文章目录
- 集合
- Set集合
- TreeSet集合
- Map集合
- 概述
- 特点
- 子类及其底层数据结构
- 常用方法
- 遍历
- 数据结构
- 常见的数据结构
- 二叉树
- 可变参数
- 介绍
- 格式
- 注意
- Collections工具类
- 方法
- 排序查找算法
- 冒泡排序
- 介绍
- 原理
- 注意
- 代码
- 选择排序
- 介绍
- 原理
- 规律
- 代码
- 二分查找
- 前提
- 介绍
- 原理
- 注意
- 代码
集合
Set集合
TreeSet集合
底层结构:红黑树结构
存储的元素会按照规则进行排序
- 在TreeSet集合中存储:String,Integer,Double,Character //JDK提供的类型
- 都默认实现了java.lang.Comparable接口(自带自然排序规则)
- 在TerrSet集合中存储:自定义类型 //程序员自己定义的
- 就必须保证自定义类型,要实现Comparable接口,并重写compareTo方法
- 如果自定义类型没有实现Comparable接口,在遍历set集合时会发生异常
- compareTo方法
//比较大小 0 相同 负数表示小 整数表示大
public int compareTo(E e){//自然排序规程//返回结果有三种:0,负数,正数(底层红黑树需要)
}
排序规则:
- 自然排序:元素需要实现Comparable接口
- 比较器排序:元素不需要实现Comparable接口,需要在创建TreeSet对象时,指定排序规则
构造方法
public TreeSet() //默认使用自然排序
public TreeSet(Comparator c) //指定比较器对象
比较器:Comparator接口(泛型接口)
int compare(Object o1,Object o2) //比较俩个元素的大小: 0,正数,负数
o1:要存储的元素
o2:已存在的元素
Map集合
概述
是一个存储成对数据的集合,称之为双列集合。Collection称之为单列集合
