目录
一、动力节点Redis的书
7. Redis持久化
二、马士兵李瑾老师
2.1 Redis高级特性和应用
1)发布订阅:
2)Stream
延伸:Redis中几种消息队列实现的总结
3)慢查询
4)Pipeline流水线
5)事务
6)Lua
延伸:Redis与限流★★★
2.2 Redis底层原理
1)持久化
2)分布式锁
2.3 Redis高并发高可用
1)集群
2)主从复制
3)哨兵
2.4 Redis缓存使用问题及互联网运用
1)Redis缓存使用的数据不一致问题
2)缓存穿透、击穿、雪崩
3)热点Key
4)BigKey
2.5 Redis设计、实现
1)数据结构和内部编码
2)Redis中的线程和IO模型
3)缓存淘汰算法
4)过期策略和惰性删除
一、动力节点Redis的书
1. Redis有哪些特性?
2. Redis的IO模型是单线程还是多线程?
- Redis4.0版本以前是纯粹的单线程模型;从4.0版本开始,处理客户端请求的仍然是单线程模型,但像持久化、对AOF的rewrite、对失效连接的清理等由后台的线程进行处理。
- 从6.0开始才是真正意义上的多线程模型,对客户端请求的处理采用的才是多线程模型,但“多线程”仅用于接收、解析客户端的请求,然后将解析出的请求写入任务队列。而对任务(命令)的处理,仍然由单线程处理。这样做的好处:用户不需要考虑线程安全问题,不需要考虑事务控制。
3. Redis的内存移除策略有哪些?(P31)
4. Redis有哪些数据类型?(P3)
5. 典型应用场景?
- String类型:缓存;计数器(如视频播放次数);共享Session(如用户登录session保存在Redis中避免分布式应用中重新登录的问题,token令牌实现接口幂等性);限速器(如用于接口防刷)。
- Hash类型:适合存储对象数据。key为对象名称,value为描述对象属性的Map,对对象属性的修改在redis中就可以直接完成,无需序列化。
- List类型:栈、队列、阻塞式消息队列、动态有限集合。
- Set类型:标签;抽奖;随机选人等。
- 有序Set类型:排行榜。
- BitMap:一般用于大数据量的二值性统计。
6. Redis命令
1)Redis基本命令
2)key操作命令
keys、exists、del、rename、move、type、expire/pexpire、ttl/pttl、persist、scan
3)String型value操作命令(值最大存512M)
- SET key value [EX seconds | PX milliseconds] [NX | XX] (NX时等同于setnx)
- setex/psetex key 过期时间秒/毫秒 value
- setnx
- getset
- mset/msetnx key value [key value ...]
- mget key [key ...]
- append key value
- incr/decr key
- incrby/decrby key increment (increment为增/减的数值,不能是小数)
- incrbyfloat key increment (没有decrbyfloat命令)
- strlen key 返回key所存字符串的长度
- getrange key start end 返回key所存字符串的子字符串(start、end为起始偏移量)
- setrange key offset value
4)Hash型value操作命令
特点:所有命令都带h
- HSET key field value [field value ...]
例如:hset user:001 name Lucy sex male age 18 hobbies read
- HGET key field
- hmset key field value [field value ...]
- hmget key field [field...]
- hgetall key 返回哈希表key中所有的域和值
- hsetnx key field value
- hdel key field [field...]
- hexists key field
- hincrby/hincrbyfloat key field increment
- hkeys key / hvals key 返回哈希表key中的所有域/值
- hlen key 返回hash表key中域的数量
- hstrlen key field 返回关联值字符串的长度
5)List型value操作命令
- lpush/rpush key value [value...] 将一个或多个值value插入到列表key的表头/表尾
- llen key 返回列表key的长度
- lindex key index 返回列表key中下标为index的元素。列表从0开始计数
- lset key index value 将列表key下标为index的元素的值设置为value
- lpop/rpop key [count] 从列表key的表头/表尾移除count个元素,并返回移除的元素,count默认值为1
- blpop/brpop key [key...] timeout 是lpop/rpop命令的阻塞式版本
- lrange、lpushx/rpushx、linsert、rpoplpush、brpoplpush、lrem、ltrim
6)Set型value操作命令
set类型所有命令均以s开头。
- sadd key member [member...]
- smembers key 返回集合key中的所有成员
- 其他命令略

6)Set型value操作命令

7. Redis持久化
Redis持久化有几种方式?默认是哪种?哪种优先级更高?
RDB持久化:RDB持久化的执行方式有几种?是否会阻塞主线程?
RDB持久化过程?
AOF持久化:Append Only File,是指Redis将每一次的写操作都以日志的形式记录到一个AOF文件中。
AOF的工作流程主要是4个部分:命令写入( append)、文件同步( sync)、文件重写(rewrite)、重启加载( load)。
命令写入:
- AOF为什么把命令追加到aof_buf中?(李瑾老师讲义)
- Redis提供了多种AOF缓冲区同步文件策略有哪几种?
