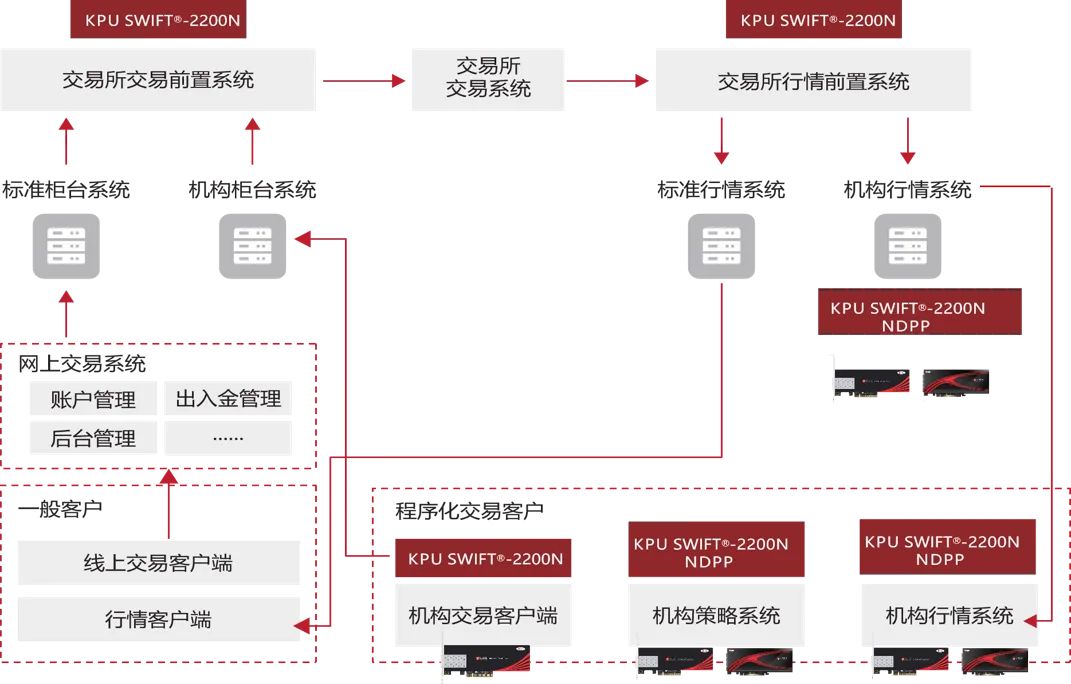
1. 客户端服务器建立连接过程
1.1 编写一个server的步骤是怎么样的?
int main(){int listenfd, connfd;pid_t childpid;socklen_t clilen;struct sockaddr_in cliaddr, servaddr;listenfd = socket(AF_INET, SOCK_STREAM, 0);bzero(&servaddr, sizeof(servaddr));servaddr.sin_family = AF_INET;servaddr.sin_addr.s_addr = htonl(INADDR_ANY);servaddr.sin_port = htons(SERV_PORT);bind(listenfd, (SA *)&servaddr, sizeof(servaddr));listen(listenfd, LISTENQ);for( ; ; ){clilen = sizeof(cliaddr);connfd = accept(listenfd, (SA *)&cliaddr, &clilen);if((childpid = fork()) == 0){close(listenfd);str_echo(connfd);exit(0);}close(connfd);}}
- serverfd = socket( opt ):调用socket( )方法创建一个对应的serverfd
- bind( serverfd, address ):调用bind( )方法将fd和指定的地址( ip + port )进行绑定
- listen( serverfd ):调用listen( )方法监听前面绑定时指定的地址
- clientfd = accept( serverfd ):进入无限循环等待接受客户端连接请求
1.2 server是怎么处理建立连接后的client请求的?
void str_echo(int sockfd){ssize_t n;char buf[MAXLINE];
again:while((n = read(sockfd, buf, MAXLINE)) > 0) // 从client读数据writen(sockfd, buf, n); // 给client写数据if(n < 0 && errno == EINTR)goto again;else if(n < 0)err_sys("str_echo: read error");
}
- n = read( clientfd, buf, size ):从客户端clientfd里读取传输进来的数据,并将数据存放到buf中
- writen( clientfd, buf, n ):往客户端clientfd写出数据n个字节的数据,写出的数据存放在buf中
1.3 server和client完整交互过程
![![[1712023405114.png]]](https://img-blog.csdnimg.cn/direct/a1b327e0f50640e59e91c756e5e96b41.png)
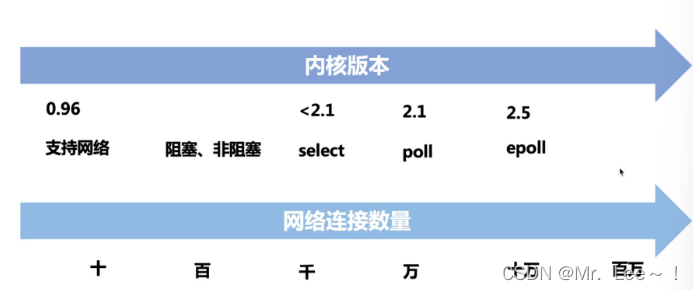
2.网络演变过程
2.1 演变的本质
2.2 阻塞IO:Blocking IO
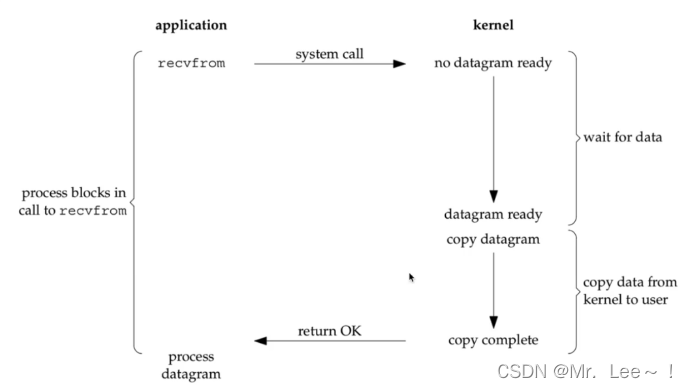
- 阻塞io:在内核中发生两次阻塞,一个是没有数据就绪的时候会发生阻塞,另一个是数据准备就绪的时候将数据从内核态copy到用户态的时候会阻塞
- 优点:
- 可以实现client和server端通信
- 实现简单,通常一个client连接分配一个线程进行处理
- 缺点:
- 能支持的并发client连接数较少,因为一台server能分配的线程是有限的,8个核最多能开8个线程;并且大量线程会造成上下文切换过多而影响性能
2.3 非阻塞IO:Nonblocking IO
-
核心矛盾:之所以一个client连接分配一个线程是因为处理客户端的读写时阻塞式的,为避免该阻塞影响后续接收新的client连接,所以将阻塞逻辑交由单独线程处理

