一、YOLO V8 Pose
YOLO V8 在上篇文章中进了简单的介绍,并基于YOLO V8 Fine-Tuning 训练了自定义的目标检测模型,而YOLO V8 Pose 是建立在YOLO V8基础上的关键点检测模型,本文基于 yolov8n-pose 模型实验 Fine-Tuning 训练15 点人脸关键点检测模型,并配合上篇文章训练的人脸检测模型一起使用。
上篇文章地址:
基于 YOLO V8 Fine-Tuning 训练自定义的目标检测模型
YOLO V8 的细节可以参考下面官方的介绍:
https://docs.ultralytics.com/zh/models/yolov8/#citations-and-acknowledgements
本文依旧使用 ultralytics 框架进行训练和测试,其中 ultralytics 和 pytorch 的版本如下:
torch==1.13.1+cu116
ultralytics==8.1.37
YOLO V8 Pose 调用示例如下:
测试图像:

这里使用 yolov8n-pose 模型,如果模型不存在会自动下载:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-pose.pt') # pretrained YOLOv8n modelresults = model.predict('./img/1.png')
# Show results
results[0].show()
二、人脸关键点检测数据集
在计算机视觉人脸计算领域,人脸关键点检测是一个十分重要的区域,可以实现例如一些人脸矫正、表情分析、姿态分析、人脸识别、人脸美颜等方向。
人脸关键点数据集通常有 5点、15点、68点、96点、98点、106点、186点 等,例如通用 Dlib 中的 68 点检测,它将人脸关键点分为脸部关键点和轮廓关键点,脸部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。

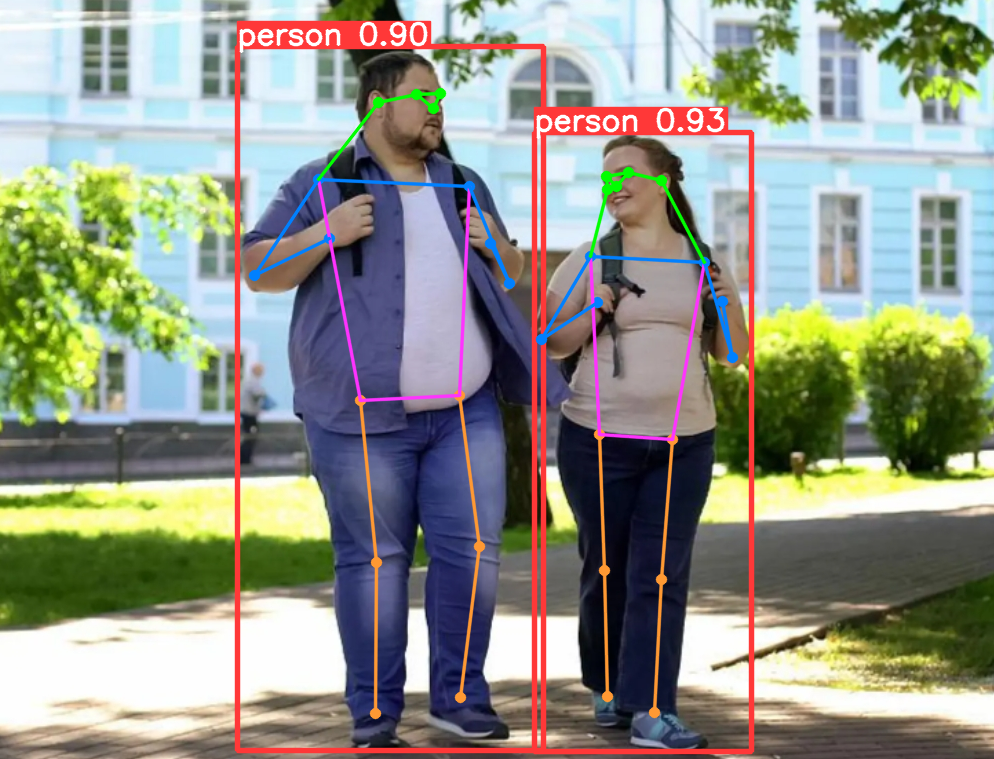
本文基于 kaggle 的 Facial Keypoints Detection 中的数据集进行实践,该数据集包含包括7,049幅训练图像,图像是 96 x 96像素的灰度图像,其中关键点有 15个点,注意数据集有的字段缺失,如果去除字段缺失的数据,实际训练数据只有 2,140 幅训练图像,还包括1,783张测试图片,数据集的效果如下所示:

可以看出,关键点包括眉毛的两端、眼睛的中心和两端、鼻子尖、嘴巴两端和上下嘴唇的中间。
下载数据集
数据集在 kaggle 的官方网址上:
https://www.kaggle.com/c/facial-keypoints-detection
下载前需要进行登录,如果没有 kaggle 账号可以注册一个。
下载解压后,可以看到 training.zip 和 test.zip 两个文件,分别对应训练集和测试集,解压后数据是以 CSV 的格式进行存放的:
其中 training.csv 中的字段分别表示:
| 序号 | 字段 | 含义 |
|---|---|---|
| 0 | left_eye_center_x | 左眼中心 x 点 |
| 1 | left_eye_center_y | 左眼中心 y 点 |
| 2 | right_eye_center_x | 右眼中心 x 点 |
| 3 | right_eye_center_y | 右眼中心 y 点 |
| 4 | left_eye_inner_corner_x | 左眼内端 x 点 |
