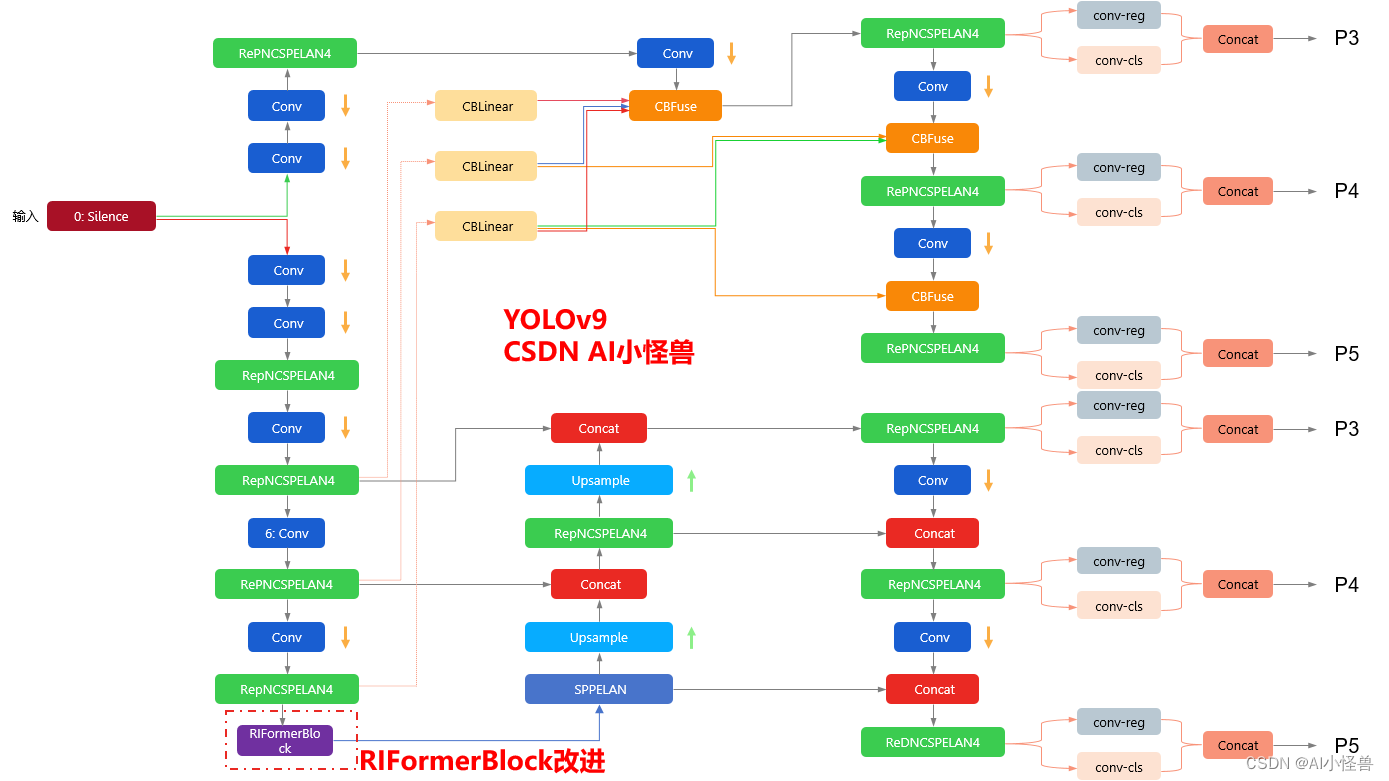
💡💡💡本文改进内容: token mixer被验证能够大幅度提升性能,但典型的token mixer为自注意力机制,推理耗时长,计算代价大,而RIFormers是无需TokenMixer也能达成SOTA性能的极简ViT架构 ,在保证性能的同时足够轻量化。
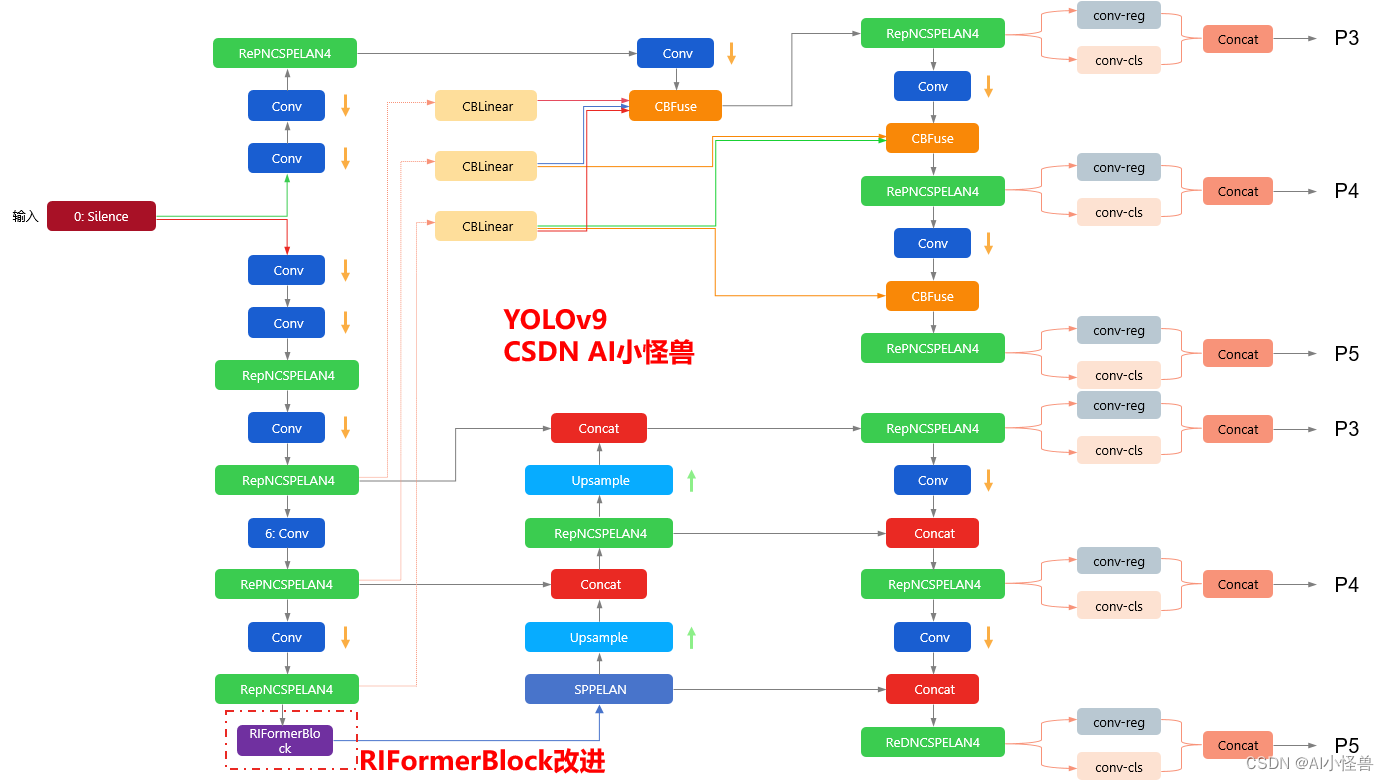
💡💡💡RIFormerBlock引入到YOLOv9,多个数据集验证能够大幅度涨点
改进结构图如下:
《YOLOv9魔术师专栏》将从以下各个方向进行创新:
【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【SPPELAN & RepNCSPELAN4优化】【小目标性能提升】【前沿论文分享】【训练实战篇】
订阅者通过添加WX: AI_CV_0624,入群沟通,提供改进结构图等一系列定制化服务。
订阅者可以申请发票,便于报销
YOLOv9魔术师专栏

💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
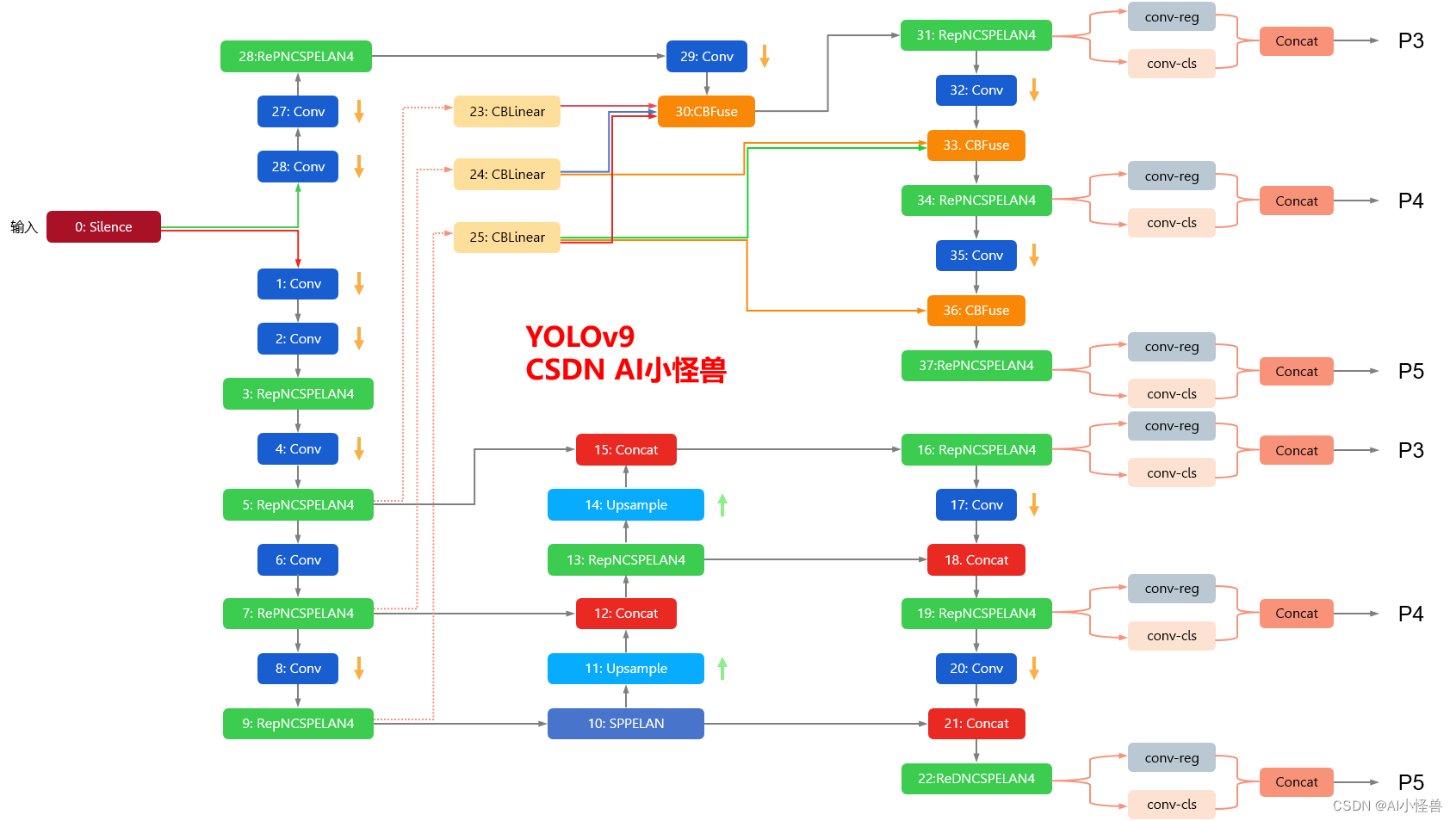
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2.RIFormer介绍

论文:https://arxiv.org/pdf/2304.05659.pdf
问题:Vision Transformer 已取得长足进步,token mixer,其优秀的建模能力已在各种视觉任务中被广泛证明,典型的 token mixer 为自注意力机制,推理耗时长,计算代价大。直接去除会导致模型结构先验不完整,从而带来显著的准确性下降。本文探索如何去掉 token mixer,并以 poolformer 为基准,探索在保证精度的同时,直接去掉 token mixer 模块!
