谁进行优化?优化什么?
优化不能仅从数据库方面考虑,比如,在存储达到数据库极限、应用涉及人员设计的代码稀巴烂的情况下,进行调优就是杯水车薪的效果。
涉及到优化人员:
- 数据库管理员
- 应用程序架构师
- 应用程序设计人员
- 系统管理员
- 存储管理员
涉及到的优化内容:
- 应用程序:(与开发人员共享 )
SQL语句性能
更改管理 - 实例优化:
内存
数据库结构
实例配置 - 操作系统交互:(与系统管理员共享)
1/0 交换 参数
优化工具
用于优化的过程取决于工具
- 基本工具:
动态性能视图
统计信息
DEM工具 - AWR报告
- DBA脚本
优化方法
- 自上而下优化以下内容
在优化应用程序代码之前先优化设计
在优化实例之前先优化代码 - 对可以带来最大潜在好处的方面进行优化,并确定:
最长的等待
最大的服务时间 - 达到目标时停止优化
内存管理
数据库管理系统是一种对内存申请和释放操作频率很高的软件,如果每次对内存的使用都使用操作系统函数来申请和释放,效率会比较低,加入自己的内存管理是 DBMS 系统所必须的。通常内存管理系统会带来以下好处:
- 申请、释放内存效率更高;
- 能够有效地了解内存的使用情况;
- 易于发现内存泄露和内存写越界的问题。
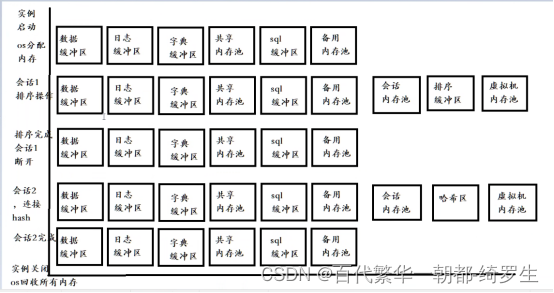
DM 数据库管理系统的内存结构主要包括内存池、缓冲区、排序区、哈希区等。根据系统中子模块的不同功能,对内存进行了上述划分,并采用了不同的管理模式。
从资源角度,主要有 2 类对象:内存池、缓冲区。
内存池
DM Server 的内存池包括共享内存池和其他一些运行时内存池。
共享内存池、备用内存池、字典缓冲区(DICT_BUF_SIZE)、Sql 缓冲区(cache_pool_size), 运行时的内存池(排序区、哈内希区、会话存池,虚拟机内存池);
-
共享内存池(名称 share_pool)
定义:共享内存池是 DM Server 在启动时从操作系统申请的一大片内存。
DM 采用共享内存池的方式:一次向操作系统申请一片较大内存,作为共享内存池。当系统在运行过程中需要申请小片内存时,可在共享内存池内进行申请,当用完该内存时,再释放掉,即归还给共享内存池。主要涉及参数:初始大小,增量大小和目标大小
DM 系统管理员可以通过 DM Server 的配置文件(dm.ini)来对共享内存池的大小进行设置,共享池初始大小的参数为 MEMORY_POOL。如果在运行时所需内存大于配置值,共享内存池也可进行自动扩展(增量大小),INI 参数== MEMORY_EXTENT_SIZE== 指定了共享内存池每次扩展的大小,参数 MEMORY_TARGET 则指定了共享内存池扩展到超过该值后,空闲时会收缩到的大小(目标大小)。
查看方法:
select para_name,para_value,para_type from v$dm_ini where para_name like '%MEMORY%';
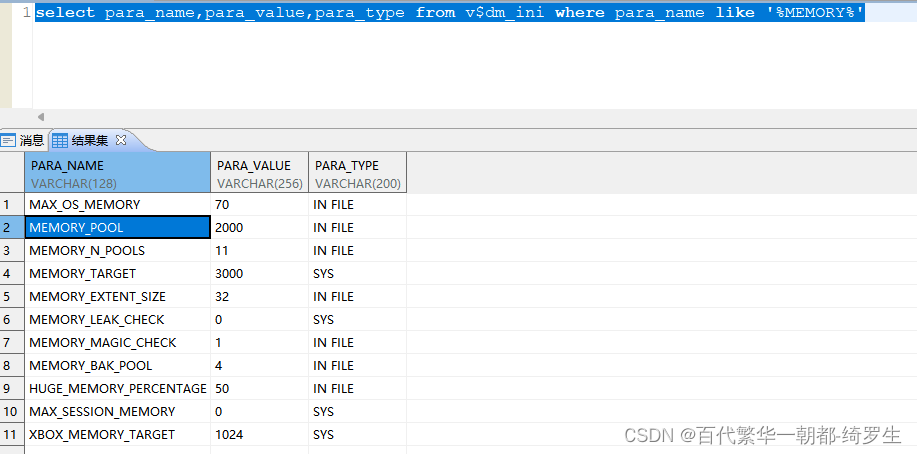
Memory_target:指定单个共享内存池的目标大小
Memory_pool: 指定单个共享内存池的初始大小
Memory_extent_size:提定单个共享内存池的增量大小
Memory_N_pool:指定多个共享内存池
私有池(会话内存池,虚拟机内存池、排序缓冲区、哈希缓冲区),
- 运行时内存池
DM Server 的一些功能模块在运行时还会使用自己的运行时内存池。这些运行时内存池是从操作系统申请一片内存作为本功能模块的内存池来使用,如会话内存池、虚拟机内存池等。
缓冲区
- 数据缓冲区
数据缓冲区是 DM Server 在将数据页写入磁盘之前以及从磁盘上读取数据页之后,数据页所存储的地方。这是 DM Server 至关重要的内存区域之一,将其设定得太小,会导致缓冲页命中率低,磁盘 IO 频繁;将其设定得太大,又会导致操作系统内存本身不够用。
系统启动时,首先根据配置的数据缓冲区大小向操作系统申请一片连续内存并将其按数据页大小进行格式化,并置入“自由”链中。
