1.总览表格
| index | 库名 | 编程语言 | 说明 | 代码示例 | 编译指令 | ||
| 1 | Posix正则 | C语言 | 是C标准库中用于编译POSIX风格的正则表达式库 | posix-re.c | gcc posix-re.c | ||
| 2 | PCRE库 | C语言 | 提供类似Perl语言的一个正则表达式引擎库。 一般系统上对应/usr/lib64/libpcre.so这个库文件,它 是PCRE(Perl Compatible Regular Expressions)库的动态链接库文件,通常用于在Linux系统中提供对正则表达式的支持。PCRE库是由 Philip Hazel 开发的,提供了对Perl风格正则表达式的支持,包括编译、执行和处理正则表达式的功能。 | test-pcre.c | gcc test-pcre.c -lpcre | ||
| 3 | RE2 | C++ | RE2是google开源的正则表达式一厍,田Rob Pike和 Russ Cox 两位来自google的大牛用C++实现。它快速、安全,线程友好,是PCRE、PERL 和Python等回溯正则表达式引擎(backtracking regularexpression engine)的一个替代品。RE2支持Linux和绝大多数的Unix平台。 |
2.代码示例
2.1 posix-re.c
#include <stdio.h>
#include <regex.h>int main() {regex_t regex;int ret;char str[] = "hello world";// 编译正则表达式ret = regcomp(®ex, "hello", REG_EXTENDED);if (ret != 0) { printf("Error compiling regex\n");return 1;} // 执行匹配ret = regexec(®ex, str, 0, NULL, 0); if (ret == 0) {printf("Match found\n");} else if (ret == REG_NOMATCH) {printf("No match found\n");} else {printf("Error executing regex\n");} // 释放正则表达式regfree(®ex);return 0;
}2.2 test-pcre.c
#include <stdio.h>
#include <string.h>
#include <pcre.h>int main() {const char *pattern = "hello (\\w+)";const char *subject = "hello world";const int subject_length = strlen(subject);const char *error;int error_offset;pcre *re = pcre_compile(pattern, 0, &error, &error_offset, NULL);if (re == NULL) {printf("PCRE compilation failed at offset %d: %s\n", error_offset, error);return 1;} int ovector[3];int rc = pcre_exec(re, NULL, subject, subject_length, 0, 0, ovector, 3); if (rc < 0) {printf("PCRE execution failed with error code %d\n", rc);pcre_free(re);return 1;} printf("Match found: ");for (int i = ovector[2]; i < ovector[3]; i++) {printf("%c", subject[i]);} printf("\n");pcre_free(re);return 0;
}3.接口说明
3.1 posix-re
#include <sys/types.h>#include <regex.h>int regcomp(regex_t *preg, const char *regex, int cflags);int regexec(const regex_t *preg, const char *string, size_t nmatch,regmatch_t pmatch[], int eflags);size_t regerror(int errcode, const regex_t *preg, char *errbuf,size_t errbuf_size);void regfree(regex_t *preg);
DESCRIPTIONPOSIX regex compilingregcomp() is used to compile a regular expression into a form that is suitable for subsequent regexec() searches.regcomp() is supplied with preg, a pointer to a pattern buffer storage area; regex, a pointer to the null-terminated string and cflags, flags usedto determine the type of compilation.All regular expression searching must be done via a compiled pattern buffer, thus regexec() must always be supplied with the address of a reg‐comp() initialized pattern buffer.cflags may be the bitwise-or of one or more of the following:REG_EXTENDEDUse POSIX Extended Regular Expression syntax when interpreting regex. If not set, POSIX Basic Regular Expression syntax is used.REG_ICASEDo not differentiate case. Subsequent