| 5 | left_eye_inner_corner_y | 左眼内端 y 点 |
| 6 | left_eye_outer_corner_x | 左眼外端 x 点 |
| 7 | left_eye_outer_corner_y | 左眼外端 y 点 |
| 8 | right_eye_inner_corner_x | 右眼内端 x 点 |
| 9 | right_eye_inner_corner_y | 右眼内端 y 点 |
| 10 | right_eye_outer_corner_x | 右眼外端 x 点 |
| 11 | right_eye_outer_corner_y | 右眼外端 y 点 |
| 12 | left_eyebrow_inner_end_x | 左眉毛内端 x 点 |
| 13 | left_eyebrow_inner_end_y | 左眉毛内端 y 点 |
| 14 | left_eyebrow_outer_end_x | 左眉毛外端 x 点 |
| 15 | left_eyebrow_outer_end_y | 左眉毛外端 y 点 |
| 16 | right_eyebrow_inner_end_x | 右眉毛内端 x 点 |
| 17 | right_eyebrow_inner_end_y | 右眉毛内端 y 点 |
| 18 | right_eyebrow_outer_end_x | 右眉毛外端 x 点 |
| 19 | right_eyebrow_outer_end_y | 右眉毛外端 y 点 |
| 20 | nose_tip_x | 鼻尖中心 x 点 |
| 21 | nose_tip_y | 鼻尖中心 y 点 |
| 22 | mouth_left_corner_x | 嘴巴左端 x 点 |
| 23 | mouth_left_corner_y | 嘴巴左端 y 点 |
| 24 | mouth_right_corner_x | 嘴巴右端 x 点 |
| 25 | mouth_right_corner_y | 嘴巴右端 y 点 |
| 26 | mouth_center_top_lip_x | 上嘴唇中心 x 点 |
| 27 | mouth_center_top_lip_y | 上嘴唇中心 y 点 |
| 28 | mouth_center_bottom_lip_x | 下嘴唇中心 x 点 |
| 29 | mouth_center_bottom_lip_y | 下嘴唇中心 y 点 |
| 30 | Image | 图形像素 |
由于数据是存放在CSV中,可以借助 pandas 工具对数据进行解析,如果没有安装 pandas 工具,可以通过下面指令安装:
pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
下面程序通过 pandas 解析 CSV 文件,并将图片转为 numpy 数组,通过 matplotlib 可视化工具查看,其中具体的解释都写在了注释中:
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltdef main():csv_path = './data/training.csv'# 读取 CSV 文件train_df = pd.read_csv(csv_path)# 查看数据框,并列出数据集的头部。