-
非阻塞io:上层应用每过一段时间就向内核询问是否有数据就绪,如果没有数据就返回,如果有数据了就会从内核态cpoy数据到用户态
-
阻塞和非阻塞IO的区别:在于内核中数据尚未就绪时如何处理
- 对于非阻塞IO,则直接返回给用户态RWOULDBLOCK状态码错误
- 对于阻塞IO则一直处于阻塞状态,直到数据就绪并从内核态拷贝到用户态后才返回
-
如何设置非阻塞
- 方法1:
- 通过socket( )方法中的type参数来指定为SOCK_NONBLOCK即可设置该socket为非阻塞方式
- int socket( int domain, int type, int protocol );
- 方法2:
- 通过fcntl( )方法中args参数设置为O_NONBLOCK即可设置该socket为非阻塞方式
- int fcntl( int fd, int cmd, … /*arg*/ );
- fcntl( socket_fd, F_SETFL, flags | O_NONBLOCK )
- 方法1:
-
非阻塞的优缺点:
- 优点:将socket设置成非阻塞后,在读取时如果数据未就绪就直接返回,得益于非阻塞的特性可以通过一个线程管理多个client连接
- 缺点:需要不断轮询询问内核数据是否已经就绪,涉及很多无效的频繁的系统调用
2.4 IO多路复用第一版:select poll
-
核心矛盾:涉及很多次无用的平凡的系统调用,非阻塞socket在read时并不知道什么时候数据会准备好,所以需要不断的主动询问