regexec() searches using this pattern buffer will be case insensitive.REG_NOSUBDo not report position of matches. The nmatch and pmatch arguments to regexec() are ignored if the pattern buffer supplied was compiledwith this flag set.REG_NEWLINEMatch-any-character operators don't match a newline.A nonmatching list ([^...]) not containing a newline does not match a newline.Match-beginning-of-line operator (^) matches the empty string immediately after a newline, regardless of whether eflags, the executionflags of regexec(), contains REG_NOTBOL.Match-end-of-line operator ($) matches the empty string immediately before a newline, regardless of whether eflags contains REG_NOTEOL.POSIX regex matchingregexec() is used to match a null-terminated string against the precompiled pattern buffer, preg. nmatch and pmatch are used to provide informa‐tion regarding the location of any matches. eflags may be the bitwise-or of one or both of REG_NOTBOL and REG_NOTEOL which cause changes inmatching behavior described below.REG_NOTBOLThe match-beginning-of-line operator always fails to match (but see the compilation flag REG_NEWLINE above) This flag may be used when dif‐ferent portions of a string are passed to regexec() and the beginning of the string should not be interpreted as the beginning of the line.REG_NOTEOLThe match-end-of-line operator always fails to match (but see the compilation flag REG_NEWLINE above)Byte offsetsUnless REG_NOSUB was set for the compilation of the pattern buffer, it is possible to obtain match addressing information. pmatch must be dimen‐sioned to have at least nmatch elements. These are filled in by regexec() with substring match addresses. The offsets of the subexpressionstarting at the ith open parenthesis are stored in pmatch[i]. The entire regular expression's match addresses are stored in pmatch[0]. (Notethat to return the offsets of N subexpression matches, nmatch must be at least N+1.) Any unused structure elements will contain the value -1.The regmatch_t structure which is the type of pmatch is defined in <regex.h>.typedef struct {regoff_t rm_so;regoff_t rm_eo;} regmatch_t;Each rm_so element that is not -1 indicates the start offset of the next largest substring match within the string. The relative rm_eo elementindicates the end offset of the match, which is the offset of the first character after the matching text.POSIX error reportingregerror() is used to turn the error codes that can be returned by both regcomp() and regexec() into error message strings.regerror() is passed the error code, errcode, the pattern buffer, preg, a pointer to a character string buffer, errbuf, and the size of the stringbuffer, errbuf_size. It returns the size of the errbuf required to contain the null-terminated error message string. If both errbuf anderrbuf_size are nonzero, errbuf is