存储的数据,称之为键值对(Entry),底层key=value存在
特点
- 可以存储2个元素(键值对元素)
- key元素不能重复,value元素可以重复
- 一个key元素只能对应一个value元素(一一对应),能通过key找到value
- 存储元素不保证顺序
- 没有索引
子类及其底层数据结构
java.util.Map(接口)
- HashMap:底层使用哈希表
- LinkedHashMap:底层使用哈希表+链表
- TreeMap:底层使用红黑树
HashSet底层实现就是HashMap的键值完成的,同理其他俩个也是
常用方法

添加和修改都是put;修改需要在键的位置写上进行修改的键值即可
遍历
不能直接遍历,只能间接性实现遍历操作
- 键找值方式
- 获取Map集合中所有的key元素,遍历所有的key,通过key元素找到对应的value元素
Map对象.keySet();
- 键值对对象
- 获取Map集合中所有的Map.Entry对象,遍历所有的Entry对象,通过Entry中的API获取key,value
Map对象.entrySet();
键要唯一,所有键的存储对象为自定义对象时,要重写hashCode和equals方法
TreeMap参考TreeSet
数据结构
常见的数据结构
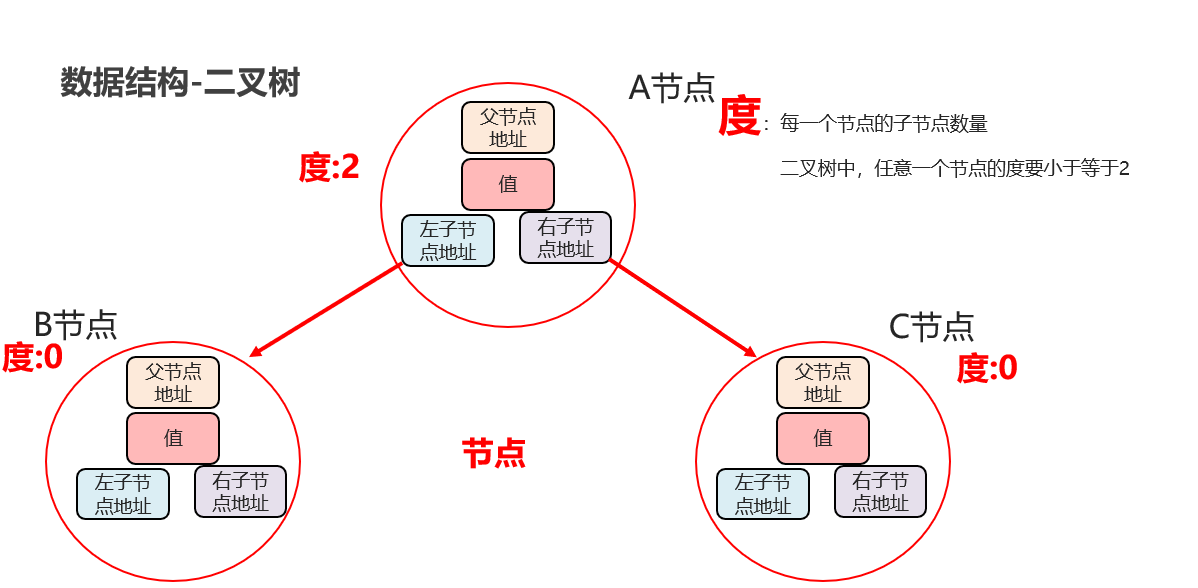
二叉树
二叉查找树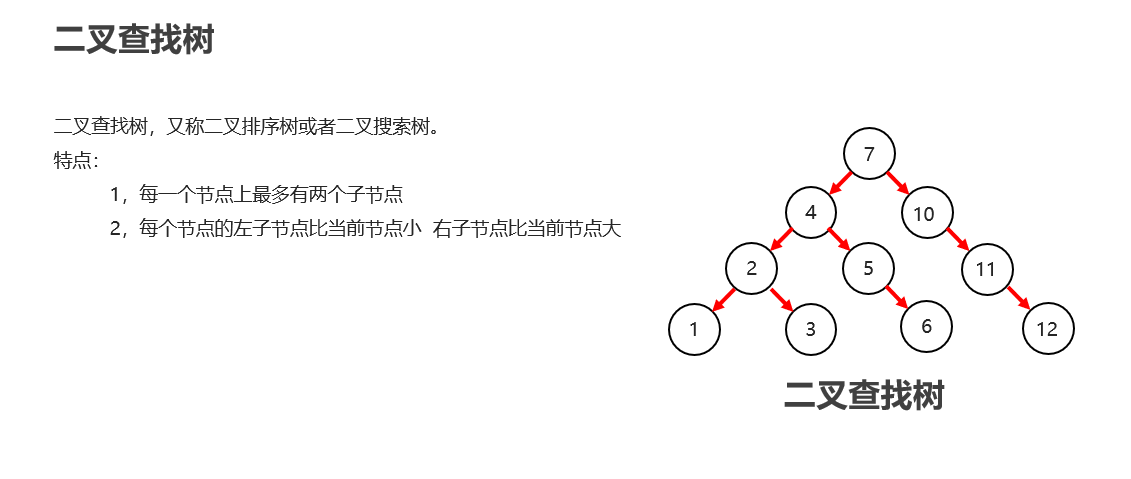
规则:小的存左边,大的存右边,一样的不存
平衡二叉树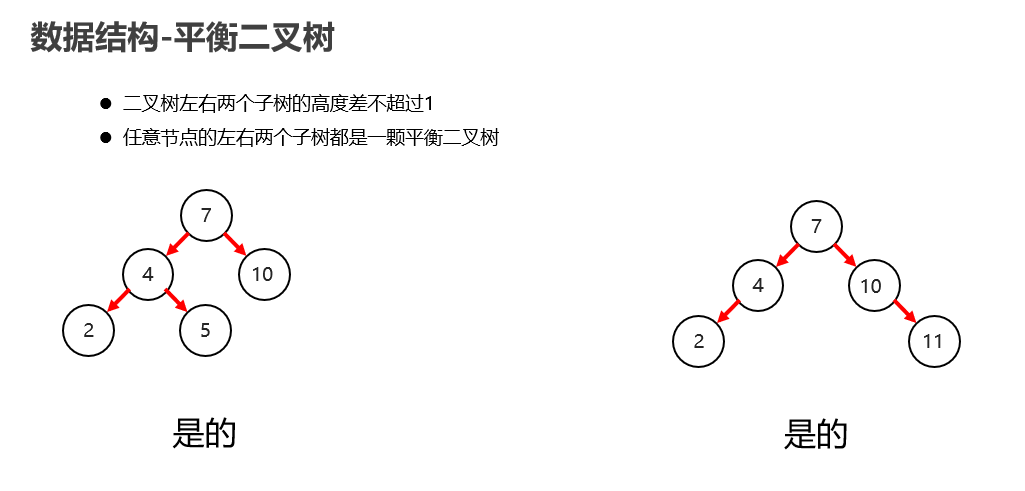

红黑树(平衡二叉B树)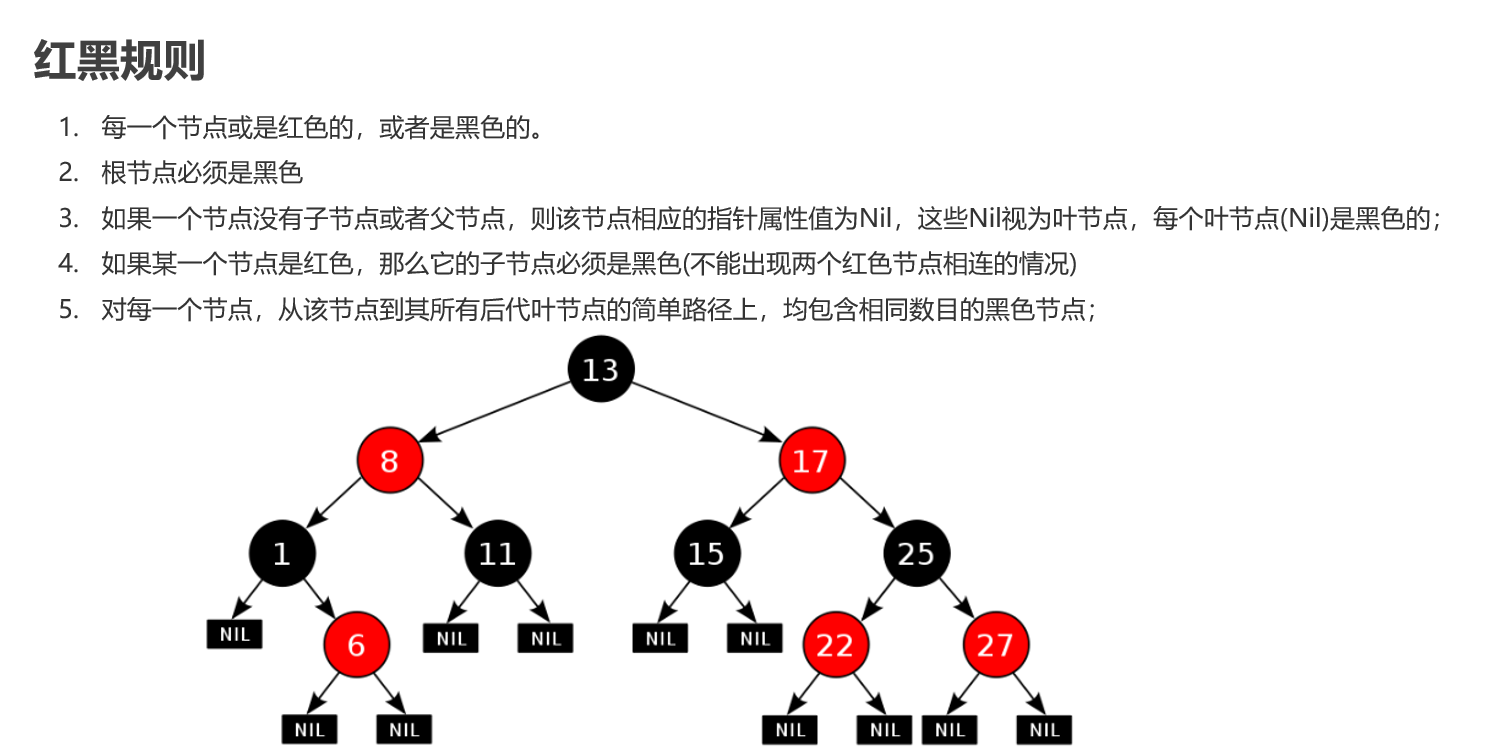
可变参数
介绍
在调用方法是传入任意个参数,底层是使用数组
格式
public 返回值类型 方法名(参数类型... 参数名){//...就是可变参数的语法表示格式
}
注意
- 可变参数只能作为方法的最后一个参数,前面可以有也可以没有参数