数据缓冲区存在三条链来管理被缓冲的数据页:
一条是“自由”链,用于存放目前尚未使用的内存数据页
一条是“LRU”链,用于存放已被使用的内存数据页(包括未修改和已修改)
一条即为“脏”链,用于存放已被修改过的内存数据页。全部修改过的数据页,执行checkpoint后,脏页的数据全部落盘。(写盘的时机:checkpoint、脏链满的时候落盘、有个参数可以查多长时间写盘,默认可能是3s,需要查询。)业务非常繁忙的时候,可以修改,一般情况下,默认是1,一次取一页。一次取多个页可以减少IO。但是并不是说这个数越大越好,你读了很多页不一定能用上,造成无用IO。应该取一个合适的值,需要自己取试。
在系统运行过程中,通常存在一部分“非常热”(反复被访问)的数据页,将它们一直留在缓冲区中,对系统性能会有好处。对于这部分数据页,数据缓冲区开辟了一个特定的区域用于存放它们,以保证这些页不参与一般的淘汰机制,可以一直留在数据缓冲区中。
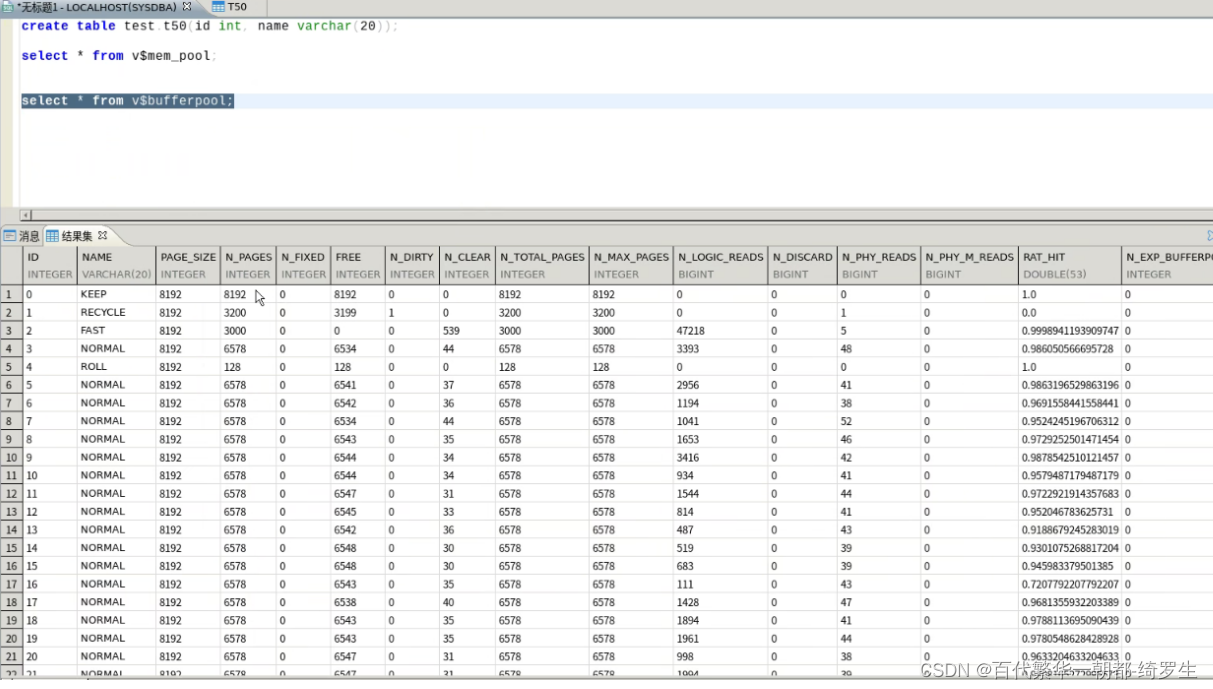
DM Server 中有四种类型的数据缓冲区,分别是 NORMAL、KEEP、FAST 和 RECYCLE。
–NORMAL 缓冲区主要是提供给系统处理的一些数据页,没有特定指定缓冲区的情况下,默认缓冲区为 NORMAL;
–KEEP 的特性是对缓冲区中的数据页很少或几乎不怎么淘汰出去,主要针对用户的应用是否需要经常处在内存当中,如果是这种情况,可以指定缓冲区为 KEEP。
–RECYCLE 缓冲区供临时表空间使用。
–FAST 缓冲区根据用户指定的 FAST_POOL_PAGES 大小由系统自动进行管理,用户不能指定使用 RECYCLE 和 FAST 缓冲区的表或表空间。
dm.ini 文件中 BUFFER、KEEP、RECYCLE、FAST_POOL_PAGES,这些值分别对应是 NORMAL 缓冲区大小、KEEP 缓冲区大小、RECYCLE 缓冲区大小、FAST 缓冲区数据页总数。
- 日志缓冲区(从操作系统申请的)
日志缓冲区是用于存放重做日志的内存缓冲区。为了避免由于直接的磁盘 IO 而使系统性能受到影响,系统在运行过程中产生的日志并不会立即被写入磁盘,而是和数据页一样,先将其放置到日志缓冲区中。那么为何不在数据缓冲区中缓存重做日志而要单独设立日志缓冲区呢?主要是基于以下原因:
1、 重做日志的格式同数据页完全不一样,无法进行统一管理;
2、 重做日志具备连续写的特点;
3、 在逻辑上,写重做日志比数据页 IO 优先级更高。
DM Server 提供了参数 ==RLOG_BUF_SIZE ==对日志缓冲区大小进行控制,日志缓冲区所占用的内存是从共享内存池中申请的,单位为页数量。
达梦数据库服务启动时,向操作系统申请 6 块独立的内存(数据缓冲区,字典缓冲区,日志缓冲区,共享内存池,备用内存池,sql 缓冲区)。
如果有会话连接,则会去建立相关的内存池(会话内存池,排序内存池,虚拟机内存池等)会话结束后,相关内存池回收。
服务器关闭,OS 回收所有的内存。
1、数据缓冲区(keep,recycle,normal,fast).服务器启动后,向操作系统申请四块大小固定的内存做为四个分区,服务器关闭前向操作系统归还内存。数据缓冲区不会拓展。
数据缓冲区四种类型:
Normal: 普通数据页,缓冲区满进行淘汰。
Fast:数据页,回滚页,常驻缓冲区
Recycle: 临时表数据页,正常淘汰
Keep:普通数据页,很少淘汰
5、日志缓冲区,创建时从共享内存池分配内存,服务器关闭前归还
内存,日志缓冲区拓展时直接向共享内存池申请。
6、运行时内存池:在需要使用的时候被创建,使用完毕立即销毁,
(会话内存池,虚拟机内存池,排序区和哈希区)。
Cpu (高速缓存)----内存-(内存缓冲区)------磁盘
备用内存池
操作系统的内存池不沟通的情况下,会用到备用内存池。
字典缓冲区
表非常多的时候,可能需要扩大字典缓冲区。
SQL缓冲区
执行完SQL后,SQL的解析或者结果集,均缓存到SQL缓冲区。结果集的缓存就缓存一会儿会儿。 会判断结果集的数据是否改变,如果没有改变,下次还有可能用到。