本文基于重参数机制提出了RepIdentityFormer方案以研究无Token Mixer的架构体系。紧接着,作者改进了学习架构以打破无Token Mixer架构的局限性并总结了优化策略。搭配上所提优化策略后,本文构建了一种极致简单且具有优异性能的视觉骨干,此外它还具有高推理效率优势。
为什么这么做?
Token Mixer是ViT骨干非常重要的组成成分,它用于对不同空域位置信息进行自适应聚合,但常规的自注意力往往存在高计算复杂度与高延迟问题。而直接移除Token Mixer又会导致不完备的结构先验,进而导致严重的性能下降。
Token Mixer是ViT架构中用于空域信息聚合的关键模块,但由于采用了自注意力机制导致其计算量与内存消耗与图像尺寸强相关

重参数方法在各个领域得到了广泛的应用。RIFormer推理时的TokenMixer模块可以视作LN+Identity组合
作者进一步提出了Module Imitation以充分利用老师模型TokenMixer后的有用信息
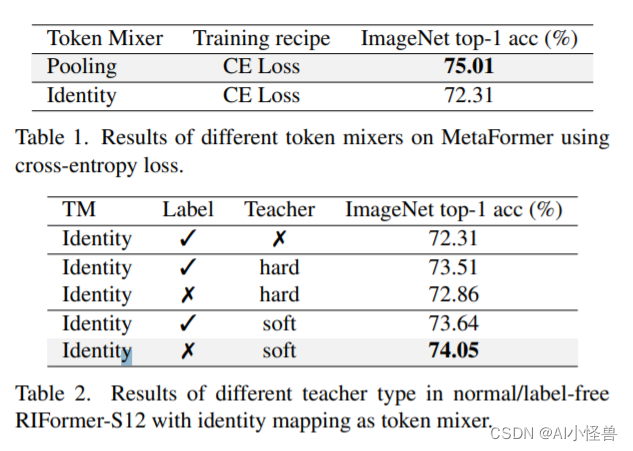
表 6 展示了 RIFormer 在 ImageNet 分类上的结果。文章主要关注吞吐量指标,因为首要考量是满足边缘设备的延迟要求。如预期所示,比其他类型的骨干拥有明显的速度优势,因为 RIFormer 其构建块不包含任何 token mixer。
- RIFormer-M36的吞吐量可达1185,同时精度高达82.6%;而PoolFormer-M36的吞吐量为109,精度为82.1%。
- 对比GFNet与RIFormer,GFNet-H-B吞吐量为939,精度为82.9%,但需要特殊的、硬件不友好的FFT操作;而RIFormer可达到与之相关的水准且无复杂的操作。

消融实验
module imitation 的有效性,作为额外仿射算子学习适当权重的重要方法,模组模仿是基于蒸馏的。因此,文章将其与隐藏状态特征蒸馏方法(带有关系)进行比较。采用第 4.2 节的范式,软蒸馏而不考虑交叉熵损失,文章得到表 7 中的结果。使用特征蒸馏,准确率比模组模仿低 0.46%,说明模组模仿正向影响额外权重的优化。

不同加速策略的比较。接下来,文章讨论拆除 token 是否优于其他稀疏化策略。基于 PoolFormer [46]基线,文章首先构建了一个更薄的 PoolFormer-S9 和 PoolFormer-XS12,分别通过减少深度到 9 和保持其宽度(即嵌入维度)大约为原来的 5/6,以获得与文章的 RIFormer-S12 相当的推理速度。文章也跟随第 4.2 节的软蒸馏范式。表 8 显示结果。直接减少深度或宽度无法比文章无需延迟高昂的 token mixer 更好。
3.RIFormerBlock加入到YOLOv9
3.1新建py文件,路径为models/block/RIFormerBlock.py
3.2修改yolo.py
1)首先进行引用
from models.block.RIFormerBlock import RIFormerBlock2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入RIFormerBlock
if m in {Conv, AConv, ConvTranspose, Bottleneck, SPP, SPPF, DWConv, BottleneckCSP, nn.ConvTranspose2d, DWConvTranspose2d, SPPCSPC, ADown,RepNCSPELAN4, SPPELAN,RIFormerBlock}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, SPPCSPC}:args.insert(2, n) # number of repeatsn = 13.3 yolov9-c-RIFormerBlock.yaml