-
所谓io多路复用:
- 网上大多数的观点是可以使用单个线程管理多个客户端的连接
- 另一个个人观点说io多路复用的是系统调用,原先是一个客户端通过一个系统调用去处理,现在转变成通过一次系统调用select/poll由内核主动通知用户哪些client数据已就绪,大大减少了无效的系统调用次数
select
#include <sys/select.h>
#include <sys/time.h>int select(int maxfd, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);
- maxfd:表示被select管理的描述符个数,值为最大描述符+1
- fd_set:表示一组描述符集合,select中是用一个位数组来实现的,要给描述符占一位
- readset、writeset、exceptset:可读事件集合、可写事件集合、异常事件集合
- timeout:等于0立即返回,大于0设置一个超时时间,小于0永远等待
poll
struct pollfd{int fd;short events; // 关心的事件short revents; // 发生的事件
};#include <poll.h>int poll(struct pollfd *fdarray, unsigned long nfds, int timeout);
- poll参数解释:
- fdarray:为传入的pollfd数组的首地址,该数组中的每一个元素为一个poll结构体镜像,关联一个管理的描述符fd
- nfds:传入的值为fdarray数组的长度,表示管理的描述符个数,主要原因在于前面的fdarray是一个可变长度的数组,因此需要指定数组长度
- timeout:无限等待(INFTIM,一个负值)、立即返回不阻塞(0)、等待指定的超时时间(timeout)
- poll事件定义:四类处理输入事件、三类处理输出事件、三类处理错误事件
- poll识别三类事件:普通(normal)、优先级带(priority band)、高优先级(priority)

select 和 poll 的区别
- 在实现上
- select底层实现是采用位数组来实现的,一个描述符对应一位
- poll底层是通过pollfd结构体来实现的,管理的描述符通过pollfd数组来组织,一个描述符对应一个pollfd对象
- 在用法上
- select默认大小是FD_SETSIZE(1024),修改的话需要修改配置参数同时重新编译内核来实现
- poll是采用变长数组管理的,理论上可以支持海量连接
- 相同点
- 二者在调用时,都需要从用户态拷贝管理的全量描述符到内核态,返回时也需要拷贝全量描述符从内核态到用户态,再有用户态遍历全量描述符判断哪些描述符有就绪事件
优缺点
- 优点:
- 充分利用了一次系统调用select/poll就可以实现管理多个client事件,大大降低了非阻塞IO频繁无效的系统调用
- 核心是将主动询问内核转变为等待内核通知,提升性能
- 缺点:
- 每次都需要将管理的多个client从用户态拷贝到内核态,在管理百万连接时,由拷贝带来的资源开销较大,影响性能
2.5 IO多路复用第二版:epoll
- 核心矛盾:select/poll每次都需要将管理的多个client从用户态拷贝到内核态,影响性能

epoll三大核心接口
1. epoll_create( )
#include<sys/epoll.h>
int epoll_create(int size);
- 从linux2.6.8以后,size参数已经被忽略,大于0即可
- epoll_create( )创建返回的epollfd指向内核中的一个epoll实例,同时该epollfd用来调用所有和epoll相关的接口(epoll_ctl和epoll_wait)
- 当epollfd不再使用时,需要调用close关闭。当所有指向epoll的文件描述符关闭后,内核会摧毁该epoll实例并释放和其关联的资源
- 成功会返回大于0的epollfd,失败返回-1
2. epoll_ctl( )
- 核心思想:将哪个客户端(fd)的哪些事件(event)交给哪个epoll(epfd)来管理(op)
#include<sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- epfd:通过epoll_create( )创建的epollfd
- op:EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL
- fd:待监听的描述符fd
- event:要监听的fd的时间(读、写、接收连接等),具体如下:

3. epoll_wait( )
#include<sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *event, int maxevents, int timeout);
- epfd:通过epoll_create( )创建的epollfd
- events:返回就绪的事件列表,就绪的事件列表个数通过epoll_wait( )的返回值来传递
- maxevents:最多返回的events个数,该值用来告诉内核创建的events有多大
- timeout:超时时间
- 返回值cnt:
- 0表示超时时间范围内无就绪队列
- 大于0表示返回就绪列表的个数(后续通过循环遍历events[0]~events[cnt-1])
- -1表示错误
- event检测:
if(event & EPOLLHUP){ ... } if(event & (EPOLLPRI | EPOLLERR | EPOLLHUP)){ ... }
epoll的ET模式和LT模式区别
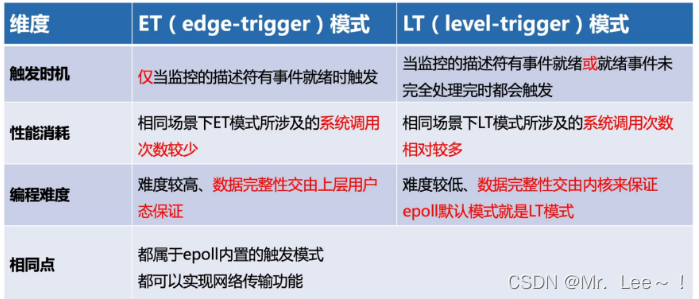
epoll内核实现