如果有很多复杂的SQL,或者有SQL包,SQL缓冲区需要扩大。
图解:

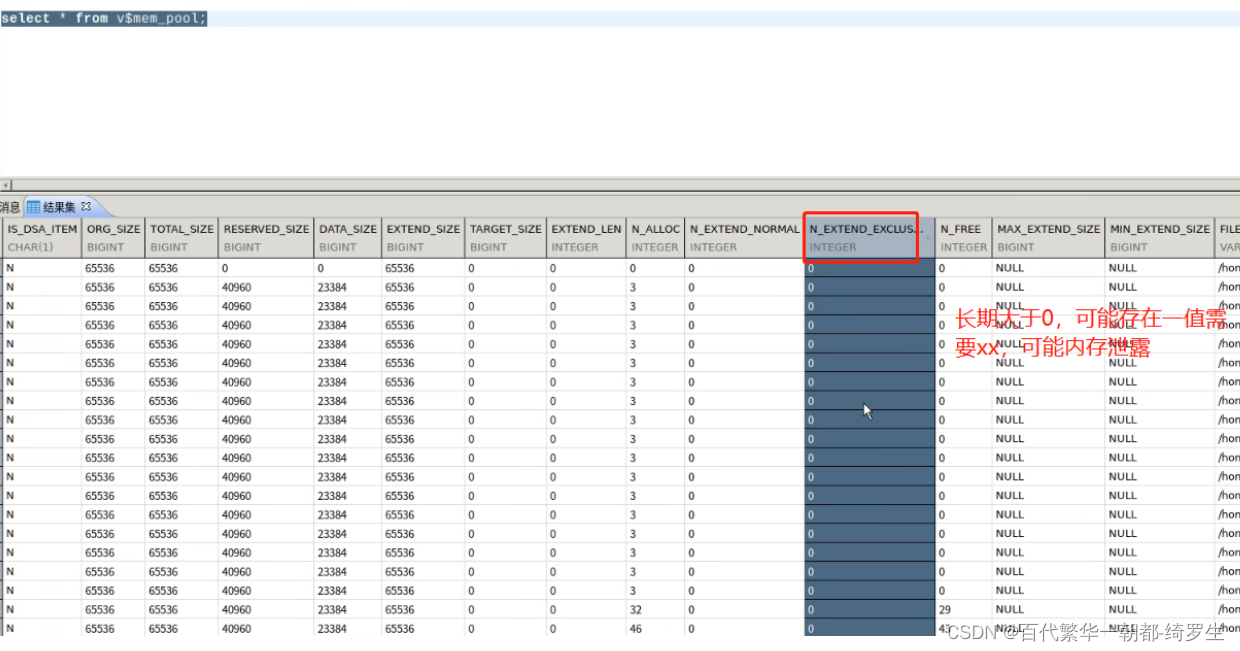
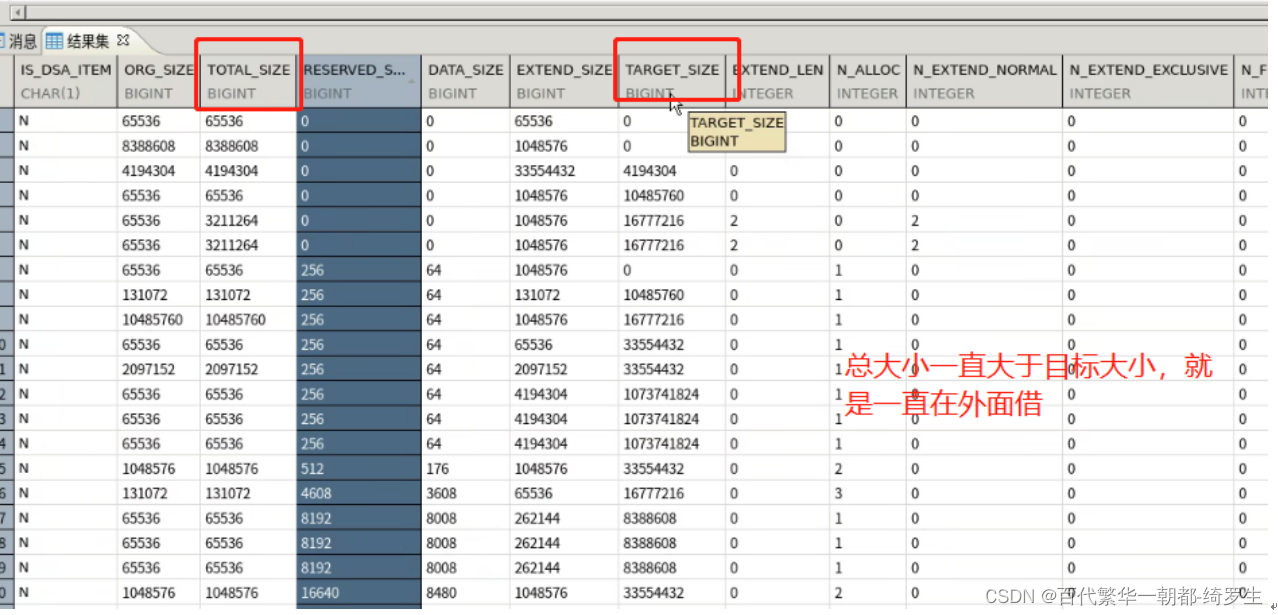
内存查询视图及修改
- V$mem_pool 查看所有内存池的使用信息。
select * from V$mem_pool

- V$bufferpool
如果free=0,说明这个区域经常淘汰,说明缓冲区的参数给太小。 fast经常出现淘汰的操作,fast给小。
select * from V$bufferpool
- Buffer+mpool
达梦数据库使用的内存
通过v$sql_stat 可以查询哪些SQL执行超过xx秒
可以设置 来设置阀值

Select * from v$mem_reginfo order by refnum desc;

refnum特别大,说明数据库内存一直在涨,就需要分析,为啥一直涨内存。
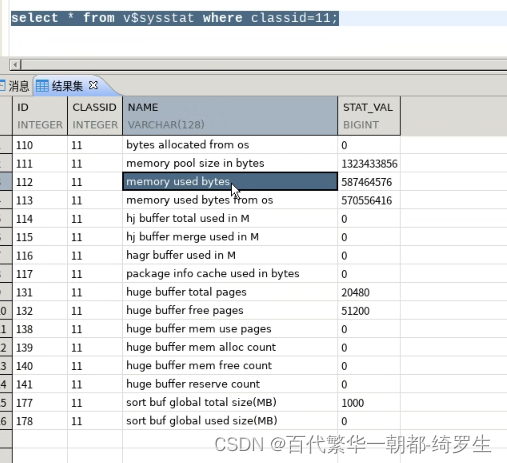
内存的使用情况
select * from v$sysstat where classid=11;
Rlog_buf_size rlog_pool_size v$rlogbuf
Rlog_parallel_enbable=1
Sp_set_para_value(1,’BUFFRE’,300);
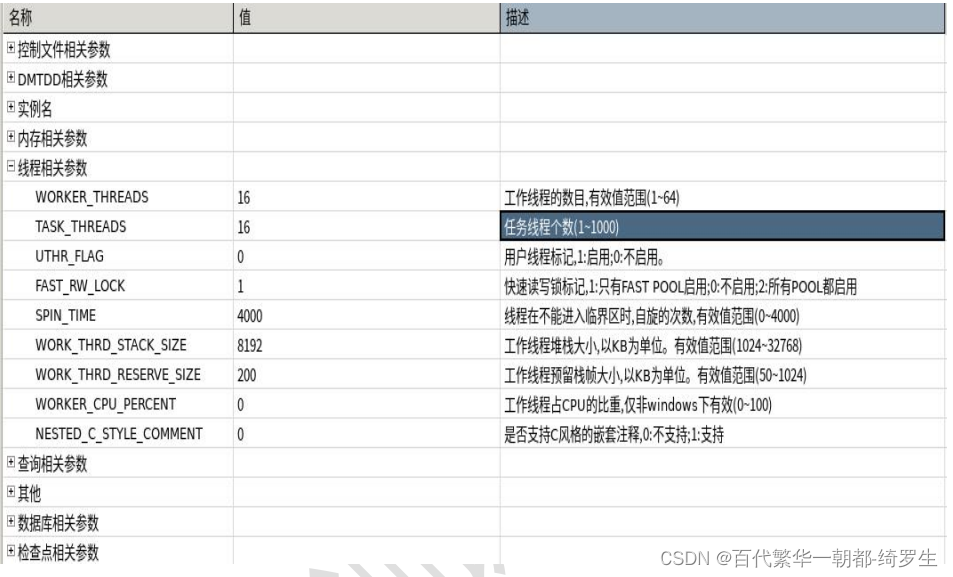
后台的线程管理
达梦是单进程多线程的,每一个实例只有一个进程 v$process;
查询所有线程:
select * from v$threads

监听线程:在服务端口上进行循环监听,一旦有来自客户的连接请求,
监听线程被唤醒并生成一个会话申请任务。
工作线程:DM 服务器的核心线程
任务线程:最多一千个。
工作线程是用来干活的: 工作线程数和任务线程数,在调优的时候经常用到。