重写机制:用于压缩日志文件大小的。
对比:RDB文件较小,保存的是快照,数据恢复较快,实时性差,数据安全性低;
AOF保存的是写操作的日志,实时性好,文件可读性强。
二、马士兵李瑾老师
2.1 Redis高级特性和应用
1)发布订阅:
使用场景和缺点:
- 需要消息解耦又并不关注消息可靠性的地方都可以使用发布订阅模式。
- PubSub 的生产者传递过来一个消息,Redis会直接找到相应的消费者传递过去。如果一个消费者都没有,那么消息直接丢弃。如果开始有三个消费者,一个消费者突然挂掉了,生产者会继续发送消息,另外两个消费者可以持续收到消息。但是挂掉的消费者重新连上的时候,这断连期间生产者发送的消息,对于这个消费者来说就是彻底丢失了。
- 所以和很多专业的消息队列系统(例如Kafka、RocketMQ)相比,Redis 的发布订阅很粗糙,例如无法实现消息堆积和回溯。但胜在足够简单,如果当前场景可以容忍的这些缺点,也不失为一个不错的选择。
- 正是因为 Pub/Sub 有这些缺点,它的应用场景其实是非常狭窄的。从Redis5.0 新增了 Stream 数据结构,这个功能给 Redis 带来了持久化消息队列。
2)Stream
Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的支持多播的可持久化的消息队列,借鉴了 Kafka 的设计。
延伸:Redis中几种消息队列实现的总结
- 基于List的 LPUSH+BRPOP 的实现
- 基于Sorted-Set的实现
- PUB/SUB,订阅/发布模式
- 基于Stream类型的实现
3)慢查询
默认慢查询时间是10毫秒,可以在配置文件中配置slowlog-log-slower-than参数,单位是微秒。可以持久化,后期可以查询慢查询。慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行时间。
4)Pipeline流水线
Redis客户端执行一条命令分为如下4个部分: 1)发送命令2)命令排队3)命令执行4)返回结果。

其中1和4花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
但大部分命令是不支持批量操作的,例如要执行n次 hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地,Redis服务器在阿里云的广州,两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端,而没有使用Pipeline则需要执行n条命令,整个过程需要n次RTT。
5)事务
事务原理:
- MULTI用于开启事务,EXEC用于提交事务。discard命令是回滚(discard也只是丢弃这个缓存队列中的未执行命令,并不会回滚已经操作过的数据,这一点要和关系型数据库的Rollback操作区分开)。
- Redis提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算。
Redis的watch命令:
- 有些应用场景需要在事务之前,确保事务中的key没有被其他客户端修改过,才执行事务,否则不执行(类似乐观锁)。Redis 提供了watch命令来解决这类问题。
6)Lua
通过使用LUA脚本:
1、减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行;
2、原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入(Redis执行命令是单线程)。
3、复用性,客户端发送的脚本会永远存储在redis中,这意味着其他客户端可以复用这一脚本来完成同样的逻辑。
不过为了我们方便学习Lua语言,我们还是单独安装一个Lua。
在Redis使用LUA脚本的好处包括:
1、减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行;
2、原子操作,Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说,编写脚本的过程中无需担心会出现竞态条件;
3、复用性,客户端发送的脚本会存储在Redis中,这意味着其他客户端可以复用这一脚本来完成同样的逻辑
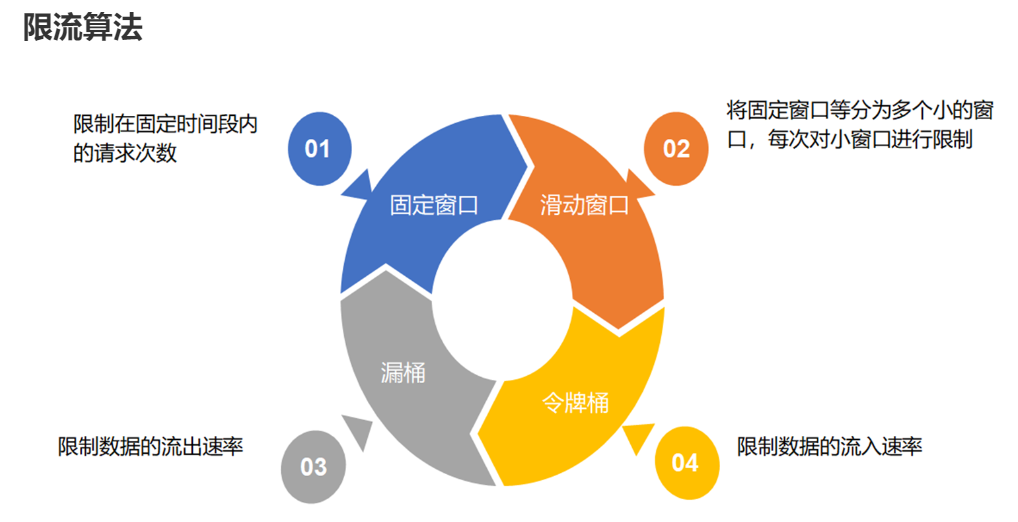
延伸:Redis与限流★★★
- 使用Redis+Lua语言实现限流(代码见讲义)
- 限流算法有哪些?