train_df.info()# 丢弃有缺失数据的样本train_df = train_df.dropna()# 获取图片信息,并转为 numpy 结构x_train = train_df['Image'].apply(lambda img: np.fromstring(img, sep=' '))x_train = np.vstack(x_train)# 重新修改形状x_train = x_train.reshape((-1, 96, 96, 1))# 去除最后一列的 Imagecols = train_df.columns[:-1]y_train = train_df[cols].valuesprint('训练集 shape: ', x_train.shape)print('训练集label shape: ', y_train.shape)plt.figure(figsize=(10, 10))for p in range(2):data = x_train[(p * 9):(p * 9 + 9)]label = y_train[(p * 9):(p * 9 + 9)]plt.clf()for i in range(9):plt.subplot(3, 3, i + 1)img = data[i].reshape(96, 96, 1)plt.imshow(img, cmap='gray')# 画关键点l = label[i]# 从 1 开始,每次走 2 步,j-1,j 就是当前点的坐标for j in range(1, 31, 2):plt.plot(l[j - 1], l[j], 'ro', markersize=4)plt.show()if __name__ == '__main__':main()运行之后,可以看到如下效果图:

下面我们基于该数据集进行建模,训练一个自己的关键点检测模型。
三、数据集拆分和转换
数据集格式需要转换成 Ultralytics 官方的 YOLO 格式,主要包括以下几点的注意:
- 每幅图像一个文本文件:数据集中的每幅图像都有一个相应的文本文件,文件名与图像文件相同,扩展名为"
.txt"。 - 每个对象一行:文本文件中的每一行对应图像中的一个对象实例。
- 每行对象信息:每行包含对象实例的以下信息
- 对象类别索引:代表对象类别的整数(如
0代表人,1代表汽车等)。 - 对象中心坐标:对象中心的
x和y坐标,归一化后介于0和1之间。 - 对象宽度和高度:对象的宽度和高度,标准化后介于
0和1之间。 - 对象关键点坐标:对象的关键点,归一化为
0至1。
- 对象类别索引:代表对象类别的整数(如
姿势估计任务的标签格式示例:
<class-index> <x> <y> <width> <height> <px1> <py1> <px2> <py2> ... <pxn> <pyn>
官方的介绍:
https://docs.ultralytics.com/zh/datasets/pose/#ultralytics-yolo-format
这里由于数据集中仅包含人脸信息,没有其他因素影响,因此,<class-index> <x> <y> <width> <height> 我们可以固定写死为:0 0.5 0.5 1 1 ,转换和拆分的逻辑如下:
import os
import shutil
from tqdm import tqdm
import numpy as np
import pandas as pd
from PIL import Image# training.csv 地址
csv_path = "./data/training.csv"
# 训练集的比例
training_ratio = 0.8
