一、非关系型数据库
1.什么是非关系型数据库
非关系型数据库(Non-relational Database)又称NoSQL数据库是一种不同于传统关系型数据库管理系统(RDBMS)的数据存储解决方案。NoSQL这个术语最初意味着"Not Only SQL",强调的是这类数据库不完全依赖于SQL作为查询语言,并且通常不遵循关系模型的设计原则。
2.非关系型数据库的主要特征
非关系型数据库的主要特征包括:
数据模型多样性:
键值对存储(Key-Value Store):如Redis,通过键快速检索对应的值。
文档型数据库(Document-Oriented):如MongoDB,存储类似JSON或XML格式的文档集合,每个文档有自己的内部结构。
列族数据库(Column-Family):如Cassandra和HBase,以列簇为单位存储数据,适合大量数据的分布式存储和分析。
图形数据库(Graph Database):如Neo4J,关注实体间复杂关系的建模和查询。
灵活性:非关系型数据库允许更灵活的数据模型,能够轻松应对不断变化的应用需求,特别是在需要水平扩展时。
可扩展性与分布式计算:多数NoSQL数据库设计之初就考虑到横向扩展(Scale-out),可以在多个节点间分布数据和负载,从而处理海量数据和高并发请求。
弱一致性与CAP定理:很多NoSQL系统在设计上选择了可用性与分区容错性优先于强一致性,提供了最终一致性保证,而非传统RDBMS的ACID事务。
性能优化:某些非关系型数据库通过减少冗余、利用数据局部性以及针对特定场景优化数据结构和算法,提高了读写性能
3.关系型数据库和非关系型数据库区别
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
(2)扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多克服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限个表,这都需要通过提高计算机性能来。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
关系:纵向 比如说硬件中添加内存
非关:横向 天然分布式
(3)对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
二、Redis数据库
1.什么是Redis数据库
Redis(远程字典服务器) 是一个开源的、使用 C 语言编写的 NoSQL 数据库即非关系数据库。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。
Redis 6.0 中新增加的多线程也只是针对处理网络请求过程采用了多线性,而数据的读写命令,仍然是单线程处理的。
2、Redis命中机制和淘汰机制
命中机制:查询数据可以查询到,例如查询100条可以查询到20条即命中20条
淘汰机制:Redis缓存的是高热数据,若负载高于限制则淘汰一些最近没有访问的数据,即删除
2.数据模型与操作命令
Redis支持多种数据结构,这使得它能灵活地处理不同类型的数据和场景
键值对(Strings):简单的字符串类型,可以进行 GET、SET、INCR 等操作。
哈希表(Hashes):内含多个字段的键值对集合,例如存储用户信息。
列表(Lists):有序的字符串列表,可用于消息队列或者粉丝列表。
集合(Sets):无序且不允许重复元素的集合,常用于标签系统、好友列表等。
有序集合(Sorted Sets):具有排序特性的集合,每个成员有分数属性,可用于排行榜、带权重的索引等
3.Redis的优点
(1)具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
(2)支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Sorted Sets 等数据类型操作。
(3)支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性:Redis 所有操作都是原子性的。
(5)支持数据备份:即 master-salve 模式的数据备份。
4.安装部署Redis
安装环境和Redis并解压
[root@localhost ~]#yum install -y gcc gcc-c++ make
#安装编译环境
[root@localhost opt]#ls /opt
redis-5.0.7.tar.gz
[root@localhost opt]#tar zxvf redis-5.0.7.tar.gz -C /opt/
#解压源码包
[root@localhost opt]#ls
redis-5.0.7 redis-5.0.7.tar.gz
[root@localhost opt]#cd /opt/redis-5.0.7/
[root@localhost redis-5.0.7]#ls
00-RELEASENOTES COPYING Makefile redis.conf runtest-moduleapi src
BUGS deps MANIFESTO runtest runtest-sentinel tests
CONTRIBUTING INSTALL README.md runtest-cluster sentinel.conf utils
#因为源码包中自带Makefile文件,所以不需要执行configure命令,直接执行make命令即可
[root@localhost redis-5.0.7]#make -j 4
#进行编译
[root@localhost redis-5.0.7]#make PREFIX=/usr/local/redis install
#安装redis执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
首先切入/opt/redis-5.0.7/utils
然后脚本设置文件


Selected config:
Port : 6379 #默认侦听端口为6379
Config file : /etc/redis/6379.conf #配置文件路径
Log file : /var/log/redis_6379.log #日志文件路径
Data dir : /var/lib/redis/6379 #数据文件路径
Executable : /usr/local/redis/bin/redis-server #可执行文件路径
Cli Executable : /usr/local/bin/redis-cli #客户端命令工具设置软连接把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
ln -s /usr/local/redis/bin/* /usr/local/bin/

如果需要修改redis服务的配置,部分配置还需要修改启动文件,例如端口号与PID文件路径
修改配置 /etc/redis/6379.conf 参数


修改配置 /etc/redis/6379.conf 参数
vim /etc/redis/6379.conf
bind 127.0.0.1 192.168.10.23 #70行,添加 监听的主机地址
port 6379 #93行,Redis默认的监听端口
daemonize yes #137行,启用守护进程
pidfile /var/run/redis_6379.pid #159行,指定 PID 文件
loglevel notice #167行,日志级别
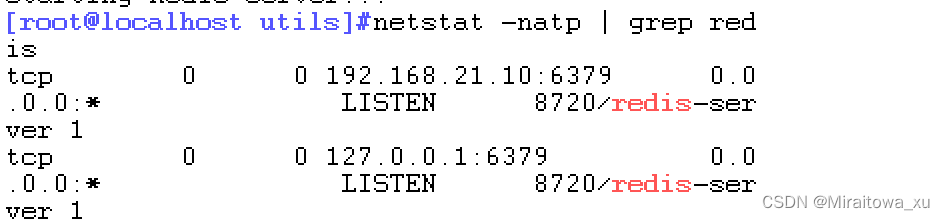
logfile /var/log/redis_6379.log #172行,指定日志文件查看端口发
总结
非关系数据
数据保存在缓存中,利于读取速度/查询数据
架构位置灵活
分布式、扩展性高
关系型数据库
安全性高(持久化)
事务处理能力强
任务控制强
可以做日志备份、 恢复容灾(能力更强一些
数据存储流向
非关系数据库
实列--》数据库--》集合---》键值对
非关系数据库不需要建数据库和集合(表)
关系型数据库
实列--》数据库--》表--》记录行---》存储到存储数据
redis 是一个关系型数据库 是一个开源基于内存上运行并且支持持久化,采用键值对(key-value),分布式集群架构
redis 有点 以及为什么这么快
- 读写速度快
- 支持丰富的数据类型
- 支持数据的持久化
- 操作方式原子性
- 支持数据备份 master-slave