- 固定窗口算法:
- 滑动窗口算法:
- 漏洞算法:先有一个桶,桶的容量是固定的。以任意速率向桶流入水滴,如果桶满了则溢出(被丢弃)。桶底下有个洞,按照固定的速率从桶中流出水滴。漏桶核心是:请求来了以后,直接进桶,然后桶根据自己的漏洞大小慢慢往外面漏。
- 令牌算法:先有一个桶,容量是固定的,是用来放令牌的。以固定速率向桶放令牌,如果桶满了就不放令牌了。处理请求是先从桶拿令牌,先拿到令牌再处理请求,拿不到令牌同样也被限流了。
2.2 Redis底层原理
1)持久化
见上面动力节点的。
2)分布式锁
1. 最简单的实现是setnx,但如果某个客户端拿到锁后进程挂了没机会释放锁就会造成死锁。如何避免呢?设置过期时间!
SETNX productIdlock 1 // 加锁
EXPIRE productIdlock 10 // 10s后自动过期但上面两条操作不是原子性的,如果执行了一条之后宕机或者网络出现问题,依旧会有死锁的情况发生。在 Redis 2.6.12 之后,Redis 扩展了 SET 命令的参数,用这一条命令就可以了:
SET productIdlock 1 EX 10 NXredisTemplate.opsForValue().set(key, value, timeout, timeUnit);2. 锁被别人释放怎么办?
3. Java代码实现分布式锁(见讲义)
4. 锁过期时间不好评估怎么办?(看门狗)
5. Redisson中的分布式锁(可重入),把上面这些工作都封装好了
这一块看看动力节点的书P243页。
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.12.3</version></dependency>package com.msb.redis.config;import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MyRedissonConfig {/*** 所有对Redisson的使用都是通过RedissonClient*/@Bean(destroyMethod="shutdown")public RedissonClient redisson(){//1、创建配置Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");//2、根据Config创建出RedissonClient实例RedissonClient redisson = Redisson.create(config);return redisson;}
}6. 集群下的锁还安全吗?
以上1~5是分布式场景下,锁在「单个」Redis实例中可能产生的问题,并没有涉及到 Redis 的部署架构细节。 而我们在使用 Redis 时,一般会采用主从集群 +哨兵的模式部署,这样做的好处在于,当主库异常宕机时,哨兵可以实现「故障自动切换」,把从库提升为主库,继续提供服务,以此保证可用性。
但是因为主从复制是异步的,那么就不可避免会发生的锁数据丢失问题(加了锁却没来得及同步过来)。从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!
7. Redlock真的安全吗?(详见讲义)
2.3 Redis高并发高可用
1)集群
2)主从复制
①Redis主从复制原理?
3)哨兵
①哨兵机制的原理?
②Redis节点的下线判断?
③Sentinel Leader选举
2.4 Redis缓存使用问题及互联网运用
1)Redis缓存使用的数据不一致问题
针对高并发写场景。
通常选择先更新DB,再删除缓存。同时结合延时双删的处理,可以有效的避免缓存不一致的情况。“延迟双删” 伪代码如下:
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
2)缓存穿透、击穿、雪崩
针对高并发读场景。
缓存穿透:查询一个根本不存在的数据
原因:代码或业务出现问题;恶意攻击;
解决方法:缓存空对象(设置过期时间);布隆过滤器拦截。
缓存击穿:热key,过期的瞬间高并发
解决方法:使用互斥锁(mutex key);永远不过期
缓存雪崩:缓存层由于某些原因不能提供服务,比如同一时间缓存数据大面积失效。
3)热点Key
4)BigKey
2.5 Redis设计、实现
1)数据结构和内部编码
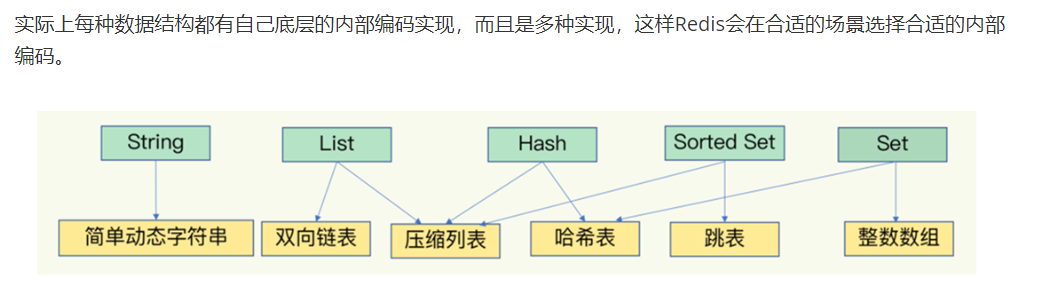
Redis存储的所有值对象在内部定义为redisobject结构体:type字段,encoding字段,lru字段,refcount字段,*ptr字段。
2)Redis中的线程和IO模型
略。
3)缓存淘汰算法
4)过期策略和惰性删除
略。