什么是数据仓库?
数据仓库是一个用于存储大量数据并支持数据分析与报告的系统。它通常用于集成来自不同来源的数据,提供一个统一的视图,以便进行更深入的分析和决策。
数据仓库的主要优势?
- 决策支持:为企业决策提供可靠数据支持
- 数据整合:整合多个数据源,提供一致的视图
- 高性能:支持复杂查询和大数据量的分析
数据仓库的结构?
数仓通常包含三个主要层级:
- 采集层(Staging Layer):用于原始数据的收集与存储,不做任何改动
- 集成层(Integration Layer):将采集层数据整合、清洗和转换,建立一个统一、一致的数据视图
- 应用层(Access Layer):用于向用户展示数据的最终层,提供直观易懂的数据分析和报告
数据仓库的建模?
- 维度(Dimensions)
维度是用来描述业务过程的可度量特征,通常为数据建模提供上下文。它们是用来对事实进行分类和筛选的属性。常见的维度包括时间、地理位置、产品、客户等。维度可以有层次结构,如时间维度可以包括年、季度、月份等层级。
- 事实(Facts)
事实是在数据仓库中可以量化的事物或事件,是可度量的数字指标。它们通常是业务过程中的一些关键性能指标,如销售额、利润、数量等。事实与维度结合使用,可以提供对业务过程的完整描述和分析。
- 指标(Measures)
指标是用来度量业务绩效的计算标准。它们可以基于事实和维度数据计算得出,用于衡量业务的表现和趋势。常见的指标包括平均销售额、利润率、增长率等。指标通常被用于数据分析和报告中,以帮助决策者更好地理解业务数据和趋势。
- 统计表 (Stats)
统计表由维度和指标构成,维度一般包含时间维度、地区维度,可以是二维、三维甚至多维,维度越多,则数据的统计粒度越细。统计表可以给到应用层去使用,也可以使用 BI 工具(metabase)去可视化展示。
在数据仓库中,维度、事实、指标、统计是构建数据模型和报告的关键组成部分,它们的正确理解和应用有助于提高数据分析的精度和价值。
数据库 Doris
Doris 数据库是一种开源的、基于大规模并行处理(Massively Parallel Processing, MPP)架构的分布式列式存储在线分析处理(Online Analytical Processing, OLAP)数据库系统。它由百度公司开发并贡献给 Apache 软件基金会,目前作为 Apache 顶级项目进行维护和进一步发展。
Doris 数据库具备多项优势,使其非常适合作为数据仓库技术栈的一部分,甚至作为独立的数据仓库解决方案。以下是 Doris 数据库的主要优势,以及为何它适合作为数据仓库:
- 高性能与实时性
- MPP 架构:Doris 利用 MPP 技术,将查询任务并行化处理,有效利用集群资源,显著提升查询速度
- 列式存储:列式存储方式减少了 I/O 开销,利于数据压缩,尤其适合于聚合查询和过滤查询,大大加快了数据扫描速度
- 实时分析:Doris 支持实时数据导入,如通过 Stream Load 或 Flink 对接,实现数据的近实时更新与查询,满足业务对即时数据分析的需求
Tips:假设你是一家电商公司的数据分析师,需要实时监控销售数据,以便快速做出决策。使用 Doris 数据库,你可以将订单数据实时导入(如通过 Kafka 消息队列),Doris 会立即处理这些数据并更新相关表。当你执行如下 SQL 查询时:
SELECThour(order_time), product_category, SUM(order_amount)
FROMorders
WHEREorder_date = CURDATE()
GROUP BYhour(order_time), product_category;
Doris 凭借其 MPP 架构和列式存储,能在短时间内从大量订单数据中筛选出当日的交易记录,按照小时和商品类别进行聚合计算,提供实时销售趋势分析。由于 Doris 对实时数据的高效处理能力,你几乎可以实时看到最新数据的变化,迅速响应市场动态。
- 易用性与灵活性
- 简单易用的 SQL 接口:Doris 遵循 SQL 标准,用户可以直接使用 SQL 进行查询、数据加载和管理,降低学习成本
- 在线表结构变更:允许在不影响业务的情况下动态调整表结构,包括添加、删除列或修改表定义,无需停机维护
- 预聚合 Rollup:支持创建预计算的聚合表(Rollup 表),提前计算并存储常见聚合结果,提高查询效率
Tips:随着业务发展,你发现需要在订单表中新增一列记录用户的购物偏好。在传统数据库中,这可能需要停机维护,但在Doris 中,你可以在线添加列:
ALTER TABLE orders ADD COLUMN shopping_preference VARCHAR(100);
这一操作不会影响正在进行的查询或数据导入,确保业务连续性。此外,若发现某些聚合查询频繁且耗时较长,你可以创建预聚合 Rollup 表:
CREATE ROLLUP TABLE orders_summary
ON orders (order_date, product_category)
AGGREGATE (SUM(order_amount));
以后查询每日各产品类别的总销售额时,可以直接查询 orders_summary 表,查询速度将大幅提高。
- 高效数据管理与运维
- 自动负载均衡:系统自动管理数据分片(Tablet)的分布与副本迁移,确保数据均匀分布在各节点上,实现高效资源利用
- 高可用与容错:通过多副本机制,节点故障时能自动切换至备份副本,确保数据不丢失且服务持续可用
- 轻量级运维:Frontend(FE)节点负责集群管理,简化了部署与运维工作,降低了总体运维成本
Tips:你的 Doris 集群规模随着数据增长而扩大,新加入的节点会自动参与到数据分片(Tablet)的存储和查询处理中,系统自动进行负载均衡。当某个 BE 节点出现故障时,Doris 会自动切换到其他副本节点,确保查询不受影响。此外,你还可以通过设置数据过期策略,自动清理超过一定期限(如保留最近一年数据)的历史订单记录,节省存储空间:
ALTER TABLE orders SET ("TTL"="1year");
- 丰富的生态兼容性与集成
- 多种数据源接入:支持从多种异构数据源(如 MySQL、HDFS、Kafka 等)直接加载数据,方便数据集成
- BI 工具对接:与主流商业智能(BI)工具无缝集成,如 Tableau、Power BI 等,便于构建数据分析报告与可视化仪表板
- 大数据生态集成:与 Hadoop、Spark、Flink 等大数据生态系统组件良好兼容,便于在大数据处理管道中嵌入 Doris 作为 OLAP 层
Tips:你的公司已有一套基于 Hadoop 的数据湖,其中存储了历史订单数据。你希望在 BI 工具(如 Tableau)中直接分析这些数据,而无需额外 ETL 过程。借助 Doris 对 HDFS 数据源的支持,你可以创建外部表直接映射到 Hadoop 上的数据文件:
CREATE EXTERNAL TABLE historical_orders
LIKE orders
LOCATION 'hdfs://your-hadoop-cluster/path/to/orders';
然后在 Tableau 中连接到 Doris 数据库,即可直接对 historical_orders 表进行深度分析,构建可视化报表。
- 数据仓库功能完备
- 数据分区:通过灵活的分区策略,用户可以根据时间、地区或其他业务逻辑对数据进行组织,优化查询性能与数据管理
- 数据分桶:支持数据分桶,进一步细化数据分布,提升特定查询条件下的查询效率
- 数据生命周期管理:可以设置数据过期策略,自动清理过期数据,符合数据仓库对数据保留期限的管理要求
综上所述,Doris 数据库凭借其强大的实时分析性能、易用性、高效的数据管理、广泛的生态集成以及完备的数据仓库功能,完全可以胜任作为数据仓库技术栈的角色。无论是作为数据仓库的核心引擎,还是作为现有数据仓库体系中的一个关键组件,Doris 都能够为用户提供快速、灵活且经济高效的分析能力。特别是在需要实时分析、快速响应业务变化以及简化运维场景下,Doris 数据库的优势尤为突出。
Q & A
- 什么是 MPP?