工作线程:最多64核,达梦服务的核心线程,从任务队列区任务,完成响应的任务。最开始达梦为了能够及时响应线程的工作,一个session过来,均有一个工作线程完成,减少线程切换代价,提高系统效率。 工作线程可能忙不过来,就有task线程,相当于公司前台,分配任务用的,工作线程完成后,在任务线程里面取数据。
用到CPU,如果CPU核数太少,但是工作线程调整太高,此时无效。
IO 线程:最为耗时的操作之一。Dm.ini IO_THR_GROUPS,默认 8 个
调度线程:
日志 flush 线程
日志归档线程
日志 APPLY 线程
MAL 系统相关线程
V$ latches :记录当前正在等待的线程信息
V$ THREADS:记录当前系统中活动线程的信息
V$ wthrd_history :记录自系统启动以来,所有活动过的线程的要历史
信息。
V$ process :记录服务器进程信息。
V$ SESSIONS:显示当前会话的具体信息
sql 优化
85%的操作,都在做SQL优化。
Select * from v$sessions where state =’ACTIVE’;
首先了解SQL执行过程
- 语法分析(字典缓冲区)
- 语义分析(字典缓冲区)
- 权限判断(字典缓冲区)
- 是否存在执行计划(SQL缓冲区,buffer )
Select * from v$sessions where state=’ACTIVE’; --全部解析
SELECT * FROM v$sessions WHERE state=’ACTIVE’;
虽然功能一样,但是当作不同SQL,又解析一遍,就很慢。如果SQL规范书写,写出来像一个人写的。会提高效率。
- 执行SQL:结果缓冲到sql缓冲区(sql缓冲区,排序区,哈希区,buffer、日志缓冲区)
Sql 编写规则:
1、统一编写风格
Select * from test;
SELECT * FROM TEST;
SETECT * FROM test;
2、使用绑定变量
Select * from test where id=?
