书生·浦语大模型实战营之全链路开源体系
为了推动大模型在更多行业落地开花,让开发者们更高效的学习大模型的开发与应用,上海人工智能实验室重磅推出书生·浦语大模型实战营,为广大开发者搭建大模型学习和实践开发的平台,两周时间带你玩转大模型微调、部署与评测全链路。
https://github.com/internLM/tutorial


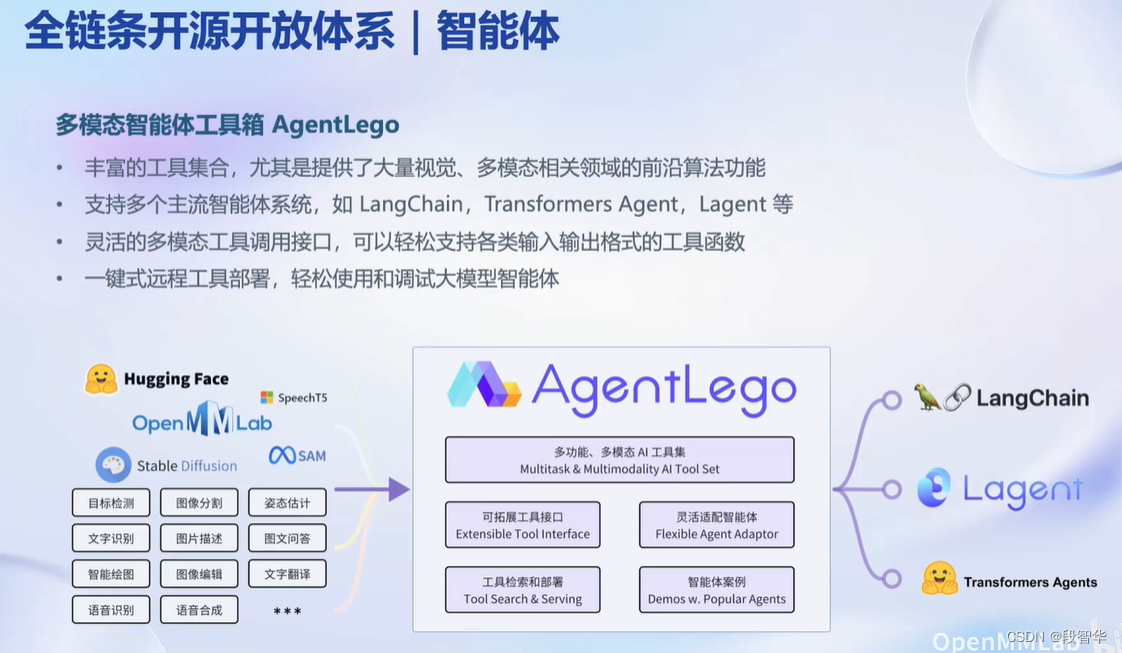
书生·浦语大模型全链路开源体系







技术报告学习
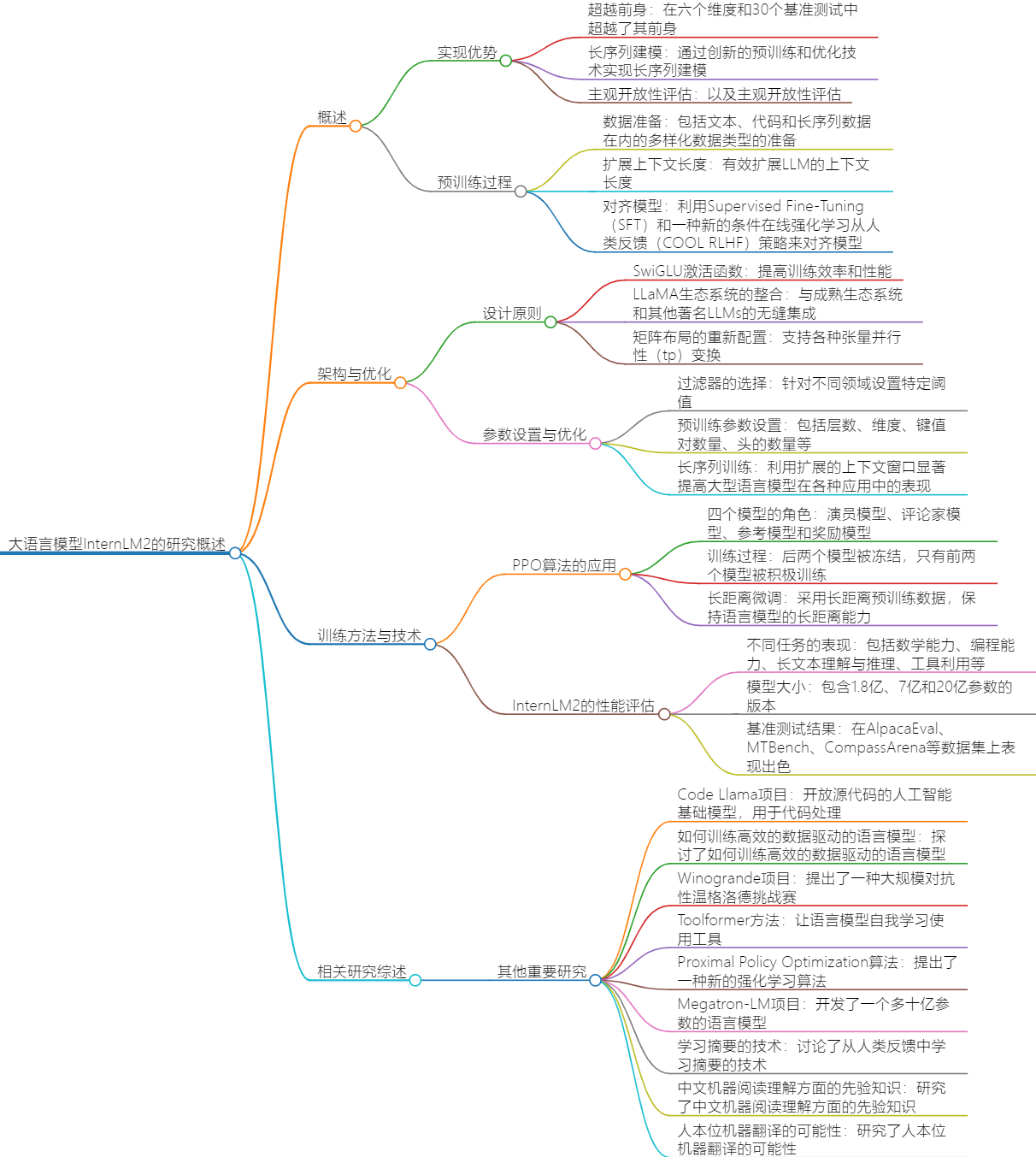
论文介绍了InternLM2的开发背景和目标,然后详细阐述了其预训练过程,包括数据准备、模型结构和优化技术。接着,文章讨论了如何通过使用不同的过滤器来减少大规模语言模型的训练数据量,并优化其性能。文章介绍了一种采用改进的Proximal Policy Optimization 算法进行训练的语言模型,并对其进行了详细的分析和优化。
文章主要内容包括:
- InternLM2是一个开源的大型语言模型,旨在通过创新的预训练和优化技术实现长序列建模和主观开放性评估。
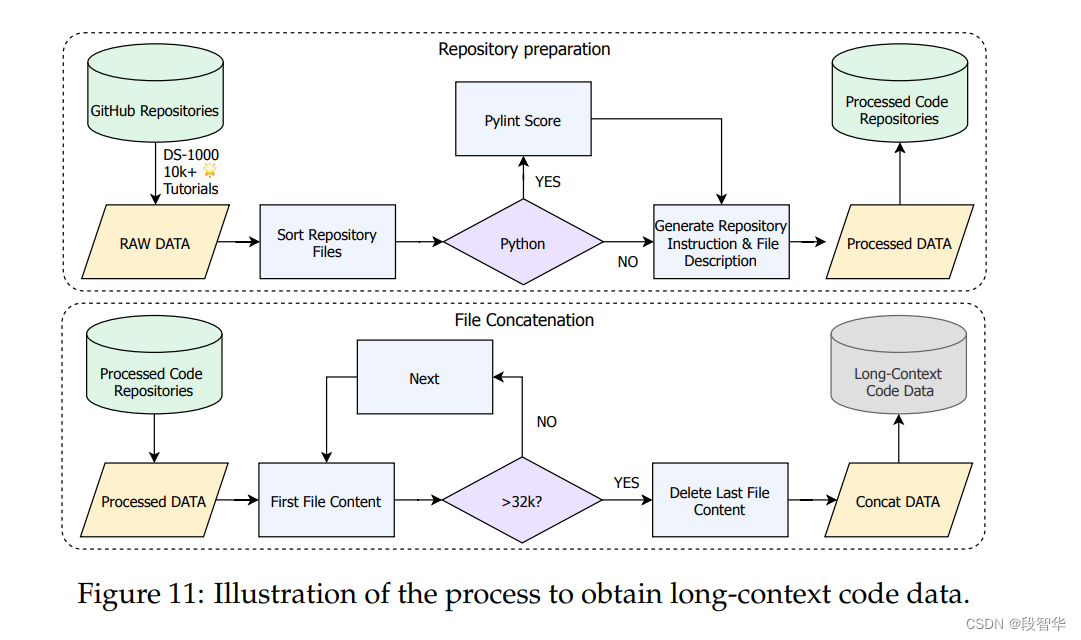
数据准备:包括文本、代码和长序列数据在内的多样化数据类型的准备。 - 模型结构:通过整合Wk、Wq和Wv矩阵,以及为每个头的Wk、Wq和Wv采用一种交错的方法,以支持各种张量并行性(tp)变换。
