在linux控制台跑spark on yarn一个测试案例,日志中总显示RM连yarn服务的时候是:0.0.0.0:8032
具体情况如下图:

我问题出现的原因,总结如下:
1.防火墙没关闭,关闭
2.spark-env.sh这个文件的YARN_CONF_DIR=/opt/module/hadoop-3.3.4/etc/hadoop 没写对,这个很关键,报错就是因为这
3.安有yarn服务器的那台节点的/etc/hostname文件中,没配hadoop103
这3个都没问题了,再跑
[dahua@hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10[dahua@hadoop102 spark-yarn]$ bin/spark-submit \
--class com.atguigu.wrodcount_case.WordCountYarn \
--master yarn \
./Spark-1.0-SNAPSHOT.jar \
/input \
/output
备注:上面标黄的三个地方是每次提交要改的地方,第一个是指明类路径,第二个是jar包名,第三个是HDFS输出路径,不能已存在。
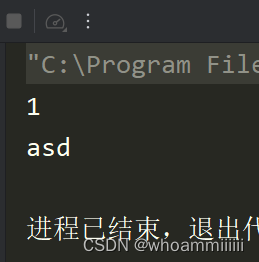
成功!!!!

嘿嘿~
备注:写的workCount案例yarn模式不能直接在IDEA上运行,报错如下:
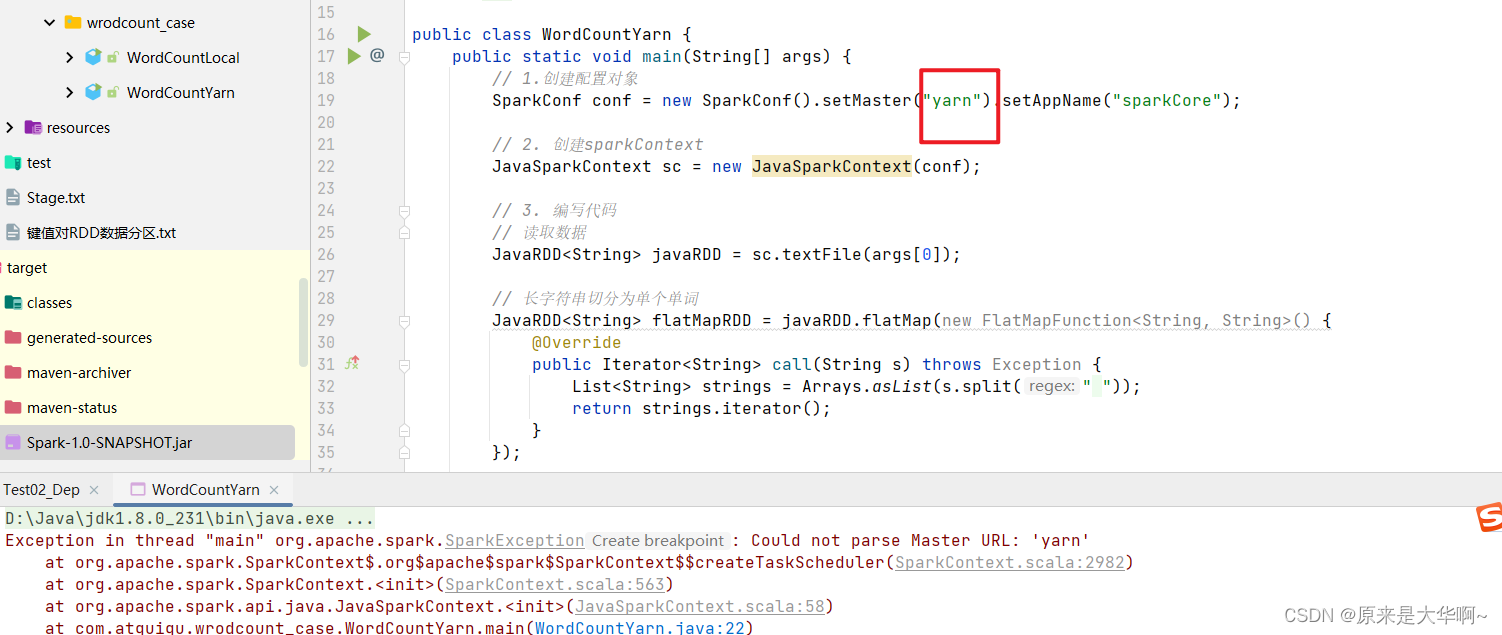
Exception in thread "main" org.apache.spark.SparkException: Could not parse Master URL: 'yarn'at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$createTaskScheduler(SparkContext.scala:2982)at org.apache.spark.SparkContext.<init>(SparkContext.scala:563)at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)at com.atguigu.wrodcount_case.WordCountYarn.main(WordCountYarn.java:22)