前言
今天继续来看看有关 Redis 的一个问题,主从复制。通常,对于大多数的场景来说,读比写更多,于是对于缓存的水平扩展,其中的一个方式 “主从复制” 就是一个常见的思路。有了主从复制,那么可以扩展出很多从节点来应对大量的读请求。那么问题来了 Redis 的主从复制是如何实现的呢?
PS:本文仅关心复制的机制,不关心主节点下线重新选等等异常情况。
前置知识
-
你需要知道 Redis 的持久化方式,RDB 和 AOF
-
Redis 执行命令的基本思路
审题
题目本身不复杂,提问者问这个问题的想法可能会有下面几个方面:
-
了解 Redis 的主从复制机制的话,如果在实际使用过程中出现问题就更容易排查。
-
在设计复制机制的时候需要注意和考虑什么问题。
-
这样的设计是否能应用在别的场景中。
尝试思考
假设你完全没有看过 Redis 源码来思考这个问题,可以从下面几个角度去尝试分析,并猜测答案。
-
首先,想到一个关系户,也就是我们常用的 Mysql,它也有主从复制,如果你了解 binlog 那么可以尝试从这里着手,虽然不同,但思路应该是差不多的。
-
然后,简化问题,主从复制,无非就是将数据发送过去,对方接受保存。
-
不可能每次都复制的是全量数据,那么肯定需要有机制去确保如何每次复制增量的数据。
-
复制的是什么?
-
复制的是数据本身?数据只要变动就将变动的 kv 直接扔给从节点?
-
复制的是执行命令?将客户端执行的命令发送给子节点执行一次?
-
解决
有了上面的思考,其实实际也就有思路的。首先主从复制肯定有两种情况,一种就是第一次复制,也就是要执行一次全量复制,将主节点的所有数据到复制到从节点上去;另一种就是增量复制,在数据同步之后后续的增量数据保持同步。
全量同步
持久化数据
因为需要全量同步所有数据,我们知道 Redis 数据在内存里面,既然要发送,那势必需要先持久化一次。也就是先 SYNC 一遍,通过方法 startBgsaveForReplication 来完成的。
代码位置在:https://github.com/redis/redis/blob/14f802b360ef52141c83d477ac626cc6622e4eda/src/replication.c#L855
这个问题不大, 就是保存一个 RDB 文件。
发送数据
这个也很不难,就是将数据直接扔过去就好了。
代码位置在:https://github.com/redis/redis/blob/14f802b360ef52141c83d477ac626cc6622e4eda/src/replication.c#L1402
增量同步
后续的任务就是增量同步后续产生的数据了。在猜测时我们想到有两种复制方式,一种是直接复制数据,这种方式复制 RDB 是可行,在全量同步的时候用这个肯定更好,如果同步命令那么从节点还需再执行一次过于复杂和麻烦,还耗时。而对于后续的增量同步来说,肯定是同步命令来的更高效(不过还是得看实际)。
下面就是传播命令的方法:
/* Propagate the specified command (in the context of the specified database id)* to AOF and Slaves.** flags are an xor between:* + PROPAGATE_NONE (no propagation of command at all)* + PROPAGATE_AOF (propagate into the AOF file if is enabled)* + PROPAGATE_REPL (propagate into the replication link)** This is an internal low-level function and should not be called!** The API for propagating commands is alsoPropagate().** dbid value of -1 is saved to indicate that the called do not want* to replicate SELECT for this command (used for database neutral commands).*/static void propagateNow(int dbid, robj **argv, int argc, int target) {if (!shouldPropagate(target))return;/* This needs to be unreachable since the dataset should be fixed during* replica pause (otherwise data may be lost during a failover) */serverAssert(!(isPausedActions(PAUSE_ACTION_REPLICA) &&(!server.client_pause_in_transaction)));if (server.aof_state != AOF_OFF && target & PROPAGATE_AOF)feedAppendOnlyFile(dbid,argv,argc);if (target & PROPAGATE_REPL)replicationFeedSlaves(server.slaves,dbid,argv,argc);}
这个方法就是将增量命令传播给 AOF 和 Slaves,AOF 就是持久化的另一种方式,而 Slaves 就是我们需要同步的从节点了。具体 replicationFeedSlaves 方法就不具体看了。
监控状态
这个其实是我们在猜测的时候漏掉的,想来也是,master 肯定需要知道 slave 的状态,如果连不上了,肯定要处理,在 replication.c 中有这样一个方法:
/* Replication cron function, called 1 time per second. */void replicationCron(void) {
看名字和注释就秒懂了,每秒执行一次的同步定时任务。
而其中调用了 replicationFeedSlaves 方法,也就是 PING 一下,看看活着没:
replicationFeedSlaves(server.slaves, -1, ping_argv, 1);可能导致的问题
第一次同步 RDB 时间太长?
