本文是 SpringBoot 开发的干货集中营,涵盖了日常开发中遇到的诸多问题,通篇着重讲解如何快速解决问题,部分重点问题会讲解原理,以及为什么要这样做。便于大家快速处理实践中经常遇到的小问题,既方便自己也方便他人,老鸟和新手皆适合,值得收藏 😄
1. 哪里可以搜索依赖包的 Maven 坐标和版本
-
https://mvnrepository.com/
这个在2023年前使用得最多,但目前(2024)国内访问该网站时,经常卡死在人机校验这一步,导致无法使用
-
Maven Central
刚开始我是临时用这个网站来替换前面那个,现在它越来越好用,就直接使用它了
2. 如何确定 SpringBoot 与 JDK 之间的版本关系
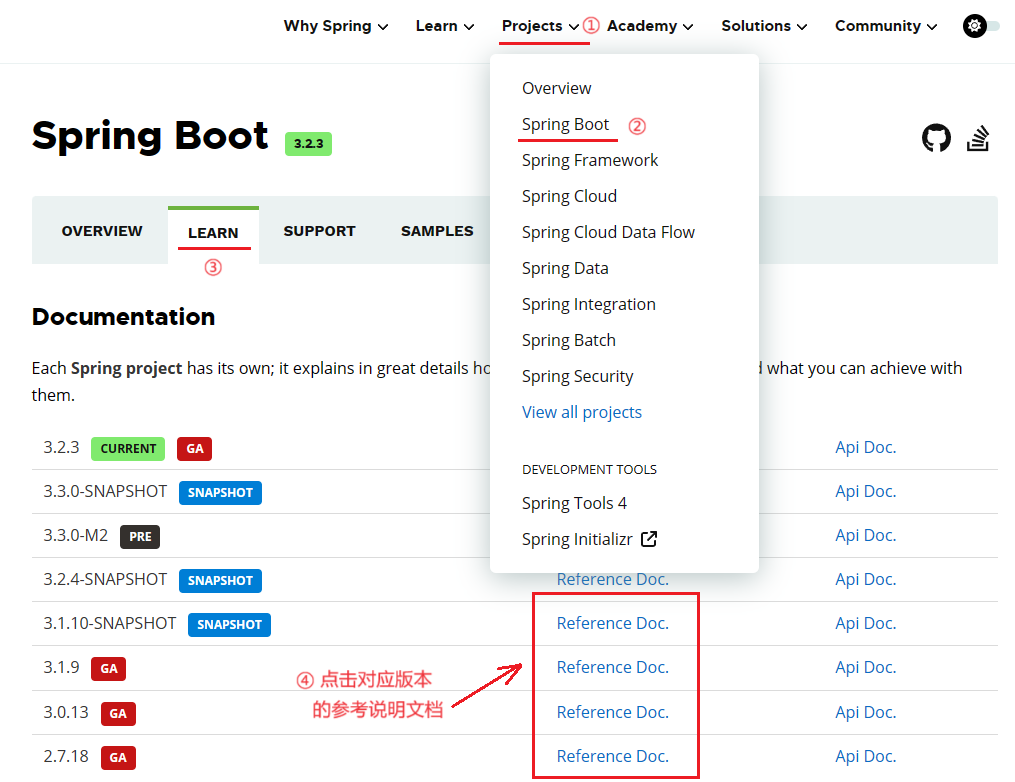
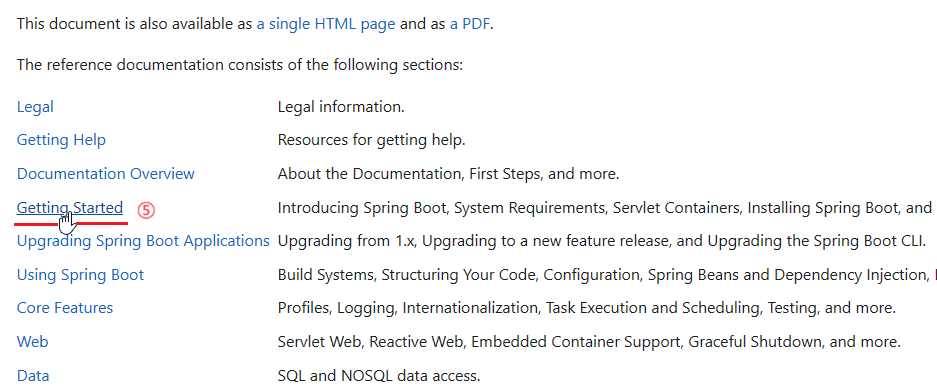
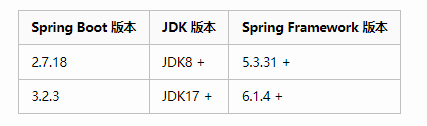
在 Spring官网 可以找到 SpringBoot 对应的 JDK 关系,但这种关系说明位于具体版本的参考手册(Reference Doc)中,按照以下图示顺序操作即可找到。
重大版本与JDK及Spring基础框架的对应关系表
3. 如何统一处理Web请求的JSON日期格式问题
方式一:编程式声明
在 JacksonAutoConfiguration 装配前, 先装配一个 Jackson2ObjectMapperBuilderCustomizer,并在这个 Customizer 中设置日期格式。如下所示:
@Configuration
@ConditionalOnClass(ObjectMapper.class)
@AutoConfigureBefore(JacksonAutoConfiguration.class) // 本装配提前于官方的自动装配
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public class JacksonConfig {@Beanpublic Jackson2ObjectMapperBuilderCustomizer myJacksonCustomizer() {return builder -> {builder.locale(Locale.CHINA);builder.timeZone(TimeZone.getTimeZone(ZoneId.systemDefault()));builder.simpleDateFormat("yyyy-MM-dd HH:mm:ss");}
} 方式二:配置式声明 <推荐>
参考下面的示例代码即可,关键之处是要指定 spring.http.converters.preferred-json-mapper 的值为 jackson, 否则配置不生效
spring:jackson:date-format: yyyy-MM-dd HH:mm:sslocale: zh_CNtime-zone: "GMT+8"http:converters:preferred-json-mapper: jackson ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄4. 如何以静态方式访问Bean容器
写一个实现了 ApplicationContextAware 接口的类,通过该接口的 setApplicationContext()方法,获取 ApplicationContext, 然后用一个静态变量来持有它。之后便可以通过静态方法使用 ApplicationContext 了。Spring 框架在启动完成后,会遍历容器中所有实现了该接口的Bean,然后调用它们的setApplicationContext()方法,将ApplicationContext(也就是容器自身)作为参数传递过去。下面是示例代码:
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;@Component
public class ApplicationContextHolder implements ApplicationContextAware {// 声明一个静态变量来持有 ApplicationContext private static ApplicationContext appContext;@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {ApplicationContextHolder.appContext = applicationContext;}public static ApplicationContext getContext() {return ApplicationContextHolder.appContext;}}5. 如何将工程打包成一个独立的可执行jar包
按以下三步操作即可(仅针对maven工程):
-
在 pom.xml 中添加 spring boot 的构建插件
-
为上一步的插件配置执行目标
-
在工程目录下,命令行执行 maven clean package -Dmaven.test.skip=true
<build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.1.6.RELEASE</version><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins>
</build>🔔 关于 spring-boot-maven-plugin 插件的版本问题
如果不指定版本,默认会去下载最新的,这极有可能与代码工程所用的 jdk 版本不兼容,导致打包失败。那么应该用哪个版本呢?一个简单的办法,是先进入到本机的 Maven 仓库目录,然后再分别打开以下两个目录
-
org/springframework/boot/spring-boot
-
org/springframework/boot/spring-boot-maven-plugin
再结合自己工程的spring-boot版本(可通过IDE查看),选择相同版本或稍低版本的plugin插件
6. 如何从jar包外部读取配置文件
在 Java 启动命令中添加 spring-boot 配置文件相关参数,指定配置文件的位置,如下所示:
java -jar xxxx.jar --spring.config.location={yaml配置文件绝对路径}  ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄指定外部配置文件还有其它一些方式,详情参见 SpringBoot项目常见配置
📌 特别说明:
--spring.config.location 这个配置项一定要写在 xxxx.jar 之后,因为这是一个 SpringApplication 的参数,不是 java 命令的参数或选项,该参数最终是传递到了 main 方法的 args 变量上,因此在 main 方法中构建 SpringApplication 实例时,务必要把 args 参数传递过去,比如下面这两种写法
/** 样例A */
public static void main(String[] args) {SpringApplication.run(OverSpeedDataInsightMain.class);
}/** 样例B */
public static void main(String[] args) {SpringApplication.run(OverSpeedDataInsightMain.class, args); ̄ ̄ ̄
}样例A由于没有传递args参数,因此通过命令行添加的 --spring.config.location 参数不会被SpringBoot实例读取到,在运行期间也就不会去读取它指定的配置文件了。
7. 如何同时启用多个数据源
方式一:手动创建多个My Batis的SqlSessionFactory
因为国内使用 MyBatis 框架最多,因此特别针对此框架单独说明。总体思路是这样的:
-
多个数据源,各有各的配置
-
针对每个数据源,单独创建一个 SqlSessionFactory
-
每个 SqlSession 各自扫描不同数包和目录下的 Mapper.java 和 mapper.xml
-
指定某个数据源为主数据源<强制>
样例工程部分代码如下,完整源码请访问码云上的工程 mybatis-multi-ds-demo
application.yml (点击查看)
spring:datasource:primary:driver: org.sqlite.JDBCurl: jdbc:sqlite::resource:biz1.sqlite3?date_string_format=yyyy-MM-dd HH:mm:ssminor:driver: org.sqlite.JDBCurl: jdbc:sqlite::resource:biz2.sqlite3?date_string_format=yyyy-MM-dd HH:mm:ss主数据源装配 (点击查看)
@MapperScan(basePackages = {"cnblogs.guzb.biz1"},sqlSessionFactoryRef = "PrimarySqlSessionFactory"
)
@Configuration
public class PrimarySqlSessionFactoryConfig {// 表示这个数据源是默认数据源,多数据源情况下,必须指定一个主数据源@Primary@Bean(name = "PrimaryDataSource")@ConfigurationProperties(prefix = "spring.datasource.primary")public DataSource getPrimaryDateSource() {// 这个MyBatis内置的无池化的数据源,仅仅用于演示,实际工程请更换成具体的数据源对象return new UnpooledDataSource();}@Primary@Bean(name = "PrimarySqlSessionFactory")public SqlSessionFactory primarySqlSessionFactory(@Qualifier("PrimaryDataSource") DataSource datasource) throws Exception {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();bean.setDataSource(datasource);// 主数据源的XML SQL配置资源Resource[] xmlMapperResources = new PathMatchingResourcePatternResolver().getResources("classpath:mappers/primary/*.xml");bean.setMapperLocations(xmlMapperResources);return bean.getObject();}@Primary@Bean("PrimarySqlSessionTemplate")public SqlSessionTemplate primarySqlSessionTemplate(@Qualifier("PrimarySqlSessionFactory") SqlSessionFactory sessionFactory) {return new SqlSessionTemplate(sessionFactory);}
}副数据源装配 (点击查看)
@Configuration
@MapperScan(basePackages = {"cnblogs.guzb.biz2"},sqlSessionFactoryRef = "MinorSqlSessionFactory"
)
public class MinorSqlSessionFactoryConfig {@Bean(name = "MinorDataSource")@ConfigurationProperties(prefix = "spring.datasource.minor")public DataSource getPrimaryDateSource() {// 这个MyBatis内置的无池化的数据源,仅仅用于演示,实际工程请更换成具体的数据源对象return new UnpooledDataSource();}@Bean(name = "MinorSqlSessionFactory")public SqlSessionFactory primarySqlSessionFactory(@Qualifier("MinorDataSource") DataSource datasource) throws Exception {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();bean.setDataSource(datasource);// 主数据源的XML SQL配置资源Resource[] xmlMapperResources = new PathMatchingResourcePatternResolver().getResources("classpath:mappers/minor/*.xml");bean.setMapperLocations(xmlMapperResources);return bean.getObject();}@Bean("MinorSqlSessionTemplate")public SqlSessionTemplate primarySqlSessionTemplate(@Qualifier("MinorSqlSessionFactory") SqlSessionFactory sessionFactory) {return new SqlSessionTemplate(sessionFactory);}
}方式二:使用路由式委托数据源 AbstractRoutingDataSource <推荐>
上面这种方式,粒度比较粗,在创建SqlSessionFactory时,将一组Mapper与DataSource绑定。如果想粒度更细一些,比如在一个Mapper内,A方法使用数据源A, B方法使用数据源B,则无法做到。
Spring 官方有个 AbstractRoutingDataSource 抽象类, 它提供了以代码方式设置当前要使用的数据源的能力。其实就是把自己作为 DataSource 的一个实现类,并将自己作为数据源的集散地(代理人),在内部维护了一个数据源的池,将 getConnection() 方法委托给这个池中对应的数据源。
DynamicDataSource.java
public class DynamicDataSource extends AbstractRoutingDataSource {/** 通过 ThreadLocal 来记录当前线程中的数据源名称 */private final ThreadLocal<String> localDataSourceName = new ThreadLocal<>();public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources) {super.setDefaultTargetDataSource(defaultTargetDataSource);super.setTargetDataSources(targetDataSources);}@Overrideprotected Object determineCurrentLookupKey() {return localDataSourceName.get();}public void setDataSourceName(String dataSourceName) {localDataSourceName.set(dataSourceName);}public void clearDataSourceName() {localDataSourceName.remove();}
}DynamicDataSourceConfig
@Configuration