2.5 异步IO
- 异步io,两个阶段都不会被阻塞
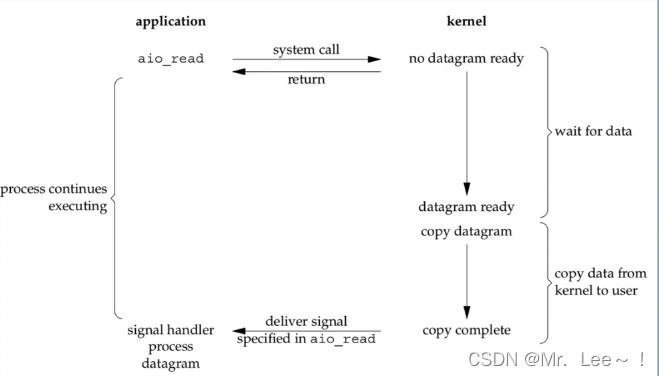
同步IO和异步IO的区别
- 第二阶段copy阶段,如果是用户线程来完成的就是同步io,如果是内核线程来完成的就是异步io

3. 主流网络模型
3.1 thread-based架构模型
-
适用场景:并发量不大的场景
-
原因:
- 线程的创建、销毁开销较大
- 创建的线程需要占用一定的资源
- 线程切换需要一定的资源开销
- 一个进程能开辟的线程数据有限
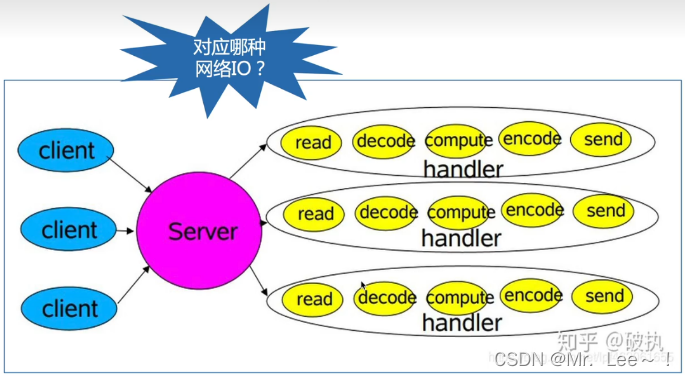
-
对应的是阻塞IO
3.2 single-reactor单线程网络模型
- 核心:IO中的accept、read、write都是在一个线程完成的
- 存在问题:目前该模型中,除了IO操作在reactor线程外,业务逻辑处理操作也在reactor线程上,当业务逻辑处理比较耗时时,会大大降低了IO请求的处理效率
- 典型实现:redis(4.0之前)

3.3 single-reactor线程池模型
- 如何改进:引入了线程池,用来专门处理业务逻辑操作,提升IO响应速度
- 缺陷:虽然在引入线程池后IO响应速度提升了,但在管理百万级连接、高并发大数据量时,单个reactor线程仍然会效率比较低下

3.4 multi-reactor多线程模型
- 如何改进:保留原先single-reactor引入的线程池外,新扩展了reactor线程。引入了多个reactor线程,也称为主从结构
- 扩展方法:
- 单进程(多线程)模式
- 多进程模式
- 典型实现:
- netty
- memcached
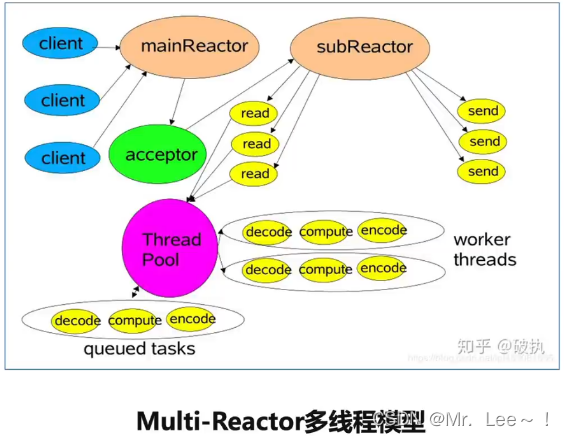
3.5 multi-reactor多进程模型
- mainreactor进程主要负责接收客户端连接,并将建立的客户端连接进行分发给subreactor进程中
- subreactor进程主要负责处理客户端的数据读写和业务逻辑的处理
- 经典实现:nginx

两种multi-reactor模型对比