# 拆分后数据的位置
train_dir = "train_data"def toRgbImg(img):img = np.fromstring(img, sep=' ').astype(np.uint8).reshape(96, 96)img = Image.fromarray(img).convert('RGB')return imgdef split_data():# 训练集目录os.makedirs(os.path.join(train_dir, "images/train"), exist_ok=True)os.makedirs(os.path.join(train_dir, "labels/train"), exist_ok=True)# 验证集目录os.makedirs(os.path.join(train_dir, "images/val"), exist_ok=True)os.makedirs(os.path.join(train_dir, "labels/val"), exist_ok=True)# 读取数据train_df = pd.read_csv(csv_path)# 丢弃有缺失数据的样本train_df = train_df.dropna()# 获取图片信息,并转为 numpy 结构x_train = train_df['Image'].apply(toRgbImg)# 去除最后一列的 Image, 将y值缩放到[0,1]区间cols = train_df.columns[:-1]y_train = train_df[cols].values# 使用 80% 的数据训练,20% 的数据进行验证size = int(x_train.shape[0] * 0.8)x_val = x_train[size:]y_val = y_train[size:]x_train = x_train[:size]y_train = y_train[:size]trains = []vals = []# 生成训练数据for i, image in tqdm(enumerate(x_train), total=len(x_train)):label = y_train[i]image_file = os.path.join(train_dir, f"images/train/{i}.jpg")label_file = os.path.join(train_dir, f"labels/train/{i}.txt")image.save(image_file)trains.append(image_file)width, height = image.sizeyolo_label = ["0", "0.5", "0.5", "1", "1"]for i, v in enumerate(label):if i % 2 == 0:yolo_label.append(str(v / float(width)))else:yolo_label.append(str(v / float(height)))with open(label_file, "w", encoding="utf-8") as w:w.write(" ".join(yolo_label))# 生成验证数据for i, image in tqdm(enumerate(x_val), total=len(x_val)):label = y_val[i]image_file = os.path.join(train_dir, f"images/val/{i}.jpg")label_file = os.path.join(train_dir, f"labels/val/{i}.txt")image.save(image_file)vals.append(image_file)width, height = image.sizeyolo_label = ["0", "0.5", "0.5", "1", "1"]for