public class DynamicDataSourceConfig {// 表示这个数据源是默认数据源,多数据源情况下,必须指定一个主数据源@Primary@Bean(name = "dynamic-data-source")@DependsOn(DataSourceName.FIRST)public DynamicDataSource getPrimaryDateSource(@Qualifier(DataSourceName.FIRST) DataSource defaultDataSource,@Qualifier(DataSourceName.SECOND) @Autowired(required = false) DataSource secondDataSource) {System.out.println("first=" + defaultDataSource + ", second = " + secondDataSource);Map<Object, Object> allTargetDataSources = new HashMap<>();allTargetDataSources.put(DataSourceName.FIRST, defaultDataSource);allTargetDataSources.put(DataSourceName.SECOND, secondDataSource);return new DynamicDataSource(defaultDataSource, allTargetDataSources);}@Bean(name= DataSourceName.FIRST)@ConfigurationProperties(prefix = "spring.datasource.first")public DataSource createFirstDataSource() {// 这个MyBatis内置的无池化的数据源,仅仅用于演示,实际工程请更换成具体的数据源对象return new UnpooledDataSource();}@Bean(name= DataSourceName.SECOND)@ConfigurationProperties(prefix = "spring.datasource.second")public DataSource createSecondDataSource() {// 这个MyBatis内置的无池化的数据源,仅仅用于演示,实际工程请更换成具体的数据源对象return new UnpooledDataSource();}}SwitchDataSourceTo
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface SwitchDataSourceTo {/** 数据源的名称 */String value() default DataSourceName.FIRST;}SwitchDataSourceAspect
@Aspect
@Component
public class SwitchDataSourceAspect {@AutowiredDynamicDataSource dynamicDataSource;@Around("@annotation(switchDataSourceTo)")public Object around(ProceedingJoinPoint point, SwitchDataSourceTo switchDataSourceTo) throws Throwable {String dataSourceName = switchDataSourceTo.value();try {dynamicDataSource.setDataSourceName(dataSourceName);System.out.println("切换到数据源: " + dataSourceName);return point.proceed();} finally {System.out.println("执行结束,准备切换回到主数据源");dynamicDataSource.setDataSourceName(DataSourceName.FIRST);}}
}Biz1Mapper
@Mapper
public interface Biz1Mapper {// 未指定数据源,即为「默认数据源」@Select("select * from user")List<UserEntity> listAll();@SwitchDataSourceTo(DataSourceName.FIRST)@Select("select * from user where id=#{id}")UserEntity getById(@Param("id") Long id);
}Biz2Mapper
@Mapper
public interface Biz2Mapper {@Select("select * from authority")@SwitchDataSourceTo(DataSourceName.SECOND)List<AuthorityEntity> listAll();// 本方法没有添加 SwitchDataSourceTo 注解,因此会使用默认的数据源,即 first// 但 first 数据源中没有这个表。该方法会通过在程序中手动设置数据源名称的方式,来切换@Select("select count(*) as quantity from authority")Integer totalCount();}完整源码请访问码云上的工程 mybatis-multi-ds-demo
方式三:使用 MyBatisPlus 的 多数据源方案 <推荐>
MyBatisPlus 增加了对多数据源的支持,详细做法请参考 MyBatis多数据源官方手册,它的底层原理与方式二一致,但特性更多,功能出更完善。若有兴趣的话,建议将这个多数据源的功能单独做成一个 jar 包或 maven 依赖。以使其可以在非 MyBatis 环境中使用。
多数据源切换引起的事务问题
对于纯查询类非事务性方法,上面的多数据源切换工作良好,一旦一个Service方法开启了事务,且内部调用了多个有不同数据源的Dao层方法,则这些数据源切换均会失败。原因为切换数据源发生在openConnection()方法执行时刻,但一个事务内只有一个Connection。当开启事务后,再次切换数据源时,由于已经有connection了,此时切换会无效。
因此解决办法为:先切换数据源,再开启事务。开启事务后,不能再切换数据源了。
8. 如何同时启用多个Redis连接
最简单的办法是直接使用 Redis官方的客户端库,但这样脱离了本小节的主旨。业务代码中使用spring 的 redis 封装,主要是使用 RedisTemplate 类,RedisTemplate 封装了常用的业务操作,但它并不关注如何获得 redis 的连接。这个工作是交由 RedisConnectionFactory 负责的。因此,RedisTemplate 需要指定一个 RedisConnectionFactory。由此可知,在工程中,创建两个RedisConnectionFactory, 每个连接工厂连接到不同的 redis 服务器即可。以下简易示例代码中,两个连接工厂连接的是同一个服务器的不同数据库。
创建两个 RedisConnectionFactory 和两个 RedisTemplate
@Configuration
public class RedisConfiguration {/** * 0号数据库的连接工厂* 本示例没有使用早期的 JedisConnectionFactory, 而是选择了并发性更好的 LettuceConnectionFactory, 下同*/@Primary@Bean("redis-connection-factory-db0") // 明确地指定 Bean 名称,该实例将作为依赖项,传递给相应的 RedisTemplate, 下同 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄public RedisConnectionFactory createLettuceConnectionFactory0() {// 这里使用的是单实例Redis服务器的连接配置类,// 哨兵与集群模式的服务器,使用对应的配置类设置属性即可。