文章目录
- 1. 源算子 Source
- 1. 从集合读
- 2. 从文件读取
- 3. 从 socket 读取
- 4. 从 kafka 读取
- 5. 从数据生成器读取数据
- 2. 转换算子
- 基本转换算子(map/ filter/ flatMap)
1. 源算子 Source
Flink可以从各种来源获取数据,然后构建DataStream进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source就是我们整个处理程序的输入端。

在Flink1.12以前,旧的添加source的方式,是调用执行环境的addSource()方法:
DataStream stream = env.addSource(…);
方法传入的参数是一个“源函数”(source function),需要实现SourceFunction接口。
从Flink1.12开始,主要使用流批统一的新Source架构:
DataStreamSource stream = env.fromSource(…)
Flink直接提供了很多预实现的接口,此外还有很多外部连接工具也帮我们实现了对应的Source,通常情况下足以应对我们的实际需求。
1. 从集合读
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 1. 从集合读
// DataStreamSource<Integer> source = env.fromCollection(Arrays.asList(1, 2, 3));// 2. 直接填元素DataStreamSource<Integer> source = env.fromElements(1, 2, 3, 4);source.print();env.execute();}
2. 从文件读取
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency> public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();FileSource<String> source = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/world.txt")).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "fileSource").print();env.execute();}
3. 从 socket 读取
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.socketTextStream("localhost", 7777);source.print();env.execute();}
可以使用
nc -l 7777创建一个监听链接的 tcp
4. 从 kafka 读取
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency>
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers("hadoop102:9092").setTopics("topic_1").setGroupId("atguigu").setStartingOffsets(OffsetsInitializer.latest()).setValueOnlyDeserializer(new SimpleStringSchema()) .build();DataStreamSource<String> stream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka-source");stream.print("Kafka");env.execute();}
5. 从数据生成器读取数据
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-datagen</artifactId><version>${flink.version}</version></dependency>
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "Number:" + value;}}, 10, // 自动生成的数字序列RateLimiterStrategy.perSecond(10), // 限速策略,每秒生成10条Types.STRING // 返回类型);env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "datagenerator").print();env.execute();}
2. 转换算子
数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream。

基本转换算子(map/ filter/ flatMap)
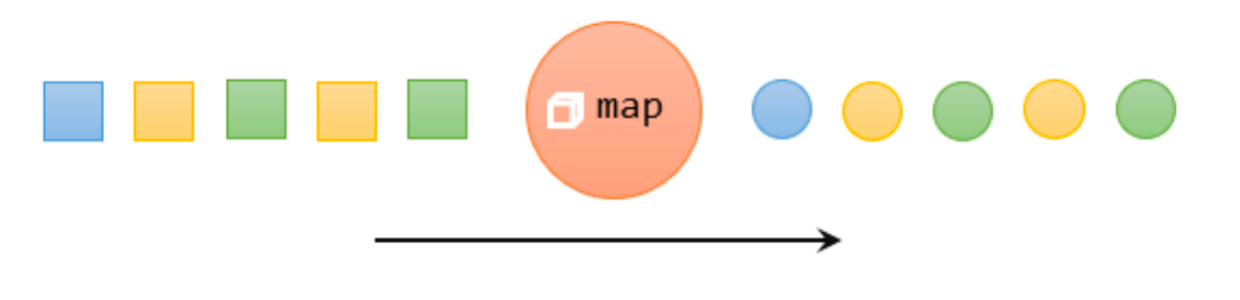
map是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉。

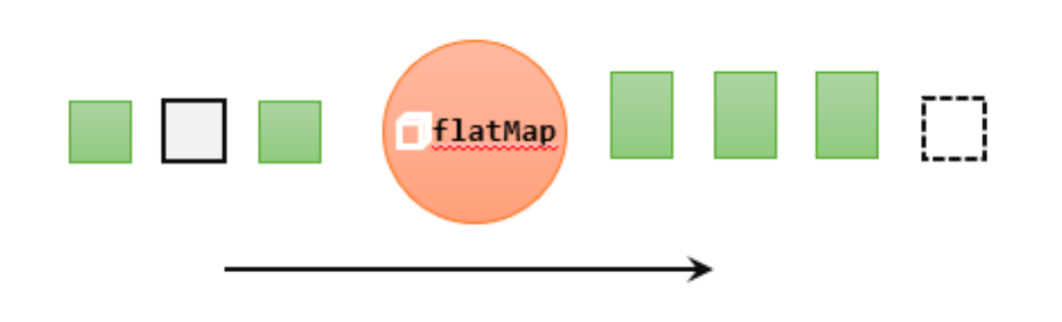
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。
:::info
消费一个元素,可以产生0到多个元素。
:::
flatMap可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。