MPP(Massively Parallel Processing),即大规模并行处理。MPP 是一种分布式计算架构,用于数据库和数据仓库系统,它将查询任务分解成多个子任务,这些子任务在集群中的多个节点上并行执行。这样可以充分利用硬件资源,大幅度提升处理海量数据的查询性能。
- 什么是列式存储?
列式存储是一种数据存储方式,与传统的行式存储相对。在列式存储中,数据表的每一列被单独存储,并且同一列的所有数据值紧密相邻。这意味着查询只需要读取涉及的列,而不是整行数据,这对于 OLAP(在线分析处理)场景非常有利,尤其是当查询仅关注少量列或进行大量聚合计算时。列式存储还利于数据压缩,因为同一列内数据类型相同,更容易进行高效压缩,从而减少存储空间需求和 I/O 开销。
- 为什么说传统数据库在新增列时需要停机维护?借助 ORM 不是可以实现方便快捷地操作数据库吗?
传统数据库(尤其是关系型数据库)在增加新列时,通常需要对整个表进行结构修改。这个过程可能涉及到以下步骤:
- 更新表的元数据(定义)以包含新列
- 对于非空新列,可能需要为表中已有行分配默认值或填充策略指定的值
- 对于有索引、约束或其他依赖于表结构的对象,可能需要相应地更新或重建
这些操作可能导致以下情况:
- 锁表:在执行 DDL(数据定义语言)操作时,数据库系统可能会锁定整个表,阻止其他事务对表的读写,以确保数据一致性。这会导致在修改期间服务中断
- 长时间阻塞:对于大型表,特别是含有大量数据的表,新增列可能需要较长时间,特别是如果涉及到数据填充或索引重建。这段时间内,表无法被其他查询访问
- 数据迁移:在某些数据库管理系统中,即使支持在线 DDL,也可能需要后台进程进行数据迁移,尤其是在有分区表或集群环境中,这同样可能引起性能下降或短暂的服务不可用
ORM(Object-Relational Mapping)与新增列: ORM(对象关系映射)是一种编程技术,用于将面向对象编程语言中的对象模型与关系型数据库中的表结构进行映射,以简化应用程序与数据库之间的交互。虽然 ORM 可以帮助开发者以更高级、抽象的方式操作数据库,但它并不能解决数据库本身在执行 DDL 操作(如新增列)时可能引发的停机问题。
尽管某些数据库系统提供了在线 DDL 功能,允许在不停止服务的情况下添加新列,但这通常需要数据库引擎具备特定的并发控制机制和数据迁移策略来尽量减少对业务的影响。然而,即便是支持在线 DDL 的数据库,对于大型表或高并发场景,新增列仍可能引起性能波动或短暂的服务降级。因此,是否需要停机维护主要取决于底层数据库管理系统的能力和具体操作的复杂性,而非 ORM 工具的使用与否。
总之,传统数据库在新增列时可能需要停机维护,是因为该操作涉及到对表结构的实质性更改,可能触发锁表、长时间阻塞或数据迁移等影响服务可用性的行为。ORM 作为一种中间件,虽然简化了应用程序与数据库的交互,但并不直接影响数据库底层的 DDL 操作特性。现代数据库系统(如 Doris)提供的在线表结构变更能力,允许在不影响业务的情况下动态调整表结构,这是其易用性和灵活性优势的具体体现。
- 基于上一问,市面上的企业应用在面对需求要需新增列等场景时,除了停机维护的方式,还有其他策略吗?如何降低对正常用户的影响?
- 计划停机维护
对于确实需要停机才能完成新增列操作的数据库系统,企业通常会选择在业务低峰时段或者事先通知用户的特定时间内进行维护,以尽量减少对正常用户使用的影响。
维护窗口应尽可能短,并确保有详细的回滚计划,以防万一出现问题可以迅速恢复到维护前状态。
- 在线 DDL 支持
许多现代数据库系统(如 Oracle、PostgreSQL、MySQL 的部分版本、SQL Server 等)已经支持在线 DDL(数据定义语言)操作,可以在不完全阻断业务的情况下添加新列。这些系统通常采用各种技术来确保数据的一致性和避免长时间锁表,如使用元数据版本控制、两阶段提交、并行数据迁移等。
使用这类数据库的企业可以在不影响用户正常使用的情况下进行列添加,不过即使如此,对于大型表或高并发场景,仍可能引起短暂的性能波动或服务降级,因此也需要合理规划和监控。
- 应用层面兼容
在某些情况下,如果业务允许一定的灵活性,可以在应用代码中暂时模拟新列的行为,直到安排合适的维护窗口。例如,可以通过在现有列中增加额外的信息,或者在应用逻辑中临时存储新列的值,然后在后续的数据库维护窗口中正式添加新列并迁移数据。
- 数据仓库分离
对于分析型需求,有时可以选择在数据仓库层面而非生产数据库中新增列。数据仓库通常与业务系统异步更新,可以在不影响实时业务的前提下进行结构变更。业务系统产生的数据经过 ETL(抽取、转换、加载)过程进入数据仓库,此时可以灵活地添加新列并重新计算历史数据。
- 数据库中间件或 Proxy
使用数据库中间件(如 ShardingSphere、MyCat 等)或 Proxy(如 ProxySQL、MaxScale 等)的企业,可以在中间件层模拟新列的存在,先在中间件上完成逻辑上的列添加,然后在实际数据库维护窗口时同步更新数据库结构。这样,应用程序在中间件看来已经包含了新列,而实际数据库的变更则可以在对用户影响最小的时候进行。
- 云数据库服务
公有云服务商提供的数据库服务(如 AWS RDS、Azure SQL Database、Google Cloud SQL 等)往往提供更高级的管理功能和更高的可用性承诺。对于支持在线 DDL 的云数据库,用户可以利用其特性在不停服的情况下完成列添加;对于需要停服的变更,云服务商可能提供透明的维护升级服务,如蓝绿部署、读写分离切换等,最大限度减少对用户的影响。
- 举例说明列式存储和行式存储的区别?
假设我们有一个销售数据表 sales,包含以下字段:
- order_id:订单ID(整数)
- customer_id:客户ID(整数)
- product_id:产品ID(整数)
- order_date:订单日期(日期)
- quantity:购买数量(整数)
- price:单价(浮点数)
在行式存储数据库中,数据按行组织,每行包含表中所有字段的值。假设我们有三笔销售记录:
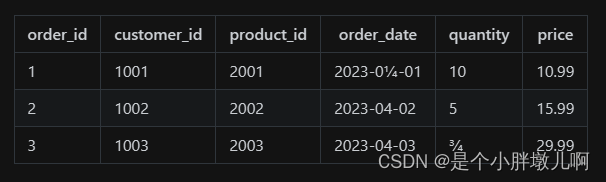
在硬盘上,这些数据以连续的块形式存储,每行数据紧凑地排列在一起。例如:
1|1001|2001|2023-04-01|10|10.99
2|1002|2002|2023-04-02|5 |15.99
3|1003|2003|2023-04-03|3 |29.99
在列式存储数据库中,数据按列组织,同一列的所有值存储在一起。同样的三笔销售记录在列式存储中的布局如下:
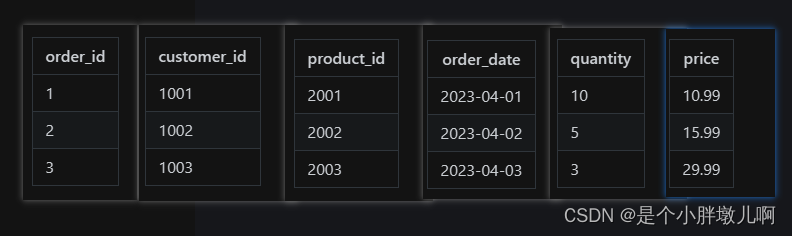
在硬盘上,这些数据按列分别存储在不同的物理位置,每列数据紧凑排列。例如:
订单ID列: 1|2|3
客户ID列: 1001|1002|1003
产品ID列: 2001|2002|2003
订单日期列: 2023-04-01|2023-04-02|2023-04-03
购买数量列: 10|5|3
单价列: 10.99|15.99|29.99
假设我们需要执行两个查询:
- 查询1:统计所有产品的总销售额
- 查询2:找出所有在 2023 年 4 月购买了产品的客户 ID
在行式存储中:
- 查询1:需要遍历所有行,累加 quantity 乘以 price。因为数据按行存储,每次读取都需要获取所有字段的值,即使只关心 quantity 和 price 字段
- 查询2:同样需要遍历所有行,检查 order_date 是否在 2023 年 4 月,并提取对应的 customer_id。同样,即使只关心这两个字段,也需要读取整行数据
在列式存储中:
- 查询1:只需读取 quantity 和 price 两列,对这两列数据并行计算累加。由于列式存储中同类数据紧密存储,压缩效率高,且无需读取无关字段,查询效率显著提高
- 查询2:仅需读取 order_date 和 customer_id 两列,筛选出 order_date 在指定范围内的记录,直接获取对应的 customer_id。同样,由于只访问所需列,查询效率得到提升
总结起来,列式存储和行式存储的主要区别在于数据的物理存储方式和对查询性能的影响:
- 行式存储:适合于事务处理(OLTP)场景,强调单行数据的完整性和更新效率,查询时通常需要访问整行数据,对涉及多行但仅需少数字段的分析查询效率较低
- 列式存储:适合于数据分析(OLAP)场景,强调对大量数据的高效扫描和聚合运算,查询时只需访问相关列,对大数据量的特定列查询和聚合查询有显著性能优势。由于同类数据集中存储,利于压缩和快速扫描。但对于涉及多列更新或全行读取的场景,列式存储可能不如行式存储高效
- 基于上一问,在行式存储中,传统数据库如 MySQL 采用 B+ 树索引结构吗,查询 1 和查询 2 可以不需要读取整行数据。既然行式存储可以借助索引实现高效读取,那为什么还需要有列式存储呢?
尽管行式存储数据库通过索引可以避免某些查询时的全表扫描,显著提升查询性能,但在特定业务场景下,尤其是大规模数据分析和数据仓库应用中,列式存储仍有其独特的价值和优势:
- 高效数据压缩
列式存储将同一类型的值集中存储,有利于实现高效的压缩算法。由于列内数据具有高度相似性,压缩比通常远高于行式存储,显著减少存储空间需求和 I/O 成本。这对于存储海量数据的数据仓库至关重要
- 针对性数据扫描
对于分析查询,通常只关注表中的一部分列。列式存储只需读取相关列的数据,避免了无关列的 I/O 开销。在处理大数据集时,这种针对性的数据扫描可以极大提升查询性能。相比之下,即使行式存储有索引,对于需要多个列参与计算的查询,可能仍需多次访问数据页以获取所有所需列的值。
- 高效聚合运算
列式存储非常适合执行大规模的聚合查询(如 SUM、AVG、COUNT 等)。由于数据按列组织,相同列的值聚集在一起,可以直接在列级别进行并行计算,无需像行式存储那样跨行收集数据。这使得列式存储在处理复杂的分析查询时表现出色,尤其是对于数据仓库和 BI(商务智能)应用。
- 冷热数据分离与存储优化
列式存储更容易实现冷热数据分离和存储层优化。例如,可以为访问频率高的列设置更高的存储级别(如 SSD),而对于访问较少的列,可以存储在成本更低的介质上。此外,可以根据数据访问模式和压缩策略动态调整列的存储布局,进一步优化存储效率。
- 列存计算友好
列式存储天然契合现代并行计算框架(如 Spark、Hadoop 等)和向量化执行引擎。这些框架和引擎通常以列作为基本处理单元,与列式存储的数据布局完美匹配,可以高效地进行批量数据处理和分析。
- 数据生命周期管理
在数据仓库环境中,数据通常有明确的生命周期,某些列可能仅在早期阶段被频繁查询,随着时间推移变得不那么重要。列式存储使得对单个列进行独立的存储策略调整(如归档、删除等)更为容易,有助于精细化的数据生命周期管理。
综上所述,尽管行式存储数据库通过索引可以优化部分查询性能,但在大数据分析、数据仓库、BI 等侧重于复杂查询和大规模数据处理的场景中,列式存储凭借其高效压缩、针对性数据扫描、卓越的聚合运算能力、灵活的存储优化以及与现代计算框架的良好集成等优势,提供了更为高效且成本效益高的解决方案。行式存储和列式存储各有适用场景,实际应用中往往根据业务需求、数据规模、查询模式等因素综合考虑,甚至在同一系统中结合使用两种存储模式(如 HybridDB 等混合存储数据库)。
- 基于前两问,在列式存储中,既然每一列都是单独存储的,那在查询 2 中是如何通过筛选 order_date 范围后获取对应的 customer_id 的呢?
在列式存储数据库中,尽管每一列数据是单独存储的,但数据库系统仍然会维护必要的元数据和索引来支持高效的查询。对于查询 2(找出所有在 2023 年 4 月购买了产品的客户 ID),列式存储数据库会通过以下步骤来获取对应的结果:
- 列式索引
列式数据库通常会对查询频繁或用于过滤条件的列(如 order_date)建立索引。这种索引可能采用 B 树、位图索引、稀疏索引等多种形式,目的是快速定位到符合条件的数据。例如,对于 order_date 列,可以构建一个按日期范围划分的索引结构,使得查询特定时间段的记录变得高效。
- 筛选 order_date
查询首先在 order_date 列的索引中查找 2023 年 4 月对应的索引条目。索引结构帮助快速定位到这一时间范围内的订单记录。查询结果通常是索引条目中存储的行标识符(row identifier,RID)或行组标识(chunk ID),它们指向实际数据存储的位置。
- 关联 customer_id
有了筛选出的行标识符后,数据库系统会使用这些标识符去对应的 customer_id 列数据区段中查找相应的客户 ID。由于列式存储中数据按列组织,customer_id 列的数据是连续存放的,所以可以用高效的方式(如一次批量读取)获取所有筛选出的行对应的 customer_id 值。
- 结果合并
最后,将从 customer_id 列获取的值与之前筛选出的行标识符(或直接就是 customer_id 值,取决于索引结构)进行合并,形成最终的查询结果集,即所有在 2023 年 4 月购买了产品的客户 ID 列表。
虽然列式存储中的数据分散在不同列中,但通过有效的索引结构和元数据管理,数据库系统能够有效地定位和关联相关数据,完成查询任务。这种方式避免了行式存储中可能需要的全表扫描或大量随机 I/O,利用列式存储的优势实现了对特定列高效且有针对性的访问。对于分析查询,尤其是涉及大数据集和复杂过滤条件的情况,这种设计能显著提升查询性能。
Doris 安装
-
安装 Docker
略
-
安装 WSL
wsl --install事实上,在本地实践时,直接通过执行上述命令安装即可,期间第一次失败了,再尝试执行就成功了。
如何使用 WSL 在 Windows 上安装 Linux
WSL 安装与使用
-
按键
Win + Q,输入wsl,开始运行 WSL若失败,切换挂载即可。
wsl --list wsl --setdefault <DISTRO_NAME><3>WSL (358) ERROR: CreateProcessParseCommon:789: Failed to translate Z:/
# 报错: Please disable swap memory before installation. # 临时禁用 Linux 系统中的交换内存 sudo swapoff -a -
修改内核参数
Doris 官方要求需要将 Linux 操作系统的内核参数设置为 2000000。