// 另外,这里没有演示通过yaml外部配置文件来设置相应的连接参数,因为这不是本小节的重点RedisStandaloneConfiguration clientProps = new RedisStandaloneConfiguration();clientProps.setHostName("localhost");clientProps.setPort(6379);clientProps.setDatabase(0);return new LettuceConnectionFactory(clientProps);}/** 1号数据库的连接工厂 */@Bean("redis-connection-factory-db1") ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄public RedisConnectionFactory createLettuceConnectionFactory1() {RedisStandaloneConfiguration clientProps = new RedisStandaloneConfiguration();clientProps.setHostName("localhost");clientProps.setPort(6379);clientProps.setDatabase(1);return new LettuceConnectionFactory(clientProps);}/** * 操作0号数据库的 RedisTemplate, * 创建时,直接将0号数据库的 RedisConnectionFactory 实例传递给它*/@Primary@Bean("redis-template-db-0")public RedisTemplate<String, String> createRedisTemplate0(@Qualifier("redis-connection-factory-db0") RedisConnectionFactory factory0) { ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(factory0);redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setValueSerializer(new StringRedisSerializer());return redisTemplate;}/** * 操作1号数据库的 RedisTemplate, * 创建时,直接将1号数据库的 RedisConnectionFactory 实例传递给它*/@Bean("redis-template-db-1")public RedisTemplate<String, String> createRedisTemplate1(@Qualifier("redis-connection-factory-db1") RedisConnectionFactory factory1) { ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(factory1);redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setValueSerializer(new StringRedisSerializer());return redisTemplate;}}多Redis连接的测试验证代码
@Component
@SpringBootApplication
public class MultiRedisAppMain {// 注入操作0号数据库的Redis模板@Resource(name = "redis-template-db-0")RedisTemplate redisTemplate0;// 注入操作1号数据库的Redis模板@Resource(name = "redis-template-db-1")RedisTemplate redisTemplate1;public static void main(String[] args) {SpringApplication.run(MultiRedisAppMain.class, args);}@EventListener(ApplicationReadyEvent.class)public void operateBook() {redisTemplate0.opsForValue().set("bookName", "三体");redisTemplate0.opsForValue().set("bookPrice", "102");redisTemplate1.opsForValue().set("bookName", "老人与海");redisTemplate1.opsForValue().set("bookPrice", "95");}
}本小节完整的示例代码已上传到 multi-redis-demo
9. 如何同时消费多个 Kafka Topic
9.1 同时消费同一 Kakfa 服务器的多个topic
这个是最常见的情况,同时也是最容易实现的,具体操作是:为 @KafkaListener 指定多个 topic 即可,如下所示
点击查看代码
/** 多个topic在一个方法中消费的情况 */
@KafkaListener(topics = {"topic-1", "topic-2", "topic-3"}, groupId = "group-1") ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public void consumeTopc1_2_3(String message) {System.out.println("收到消息 kafka :" + message);
}/** 不同 topic 在不同方法中消费的情况 */
@KafkaListener(topics = "topic-A", groupId = "group-1")
public void consumeTopicA(String message) {System.out.println("收到消息 kafka :" + message);
}/** 不同 topic 在不同方法中消费的情况 */
@KafkaListener(topics = "topic-B", groupId = "group-1")
public void consumeTopicB(String message) {System.out.println("收到消息 kafka :" + message);
}9.2 同时消费不同Kafka服务器的多个topic
这种情况是本小节的重点,与 spring 对 redis 的封装不同,spring 对 kafka 官方的 client lib 封装比较重,引入了以下概念
-
ConsumerFactroy
消费者工厂,该接口能创建一个消费者,它将创建与消息系统的网络连接
-
MessageListenerContainer
消息监听器容器,这是 spring 在 Consumer 之上单独封装出来的概念,顾名思义,该组件的作用是根据监听参数,创建一个消息监听器。看上去它似乎与 Consumer 组件要干的事一样,但在 spring 的封装结构里,consumer 实际上只负责连接到消息系统,然后抓取消息,抓取后如何消费,是其它组件的事,MessageLisntener 便是这样的组件,而 MessageListenerContainer 是创建 MessageListener 的容器类组件。
-
KafkaListenerContainerFactory
消息监听器容器的工厂类,即这个组件是用来创建 MessageListenerContainer 的,而 MessageListenerContainer 又是用来创建 MessageLisntener 的。
看了上面3个重要的组件的介绍,你一定会产生个疑问:创建一个监听器,需要这么复杂吗?感觉一堆的工厂类,这些工厂类还是三层套娃式的。答案是:如果仅仅针对 Kafka,不需要这么复杂。spring 的这种封装是要建立一套『事件编程模型』来消费消息。并且还是跨消息中间件的,也就是说,无论是消费 kafka 还是 rabbitmq , 它们的上层接口都是这种结构。为了应对不同消息系统间的差异,才引出了这么多的工厂类。
但不得不说,作为一个具体的使用者而言,这就相当于到菜单市买一斤五花肉,非得强行塞给你二两边角料,实得五花肉只有8两不说,那二两完全是多余的,既浪费又增加负担。spring 官方的这种封装,让它们的程序员爽了,但使用者的负担却是增加了。我们愿意花大把时间来学习 Spring Framework 和 Spring Boot 的编程思想和源代码,因为这两个是非常基础的通用框架。但是对具体产品的过渡封装,使用者大多是不喜欢的,因为我们可没那么多时间来学习它的复杂设计。毕竟这些只是工具的封装,不是一个可部署的产品。业务代码要基于它们来实现功能,谁也不想错误堆栈里全是一堆第三访库的类,而不是我们自己写的代码。尽管spring 的工具质量很好。但复杂的包装增加了使用难度,概念没有理解到位、某个理解不透彻的参数配置不对、某个完全没听说过的默认配置项在自己特定的环境下出错,这些因素导致的异常,都会让开发者花费巨大的时间成本来解决。因此,对于有复杂需求的同仁们,建议大家还是直接使用 kafka 官方提供的原生 client lib, 自己进行封装,这样可以做到完全可控。
回到主题,要实现同时连接多个不同的kafka服务器,提供相应服务器的 ConsumerFactory 即可。只是 ConsumerFactory 实例还需要传递给 KafkaListenerContainerFactory,最后在 @KafkaLisntener 注解中指定要使用的 KafkaListenerContainerFactory 名称即可。
连接多个 Kafka 服务器的组件配置类
@Configuration
public class KafkaConfiguration {@Primary@Bean("consumerFactory") ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄public ConsumerFactory createConsumerFactory() {Map<String, Object> consumerProperties = new HashMap<>();consumerProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");consumerProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());consumerProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());return new DefaultKafkaConsumerFactory<>(consumerProperties);}// 第二个消费工厂,为便于实操, 这里依然连接的是同一个 Kafka 服务器@Bean("consumerFactory2") ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄public ConsumerFactory createConsumerFactory2() {Map<String, Object> consumerProperties = new HashMap<>();consumerProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");consumerProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());consumerProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());return new DefaultKafkaConsumerFactory<>(consumerProperties);}@Primary// 自己创建的监听容器工厂实例中,一定要有一个实例的名字叫: kafkaListenerContainerFactory,// 因为 KafkaAnnotationDrivenConfiguration 中也默认配置了一个 KafkaListenerContainerFactory,// 这个默认的 KafkaListenerContainerFactory 名称就叫 kafkaListenerContainerFactory,// 其装配条件就是当容器中没有名称为 kafkaListenerContainerFactory 的Bean时,那个装配就生效,// 如果不阻止这个默认的KafkaListenerContainerFactory装备,会导致容器中有两个 KafkaListenerContainerFactory,这会引入一些初始化问题@Bean("kafkaListenerContainerFactory")public KafkaListenerContainerFactory<KafkaMessageListenerContainer> createContainerFactory1(ConcurrentKafkaListenerContainerFactoryConfigurer configurer,@Qualifier("consumerFactory") ConsumerFactory consumerFactory) { ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ConcurrentKafkaListenerContainerFactory listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory();configurer.configure(listenerContainerFactory, consumerFactory);return listenerContainerFactory;}// 第二个监听器容器工厂@Bean("kafkaListenerContainerFactory2")public KafkaListenerContainerFactory<KafkaMessageListenerContainer> createContainerFactory2(ConcurrentKafkaListenerContainerFactoryConfigurer configurer,@Qualifier("consumerFactory2") ConsumerFactory consumerFactory2) { ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ConcurrentKafkaListenerContainerFactory listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory();configurer.configure(listenerContainerFactory, consumerFactory2);return listenerContainerFactory;}
}连接多 Kafka 服务器的测试主程序
@Component
@EnableKafka
@SpringBootApplication
public class MultiKafkaAppMain {public static void main(String[] args) {SpringApplication.run(MultiKafkaAppMain.class, args);}@KafkaListener(topics = "topic1", groupId = "g1", containerFactory = "kafkaListenerContainerFactory") ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄public void consumeKafka1(String message) {System.out.println("[KAFKA-1]: 收到消息:" + message);}@KafkaListener(topics = "topic-2", groupId = "g1", containerFactory = "kafkaListenerContainerFactory2") ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄public void consumeKafka2(String message) {System.out.println("[KAFKA-2]: 收到消息:" + message);}@EventListener(ApplicationReadyEvent.class)public void init() {System.out.println("[MAIN]: 启动成功,等待Kakfa消息");}