filled in with the first errbuf_size - 1 characters of the error message and a terminating null byte ('\0').POSIX pattern buffer freeingSupplying regfree() with a precompiled pattern buffer, preg will free the memory allocated to the pattern buffer by the compiling process, reg‐comp().RETURN VALUEregcomp() returns zero for a successful compilation or an error code for failure.regexec() returns zero for a successful match or REG_NOMATCH for failure.ERRORSThe following errors can be returned by regcomp():REG_BADBRInvalid use of back reference operator.REG_BADPATInvalid use of pattern operators such as group or list.REG_BADRPTInvalid use of repetition operators such as using '*' as the first character.REG_EBRACEUn-matched brace interval operators.REG_EBRACKUn-matched bracket list operators.REG_ECOLLATEInvalid collating element.REG_ECTYPEUnknown character class name.REG_EENDNonspecific error. This is not defined by POSIX.2.REG_EESCAPETrailing backslash.REG_EPARENUn-matched parenthesis group operators.REG_ERANGEInvalid use of the range operator, e.g., the ending point of the range occurs prior to the starting point.REG_ESIZECompiled regular expression requires a pattern buffer larger than 64Kb. This is not defined by POSIX.2.REG_ESPACEThe regex routines ran out of memory.REG_ESUBREGInvalid back reference to a subexpression.3.2 pcre
3.2.1 pcre_complie-编译正则表达式
NAMEPCRE - Perl-compatible regular expressionsSYNOPSIS#include <pcre.h>pcre *pcre_compile(const char *pattern, int options,const char **errptr, int *erroffset,const unsigned char *tableptr);pcre16 *pcre16_compile(PCRE_SPTR16 pattern, int options,const char **errptr, int *erroffset,const unsigned char *tableptr);pcre32 *pcre32_compile(PCRE_SPTR32 pattern, int options,const char **errptr, int *erroffset,const unsigned char *tableptr);DESCRIPTIONThis function compiles a regular expression into an internal form. It is the same as pcre[16|32]_compile2(), except for the absence of the errorcodeptr argument. Its arguments are:pattern A zero-terminated string containing theregular expression to be compiledoptions Zero or more option bitserrptr Where to put an error messageerroffset Offset in pattern where error was foundtableptr Pointer to character tables, or NULL touse the built-in defaultThe option bits are:PCRE_ANCHORED Force pattern anchoringPCRE_AUTO_CALLOUT Compile automatic calloutsPCRE_BSR_ANYCRLF \R matches only CR, LF, or CRLFPCRE_BSR_UNICODE \R matches all Unicode line endingsPCRE_CASELESS Do caseless matchingPCRE_DOLLAR_ENDONLY $ not to match newline at endPCRE_DOTALL . matches anything including NLPCRE_DUPNAMES Allow duplicate names for subpatternsPCRE_EXTENDED Ignore white space and # commentsPCRE_EXTRA PCRE extra features(not much use currently)PCRE_FIRSTLINE Force matching to be before newlinePCRE_JAVASCRIPT_COMPAT JavaScript