i, v in enumerate(label):if i % 2 == 0:yolo_label.append(str(v / float(width)))else:yolo_label.append(str(v / float(height)))with open(label_file, "w", encoding="utf-8") as w:w.write(" ".join(yolo_label))with open(os.path.join(train_dir, "train.txt"), "w") as file:file.write("\n".join([image_file for image_file in trains]))print("save train.txt success!")with open(os.path.join(train_dir, "val.txt"), "w") as file:file.write("\n".join([image_file for image_file in vals]))print("save val.txt success!")if __name__ == '__main__':split_data()运行后,可以在 train_data 下面看到拆分后的数据:
四、训练
使用 ultralytics 框架训练非常简单,仅需三行代码即可完成训练,不过在训练前需要编写 YAML 配置信息,主要标记数据集的位置。
创建 face.yaml 文件,写入下面内容:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/pyProject/yolov8/face/train_data # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)# Keypoints
kpt_shape: [15, 2] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)# Classes dictionary
names:0: person
开始训练:
from ultralytics import YOLO# 加载模型
model = YOLO('yolov8n-pose.pt')# 训练
model.train(data='face.yaml', # 训练配置文件epochs=50, # 训练的周期imgsz=640, # 图像的大小device=[0], # 设备,如果是 cpu 则是 device='cpu'workers=0,lr0=0.001, # 学习率batch=8, # 批次大小amp=False # 是否启用混合精度训练
)
运行后可以看到打印的网络结构:

训练中:

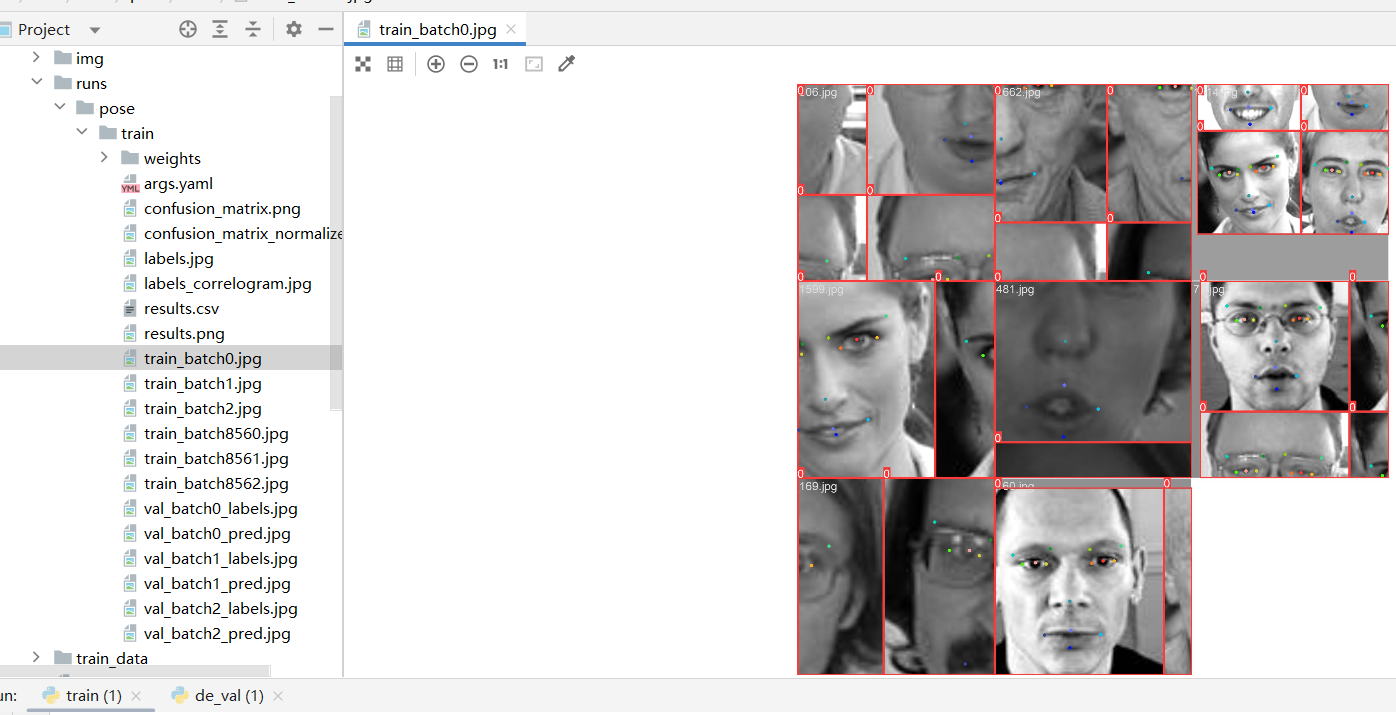
训练结束后可以在 runs 目录下面看到训练的结果:
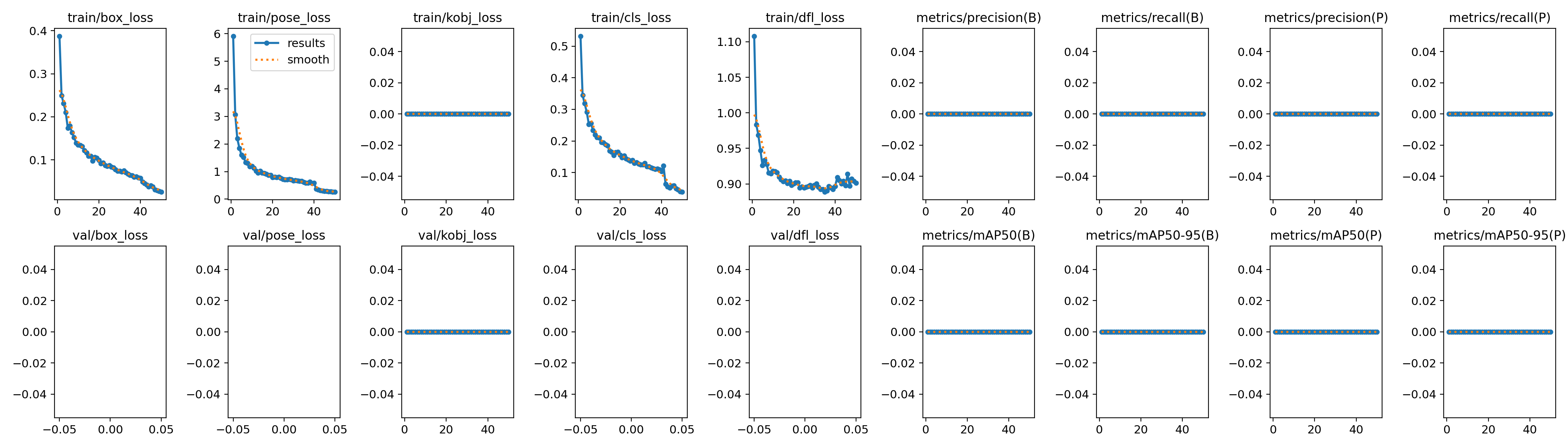
看下训练时 loss 的变化图:
三、模型预测
首先使用测试集进行测试:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
