Go响应之间的时间呈负相关-Go (RSG) 任务 [49,8]。因此,我们从测试速率预测中计算每次试验的平均神经速度,然后计算神经速度和测量的 t p t_p tp之间的皮尔逊r,作为预测的神经活动如何反映观察到的行为的度量 [49]。
Match to PSTH.
当行为任务包括重复试验的不同条件时,一种粗略的,常用的去噪尖峰活动的方法是计算刺激时间直方图 (PSTH)。Psth是通过在给定条件下的试验中平均神经元反应来计算的,因此揭示了在行为条件的重复观察中一致的特征 [3]。对于lvm,推断概括psth的激发速率提供了证据,表明模型可以捕获神经元响应的某些刻板特征。但是,由于两个限制,我们使用与 Match to PSTH 作为辅助指标: 首先,并非所有数据集都非常适合计算PSTH。其次,PSTH将所有跨试验的变异性视为 “噪音”,因此 Match to PSTH 并不能测试模型预测单次试验变异性的能力,这种变异性可能是突出的,也是给定大脑区域计算作用的关键部分 [3]。
在MC_RTT数据集 (其由于缺乏清晰的试验结构而不太适合试验平均方法) 之外,可以通过在相同条件内的试验中平均平滑的尖峰来估计对其他数据集的特定条件的典型神经反应。我们通过计算每个条件的试验平均模型速率预测与真实psth之间的 R 2 R^2 R2 来评估预测速率与psth的匹配程度。 R 2 R^2 R2 首先在所有条件下为每个神经元计算,然后在神经元之间求平均。
Forward prediction.
我们还测试了该模型预测所有神经元在看不见的未来时间点的反应的能力。以与共同平滑类似的方式评估前向预测基准,区别在于保持的响应在未来时间点跨越所有神经元。前向预测提供了模型在多大程度上可以捕获数据中的时间结构的进一步度量。然而,它假设可以基于先前的神经活动来预测未来的神经活动。一般情况下不应该是这种情况,并且对于其中不可预测的输入是常见的大脑区域和行为任务尤其成问题。因此,虽然前向预测提供了对LVM预测本身可预测的活动的能力的一些评估,但它最好应用于可以通过自主动力学对数据进行良好建模的场景 (例如MC_Maze)。
我们用5种已建立的神经种群活动建模方法为基准设定种子: Smoothed spikes [12],Gaussian Process Factor Analysis (GPFA) [12],Switching Linear Dynamical System(SLDS) [53,54,55],AutoLFADS [8],和 Neural Data Transformer (NDT) [42]。
这些模型在动力学,向前 (或生成) 模型及其整体复杂性的基本假设方面有所不同 [2]。尖峰平滑是通过将尖峰活动与高斯内核进行卷积来对发射速率进行降噪的最简单但仍然常见的方法。GPFA将神经状态建模为高斯过程的低维集合,因此在生成模型的潜在空间上强加了简单的线性动力学。Sld扩展了标准线性动力学系统,并通过在多个不同的线性系统之间交替或 “切换” 来近似复杂的非线性动力学。AutoLFADS是一种变分顺序自动编码器,它使用RNN对神经动力学进行建模,因此可以捕获复杂的非线性动力学和嵌入。NDT使用 Transformer 来生成神经活动,而没有任何显式的动力学模型。
4 Results
4.1 MC_Maze as Neuroscience MNIST
我们首先对MC_Maze上的模型结果进行了仔细检查,该模型对于基本模型石蕊测试具有许多理想的品质。它具有丰富的结构,具有108不同的到达条件,180神经元和 > 2000 试验。然而,每种情况也有许多重复试验,允许通过PSTH指标进行评估。此外,由于运动皮层与运动输出具有紧密的解剖学联系,因此MC_Maze支持通过行为解码进行模型评估。最后,它在经验上和理论上都是行之有效的,因为许多LVM已经在数据集上进行了评估,并且动态很好地近似为自治的 [32],邀请前瞻性预测措施来评估LVM动态模型的质量。这种良好控制的设置使MC_Maze像一个 “神经科学MNIST”: 立即用于验证神经lvm,即使长期神经科学或建模进展可能受到限制。