sudo sysctl -w vm.max_map_count=2000000 sysctl vm.max_map_count -
拉取镜像
docker run apache/doris:build-env-ldb-toolchain-0.19-latest -
下载安装包
apache-doris-2.1.0-bin-x64.tar.gz
mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz
-
启动镜像
docker run -d -it --name=doris -p 9030:9030 -p 8030:8030 apache/doris:build-env-ldb-toolchain-0.19-latest /bin/bash -
拷贝安装包至容器内
docker cp D:\doris\mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz doris:/opt docker cp D:\doris\apache-doris-2.1.0-bin-x64.tar.gz doris:/opt -
进入容器内部解压安装包
docker exec -it doris bash cd /opt/ tar -xvf apache-doris-2.1.0-bin-x64.tar.gz tar -xzvf mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz -
查看内网 IP 并配置 fe
hostname -i cd /opt/apache-doris-2.1.0-bin-x64/fe vi conf/fe.conf # 修改 priority_networks = 内网 IP -
启动 fe
./bin/start_fe.sh --daemon jps -
验证 fe 启动成功
curl http://127.0.0.1:8030/api/bootstrap # 浏览器可直接访问 http://localhost:8030/login, 用户名 root, 密码为空 -
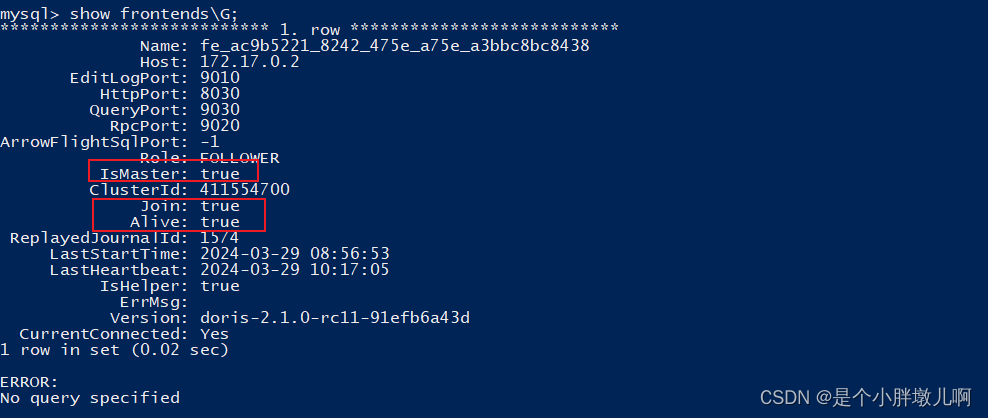
MySQL 中连接 fe,默认无密码
/opt/mysql-5.7.22-linux-glibc2.12-x86_64/bin/mysql -u root -P 9030 -h 127.0.0.1 --skip-ssl show frontends\G;
-
配置 be
cd opt/apache-doris-2.1.0-bin-x64/be vi conf/be.conf # 修改 priority_networks = 内网 IP -
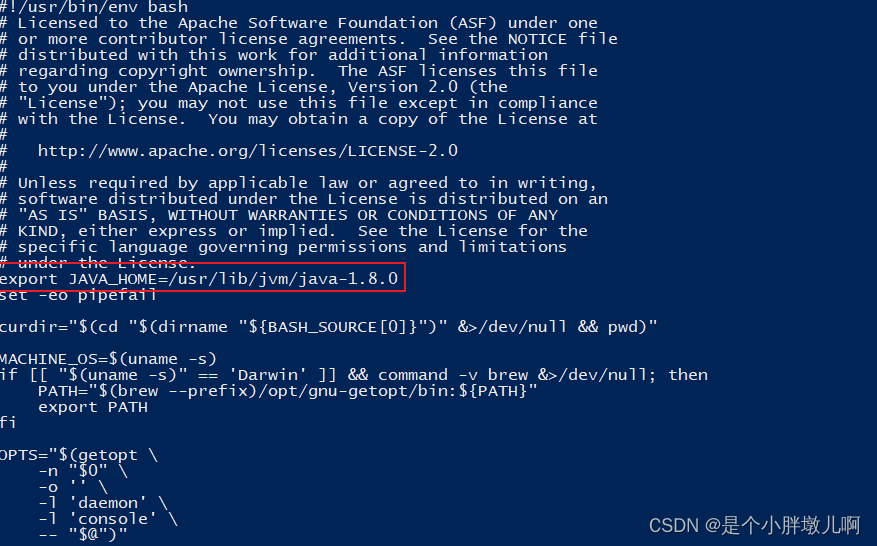
设置 jdk
镜像的 jdk 的默认路径为
/usr/lib/jvm/java-1.8.0。echo $JAVA_HOME vi bin/start_be.sh # 添加 export JAVA_HOME=/usr/lib/jvm/java-1.8.0
-
启动 be
./bin/start_be.sh --daemon -
在 MySQL 中连接 be,但更推荐直接用第三方工具(Navicat)连接后执行语句
