文章目录
- 1. 摘要
- 2. 算法:
- 2.1 结构:
- 2.2 微小的条件机制
- 2.3 多宽高比训练
- 2.4 改进自编码器
- 2.5 所有组合放到一起
- 2.6 主流方案比较
- 3. 未来工作
- 4. 限制
论文: 《SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis》
github: https://github.com/Stability-AI/generative-models
1. 摘要
SDXL,用于文生图,与之前SD相比,SDXL使用3倍大的UNet backbone:归因于更多的attention block、更大的cross-attention。作者设计多种新颖条件机制,同时引入一个精细化模块用于提升生成图片保真度。与之前版本SD相比,SDXL大大提升了性能。
2. 算法:

SDXL整体结构如图1所示。
2.1 结构:
扩散生成模型主要使用UNet结构,随着DM发展,网络结构发生变化:从增加self-attention、改进上采样层,增加cross-attention到基于transformer的结构。
为了高效,作者移除最浅特征层中transformer block,中间层使用transformer block数量设置为2和10,移除最深特征层(8倍降采样层),如表1作者与SD1.x及x2.x进行比较。

同时作者使用更强大预训练文本编码器,将OpenCLIP ViT-bigG与CLIP ViT-L倒数第二输出层进行concat。除了增加cross-attention层约束输入文本,另外将合并的文本编码作为模型条件输入,由此导致模型参数量达到2.6B,其中文本编码器器817M。
2.2 微小的条件机制
LDM的显著缺点为:训练模型需要比较小的图像大小,归因于其二阶段结构。对于该问题,一种方案为丢弃训练集中某一分辨率以下图片,比如:Stable Diffusion 1.4/1.5中512分辨率以下图片;另一种为过小图片进行上采样。然而前者将导致训练集大量数据丢弃,后者上采样过程引入人工因素,导致模型输出模糊样本。
作者使用原始图片分辨率 c s i z e = ( h o r i g i n a l , w o r i g i n a l ) c_{size} = (h_{original}, w_{original}) csize=(horiginal,woriginal)作为Unet条件输入,具体地,使用傅里叶特征将图片编码,concat为向量,该向量与timestep embedding相加。该过程如算法1

推理时,用户可设置所需图像分辨率尺度,如图3,随着图像尺寸提升,图片质量提升。

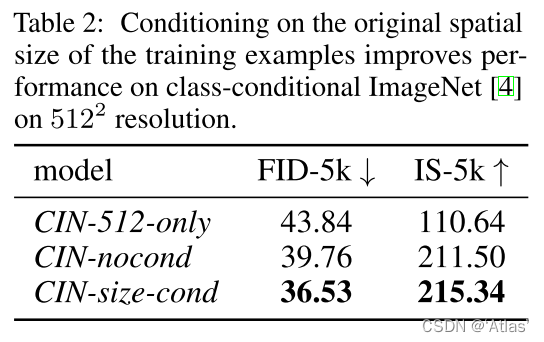
作者比较仅使用512 * 512分辨率以上数据集(CIN-512-only)、所有数据(CIN-nocond)、增加分辨率条件(CIN-size-cond),结果如表2,
基于裁剪参数调节模型

如图4前两行,之前模型生成目标可能被裁剪,这由于训练过程使用随机裁剪,为对齐batch中数据尺寸。为解决此问题,作者在加载数据过程,使用均匀采样裁剪坐标 c t o p 、 c l e f t c_{top}、c_{left} ctop、cleft(距离左上角点距离),并将其作为条件参数通过傅里叶特征编码送入模型。该过程如算法1所示。推理时设置 ( c t o p , c l e f t ) = ( 0 , 0 ) (c_{top}, c_{left}) = (0, 0) (ctop,cleft)=(0,0)可生成目标在图中心的样本,如图5所示。

2.3 多宽高比训练
当前文生图模型所生成图片为正方形,512 * 512或1024 * 1024,与真实图片存在差异。对此作者使用多种宽高比图片进行训练,但像素总量接近1024*1024,宽、高为64倍数。
预训练阶段使用固定宽高比及分辨率,只有在finetune阶段使用多种宽高比训练;
2.4 改进自编码器
作者训练与原始Stable Diffusion相同网络结构的自编码器,额外增加跟踪权重的指数滑动平均,实验结果如表3,SD-VAE 2.x为改进后结果。

2.5 所有组合放到一起
作者训练最终模型SDXL,使用2.4节提到的自编码器。
首先进行预训练基础模型,使用内部数据集,宽高分布如图2,训练时使用分辨率256*256,同时使用size及crop condition,如2.2节所述;之后在512 * 512图片上进一步训练;最后在1024 * 1024分辨率,基于不同宽高比进行训练。

精细化阶段
如图6,作者发现有些生成样本局部质量低,对此作者基于高质量、高分辨率数据在隐空间单独训练LDM,如SDEdit所提,利用基础模型生成隐向量进行加噪降噪处理。推理时,如图1,渲染来自基础SDXL模型的隐向量,基于该向量,使用同一文本输入,利用精细化模型进行扩散去噪。可视化结果如图6、13。

生成图片用户评估结果如图1左,该精细化模块作用明显。但在FID、CLIP指标上,与文本越一致样本,指标反而低于SD-1.5、SD-2.1,如图12,作者分析Kirstain等人证明COCO zero-shot FID得分与视觉评估负相关,应以人工评估为准,作者实验与此一致。

2.6 主流方案比较
图8为各种主流生成方案结果比较

3. 未来工作
单阶段:SDXL为二阶段方法,需要额外精细化模型,增加内存及采样速度,未来研究单阶段方案;
文本合成:较大的文本编码器,相对于之前SD模型,提升了文本表达能力,但是插入token或者放大模型可能也会有帮助;
结构:作者实验了基于transformer的结构:UViT、DiT,但是没有增益,需要进一步研究超参;
蒸馏:SDXL生成质量虽然提升,但是推理成本增加,未来借助蒸馏降低该成本;
模型训练过程是离散的且需要偏离噪声,Karras等人提出的EDM框架可能是未来模型训练方案,时间连续、采样灵活、无需噪声纠正机制。
4. 限制
- 对于生成复杂结构充满挑战,比如人手,如图7所示。虽然使用很多训练数据,但是人体结构复杂性导致难以获得准确表征一致性,这可能由于图中手及相似目标具有比较高方差,难以建模;

- 某些细微差别,如微妙的灯光效果或微小的纹理变化导致生成图像不真实;
- 当前模型训练依赖大规模数据集,可能引入社会种族问题,生成图像进而存在该问题;
- 当样本包含多个目标时,模型存在“concept bleeding”现象,即不同元素出现合并或堆叠,如图14。该问题可能由于文本编码器导致,所有信息压缩到单个token,难以联系到合适目标及属性,Feng等人通过单词关系编码解决;对抗损失也可导致此现象,由于不同联系的负样本出现在同一batch;

- 呈现长且易读文本存在困难,如图8,克服此问题需要进一步强化模型文本生成能力;