医学图像分类目前面临的挑战
- 医学图像分类需要研究人员同时具备医学图像分析和数字图像的知识背景。
- 由于图像尺度、数据格式和数据类别分布的影响,现有的模型方法,如传统的机器学习的识别方法和基于深度卷积神经网络的方法,取得的识别准确度和泛化性是有限的。
- 实际场景中,由于医学图像数据的标记成本问题和病例医学图像采集问题,能够获得的有标签医学图像数据是有限的。
现有的医学图像分类方法
- 基于统计的分类。分为有监督和无监督两种方式。有监督的统计分类方式通常会将数据划分成训练集和测试集,然后来预测数据的类别标签。常见的概率算法(有监督):最近邻算法、贝叶斯算法;无监督则通过特征分布来区分数据的类别:K均值聚类和模糊聚类算法。
- 基于规则的分类。根据设定的一系列规则对特征向量进行分析,后续的过程根据任务的属性设置相应的决策。
- 支持向量机。核心思想是寻找给定两个类别之间的最优分离边界。SVM不仅可以用于线性分类场景,还可以在核函数的基础上进行非线性的分类
基于神经网络的分类模式是目前主流的医学图像分类方式,它也可以分为有监督和无监督两种方式。
- 有监督的情况下,训练神经网络使得它为每个输入数据分配一个类别标签,然后通过神经网络的预测输出和实际标签之间的误差(即损失函数)来调整神经网络的参数。
- 在无监督的情况下,训练样本并不需要有明确的标签信息,神经网络主要探究数据的底层结构和类别实例之间的关联性,根据样本的相似度或不相似度将其划分为一个个簇。
卷积神经网络在医学成像分类过程中的使用方式:
- 直接进行训练;
- 迁移学习或者微调;
- 特征提取器(深度卷积神经网络会移除分类层,将卷积层的输出作为输入图像的特征表示)
卷积神经网络结构
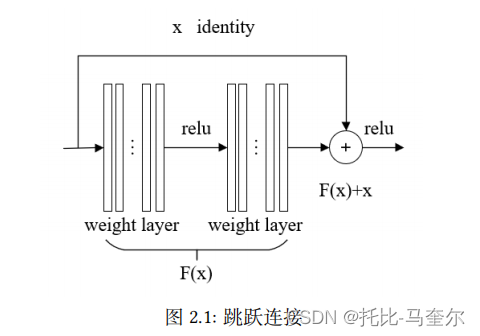
残差网络
64通道卷积神经网络
64通道卷积神经网络由四个卷积模块组成,每个卷积模块都包含了一个卷积层、一个批归一化层和一个激活层。此外,对于前两个卷积模块,它们还包含一个额外的2*2最大池化层。卷积层对应的卷积核大小为3*3,通道数为64,卷积核在特征图上的滑动步长为1.
批归一化层在这里的目的是为了对每一批处理的数据进行约束,在一定程度上减少了模型在训练过程中发生过拟合的风险,增强模型的泛化能力。
激活层则是为模型引入非线性元素,同时对于模型参数反向传播时出现梯度消失和爆炸现象起着一定的缓解作用。前两个卷积模块包含的最大池化层主要的作用是对特征图进行下采样。
Transformer
整体结构
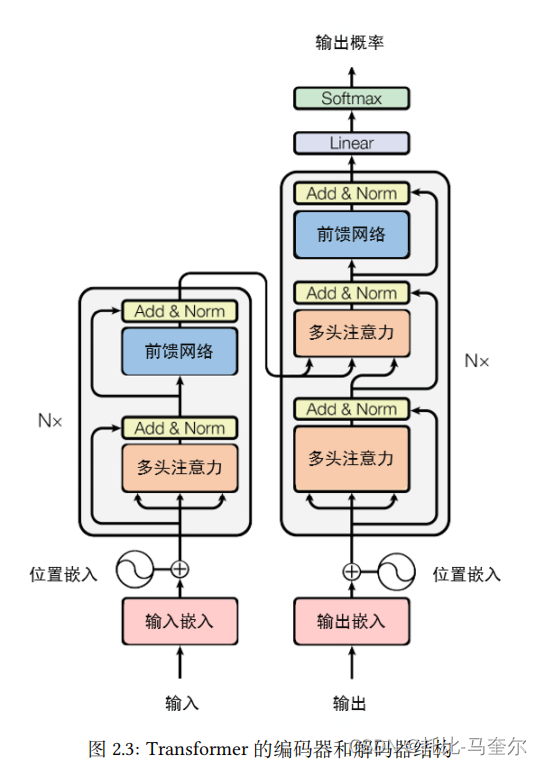
编码器由N个相同的编码层组成,每个编码层包含两个子层,分别是多头自注意力层和一个简单全连接前馈网络。同时两个子层之间采用了跳跃连接的方式,并在每个子层之后采用归一化层。
每个层对应的输出为:,其中
表示子层。
对于解码器,由N个相同解码层组成。解码层由三个子层组成,解码层比编码层多一个多头自注意力子层。增加的多头自注意力层主要用来执行输出的注意力捕获,这三个子层也采用了跳跃连接的方式进行组织。
多头自注意力模块
多头注意力模块包含多个自注意力模块,它们在通道维度进行拼接,以建模输入序列中不同元素之间的关系