from ultralytics import YOLOdef toRgbImg(img):img = np.fromstring(img, sep=' ').astype(np.uint8)img = Image.fromarray(img).convert('RGB')return imgdef main():csv_path = 'data/test.csv'# 读取 CSV 文件test_df = pd.read_csv(csv_path)# 查看数据框,并列出数据集的头部。test_df.info()# 获取图片信息,并转为 numpy 结构test_df = test_df['Image'].apply(toRgbImg)test_df = np.vstack(test_df)# 重新修改形状test_df = test_df.reshape((-1, 96, 96, 3))# 加载模型model = YOLO('runs/pose/train/weights/best.pt')plt.figure(figsize=(10, 10))for p in range(5):data = test_df[(p * 9):(p * 9 + 9)]plt.clf()for i in range(9):plt.subplot(3, 3, i + 1)img = data[i]plt.imshow(img, cmap='gray')results = model.predict(img, device='cpu')# 画关键点keypoints = results[0].keypoints.xyfor keypoint in keypoints:for xy in keypoint:plt.plot(xy[0], xy[1], 'ro', markersize=4)plt.show()if __name__ == '__main__':main()

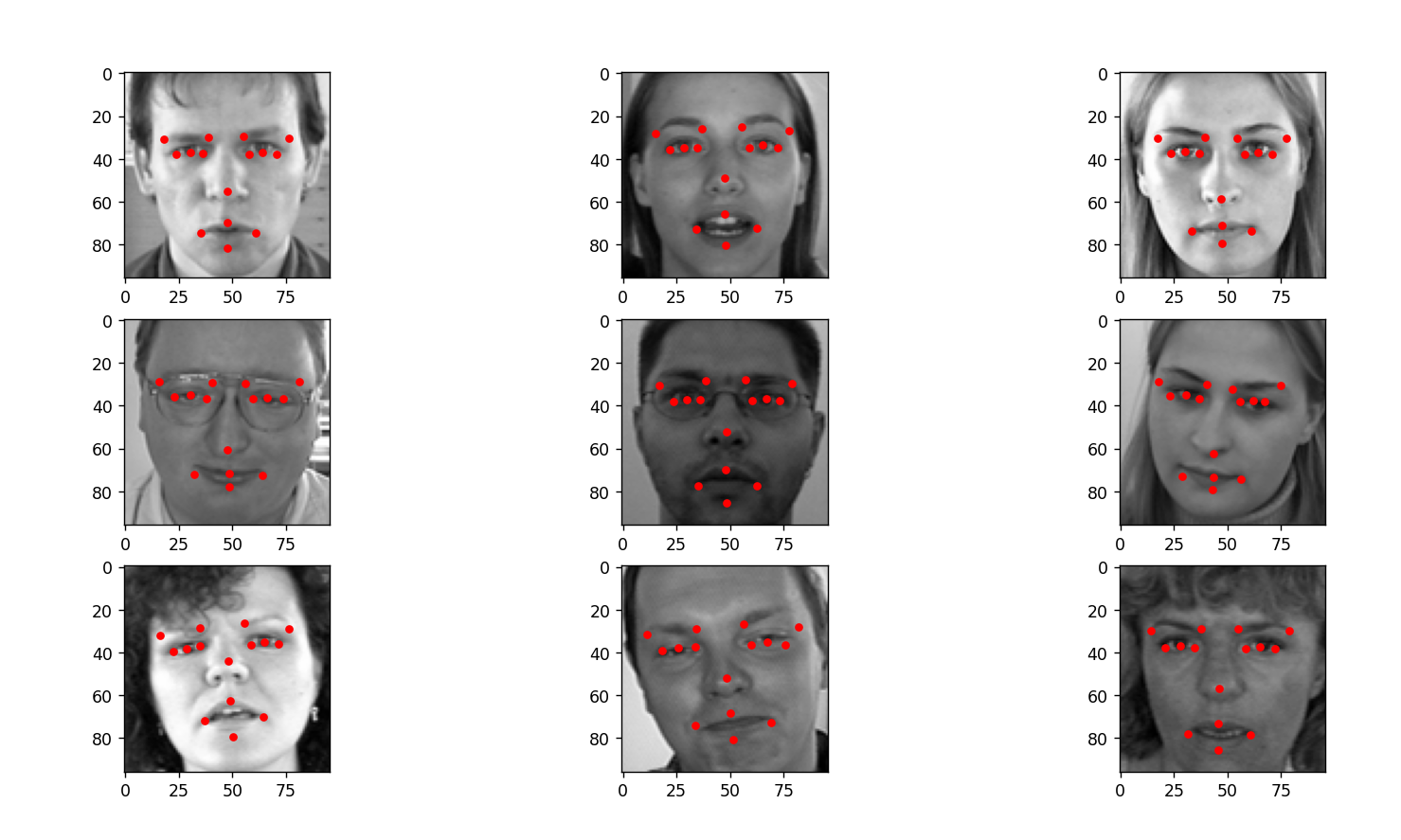
可以看到对于鼻子位置的关键点有些会出现偏差。
四、结合上篇的人脸检测模型
from ultralytics import YOLO
from PIL import Image
from matplotlib import pyplot as pltdef main():# 加载人脸检测模型detection_model = YOLO('yolov8_face_detection.pt')# 加载人脸关键点检测模型point_model = YOLO('runs/pose/train/weights/best.pt')image = plt.imread('./img/10.jpg')# 预测results = detection_model.predict(image, device='cpu')boxes = results[0].boxes.xyxyprint(boxes)ax = plt.gca()for boxe in boxes:x1, y1, x2, y2 = boxe[0], boxe[1], boxe[2], boxe[3]ax.add_patch(plt.Rectangle((x1, y1), (x2 - x1), (y2 - y1), fill=False, color='red'))# 截取图片crop = image[int(y1):int(y2), int(x1):int(x2)]results = point_model.predict(crop, device='cpu')keypoints = results[0].keypoints.xyfor keypoint in keypoints:for xy in keypoint:plt.plot(xy[0]+ x1, xy[1]+ y1, 'ro', markersize=2)plt.imshow(image)plt.show()if __name__ == '__main__':main()测试效果: