基于YOLOv5的关键点检测应用于溺水检测与警报提示是一种结合深度学习与计算机视觉技术的安全监控解决方案。该项目通常会利用YOLOv5强大的实时目标检测能力,并通过扩展或修改网络结构以支持人体关键点检测,来识别游泳池或其他水域中人们的行为姿态。
项目概述:
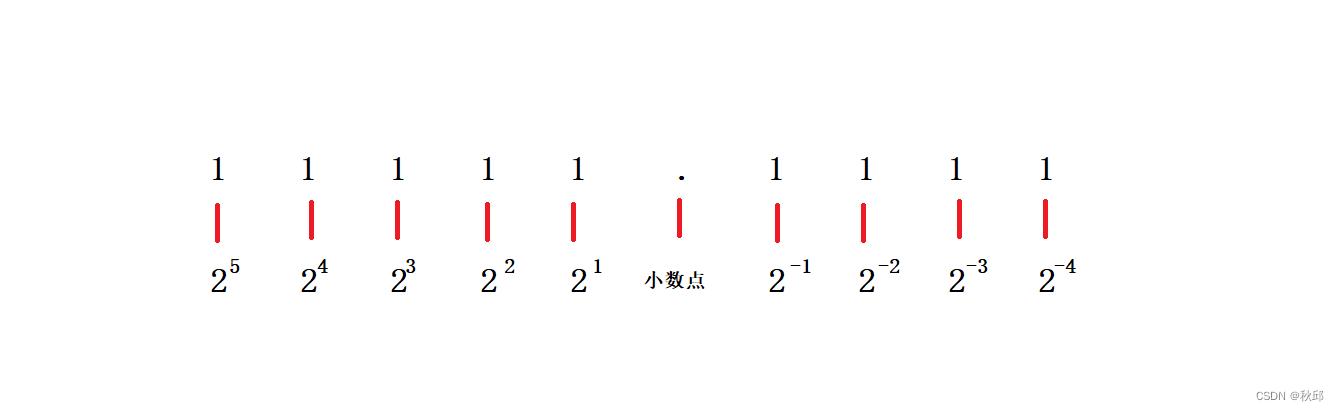
1. YOLOv5基础:YOLOv5(You Only Look Once version 5)是一种流行的实时目标检测模型,以其速度和精度著称,适合在嵌入式设备或视频流处理中进行实时分析。
2. 关键点检测:在此应用场景中,模型不仅需要检测到人,还需要定位并识别出人体的关键点,例如头部、四肢的位置。这有助于判断一个人是否处于正常游泳状态还是可能正在挣扎或无法自主浮起的溺水姿态。
3. 溺水行为识别:通过分析关键点的变化和特定姿势特征,系统可以设计算法来识别潜在的溺水行为模式,如身体垂直下沉、挥臂动作减少或者头部持续低于水面等。
4. 警报提示:一旦检测到可能的溺水事件,系统会立即触发警报机制,可以通过声音、灯光、短信或APP通知等方式向现场救生员或监护人发送紧急信号。
实施步骤:
- 数据集构建:收集包含各种溺水和正常游泳场景的图像或视频素材,并进行人工标注,包括人体边界框及对应的关键点位置。
- 模型训练:使用YOLOv5作为基础模型,添加或调整网络架构以支持关键点检测任务,并使用标注好的数据集进行训练。
- 性能优化:通过调整模型参数和后处理逻辑,提高对溺水行为检测的准确率和实时性。
- 系统集成:将训练好的模型部署到实际硬件平台,比如摄像头监控系统,并关联警报模块实现自动化的溺水预警功能。
总之,基于YOLOv5的关键点检测技术用于溺水检测与警报提示项目,旨在提供一个高效、可靠的早期风险探测系统,以减少意外溺水事故的发生。

快速定位:
首先,通过人体检测技术可以在视频流或图像中迅速锁定人物的位置,尤其是在复杂的水体环境中区分人体与其他物体。
精细识别:
人体关键点检测则能进一步提供关于人体姿态和动作的详细信息,如手脚位置、头部朝向等。当人在溺水时,会有特定的动作特征,如无规律的手臂挥动、腿部上下浮动、面部露出水面的时间和次数减少等,这些特征可通过关键点变化体现出来。
行为分析:
通过对检测到的关键点运动轨迹和姿势变化进行分析,可以识别出是否属于潜在的溺水行为模式。比如,正常的游泳者与溺水者在水面活动特点上存在显著差异,溺水者往往无法维持有效的划水动作或头颈部位置控制。
自动化预警:
基于人工智能算法的系统能够在无人值守的情况下持续工作,一旦检测到可能的溺水行为,系统可以自动触发警报,通知相关人员及时介入救援。

合YOLOv5和关键点检测技术主要用于构建一个能够同时进行目标检测和关键点定位的系统。YOLOv5是一种高效的目标检测算法,具有速度快、准确性高的特点,而关键点检测则是用来预测目标物内部的关键点位置,如人体的手肘、膝盖、面部特征点等。
结合yolov5-主要创新点
在YOLOv5的基础上加入关键点检测的具体原理和步骤通常包括:
模型架构修改:
需要在YOLOv5的基础网络之上添加关键点预测分支。这个分支通常是回归网络,用于预测每个检测到的目标框内的关键点坐标。
训练数据准备:
准备包含标注关键点信息的数据集,如COCO数据集就包含了丰富的物体检测和关键点标注信息。
损失函数设计:
修改YOLOv5原有的损失函数,添加关键点定位误差的部分,如Smooth L1 Loss或者heatmap-based的方法(如 heatmap regression 或 heatmap classification)。
模型训练:
根据新的模型结构和训练数据进行训练,使得模型不仅能够检测出图像中的物体,还能准确地标记出每个目标的关键点位置。
例如,在CSDN技术社区中提到的“yolov5人脸检测,带关键点检测”的案例,就是在YOLOv5的项目中通过修改模型结构和配置文件,实现了人脸检测的同时还能够对人脸的关键点进行精准回归。对于不同任务,可能还需要根据实际情况调整模型结构和训练策略。
溺水检测
class Tracker:def __init__(self):# Store the center positions of the objectsself.center_points = {}# Keep the count of the IDs# each time a new object id detected, the count will increase by oneself.id_count = 0def update(self, objects_rect):# Objects boxes and idsobjects_bbs_ids = []# Get center point of new objectfor rect in objects_rect:x, y, w, h = rectcx = (x + x + w) // 2cy = (y + y + h) // 2
警报提示代码
"frame_check = 7\n","flag = 0\n","while True:\n"," ret,frame=cap.read()\n"," if ret==False:\n"," break\n"," #frame=cv2.resize(frame,(1020,500))\n"," results = model(frame)\n"," imgRGB = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n"," \n"," #Apply the mediapipe pose detection module for detection\n"," result = pose.process(imgRGB)\n"," #print(results.pose_landmarks)\n"," h , w , c = frame.shape\n"," # Draw landmarks\n"," if result.pose_landmarks:\n"," mpDraw.draw_landmarks(frame,result.pose_landmarks, mpPose.POSE_CONNECTIONS)\n"," landmarks = result.pose_landmarks.landmark\n"," \n"," #for land in mpPose.PoseLandmark:\n",
因此,将人体关键点检测与人体检测技术整合起来,不仅可以大大提高监控系统的智能化程度,还可以为公共场所的安全管理、水上救援行动提供有力的技术支持。然而,这类技术仍需面对复杂光线、水体波动等因素带来的挑战,并且在算法设计上需要充分考虑各种特殊情况以避免误报和漏报。
往期热门项目大合集:
YOLOV5单目测距+车辆检测+车道线检测+行人检测(教程-代码)_yolov5只想检测车-CSDN博客
使用yolov9来实现人体姿态识别估计(定位图像或视频中人体的关键部位)教程+代码_yolov9动作识别-CSDN博客
语义分割实战项目(从原理到代码环境配置)-CSDN博客
改进的 A*算法的路径规划(路径规划+代码+教程)_a*算法的改进算法-CSDN博客
计算机视觉实战项目3(图像分类+目标检测+目标跟踪+姿态识别+车道线识别+车牌识别+无人机检测+A*路径规划+单目测距与测速+行人车辆计数等)-CSDN博客
图像分类保姆级教程-深度学习入门教程(附代码)-CSDN博客