如果我们 redis 存放的数据很多,第一次同步会有两个时间,一个是 bgsave 的时间,这个时间其实还好,毕竟平时就是要执行的,而第二个时间就是传输数据的时间,这个时间就取决于带宽了。
不过首先这个操作时,主节点依旧可以被读写,只不过操作均被缓存了,所以倒是不必担心这段时间无法被使用。难就在如果数据过多可能真的会导致一个问题就是,同步->超时->重试,然后不断循环,所以为了避免这样的情况出现,建议 Redis 前往别直接把主机全部内存吃完。通常 maxmemory 设置为 75% 就相对不会出现问题,也不容易 OOM。
当然,有人肯定会问,能不能直接先手动拷贝 RDB 文件来减少同步时间,实际操作过我告诉你,不要手动操作,容易出现意想不到的问题,当出现问题之后,数据还是会不同步,还是会执行重新同步,还不如第一次就手动让程序自己来。
优化
传播 cache
命令在传播的阶段设置了主从同步发送的缓冲区,通过维护一个缓冲区来保证当主节点无需等待,从节点自己凭实力拿就好了,即使有一段时间突然抖动了一下,也没事,缓冲区里面还有,继续同步就行嘞。但当完全超过缓冲区的承受范围,那么还是需要执行一次全量同步来保证数据一致。
无盘加载
之前看代码的时候就注意到了一个参数 repl_diskless_sync 翻译过来就是无盘同步,显然这个优化是 Redis 注意到第一次同步的时候,如果马上写入 RDB 显然是有点慢了,直接 dump 内存肯定会来的更快,所以这就是无盘,也就是不先落盘。
总结
最后用一张图来总结整个过程:
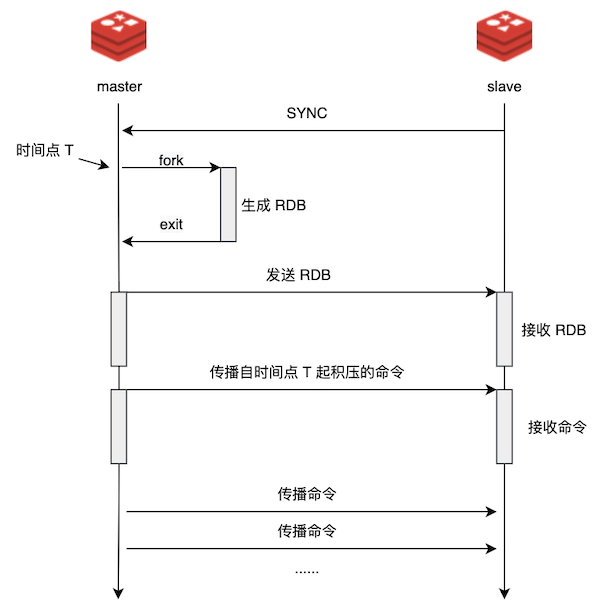
我们看着这个图我们也可以想到,其实这样复制的策略在绝大多数复制的场景中都是适用的,如果实际没有命令这个说法,那就将数据拆分成小块(chunk)来同步。需要注意点和优化点可能 Redis 都帮你想好了,对着抄就可以了。所以,我称为一种设计为 ”单向同步“,那么如果什么是多向同步呢?也就是多个人同时编辑或操作数据,互相同步的策略,此时就需要一些 diff 算法和策略了,你也可以考虑设计看看,看具体会遇到什么问题。
原文链接:https://www.linkinstars.com/post/9ddfbd5e.html