}本小节完整的示例代码已上传到 multi-kafka-demo
10. 如何查看程序启动后所有的 Properties
方式一:遍历Environment对象
Spring Boot 中有个 Environment 接口,它记录了当前激活的 profile 和所有的「属性源」,下面是一段在 runtime 期间打印所有 properties 的示例代码
PrintAllPropetiesDemo.java(点击查看)
@Component
public class PrintAllPropetiesDemo {@ResourceEnvironment env;@EventListener(ApplicationReadyEvent.class)public void printAllProperties throws Exception {// 打印当前激活的 profileSystem.out.println("Active profiles: " + Arrays.toString(env.getActiveProfiles()));// 从「环境」对象中,获取「属性源」final MutablePropertySources sources = ((AbstractEnvironment) env).getPropertySources();// 打印所有的属性,包括:去重、脱敏StreamSupport.stream(sources.spliterator(), false).filter(ps -> ps instanceof EnumerablePropertySource).map(ps -> ((EnumerablePropertySource) ps).getPropertyNames()).flatMap(Arrays::stream)// 去除重复的属性名.distinct()// 过滤敏感属性内容.filter(prop -> !(prop.contains("credentials") || prop.contains("password"))).forEach(prop -> System.out.println(prop + ": " + env.getProperty(prop)));}
}方式二:查看 Spring Acuator 的 /env 监控页面 <推荐>
先引入 acuator 的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>然后在配置 acuator 的 web 访问 uri
@Bean
public SecurityWebFilterChain securityWebFilterChain(ServerHttpSecurity http) {return http.authorizeExchange().pathMatchers("/actuator/**").permitAll().anyExchange().authenticated().and().build();
}假定端口为8080, 则访问 http://localhost:8080/acuator/env 便能看到工程运行起来后所有的 properties 了
11. 如何申明和使用异步方法
在 SpringBoot 中使用异步方法非常简单,只要做以下同步
-
启用异步特性
-
在要异步执行的方法中,添加 @Async 注解
下面是一段示例代码
// 启用异步特性
@EnableAsync
public class BookService {@Async // 声明要异步执行的方法public void disableAllExpiredBooks(){....}
}📣 特别说明
以上代码确实可以让 disableAllExpiredBook() 方法异步执行,但它的执行方式是: 每次调用此方法时,都新创建一个线程,然后在新线程中执行这个方法。如果方法调用得不是很频繁,这个做法是OK的。但如果方法调用得很频繁,就会导致系统频繁地开线程,而创建线程的开销是比较大的。Spring 已经考虑到了这个场景,只需要为异步执行的方法指定一个执行器就可以了,而这个执行器通常都是一个具备线程池功能的执行器。示例代码如下:
@EnableAsync
public class BookService {@Async("bookExcutor") // 在注解中指定执行器 ̄ ̄ ̄ ̄ ̄ ̄ ̄public void disableAllExpiredBooks(){....}
}@Configuration
public class ExecutorConfiguration {// 装配书籍任务的通用执行器@Bean("bookExcutor") ̄ ̄ ̄ ̄ ̄ ̄ ̄public Executor speedingArbitrationExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(6);executor.setMaxPoolSize(24);executor.setQueueCapacity(20000;executor.setKeepAliveSeconds(30);executor.setThreadNamePrefix("书籍后台任务线程-");executor.setWaitForTasksToCompleteOnShutdown(true);// 任务队列排满后,直接在主线程(提交任务的线程)执行任务,异步执行变同步executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());return executor;}
}12. 如何快速添加 boot 的 maven 依赖项
Spring Boot 是一个以Boot为中心的生态圈,当我们指定了boot的版本后,如果要使用中生态圈中的组件,就不用再指定该组件的版本了。有两种方式可达到此目的。
-
方式一:项目工程直接继承 Boot Starter Parent POM
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.5</version>
</parent>-
方式二:在pom.xml的依赖管理节点下,添加 spring-boot-dependencies
<dependencies><!-- ② 这里添加starter依赖,但不用指定版本 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency>
</dependencies......<dependencyManagement><dependencies><!-- ① 在这里添加spring-boot的依赖pom --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>2.7.16</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>同理,如果要引入 Spring Cloud 生态圈中的相关组件,也建议通过「方式二」,把 spring-cloud-dependencies 加入到依赖管理节点下
13. 如何以静态方式获取 HttpServletRequest 和 HttpServletResponse
通过 spring-web 组件提供的 RequestContextHolder 中的静态方法来获取 HttpServletRequest 和 HttpServletResponse,如下所示:
import org.springframework.web.util.WebUtils;import org.springframework.web.context.request.RequestAttributes;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;public class WebTool extends WebUtils {public static HttpServletRequest getHttpRequest() {RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes(); ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes) requestAttributes;return servletRequestAttributes.getRequest();}public static HttpServletResponse getHttpResponse() {RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes(); ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes) requestAttributes;return servletRequestAttributes.getResponse();}
}14. 如何解决 ConfigurationProperties 不生效的问题
如果你在自己的 Properties 类上添加了 @ConfigurationProperties 注解,启动程序后没有效果,可参考下面这两种方法来解决:
-
方式一1. 在启动类添加 @EnableConfigurationProperties 注解
2. 在 @ConfigurationProperties 标注的类上添加 @Component 注解 (@Service注解也可以)
启动类
@SpringBootApplication
@EnableAutoConfiguration
@EnableConfigurationProperties
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public class MyBootApp {public static void main(String[] args) {SpringApplication.run(MyBootApp.clss, args);}
}自定义的 Properties 类
@Component
 ̄ ̄ ̄ ̄ ̄ ̄ ̄
@ConfigurationProperties(prefix="gzub.hdfs")
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public class HdfsProperties {private String nameNode;private String user;private String password;
}方式二1. 在启动类添加 @ConfigurationPropertiesScan 注解,并指定要扫描的 package2. 在自定义的 Properties 类上添加 @ConfigurationProperties(不需要添加 @Component 注解)
启动类
@SpringBootApplication
@ConfigurationPropertiesScan({"vip.guzb"})
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public class MyBootApp {public static void main(String[] args) {SpringApplication.run(MyBootApp.clss, args);}
}自定义的 Properties 类
@ConfigurationProperties(prefix="gzub.hdfs")
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public class HdfsProperties {private String nameNode;private String user;private String password;
}15. 如何统一处理异常
-
编写一个普通的Bean,不继承和实现任何类与接口
-
在该Bean的类级别上添加 @RestControllerAdvice 注解,向框架声明这是一个可跨 Controller 处理异常、初始绑定和视图模型特性的类
-
在类中编写处理异常的方法,并在方法上添加 @ExceptionHandler 注解,向框架声明这是一个异常处理方法
编写异常处理方法的要求如下:
方法是 public 的
方法必须用 @ExceptionHandler 注解修饰
方法的返回值就是最终返给前端的内容,通常是JSON文本
方法参数中,需指定要处理的异常类型
-
如果需要对特定异常做特殊的处理,则重复第3步
下面是一较完整的示例代码(点击查看)
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import org.springframework.http.ResponseEntity
import org.springframework.http.HttpStatus;@RestControllerAdvice
public class MyGlobalExceptionHandlerResolver {/** 处理最外层的异常 */@ExceptionHandler(Exception.class)public ResponseEntity<ErrorResponse> handleException(Exception e) {List details = new ArrayList();details.add(e.getMesssage());ErrorResponse error = new ErrorResponse(e.getMessage, details);return new ResponseEntity<>(error, HttpStatus.BAD_REQUEST);}/** 处理业务异常,这里使用了另外一种方式来设置 http 响应码 */@ExceptionHandler(BusinessException.class)@ResponseStatus(HttpStatus.HTTP_BAD_REQUEST)public ErrorResponse handleException(BusinessException e) {List details = new ArrayList();details.add(e.getBackendMesssage());return new ErrorResponse(e.getFrontendMessage(), details);}
}/** 返回给前端的错误内容对象 */
public class ErrorResponse {private String message;private List<String> details;......
}/** 业务异常 */
public class BusinessException extends RuntimeException{private String frontendMessage;private String backendMessage;......
}16. 应该对哪些异常做特殊处理
对于Web开发而言,我们应该在全局异常处理类中,对以下异常做特殊处理
-
Exception
-
BusinessExecption
-
HttpRequestMethodNotSupportedException
-
HttpClientErrorException
-
FeignException
-
ConstraintViolationException
-
ValidationException
17. 异常处理组件应该具备的特性
-
业务异常处理
异常信息中,要明确区分出前端展示内容与后端错误内容
后端错误内容可再进一步分为「错误的一般描述信息」和「详细的错误列表」
前后端错误信息中,应过滤敏感内容,如身份证、密码等,且过滤机制提供开关功能,以方便开发调试
异常信息中,应该包含业务流水号,便于调试和排查线上问题时,将各个节点的错误内容串联起来
多数情况下,业务异常都不应该打印堆栈,只需要在日志中输出第一个触发业务异常的代码位置即可
