1.𝑘近邻法是基本且简单的分类与回归方法。𝑘近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的𝑘个最近邻训练实例点,然后利用这𝑘个训练实例点的类的多数来预测输入实例点的类。
2.𝑘近邻模型对应于基于训练数据集对特征空间的一个划分。𝑘近邻法中,当训练集、距离度量、𝑘值及分类决策规则确定后,其结果唯一确定。
3.𝑘近邻法三要素:距离度量、𝑘值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的pL距离。𝑘值小时,𝑘近邻模型更复杂;𝑘值大时,𝑘近邻模型更简单。𝑘值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的𝑘。常用的分类决策规则是多数表决,对应于经验风险最小化。
4.𝑘近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对𝑘维空间的一个划分,其每个结点对应于𝑘维空间划分中的一个超矩形区域。利用kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
距离度量
在机器学习算法中,我们经常需要计算样本之间的相似度,通常的做法是计算样本之间的距离。
设𝑥和𝑦为两个向量,求它们之间的距离。
这里用Numpy实现,设和为ndarray <numpy.ndarray>,它们的shape都是(N,)
𝑑为所求的距离,是个浮点数(float)。
欧氏距离(Euclidean distance)
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在𝑚�维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
距离公式: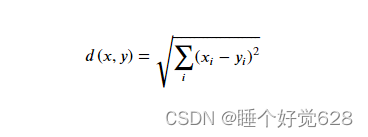
编写欧氏距离代码
##### 在此处编写或补全代码
import math
def euclidean(x, y):d = 0.for xi, yi in zip(x, y):d += (xi-yi)**2return math.sqrt(d)
a=euclidean([1,2,3], [4,5,6])
计算
a = np.array((2,3))
b = np.array((10,5))
##### 在此处编写或补全代码
op1=np.sqrt(np.sum(np.square(a-b)))
op2=np.linalg.norm(a-b)
print(op1)
print(op2) 计算结果: