HBase
简介
概述
-
HBase是Yahoo!公司开发的后来贡献给了Apache的一套开源的、分布式的、可扩展的、基于Hadoop的非关系型数据库(Non-Relational Database),因此HBase并不支持SQL(几乎所有的非关系型数据库都不支持SQL),而是提供了一套单独的命令和API操作
-
关系型数据库和非关系型数据库针对的数据是不同的
-
关系型数据库存储的数据都是结构化数据,即同一个表中所有的数据的结构都是完全相同的,所以此时可以采用SQL(Structed Query Language,结构化查询语言)来进行查询
-
非关系型数据库不只是可以存储结构化数据,还可以存储半结构化数据(数据本身可以拆分成基本组成单位,但是拆分完成之后,每条数据的结构不一定相同)甚至可以存储非结构化数据(数据本身没有结构)
-
-
HBase本身是仿照了Google的<The Big Table>来实现的,因此HBase和Big Table的原理几乎一致,只是Big Table使用的是C语言实现的,HBase使用的是Java
-
HBase支持对大量的数据进行随机且实时的读写,就意味着支持对数据进行修改
-
HBase基于集群的硬件可以管理非常大的表:billions of rows X millions of columns
-
到目前为止,HBase一共提供了4个版本:HBase0.X~HBase3.X
-
其中HBase0.X和HBase1.X已经停止更新,所以市面上也几乎不再使用
-
HBase2.x版本目前一直处在更新维护状态,所以市面上使用的比较多
-
HBase3.x还处在测试状态,不推荐于生产环境使用
-
-
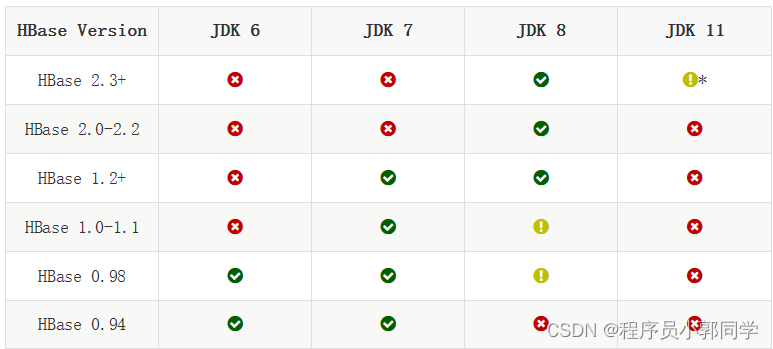
HBase是使用Java语言实现的,还基于HDFS来完成数据的存储,所以在选择HBase的时候,必须考虑和JDK以及Hadoop版本的兼容性!
-
HBase和JDK版本的兼容性
-
HBase和Hadoop版本的兼容性
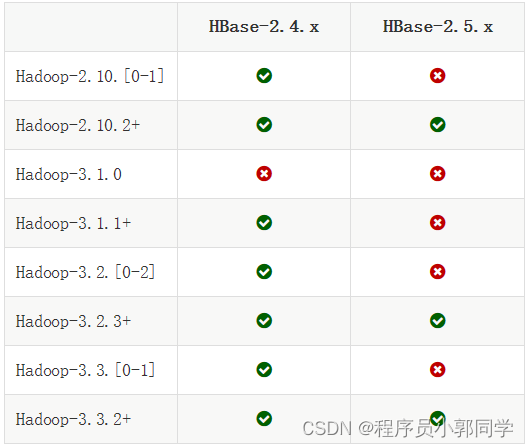
-
安装
-
环境:JDK8,Hadoop3.2.3+,Zookeeper
-
进入预安装目录
cd /opt/presoftware/ # 上传或者下载HBase的安装包
-
解压
tar -xvf hbase-2.5.5-bin.tar.gz -C /opt/software/
-
进入HBase的配置目录
cd /opt/software/hbase-2.5.5/conf/
-
编辑文件
vim hbase-env.sh # 在文件中添加 export JAVA_HOME=/opt/software/jdk1.8 export HBASE_MANAGES_ZK=false # 保存退出,生效 source hbase-env.sh
-
编辑文件
vim hbase-site.xml
在文件中添加
<!-- 开启HBase的分布式 --><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><!-- 指定HBase在HDFS上的存储位置 --><property><name>hbase.rootdir</name><value>hdfs://hadoop01:9000/hbase</value></property><!-- 指定Zookeeper的连接地址 --><property><name>hbase.zookeeper.quorum</name><value>hadoop01,hadoop02,hadoop03</value></property><!-- 指定WAL存放方式 --><property><name>hbase.wal.provider</name><value>filesystem</value></property>
-
指定子节点
vim regionservers
在文件中添加三台主机的主机名
# 删除掉原来的localhost,添加自己的主机名 hadoop01 hadoop02 hadoop03
-
将Hadoop的核心配置文件拷贝到HBase的配置目录下
cp $HADOOP_HOME/etc/hadoop/core-site.xml ./
-
远程分发
cd /opt/software/ scp -r hbase-2.5.5/ root@hadoop02:$PWD scp -r hbase-2.5.5/ root@hadoop03:$PWD
-
配置环境变量
# 编辑文件 vim /etc/profile.d/hbasehome.sh # 在文件中添加 export HBASE_HOME=/opt/software/hbase-2.5.5 export PATH=$PATH:$HBASE_HOME/bin # 保存退出,生效 source /etc/profile.d/hbasehome.sh
-
远程分发环境变量
scp /etc/profile.d/hbasehome.sh root@hadoop02:/etc/profile.d/ scp /etc/profile.d/hbasehome.sh root@hadoop03:/etc/profile.d/
-
分发完成之后,另外两个节点进行source
[root@hadoop02 ~]# source /etc/profile.d/hbasehome.sh [root@hadoop03 ~]# source /etc/profile.d/hbasehome.sh
-
测试
hbase version
-
三个节点上启动zookeeper
# 启动zookeeper zkServer.sh start # 查看zookeeper状态 zkServer.sh status
-
启动HDFS
start-dfs.sh
-
启动HBase
start-hbase.sh
-
通过
jps命令查看,在第一个节点上应该出现HMaster,三个节点上都应该出现HRegioServer -
HBase同样提供了对外访问的端口:http://主机名或者IP:16010
基本操作
基本概念
-
RowKey:行键
-
在HBase中,没有主键的概念,取而代之的是Rowkey
-
不同于关系型数据库,在HBase中,建表的时候不需要指定行键,而是在添加数据的时候手动指定行键
-
行键是表示数据是同一行的唯一标记
-
-
Column Family:列族/列簇
-
在HBase中,没有表关联的概念,取而代之的是列族
-
一个表中可以包含1到多个列族,每一个列族中可以包含0到多个列
-
在HBase中,建表的时候,需要指定列族,且列族指定之后不可变,但是不关心列,列是可以动态增删的
-
-
VERSION:版本
-
时间戳被称之为数据的版本
-
在HBase中,如果不指定,默认会存储数据的一个版本,也只会给用户返回一个版本
-
如果需要获取多个版本的数据,那么在建表的时候需要指定这个表中每一个列族能够存储数据的版本数,以及获取数据的时候需要指定获取版本的数量
-
-
Cell:单元(格)。在HBase中,如果需要锁定唯一的一条数据,需要通过行键+列族名+列名+版本号/时间戳来锁定,这个结构称之为Cell
-
namespace:名称空间
-
在HBase中,没有database的说法,取而代之的是namespace
-
Hase启动的时候,自带了两个名称空间:
hbase和default。hbase空间下放的是HBase的元数据信息,所以hbase不要动!在建表的时候,如果不指定,表是放在default空间下
-
-
DML和DDL
-
DDL(Data Defined Language):数据定义语言,用于定义数据的结构的,例如
create,drop等 -
DML(Data Manipulation Language):数据操纵语言,用于操作表中的数据的,例如
put,get等
-
注意问题
-
在HBase中,所有的数据默认要么是数字,要么是字符串,如果是字符串,必须使用单引号引起来
-
HBase适合于存储结构化和半结构化数据,或者也支持非结构化数据 - HBase中的数据的结构是稀疏的
-
HBase中的表需要先禁用才能被删除
-
HBase本身作为数据库,提供了完整的增删改查的功能。HBase是将数据存储到HDFS上,但是HDFS的特点之一是简化的一致性模型(允许一次写入多次读取不允许修改,但是允许追加写入)。那么HBase是如何实现数据的"修改"的?HBase的修改功能,并没有违反HDFS的特点,而是在文件尾部追加写入,并且HBase默认会给每一条数据添加一个时间戳。当用户试图获取数据的时候,此时HBase默认会返回时间戳最大的一条数据给用户,那么从用户角度而言,就感觉数据被修改了
基本命令
-
进入HBase的命令行
hbase shell
-
建表。建立person表,表中包含了3个列族:basic,info,extend
create 'person', {NAME => 'basic'}, {NAME => 'info'}, {NAME => 'extend'} # 如果建表的时候不需要修改其他属性,那么可以简化 create 'person', 'basic', 'info', 'extend' -
在添加数据的时候,指定这个数据对应的行键和列。put命令既可以添加数据也可以修改数据
put 'person', 'p1', 'basic:name', 'Bob' put 'person', 'p1', 'basic:age', 18 put 'person', 'p1', 'info:height', 179.9 put 'person', 'p2', 'basic:name', 'Amy' put 'person', 'p2', 'basic:gender', 'female' put 'person', 'p2', 'info:weight', 59.8
-
扫描整表
scan 'person'
-
禁用表
disable 'person'
-
删除表
drop 'person'
-
添加数据
append 'person', 'p1', 'basic:name', 'tom'
-
查询数据
# get命令不能直接对整表进行查询,在使用的时候,必须指定表名和行键 # 获取person表中p1行键对应的数据 get 'person', 'p1' # 获取person表中p1行键对应的basic列族的数据 get 'person', 'p1', {COLUMNS => 'basic'} get 'person', 'p1', 'basic' # 获取指定行键指定列的数据 get 'person', 'p1', {COLUMNS => 'basic:name'} get 'person', 'p1', 'basic:name' get 'person', 'p1', {COLUMNS => ['basic:name', 'info:height']} get 'person', 'p1', 'basic:name', 'info:heignt' -
获取指定列族的数据
scan 'person', {COLUMNS => 'basic'} -
获取指定列的数据
scan 'person', {COLUMNS => 'basic:name'} scan 'person', {COLUMNS => ['basic:name', 'info:height']} -
删除数据
# 删除指定行键指定列的数据 - 不能删除一个列族的数据,也不能删除一行数据 delete 'person', 'p2', 'basic:name' deleteall 'person', 'p2', 'basic:name' # 删除一行数据 deleteall 'person', 'p1'
-
建表,指定版本数量
# basic列族中的数据保留三个版本,info列族中的数据保留四个版本,extend列族中的数据保留1个版本 create 'person', {NAME => 'basic', VERSIONS => 3}, {NAME => 'info', VERSIONS => 4}, {NAME => 'extend'} -
获取数据
get 'person', 'ab', {COLUMN => 'basic:age', VERSIONS => 3} # 获取指定时间范围内的数据 get 'person', 'ab', {COLUMN => 'basic:age', TIMERANGE=>[0, 10000000000000]} get 'person', 'ab', {COLUMN => 'basic:age', TIMESTAMP => 100000000} -
查看所有的表
list
-
描述表
desc 'person' # 或者 describe 'person'
-
查看所有的名称空间
list_namespace
-
创建名称空间
create_namespace 'demo'
-
在demo空间下新建users表
create 'demo:users', 'basic' # 添加数据 put 'demo:users', 'u1', 'basic:name', 'hack'
-
查看demo空间下的表
list_namespace_tables 'demo'
-
删除空间
# 要求空间为空(不包含任何表) drop_namespace 'demo'
-
查看在运行的任务列表
processlist
-
查看HBase集群的状态
status
-
查看HBase的版本
version
-
查看当前用户
whoami
-
描述名称空间
describe_namespace 'demo'
-
修改名称空间的信息
# METHOD属性表示要执行set还是unset操作 alter_namespace 'demo', {METHOD => 'set', 'create_date' => '2024-04-02' } -
统计表中的行键个数
count 'person'
-
获取表的HRegion的个数
get_splits 'person'
-
摧毁重建表
truncate 'person'
-
修改表中列族的属性
alter 'person', { NAME => 'basic', VERSIONS => 5 } -
启用表
enable 'person'
-
判断表是否存在
exists 'orders'
-
判断表是启用还是禁用
# 判断表是否禁用 is_disabled 'person' # 判断表是否启用 is_enabled 'person'
-
定义行键所在的HRegion的位置
locate_region 'person', 'p1'
-
查看所有的过滤器
show_filters