因为业务异常是我们在编码阶段就手动捕获了的,也就是说,这些异常是可预期的,并且是我们自己手动编码抛出的。因此,只需要输出该异常的抛出点代码位置,异常堆栈是没有意义的,它只会增加日志的存储体积
另外,多数业务异常都是在检查业务的执行条件时触发的,比如:商品不存在、库存不足、越权访问、输入数据不合规等。且这类错误会频繁发生,若输出其堆栈的话,日志中会大量充斥着这样的异常堆栈。它既增加了日志的存储体积,也干扰了正常日志内容的查看
异常信息中,要详细记录错误内容,尽可能把异常现场的信息都输出。这是开发人员最容易给自己和他人挖坑的地方,比如:一个业务异常的日志输出内容是这样:“积分等级不够”。这个异常信息是严重不足的,它缺少以下这些重要信息,以致极难在线上排查问题:
谁的积分等级不足
这个用户当前的积分是多少
他要拥有多少积分,和什么样的等级
他在访问什么资源
注意:您可能会有疑问,把用户账号输出到日志就可以了,没必要输出它当前的积分,因为积分可以去数据库查。但这样做是不行的,因为:
生产环境的数据库研发人员是不能直接访问的,让运维人员查,效率不高还增加运维工作量
数据查询出来的值,也不是发生异常当时的值,时光荏然,你大妈已经不你大妈了 😁
即使是个相对静态(变动不频繁)的参数,运行期代码所使用的值,也极有可能与数据库中不一致。比如程序启动时,没有从数据库中加载,而是使用了默认值,又或者是某个处理逻辑将它的值临时改变了
-
非业务异常
尽可能地捕获所有异常
一定要在日志中输出非业务异常的堆栈<重要>
尽量不要二次包装非业务异常,如果一定要包装,「务必」在将包装后的异常 throw 前,先输出原始异常的堆栈信息
18. 为什么出错了却没有异常日志
在 WebMVC 程序中,通常都有一全局异常处理器(如15小节所述),因此,有异常一定是会被捕获,并输出日志的。不过,这个全局异常处理器,仅对Web请求有效,如果是以下以下情况,则需要在代码中手动捕获和输出异常日志:
-
在非WEB请求的线程中运行的代码比如定时任务中的代码所产生的异常。如果没有捕获和输出异常日志,那么发生了异常也不知道,只能从结果数据上判断,可能发生了错误,但却无法快速定位。
-
从Web请求线程中脱离出来的异步线程中的代码这种情况更常见,同时也要非常小心。比如异步发送短信,异步发邮件等,一定要做好异常处理
19. 如何处理异常日志只有一行简短的文本
比如下面这个经典的场景
java.lang.NullPointerException异常信息只有这么一行,没有代码位置,没有causedException, 更没有堆栈。这是因为JVM有个快速抛出(FastThrow)的异常优化:如果相同的异常在短时间内集中大量throw,则将这些异常都合并为同一个异常对象,且没有堆栈。
解决办法为:java 启动命令中,添加-OmitStackTraceInFastThrow这个JVM选项,如:
java -XX:-OmitStackTraceInFastThrow -jar xxxx.jar📌 说明1
JVM只对以下异常做FastThrow优化
NullPointerException
ArithmeticException
ArrayStoreException
ClassCastException
ArrayIndexOutOfBoundsException
📌 说明2
出现此问题,基本上意味着代码有重大缺陷,跟死循环差不多,不然不会出现大量相同的常集中抛出。另外,开启该选项后,若这种场景出现,是会刷爆日志存储的。当然,相比之下找到问题更重要,该选项是否要在生产环境开启,就自行决定吧。
20. 如何解决同一实例内部方法调用时,部分事务失效的问题
事务失效示例代码(点击查看)
@Service
public class BookService {@ResourceBookDao bookDao;public void changePrice(Long bookId, Double newPrice) {doChangePrice(bookId, newPrice);logOperation();sendMail();}@Transactional(rollbackFor = Exception.class)public void resetPrice(Long bookId, Double newPrice) {doChangePrice(bookId, newPrice);logOperation();sendMail();}@Transactional(rollbackFor = Exception.class)public void doChangePrice(Long bookId, Double newPrice) {bookDao.setPrice(bookId, newPrice);}@Transactional(rollbackFor = Exception.class)public void logOperation(Long bookId, Double newPrice) {.... // 省略记录操作日志的代码}public void sendMail(Long bookId, Double newPrice) {.... // 省略发送邮件的代码}
}上述代码,调用 changePrice() 方法时,如果 sendMail() 方法在执行时发生了异常,则前面的 doChangePrice() 和 logOperation() 所执行的数据库操作均不会回滚。但同样的情形如果发生在 resetPrice() 方法上,doChangePrice() 和 logOperation() 均会回滚。
这个例子还可以进行更细化的演进,不过核心原因都是一个:Spring 对注解事务的实现手段,是通过 CGLib 工具库创建一个继承这个业务类的新类,捕获原业务类方法执行期间的异常,然后执行回滚的。但是对原业务类中,方法内部对其它方法的调用,这个被调用的方法,其上的事务注解则不再生效。如果直接在外部调用这些方法,则事务注解是生效的。
以上面的示例代码为准, changePrice() 方法内部分别调用了 doChangePrice()、logOperation()、sendMail() 三个方法,但由于 changePrice() 方法本身并没有添加事务注解,因此,它内部调用的 doChangePrice()、logOperation() 这两个方法的事务注解是不生效的。因此,实际上执行过程都没有开启事务。当然,如果是从外部直接单独调用 doChangePrice() 和 logOperation(),则二者的事务均生效。
解决办法:在外部单独调用这些有事务注解的方法。如果需要将这些方法组合在一个方法体内,整体完成一个业务逻辑,也在其它类中创建方法,在该方法中调用这些有事务注解的方法完成逻辑组织。
21. 如何阻止某个第三方组件的自动装配
方法一:配置 @SpringBootApplication 注解的 exclude 属性
如下代码所示:
// 启动时,将Spring官方的数据源自动装配排除
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
public class MyAppMain{public static void main(String[] args) {SpringApplication.run(MyAppMain.class, args);}
}方法二:在配置文件中指定 <推荐>
方法一需要修改代码,对于普通的业务系统而言,是能不改代码就坚决不改。因此推荐下面这种配置的方式来指定:
spring:autoconfigure:# 指定要排除的自动装配类,多个类使用英文逗号分隔exclude: org.springframework.cloud.gateway.config.GatewayAutoConfiguration方法三:临时注释掉该组件的 @EnableXXX 注解比如常见的 @EnableConfigurationProperies 、@EnalbeAsync 、@EnableJms 等,在代码中临时注释掉这些注解即可。但仅适用于提供了这种 Enable 注解方式装配的组件。
未完待续~~~
文章转载自:顾志兵
原文链接:https://www.cnblogs.com/guzb/p/spring-boot-common-development-issue-solution-list.html
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构