compatibilityPCRE_MULTILINE ^ and $ match newlines within dataPCRE_NEWLINE_ANY Recognize any Unicode newline sequencePCRE_NEWLINE_ANYCRLF Recognize CR, LF, and CRLF as newlinesequencesPCRE_NEWLINE_CR Set CR as the newline sequencePCRE_NEWLINE_CRLF Set CRLF as the newline sequencePCRE_NEWLINE_LF Set LF as the newline sequencePCRE_NO_AUTO_CAPTURE Disable numbered capturing paren-theses (named ones available)PCRE_NO_UTF16_CHECK Do not check the pattern for UTF-16validity (only relevant ifPCRE_UTF16 is set)PCRE_NO_UTF32_CHECK Do not check the pattern for UTF-32validity (only relevant ifPCRE_UTF32 is set)PCRE_NO_UTF8_CHECK Do not check the pattern for UTF-8validity (only relevant ifPCRE_UTF8 is set)PCRE_UCP Use Unicode properties for \d, \w, etc.PCRE_UNGREEDY Invert greediness of quantifiersPCRE_UTF16 Run in pcre16_compile() UTF-16 modePCRE_UTF32 Run in pcre32_compile() UTF-32 modePCRE_UTF8 Run in pcre_compile() UTF-8 modePCRE must be built with UTF support in order to use PCRE_UTF8/16/32 and
PCRE_NO_UTF8/16/32_CHECK, and with UCP support if PCRE_UCP is used.The yield of the function is a pointer to a private data structure that
contains the compiled pattern, or NULL if an error was detected. Note that compiling
regular expressions with one version of PCRE for use with a differentversion is not guaranteed to work and may cause crashes.There is a complete description of the PCRE native API in the pcreapi page and
a description of the POSIX API in the pcreposix page.3.2.2 pcre_exec-函数参数说明
int pcre_exec(const pcre *code, const pcre_extra *extra,const char *subject, int length, int startoffset,int options, int *ovector, int ovecsize);This function matches a compiled regular expression against a given subject string,
using a matching algorithm that is similar to Perl's. It returns offsets to captured
substrings. Its arguments are:code Points to the compiled patternextra Points to an associated pcre[16|32]_extra structure,or is NULLsubject Points to the subject stringlength Length of the subject string, in bytesstartoffset Offset in bytes in the subject at which tostart matchingoptions Option bitsovector Points to a vector of ints for result offsetsovecsize Number of elements in the vector (a multiple of 3)The options are:PCRE_ANCHORED Match only at the first positionPCRE_BSR_ANYCRLF \R matches only CR, LF, or CRLFPCRE_BSR_UNICODE \R matches all Unicode line endingsPCRE_NEWLINE_ANY Recognize any Unicode newline sequencePCRE_NEWLINE_ANYCRLF Recognize CR, LF, & CRLF as newline sequencesPCRE_NEWLINE_CR Recognize CR as the only newline sequencePCRE_NEWLINE_CRLF Recognize CRLF as the only newline sequencePCRE_NEWLINE_LF Recognize LF as the only newline sequencePCRE_NOTBOL Subject string is not the beginning of a linePCRE_NOTEOL Subject string is not the end of a linePCRE_NOTEMPTY An empty string is not a valid