- 可变参数本质上是数组,不能作为方法的重载。(一个方法参数为可变参数,有一个相同方法参数为参数名相同的数组)
Collections工具类
- 不能创建对象
- 提供了静态方法
- 针对List,Set集合进行相关操作(排序,二分查找,添加元素…)
方法
static <T> boolean addAll(Collection<T> c, T... elements)
//添加任意多个数据到集合中
排序查找算法
冒泡排序
介绍
将一组数据按照升序规则进行排序
原理
相邻的数据俩俩比较,大的放后面
注意
- 如果有n个数据进行排序,总共需要比较n-1轮
- 每一次比较完毕,下一次的比较就会少一个数据参与
代码
int[] arr = {5,3,2,6,1};//数组中有n个元素,进行n-1轮排序for (int i = 0; i < arr.length - 1; i++) {//第一轮:3,2,5,1,6//第二轮:2,3,1,5,6//第三轮:2,1,3,5,6//第四轮:1,2,3,5,6for (int j = 0; j < arr.length - 1 - i; j++) {if (arr[j] > arr[j + 1]){int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}System.out.println(Arrays.toString(arr));
选择排序
介绍
将一组数据进行升序或降序排序
原理
每一次从待排序的数据元素中选出最小的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。
规律
- 有n个元素,就要比较n-1轮
- 每一轮中都会选出一个最值元素,较前一趟少比较一次
代码
//升序