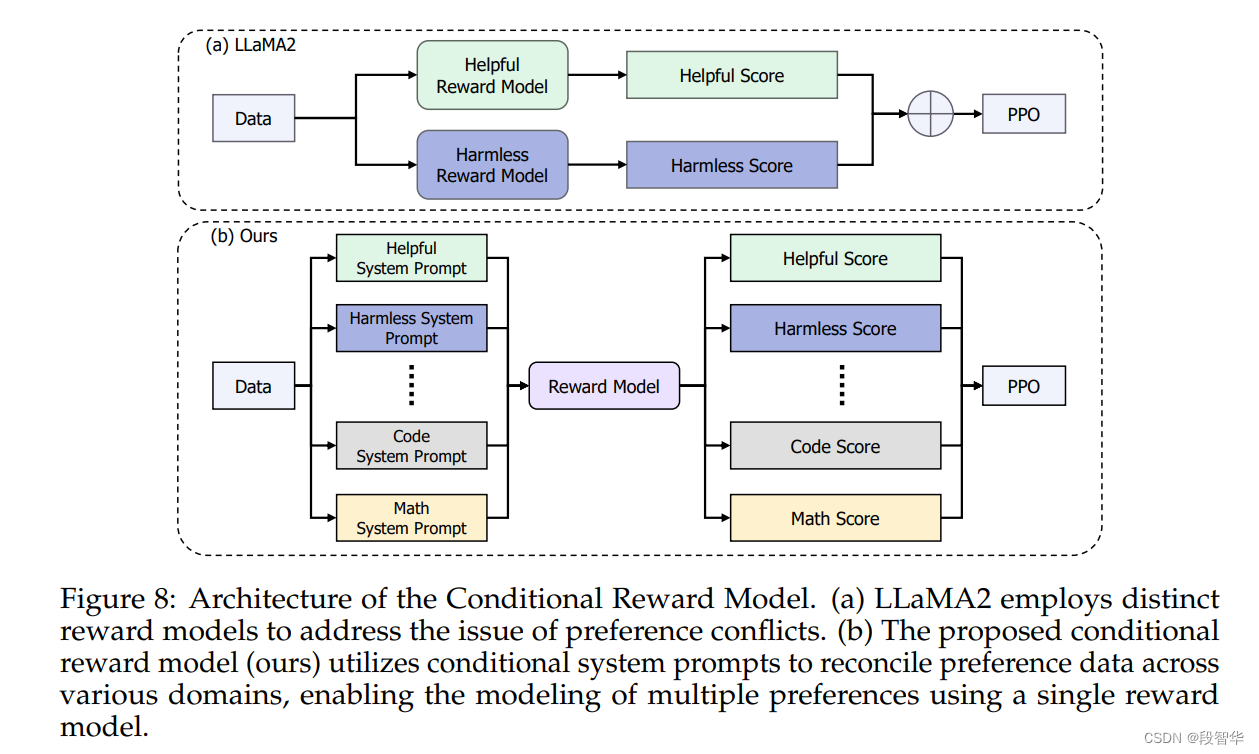
- 使用Supervised Fine-Tuning(SFT)和一种新的条件在线强化学习从人类反馈策略来对齐模型。
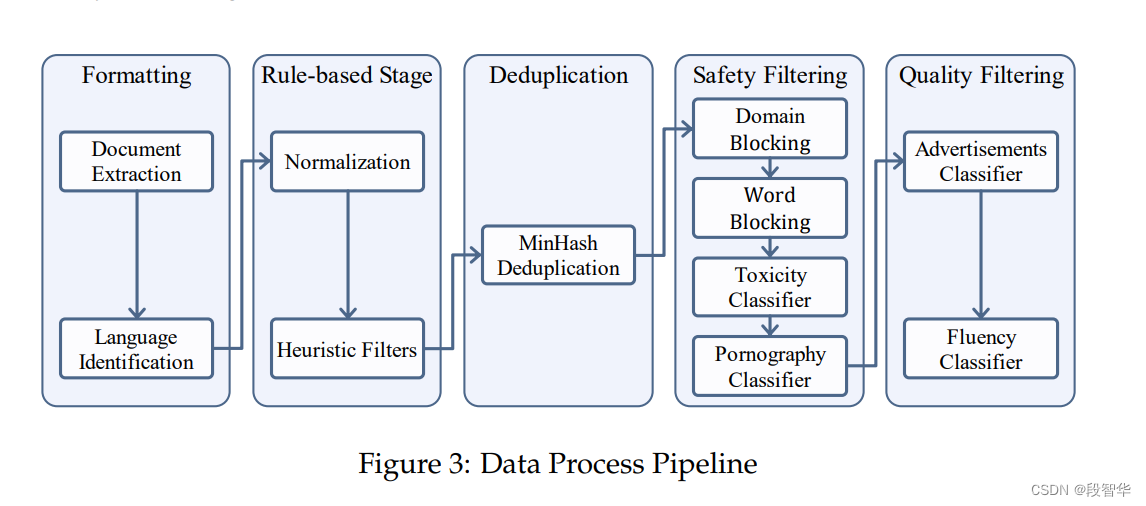
- 通过使用不同的过滤器来减少大规模语言模型的训练数据量,并优化其性能。
- 过滤器的选择:针对不同领域设置特定阈值,而不是寻求通用解决方案。
参数设置:包括层数、维度、键值对数量、头的数量等。 - 利用扩展的上下文窗口显著提高了大型语言模型在各种应用中的表现,如检索增强生成和智能代理。
- 通过采用改进的Proximal Policy Optimization算法进行训练,能够在各种任务中表现出色,特别是在长期上下文理解方面。
InternLM2大型语言模型的构建、优化及应用
-
InternLM2是一个开源的大型语言模型,其在六个维度和30个基准测试中超越了其前身。
-
实现了长序列建模和主观开放性评估,通过对多样化数据类型的准备,以及有效扩展LLM的上下文长度。
-
InternLM2在多种任务上表现出色,包括数学能力、编程能力、长文本理解与推理、工具利用等。
-
InternLM2是一款新型的开源大型语言模型,通过创新的预训练和优化技术实现了长序列建模和主观开放性评估。
-
模型的预训练过程强调了使用包括文本、代码和长序列数据在内的多样化数据类型。
-
模型在多个基准测试中超越了其前身,展现出强大的性能。
-
模型的应用范围广泛,适用于多种场景,如自然语言理解和生成任务。