matchPCRE_NOTEMPTY_ATSTART An empty string at the start of the subjectis not a valid matchPCRE_NO_START_OPTIMIZE Do not do "start-match" optimizationsPCRE_NO_UTF16_CHECK Do not check the subject for UTF-16validity (only relevant if PCRE_UTF16was set at compile time)PCRE_NO_UTF32_CHECK Do not check the subject for UTF-32validity (only relevant if PCRE_UTF32was set at compile time)PCRE_NO_UTF8_CHECK Do not check the subject for UTF-8validity (only relevant if PCRE_UTF8was set at compile time)PCRE_PARTIAL ) Return PCRE_ERROR_PARTIAL for a partialPCRE_PARTIAL_SOFT ) match if no full matches are foundPCRE_PARTIAL_HARD Return PCRE_ERROR_PARTIAL for a partial matchif that is found before a full match3.2.3 pcre.h文件中的一些枚举值
这些枚举值在pcre_exec的返回值中被用到。
/* Exec-time and get/set-time error codes */#define PCRE_ERROR_NOMATCH (-1)
#define PCRE_ERROR_NULL (-2)
#define PCRE_ERROR_BADOPTION (-3)
#define PCRE_ERROR_BADMAGIC (-4)
#define PCRE_ERROR_UNKNOWN_OPCODE (-5)
#define PCRE_ERROR_UNKNOWN_NODE (-5) /* For backward compatibility */
#define PCRE_ERROR_NOMEMORY (-6)
#define PCRE_ERROR_NOSUBSTRING (-7)
#define PCRE_ERROR_MATCHLIMIT (-8)
#define PCRE_ERROR_CALLOUT (-9) /* Never used by PCRE itself */
#define PCRE_ERROR_BADUTF8 (-10) /* Same for 8/16/32 */
#define PCRE_ERROR_BADUTF16 (-10) /* Same for 8/16/32 */
#define PCRE_ERROR_BADUTF32 (-10) /* Same for 8/16/32 */
#define PCRE_ERROR_BADUTF8_OFFSET (-11) /* Same for 8/16 */
#define PCRE_ERROR_BADUTF16_OFFSET (-11) /* Same for 8/16 */
#define PCRE_ERROR_PARTIAL (-12)
#define PCRE_ERROR_BADPARTIAL (-13)
#define PCRE_ERROR_INTERNAL (-14)
#define PCRE_ERROR_BADCOUNT (-15)
#define PCRE_ERROR_DFA_UITEM (-16)
#define PCRE_ERROR_DFA_UCOND (-17)
#define PCRE_ERROR_DFA_UMLIMIT (-18)
#define PCRE_ERROR_DFA_WSSIZE (-19)
#define PCRE_ERROR_DFA_RECURSE (-20)
#define PCRE_ERROR_RECURSIONLIMIT (-21)
#define PCRE_ERROR_NULLWSLIMIT (-22) /* No longer actually used */
#define PCRE_ERROR_BADNEWLINE (-23)
#define PCRE_ERROR_BADOFFSET (-24)
#define PCRE_ERROR_SHORTUTF8 (-25)
#define PCRE_ERROR_SHORTUTF16 (-25) /* Same for 8/16 */
#define PCRE_ERROR_RECURSELOOP (-26)
#define PCRE_ERROR_JIT_STACKLIMIT (-27)
#define PCRE_ERROR_BADMODE (-28)
#define PCRE_ERROR_BADENDIANNESS (-29)
#define PCRE_ERROR_DFA_BADRESTART (-30)
#define PCRE_ERROR_JIT_BADOPTION (-31)
#define PCRE_ERROR_BADLENGTH (-32)
#define PCRE_ERROR_UNSET (-33)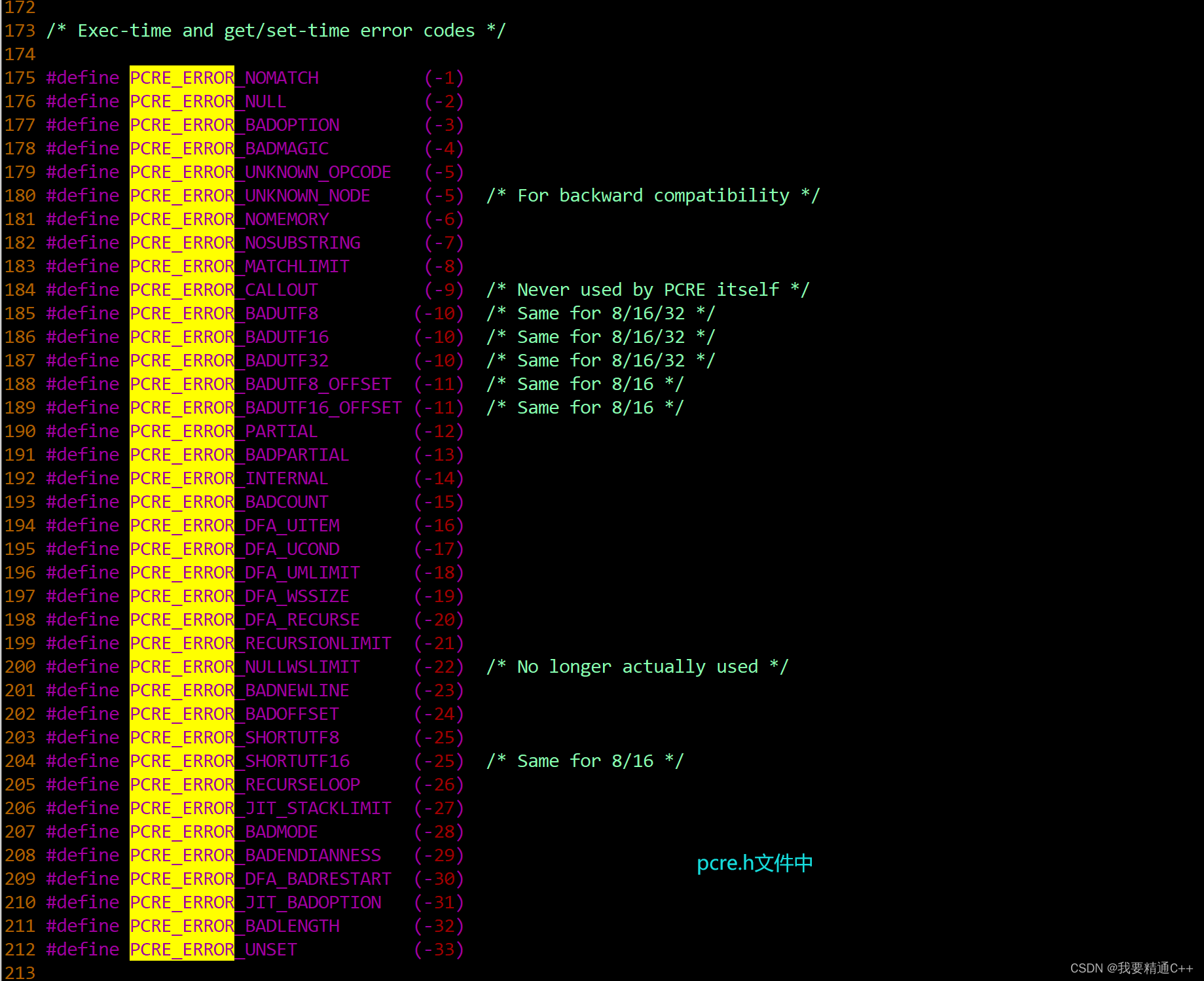
3.2.4 pcre_exec-源码实现
源码在pcre_exec.c文件中。3.2.5 pcre_exec-函数返回值说明
该函数的返回值是一个整数,代表了匹配的结果。具体来说,
(1)返回值大于等于 0:
如果返回值为非负数,表示成功匹配,且返回值是匹配的子串数量加1。
这表示正则表达式成功匹配目标字符串,并且返回了匹配的子串数量。
返回值为0时,表示正则表达式成功匹配了目标字符串,但没有返回任何子串,即没有捕获组。(2)返回值小于0:
返回值是负数,表示匹配失败或发生了错误。
返回值为 -1('PCRE_ERROR_NOMATCH')时,表示正则表达式未能匹配目标字符串。
其他负数返回值表示发生了其他错误,可能是由于正则表达式本身的问题、目标字符串格式问题或者
内存分配问题等。
根据 'pcre_exec' 函数的返回值,可以判断正则表达式是否成功匹配目标字符串,以及获取匹配的
子串数量等信息。在实际使用中,可以根据返回值来进行适当的处理和错误检测。