int[] arr = {5,8,3,6,1};for (int i = 0; i < arr.length - 1; i++) {for (int j = i + 1; j < arr.length; j++) {if (arr[i] > arr[j]){int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}}}System.out.println(Arrays.toString(arr));
//降序的话只需改成arr[i] < arr[j]即可
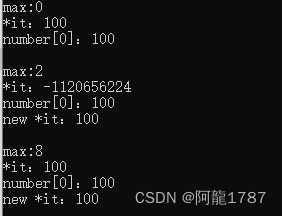
二分查找
前提
数组中的元素需要有序
介绍
也叫折半查找,是在一组有序(升序/降序)的数据中查找一个元素,它是一种效率较高的查找方法
原理
将目标元素与查找氛围的中间值作比较,将目标元素分到较大/较小的一组,重复上诉步骤,知道目标元素=中间值
注意
- 查找的过程中,min<=max作为循环的条件,当min>max时,循环结束,查找元素不存在
- 利用mid=(min+max)/2索引来确定中间值
- 如果目标数>中间值,说明在右边,min=mid+1
- 如果目标数<中间值,说明在左边,max=mid-1
代码
public static void main(String[] args) {int[] arr = {2,4,6,8,9,11,15,36,59};int msg = binarySearch(arr,1);if (msg < 0){System.out.println("目标数不存在");}else {System.out.println("目标数存在,索引为" + msg);}}public static int binarySearch(int[] arr,int key){int min = 0;int max = arr.length - 1;while (min <= max){int mid = (min + max) / 2;if (key == arr[mid]){return mid;}else if (key > arr[mid]){min = mid + 1;}else {max = mid -1;}}return -1;}