Select * from test where id=2 … 10000
3、避免排序 sort,索引来代替 .
sort是在磁盘进行排序,慢。
4、减少表的重复扫描。
5、用 exist 替代 in
Select * from test.t1 where id in (1,3,5,7,8,9); --找到3,后续所有数据再对比一遍。
Select * from test.t1 where id exist (1,3,5,7,8,9); --找到3,后面就不找了,逻辑标识就变成true,表示找到了
6、避免普通索引列上有计算。
Select * from tab1 where c-1=123; --索引失效 如果非要使用到函数,用函数索引
Select * from tab1 where c=123+1;
7、避免隐式转换
Bri (date) bri=’1990-01-01’;
Bri = to_date(‘1990-01-01,’yyyy-mm-dd’); to_date() to_number()
to_char() To_date(bri)= to_date
8、尽量避免使用 select *
9、多表连接的时候,必须使用别名来引用列,记录数大于 1000 万时,关
联的大表尽量不超过 4 个。
10、嵌套循环连接查询需要注意地方:
选择小表作为驱动表,统计信息尽量准确,保证优化器选对驱动表。适当
使用索引。
11、hash join 特点
Hash 连接比较消耗内存
Hj_buf_golbal_size hj_buf_size hj_blk_size.
12、对于大批量 dml 操作分段提交,防止大事务。
13、尽量使用缓存。
缓存/内存速度是磁盘速度的几百倍。(所以又redis内存缓存数据库)
14、Delete update 加 where。
Select ename from emp e where exists (select ‘x’ from dept where
dept_no=e.dept_no and dept_cat =’A’)
Select ename from dept d, emp e where e.dept_no = d.dept_no and
dept_cat=’A’
影响 SQL 执行计划的因素:
参数配置、统计信息、数据分布、索引、选择率,连接顺序、连接方式。
Cpu,内存,数据类型、锁等待,网络延迟,结果集大小。
创建索引的原则:
1、根据索引查询只返回很少一部分行
2、索引作为一个较瘦版本的表
3、组合索引列的顺序合理安排,最优化把等值匹配的列放最前面,范围
匹配的放在后面。把过滤性好的列放前面。查询时组合索引只能利用一个
非等值字段。
不走索引:
1、条件列不是索引首列。
2、条件列上有函数或计算。
3、存在隐式类型转换。
4、如果走索引会更慢。
5、没有更新统计信息。
实例优化
1.操作系统
CPU决定计算速度
Cpu_speed
每一个操作符都是有代价的
关注oom,内存溢出,数据库实例进程会被杀。
I/o 调度算法
2.实例
数据库架构,INI 参数
通常不要轻易修改dm.ini,特别是没有依据的情况下。
新版本安装的时候,会有性能最优参数,数据库会自动修改,平常再观察,依据实际情况修改。
3.SQL优化
相关视图 V$ sessions, v$ lock, v$sql_history
开启 sql 日志 SVR_LOG
SP_SET_PARA_VALUES(1,’SVR_LOG’,1);
关闭 sql 日志
Sp_set_para_values(1,’SVR_LOG’,0);
使用 sql 日志的流程:
—设置 SQL 过滤规则,只记录必要的 SQL,生产环境不要设成 1
– 2 只记录 DML 语句
–3 只记录 DDL 语句
–22 记录绑定参数的语句
– 25 记录 SQL 语句和它的执行时间
–28 记录 SQL 语句绑定的参数信息
SELECT SF_SET_SYSTEM_PARA_VALUE('SQL_TRACE_MASK','2:3:22:25:28', 0,1);
–同步日志会严重影响系统效率,生产环境必须设置为异步日志
SELECT SF_SET_SYSTEM_PARA_VALUE('SVR_LOG_ASYNC_FLUSH',1,0,1);
–下面这个语句设置只记录执行时间超过 200ms 的语句
SELECT SF_SET_SYSTEM_PARA_VALUE('SVR_LOG_MIN_EXEC_TIME',200, 0,1);
–下面的语句查看设置是否生效
SELECT * FROM V$DM_INI where para_name='SVR_LOG_ASYNC_FLUSH';