自注意力模块的softmax对应的计算复杂度是关于输入序列长度的平方,因此在输入序列长度过大时会消耗较大的计算资源。
位置编码
视觉Transformer
ViT首先将输入图像进行转变成一组切片序列,然后将其输入到标准的Transformer的编码器中进行处理,以实现不同的下游任务。

自动化机器学习
自动化机器学习的目标是在学习工具上构建一个高级别的控制器,用来找到合适的特征、模型以及算法的参数配置。
自动化特征工程的目标是构建一个提升后续模块表现的特征集。
特征金字塔Transformer模型
模型组件
深度残差网络和Vision Transformer,两个组件分别对应了特征提取和特征建模能力。
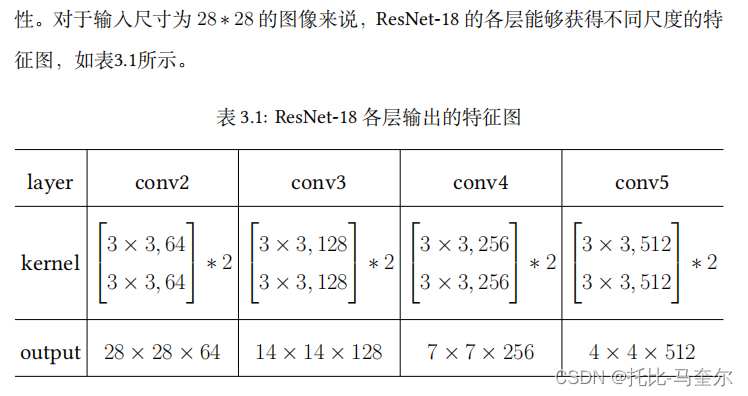
Res-Net-18主要由八个基本块组成,每两个基本块组成一个基本层(basic layer)。一般来说,浅层网络主要提取比较泛化的特征信息,而深层网络则可以提取到输入图像更具有特征的特征信息。
Vision Transformer组件则是将一张图像处理成相同尺寸的多个切片,然后被输入到Transformer中。给定一张图像,它经过变换后成为一系列展平的切片
,其中,(P,P)表示每个切片的大小。
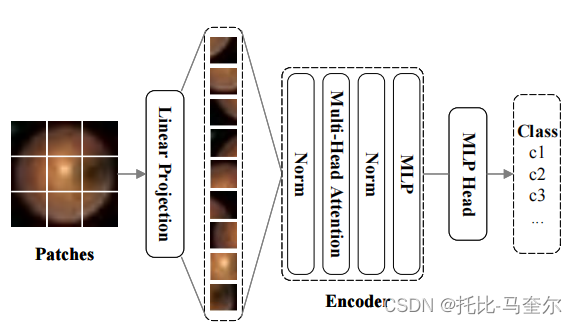
一张图像通常首先会被输入到一个卷积神经网络中提取特征,然后模型根据输出的特征图进行分类。神经网络的不同层具备不同的特征信息,但是目前大多数模型都是基于深层特征进行预测。
整体模型
模型将ResNet-18中的基本层作为特征提取器,将获取的CNN特征图展平为一个线性序列。
模型可以充分使用深度神经网络中低层、中层以及高层的特征输出来进行预测。使用基本层作为特征提取器能够取得比直接使用Vision Transformer更好的效果。

对于ResNet的四个基本层,可以使用符号 B1, B2, B3, B4 来进行表示,同时每个基本层都被看作一个特征提取器
x为输入特征,f表示基本块的一系列运算操作,g表示残差连接,并且。各层的输出可以被建模为通过不同尺度来观察输入图像。
多尺度融合决策
对于四个不同层的输出,选取前三个尺度的特征图(B1,B2,B3)并将其输入到三个浅层的ViT中。对于最后一个尺度的特征图输出(B4),它被保留在ResNet-18的原始路径中。
对于Transformer路径部分,首先将输入变换成一系列展平的2D切片,每块切片的大小都为1*1,之后利用可训练的线性投影将矢量化切片映射到一个D维的嵌入空间中。同时,为每个切片添加位置嵌入来保持切片在原图中的位置信息。

Transformer的编码器主要包含两个组件:多头自注意力结构和多层感知机(MLP)模块。通过编码器的处理后,可以获取激活函数a,其处理过程

对于ResNet原路径部分,最后一层的特征图被输入进一个池化层和一个线性层。最后一层对应的激活向量,接着将四个激活向量进行拼接,并且将最终的预测通过一个softmax或sigmoid函数进行处理。