/opt/mysql-5.7.22-linux-glibc2.12-x86_64/bin/mysql -u root -P 9030 -h 127.0.0.1 --skip-ssl ALTER SYSTEM ADD BACKEND "172.17.0.2:9050"; SHOW BACKENDS\G # Alive: true 表示节点运行正常CREATE DATABASE demo; USE demo; CREATE TABLE IFNOT EXISTS demo.example_tbl (`user_id` LARGEINT NOT NULL COMMENT "user id",`date` DATE NOT NULL COMMENT "",`city` VARCHAR ( 20 ) COMMENT "",`age` SMALLINT COMMENT "",`sex` TINYINT COMMENT "",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "",`cost` BIGINT SUM DEFAULT "0" COMMENT "",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "" ) AGGREGATE KEY ( `user_id`, `date`, `city`, `age`, `sex` ) DISTRIBUTED BY HASH ( `user_id` ) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );cd ~ vi test.csv # 10000,2017-10-01,beijing,20,0,2017-10-01 06:00:00,20,10,10 # 10006,2017-10-01,beijing,20,0,2017-10-01 07:00:00,15,2,2 # 10001,2017-10-01,beijing,30,1,2017-10-01 17:05:45,2,22,22 # 10002,2017-10-02,shanghai,20,1,2017-10-02 12:59:12,200,5,5 # 10003,2017-10-02,guangzhou,32,0,2017-10-02 11:20:00,30,11,11 # 10004,2017-10-01,shenzhen,35,0,2017-10-01 10:00:15,100,3,3 # 10004,2017-10-03,shenzhen,35,0,2017-10-03 10:20:22,11,6,6curl --location-trusted -u root: -T test.csv -H "column_separator:," http://127.0.0.1:8030/api/demo/example_tbl/_stream_load -
关闭命令
/opt/apache-doris-2.1.0-bin-x64/fe/bin/stop_fe.sh /opt/apache-doris-2.1.0-bin-x64/be/bin/stop_be.sh
● 官方文档
● Windows 搭建参考资料
数据计算工具 Spark、PySpark
分布式计算、内存计算、批处理
● 官方文档:https://spark.apache.org/
数据同步工具 CloudCanal
基于binlog可以实现mysql之间实时的数据同步,同时支持在不同类型的数据源之间做数据同步
● 官方文档:https://www.clougence.com/cc-doc/intro/product_intro
任务调度 dolphinscheduler
专业的任务调度工具,支持DAG有向无环图去配置任务间前驱后继的关系,出错自动重试等
● 官方文档:https://dolphinscheduler.apache.org/
BI工具 metabase
支持多种图表展示,支持sql原生语句
● 官方文档:https://www.metabase.com/