SELECT * FROM V$DM_INI where para_name='SQL_TRACE_MASK';
SELECT * FROM V$DM_INI where para_name='SVR_LOG_MIN_EXEC_TI
ME';
达梦数据库配置了执行计划重用的参数:use_pln_pool;
0:禁止执行计划的重用,
1:启用执行计划的重用功能。
2:对不包含显示参数的语句进行常量参数优化。
3:即使包含显示参数的语句,也进行常量参数优化。
Sql 性能分析工具ET:
ET 是 DM 自带的分析工具,能统计 SQL 每个操作符的时间花费,从而定位
到有性能问题的操作,指导用户去优化。
INI 参数 ENABLE_MONITOR=1, MONITOR_SQL_EXEC=1 时,ET 才能使用。
–两个参数均为动态参数,可直接调用系统函数进行修改
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR’,1)
SP_SET_PARA_VALUE(1,'MONITOR_SQL_EXEC’,1)
–关闭 ET
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',0);
SP_SET_PARA_VALUE(1,'MONITOR_SQL_EXEC',0);
ET 功能的开启将对数据库整体性能造成一定影响,优化工作结束后尽量关闭该功能以提升数据库整体运行效率
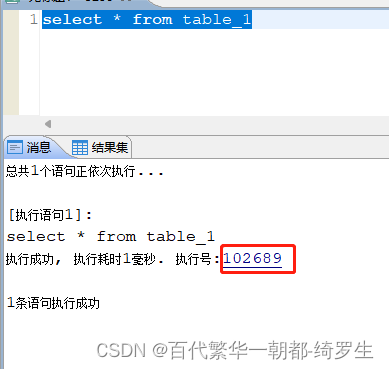
查看方式
执行 SQL 语句后,客户端会返回 SQL 语句的执行号。单击执行号即可查看 SQL 语句对应的 ET 结果

ET 结果说明:比如时间开销时间长 以及 占比比较高的 可作为优化的重点对象
OP: 操作符
TIME(us): 时间开销,单位为微秒
PERCENT: 执行时间占总时间百分比
RANK: 执行时间耗时排序
SEQ: 执行计划节点号
N_ENTER: 进入次数
awr 报告
数据库快照是一个只读的静态的数据库。DM 快照功能是基于数据库实现的,每个快照是
基于数据库的只读镜像。通过检索快照,可以获取源数据库在快照创建时间点的相关数据信
息。 为了方便管理自动工作集负载信息库 AWR(Automatic Workload Repository)的
信息,系统为其所有重要统计信息和负载信息执行一次快照,并将这些快照存储在 AWR 中。
用 户 在 使 用 DBMS_WORKLOAD_REPOSITORY 包之 前 , 需 要 提 前 调 用系 统 过
程 SP_INIT_AWR_SYS(1)创建包,包创建成功后就可以使用空间数据类型以及包提供的方法。
DM 数据库在创建该包时,默认创建一个名为 SYSAUX 的表空间,对应的数据文件为
SYSAWR.DBF,该表空间用于存储该包生成快照的数据。如果该包被删除,那么 SYSAUX 表
空间也对应地被删除。
SYS.WRM$ _WR_CONTROL 记录快照的相关控制信息。
Sys.wrm$ _snapshot 记录快照的相关信息
1、初始化 awr 快照包
SQL>SP_INIT_AWR_SYS(1);
2、设置时间
SQL> call dbms_workload_repository.awr_set_interval(10);
3、手动生成快照
SQL> call dbms_workload_repository.create_snapshot();
4、查询快照
SQL> select * from sys.wrm$_snapshot;
5、生成 awr 报告
SQL> call sys.awr_report_html(1,4,'/dm8','awr1.html');
数据库负载: db_time/(elapsed *cpus) >80% , 说明存在性能问题,我们需要分析 top 事件,或 sql order by elapse time
NON_parse cpu:sql 实际运行时间/(sql 实际运行时间+sql 解析时间)。太低,表示 sql 解析消耗时间过多。
Execute to parse:语句执行与分析比例。如果 sql 重用率高,则这个比例高。相关的动态视图。
BUFFER HIT 90%
等待事件:v$ system_event, v$ session_event, v$ event_name, v$ sessions;
内存:v b u f f e r , v buffer, v buffer,v bufferpool, v$ pool , V$ mem_pool; v$ cachepln;